吃瓜教程 | Datawhale-2021.10打卡(Task05)
目录
- 第6章 支持向量机
-
- 6.1 间隔与支持向量
- 6.2 对偶问题
- 6.4 软间隔与正则化
- 6.5 支持向量回归
- 参考文献
第6章 支持向量机
6.1 间隔与支持向量
给定一组线性可分的训练样本,分类学习的目的就是找到一个划分超平面,将不同类别的样本分开,但根据前5章的知识可知,每次训练得到的超平面可能都不相同,如下图所示
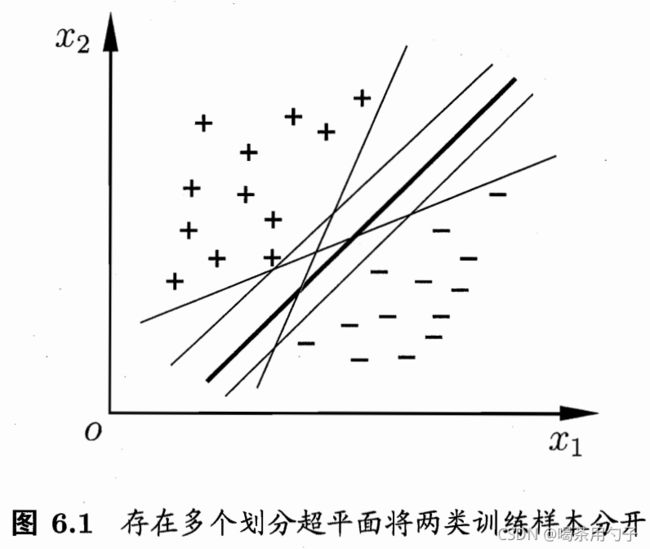
因此,支持向量机的作用:从几何角度出发,对于线性可分数据集,支持向量机就是找距离正负样本都最远的超平面。相比于感知机,这个超平面的唯一的,且这个划分超平面所产生的分类结果是最鲁棒的,对未见示例的泛化能力最强。
样本空间中任易点 x \bm{x} x到超平面 ( ω , b ) (\bm{\omega},b) (ω,b)的距离可写为:
r = ∣ ω T x + b ∣ ∥ ω ∥ (6.2) r=\frac{|\bm{\omega}^{\rm{T}}\bm{x}+b|}{\|\bm{\omega}\|} \tag{6.2} r=∥ω∥∣ωTx+b∣(6.2)
对于式(6.2)的证明过程如下所示:

支持向量机(Support Vector Machine,简称SVM)的基本模型如下:
{ m i n ω , b 1 2 ∥ ω ∥ 2 s . t . y i ( ω T x i + b ) ≥ 1 , i = 1 , 2 , … , m (6.6) \begin{aligned} \begin{cases} \underset{\bm{\omega},b}{\rm{min}} \quad \frac{1}{2}\|\bm{\omega}\|^{2} \\ {\rm{s.t.}} \quad y_{i}(\bm{\omega}^{\rm{T}}\bm{x}_{i}+b)\ge1, \qquad i=1,2,\dots,m \end{cases} \end{aligned} \tag{6.6} ⎩⎨⎧ω,bmin21∥ω∥2s.t.yi(ωTxi+b)≥1,i=1,2,…,m(6.6)
6.2 对偶问题
支持向量机(6.6)的对偶问题如下所示:
m a x α ∑ i = 1 m α i − 1 2 ∑ i = 1 m ∑ j = 1 m α i α j y i y j x i T x j s . t . ∑ i = 1 m α i y i = 0 , α i ≥ 0 , i = 1 , 2 , … , m (6.11) \begin{aligned} \underset{\bm{\alpha}}{\rm{max}} \quad &\sum\limits_{i=1}^{m}\alpha_{i}-\frac{1}{2}\sum\limits_{i=1}^{m}\sum\limits_{j=1}^{m}\alpha_{i}\alpha_{j}y_{i}y_{j}\bm{x}_{i}^{\rm{T}}\bm{x}_{j} \\ &{\rm{s.t.}} \quad \sum\limits_{i=1}^{m}\alpha_{i}y_{i}=0,\\ &\quad\qquad \alpha_{i}\ge0, \quad i=1,2,\dots,m \end{aligned} \tag{6.11} αmaxi=1∑mαi−21i=1∑mj=1∑mαiαjyiyjxiTxjs.t.i=1∑mαiyi=0,αi≥0,i=1,2,…,m(6.11)
将支持向量机原问题转化为拉格朗日对偶问题求解主要有如下两个原因:
- 无论原问题是否为凸优化问题,对偶问题恒为凸优化问题,因为对偶函数恒为凹函数(加负号即可转化为凸函数)。而且原始问题的时间复杂度与特征维数成正比(若特征维数大,会导致出现维数灾难问题),而对偶问题和数据量成正比,当特征维数远高于数据量的时候,采用拉格朗日对偶问题求解更高校;
- 对偶问题能引入核函数,进而可推广到非线性分类问题。(最主要的原因)
6.4 软间隔与正则化
上述两小节只考虑样本为线性可分情形,而在现实任务中,线性不可分的情形才是最常见的,由此引出了软间隔。
从数学角度出发,软间隔就是允许部分样本不满足下式中的约束条件:
{ m i n ω , b 1 2 ∥ ω ∥ 2 s . t . y i ( ω T x i + b ) ≥ 1 , i = 1 , 2 , … , m \begin{aligned} \begin{cases} \underset{\bm{\omega},b}{\rm{min}} \quad \frac{1}{2}\|\bm{\omega}\|^{2} \\ {\rm{s.t.}} \quad y_{i}(\bm{\omega}^{\rm{T}}\bm{x}_{i}+b)\ge1, \qquad i=1,2,\dots,m \end{cases} \end{aligned} ⎩⎨⎧ω,bmin21∥ω∥2s.t.yi(ωTxi+b)≥1,i=1,2,…,m
在最大化间隔的同时,不满足约束的样本尽可能少。于是软间隔的优化目标可写为:
m i n ω , b 1 2 ∥ ω ∥ 2 + C ∑ i = 1 m ℓ 0 / 1 ( y i ( ω T x i + b ) − 1 ) (6.29) \underset{\bm{\omega},b}{\rm{min}} \quad \frac{1}{2}\|\bm{\omega}\|^{2}+C\sum\limits_{i=1}^{m}\ell_{0/1}(y_{i}(\bm{\omega}^{\rm{T}}\bm{x}_{i}+b)-1) \tag{6.29} ω,bmin21∥ω∥2+Ci=1∑mℓ0/1(yi(ωTxi+b)−1)(6.29)
其中 C > 0 C>0 C>0是一个可人为调节的参数, ℓ 0 / 1 \ell_{0/1} ℓ0/1是“0/1损失函数”
ℓ 0 / 1 = { 1 , i f z < 0 ; 0 , o t h e r w i s e . (6.30) \ell_{0/1}= \begin{cases} 1,\quad if z<0;\\ 0, \quad otherwise. \end{cases} \tag{6.30} ℓ0/1={1,ifz<0;0,otherwise.(6.30)
由上式可知,当满足约束条件时,损失为0;不满足约束条件时,损失不为0。
当C取 + ∞ +\infty +∞时,为最小化目标函数式(6.29),会迫使所有样本满足上述约束条件,进而导致所有样本的损失为0,使得软间隔问题退化为硬间隔问题。当C取有限值时,则允许一些样本不满足约束条件。
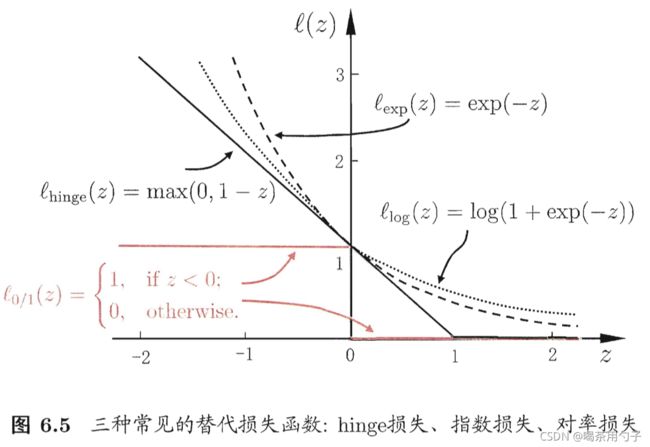
ℓ 0 / 1 \ell_{0/1} ℓ0/1非凸、非连续、存在不可导的点,因此常用如下三种常用的替代损失函数:
- hinge损失: ℓ h i n g e ( z ) = m a x ( 0 , 1 − z ) \ell_{hinge}(z)=\rm{max}(0,1-z) ℓhinge(z)=max(0,1−z);
- 指数损失(exponential loss): ℓ e x p ( z ) = e x p ( − z ) \ell_{exp}(z)=\rm{exp}(-z) ℓexp(z)=exp(−z);
- 对率损失(logistic loss): ℓ l o g ( z ) = l o g ( 1 + e x p ( − z ) ) \ell_{log}(z)=\rm{log}(1+\rm{exp}(-z)) ℓlog(z)=log(1+exp(−z));
6.5 支持向量回归
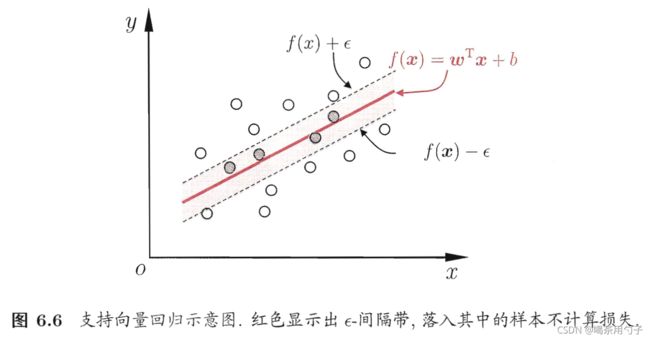
相比于线性回归用一条线来拟合训练样本,支持向量回归(Support Vector Regression,简称SVR)而是采用一个以 f ( x ) = ω T x + b f(\bm{x})=\bm{\omega}^{\rm{T}}\bm{x}+b f(x)=ωTx+b为中心,宽度为 2 ϵ 2\epsilon 2ϵ的间隔带,来拟合训练样本。
落在间隔带内的样本不计算损失,在间隔带外的样本则以偏离带子的距离作为损失,然后以最小化损失的方式迫使间隔带从样本最密集的地方(中心地带)穿过,进而达到拟合训练样本的目的。
参考文献
-《机器学习》,周志华著,清华大学出版社.
-《南瓜书》,Datawhale,南瓜书链接.