详解循环神经网络RNN原理+tensorflow实现
详解循环神经网络RNN原理+tensorflow实现
-
- 引言
- 一、原理
-
- 《深度学习》中关于循环和递归网络笔记
-
- 1、简介
- 2、展开计算图
- 3、循环神经网络
-
- (1)、三种重要的设计模式:
- (2)、作为有向图模型的循环网络
- (3)、基于上下文的RNN序列建模
- 3、双向RNN
- 4、基于编码-解码的序列到序列架构
- 5、深度循环网络
- 6、递归神经网络
- 7、长期依赖的挑战
- 8、回声状态网络
- 9、渗透单元和其他多时间尺度的策略
- 10、长短期记忆和其他门控RNN
- 11、优化长期依赖
- 12、外显记忆
- 莫烦python
-
- 1、RNN简介
- 1、LSTM介绍
- 李宏毅深度学习视频笔记
- 二、tensorflow实现
-
- 莫烦教学
- 三、总结
引言
因为前段时间在跟B站学习强化学习,其中提到过循环神经网络,于是在《深度学习》中学习了一点关于循环神经网络的知识,今天突然想再写以下代码,于是正好趁机整理下关于循环神经网络的知识。
本文推荐阅读的博客:
1、Recurrent Neural Networks(RNN) 循环神经网络初探
2、讲解详细的ppt
3、RNN应用-基于RNN的语言模型
一、原理
《深度学习》中关于循环和递归网络笔记
1、简介
循环神经网络是一类用于处理序列数据的神经网络,就像卷积神经网络是专门用于处理网格化数据。大多是循环网络也能处理可变长度的序列。
利用参数共享的思想,在模型的不同部分共享参数。参数共享可以使模型能够扩展到不同形式的样本(这里指的是不同长度的样本)并进行泛化。例如在文本处理中,可以共享在不同位置学到的特征。
卷积方法是时延神经网络的基础,参数共享的概念体现在每个时间步使用相同的卷积核。循环神经网络以不同的方式共享参数。输出的每一项是前一项的函数。输出的每一项对先前的输出应用相同的更新规则而产生。这种循环方式导致参数通过很深的计算图共享。
循环神经网络通常在序列的小批量上操作,并且小批量的每项具有不同序列长度。此外时间步索引仅表示序列中的位置。
RNN应用-基于RNN的语言模型这篇博文介绍了RNN在文本预测方面的应用原理。
2、展开计算图
本章的计算图思想扩展到包括循环,这些周期代表变量自身的值在未来某一时间步对自身的影响。
将神经网络的重复结构展开,这些重复结构通常对应一个事件链。
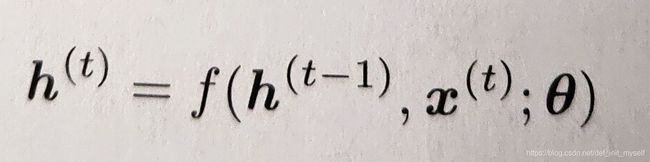
所有时间步都使用相同的参数(用于参数化f的相同θ值)。网络需要学会使用h(t)作为过去序列(直到t)与任务相关方面的有损摘要(有损是因为映射到固定长度,摘要是要保留有价值的信息)。
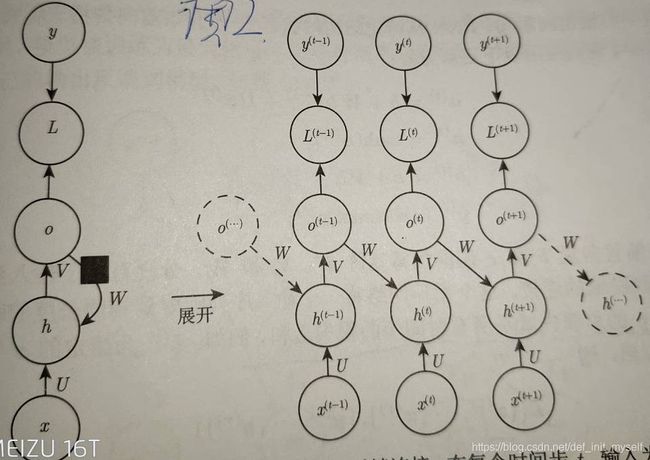
网络框图有两种,一种是回路原理图,一种是展开的计算图。
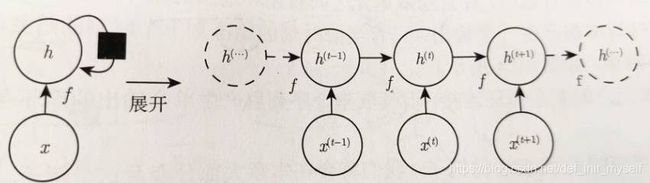
第一种定义了一个实时回路,第二种每个时间步的每个变量绘制为计算图的一个独立节点。
展开计算图有两个优点:
(1)、无论序列的长度,学成的模型始终具有相同的输入大小,因为他指定的是从一种状态到另一种状态的转移,而不是在可变的历史状态上操作。
(2)、我们可以在每个时间步使用相同的参数的相同转移函数。
3、循环神经网络
(1)、三种重要的设计模式:
(1)、每个时间步都有输出,并且隐藏单元之间有循环连接的循环网络。
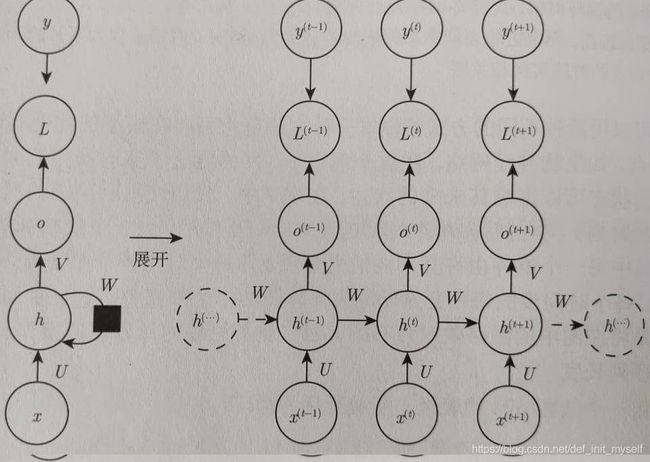
分别使用权重矩阵U,W,V参数化输入、输出。
例如应用预测词或者字符的时候,前向传播过程:

按照时间步,从h(0)开始前向传播,将输入影射到相同长度输出。
与x序列配对的y的总损失就是所有时间步的损失之和。
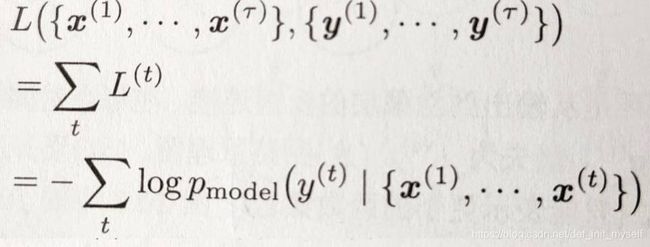
反向计算梯度,此处称之为通过时间反向传播(BPTT)。因为前向通道运行时有序可循,同时反向传播还要用到前向的参数,所以内存代价和计算复杂度都是O(τ)。
ps:BPTT:
循环神经网络的反向传播与BP有这样几个区别(在第一种模式下):、
[1]、损失函数对隐含单元求梯度的时候包含两部分,一部分是下一层的隐含单元损失函数对h(t+1)的微分再对h(t)求梯度;另一部分是这一层的损失函数o对h(t)求梯度
[2]、损失函数是多个L相加,即多个Lable对多个y求交叉熵损失的和
[3]、参数共享

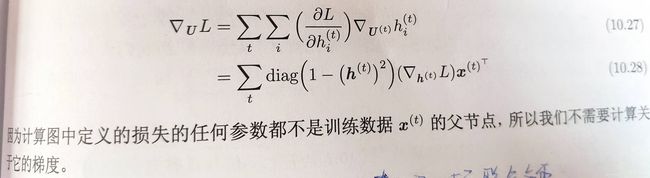
参考
BPTT 推导
RNN应用-基于RNN的语言模型
BPTT算法推导
(2)、每个时间步都产生一个输出,只有当前时刻的输出到下一时刻的隐藏单元之间有循环连接的循环网络。
没有上一种强大,上一种可以把想要放入的关于过去的任何信息放入隐藏单元h,并将h传播到未来。该网络仅把特定的输出放入o中,o是允许传播到未来的唯一信息,通常缺乏过去的重要信息,除非他高维且内容丰富。之前的h仅间接地连接到当前。但是这也更容易训练。因此每个时间步可以与其他时间步分离训练,允许并行化。
原因是可以利用导师驱动机制,即可以用真实的标签y作为下一级的输入,指定正确的反馈。当应用的时候就会只有o,用o近似y。
例如在一个网络中,给定x(1)、x(2)、y(1),模型会被训练为最大化y(2)的条件概率。
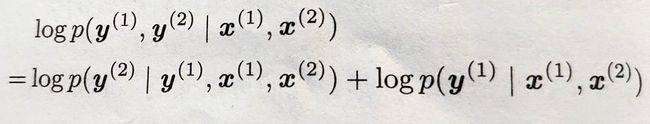

如果在开环模式下使用,也就是输入仅为真实标签的情况下,会造成训练结果和测试结果不同的情况出现。减轻问题的办法有两种:
[1]、同时使用导师驱动和自由运行的输入进行训练:这个地方大多博客没有对下面这段话给出解释:
“例如在展开循环的输出到输入路径上预测及个步骤的正确目标值。通过这种方式,网络可以学会考虑在训练时没有接触到的输入条件(如自由运行模式下,自身生成自身),以及将状态映射回网络几步之后生成正确输出的状态。”
这里我的解读是,在网络中的几个时间步采取预测的值作为输出,然后在后面的几个时间步采取真正的标签。这样做的目的是可以训练前面的权重更加具有泛化,同时还不影响网络最终的输出。
如理解有误,请不吝指正,感谢大家!!!
[2]、随意选择生成值或者真实的数据值为输入以减小训练和测试看到的输入之间的差别。
(3)、隐藏单元之间存在循环连接,但读取整个序列后产生单个输出的循环网络。
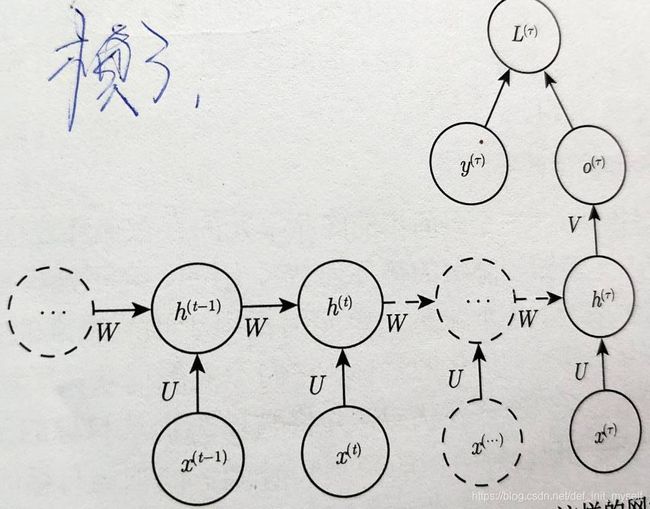
这种网络可以用来概括序列并产生用于进一步处理的固定大小的表示
(2)、作为有向图模型的循环网络
我们希望通过RNN输出解释为一个概率分布,可以通过最大化对数似然来训练网络。如果不把过去的y反馈给下一步作为预测的条件,那么y与x是条件独立的。(但是y之间没说是否独立);如果反馈输出到下一步输入,那么就可以把RNN视为一个结构为有向完全图(每两个顶点之间都有一条边)的图模型(此处只有y)。
ps:有向图,通过局部的条件概率表示联合概率,使用单个函数来描述整个联合分布是非常低效的。
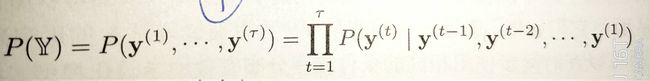
由于使用相同的函数f,以及在每个时间步的相同参数θ,所以可以将完全图模型中的边表示为一个状态变量。这样就可以实现参数大大减小,实现参数共享。
这里可以理解为比如y(1)到y(5)的边是由h(1)到h(5)以及W的乘积表示。
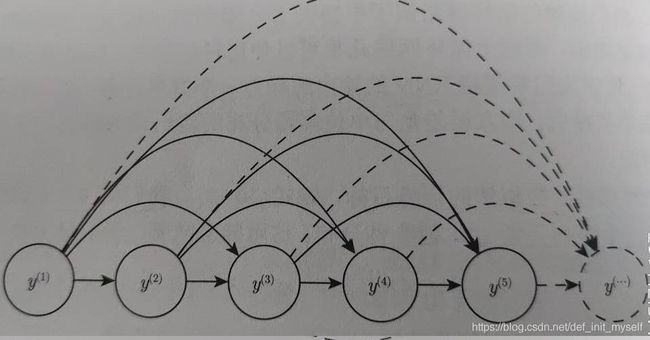

注:本来y之间不是条件独立的,但是通过引入隐藏变量h,可以间接解释了独立性的问题。同时可以代表关于y序列的任意概率分布
在图模型中唯一需要做的就是从每一时间步的条件分布采样,为了保证序列的长度,可以以以下方式实现:
[1]、添加一个对应于末端的特殊符号,当产生该符号时采样停止;
[2]、引入一个额外的Bernoulli输出,表示每个时间步继续生成还是停止;
[3]、可以将模型的额外输出,例如t引入模型,使模型知道自己是否靠近末尾
(3)、基于上下文的RNN序列建模
RNN图模型允许p(y;x)的关于x,y的联合分布,可以解释为p(y|x)条件分布模型(由以上图模型得知)。
因此我们考虑x输入情况下的RNN图模型。
ps:以上介绍的三种重要设计模式都是RNN图模型,只不过上一小节为分析过程。
[1]、x为向量时,将x作为一个额外输入提供到RNN,方法为每个时刻作为一个额外输入。
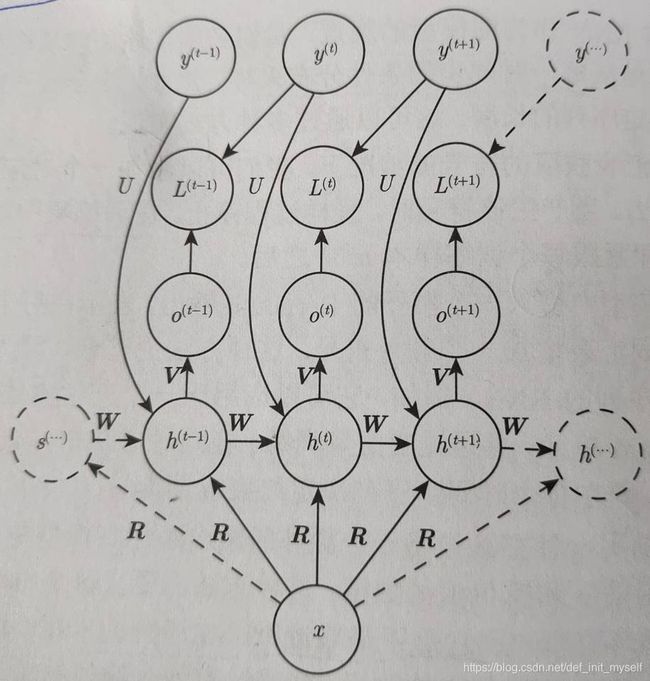
因为对应的x都是同一个x,所以这里y之间还是存在独立性,t时刻的y同时作用于当前输入,与t-1时刻(这里我的理解为,作为前一时刻的“标签”)。
[2]、接受x序列作为输入,同时去掉条件独立性假设。就可以表示y的任意概率分布。这里的任意,我的理解是可以表示在任意数量y(i_past)下y(now)的概率。
同时要求输入和输出具有相同的序列长度。

3、双向RNN
在协同发音,和手写识别等过程中,正确解释可能需要依赖未来的语义才能确定,因此使用双向RNN。
双向RNN,顾名思义,结合时间上从序列起点开始移动的RNN和另一个时间上从序列未来开始移动的RNN。这允许输出单元o(t)能够计算同时依赖于过去和未来,且对时刻T的输入值最敏感的表示。而不必指定t周围固定大小的窗口。
扩展到图像,可以用4个(上、下、左、右)RNN,如果能学习承载长期信息,那么每个点输出就能计算一个捕捉到周围大多数局部信息,但仍以来于长期输入的表示。

4、基于编码-解码的序列到序列架构
对于机器翻译,语音识别等任务而言,输入序列长度不一定等于输出序列长度,我们将RNN输入称为上下文,并将上下文通过RNN处理(编码器)为一个向量或者向量序列C。
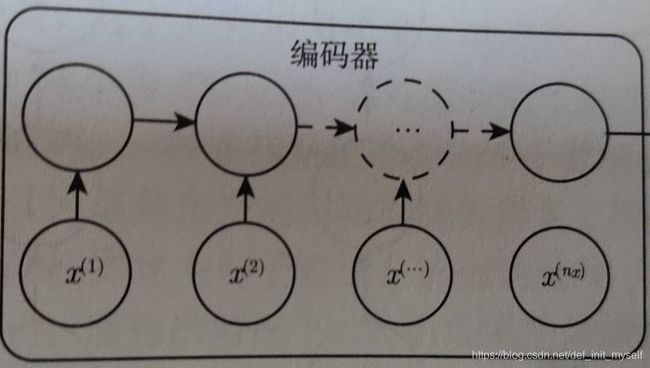
通过RNN以固定长度向量为条件产生输出序列(解码器)。
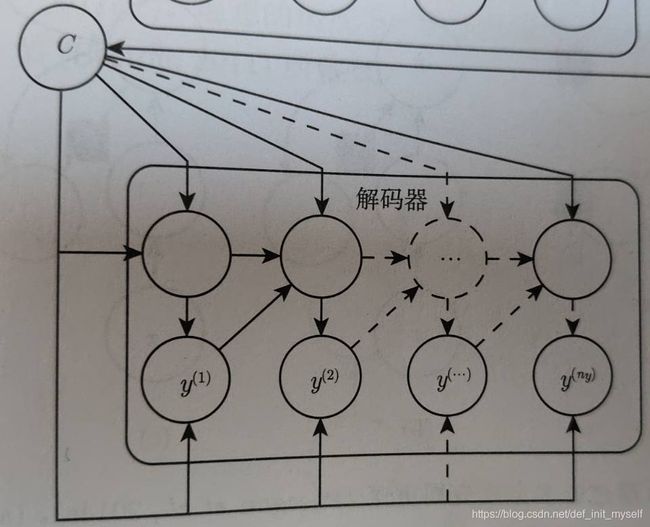
整个过程包括首先概括输入的语义,然后将其“翻译”输出。
基于希望生成序列的元素与输入数据之间具有密切关联的,采用注意力机制。
通常实现方法是对于编码器和解码器中隐藏单元的对齐可能性来赋予每个Ci中对于各个输入部分不同的权重。详见【NLP】Attention Model(注意力模型)学习总结
5、深度循环网络
RNN的组成部分大多可以分解成三块参数以其相关的变换:
[1]、从输入到隐藏状态
[2]、从前一隐藏状态到下一隐藏状态
[3]、从隐藏状态到输出
每一部分都是一个浅变换(MLP中的一层,由仿射变换和非线性表示组成)
深度也就是在这三个部分中增加深度,由如下三种方式:

概况来讲,第一种可以生成更加合适的输入;第二种可以增加容量;第三种在第二种的基础上加入跳跃连接可以缩短变量之间的最短路径长度。
6、递归神经网络
递归神经网络被构造为树状结构而不是RNN的链状结构,潜在用途是学习推断。递归网络已成功应用在输入是数据结构(因为可以适合特定的树结构)的神经网络。
明显优势:具有相同长度τ的序列,深度可以急剧得从O(τ)减小为O(logτ),有助于解决长期依赖。
可以采用不依赖数据结构的树结构,如平衡二叉树;或者某些外部方法,比如语法分析树等。

7、长期依赖的挑战
对于RNN这种依赖长期输入的结构,长期依赖的困难来自比短期相互作用指数小的权重(即长期依赖关系的信号很容易被短期相关性产生的最小波动隐藏)。比如对于这种循环神经网路:


正如书中所言,可以通过给定目标期望方差然后设计单个比例方差的方法来避免梯度消失和爆炸问题

同时可以使用batch_normal来避免梯度消失。
8、回声状态网络
从输入到隐藏单元的权重映射以及隐藏单元之间的权重映射是循环神经网络中最难学习的参数。
因此提出设定循环隐藏单元,使其很好的捕捉过去输入历史(任意长度序列映射为一个固定长度向量),并只学习输出权重(可以加一个线性预测算子)。
概括来看就是从输出到输出前的网络不去学习只需要初始化,只学习最后一层线性层。回声状态网络到底是什么?
所以问题是如何设置参数?
书中介绍的是将循环网络视为动态系统,根据隐藏单元之间雅可比矩阵的谱半径来固定权重。
谱半径:
谱半径就是雅可比矩阵中特征值的最大绝对值。
线性映射时:雅可比矩阵就是W的线性组合的乘积,当梯度反向传播的时候,梯度向量g乘以雅可比矩阵J,此时如果g含有小的扰动δ,并且是v的特征值λ的特征向量,当|λ|>1的时候偏差δJv会指数增加,当小于1的时候会指数减少。
非线性映射时:雅可比矩阵J是W与非线性函数导数乘积的组合的乘积,会在每一步任意变化,因此建议使用谱半径大于1的矩阵。非线性和线性的区别时压缩非线性,比如tanh可以使前向传播中循环动态量有界,反向传播一般有界(排除所有tanh都处于线性区的极端情况)
9、渗透单元和其他多时间尺度的策略
第7节是通过初始化参数的方法解决的长期依赖的挑战,还有一种方法是设计工作在多个时间尺度的模型。使模型可以在某些部分的细粒时间尺度上操作并能处理小细节,在其他部分的粗时间尺度上操作并能把遥远过去的信息更有效传递过来。构建方法有以下三种
(1)、时间维度的跳跃连接**
[1]一种方法是增加从遥远过去的变量到目前变量的直接连接,可以得到粗时间尺度。
可以理解为原来的连接不变,只是增加到将来的连接
RNN 中学习长期依赖的三种机制
[2]、一种是引入d延时,要理解d延时,就必须知道循化神经网络的实质,是一个隐藏单元的不断循环,这里不要用展开计算图的思想
讲解详细的ppt
(2)、渗透单元和一系列不同时间尺度**
[1]、渗透单元是在隐藏单元中设置线性自连接的隐藏单元。
通过滑动平均的方法对当前和过去进行权衡,类似于强化学习中迭代平均计算以及Q-Learning公式。

图连接如下
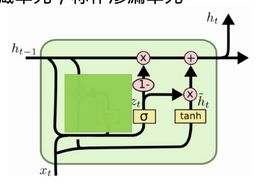
a值越大,越能记住以前的数据。
[2]、d时间步的跳跃连接。确保单元总能够被d个时间步前的的值影响。
(3)、删除连接**
因为信息在较慢的时间尺度上更容易长距离流动,因此通过删除长度为1的边,也就是在跳跃连接的基础上,把中间的长度为1的边删除,来选择长时间尺度运行。
同时可以强制一组循环单元在不同时间尺度上运行有不同方式。
一种是使循环单元关联不同的时间尺度;另一种是通过跳跃,删除等方式。
10、长短期记忆和其他门控RNN
门控RNN的想法可以在每个时间步都可能改变连接权重
(1)、LSTM**
与普通RNN相比,关键扩展是使自循环的权重视上下文而定,门控此自循环的权重,累计的时间尺度可以动态地改变。

其中输入可以是任意压缩非线性,门控单元需要是sigmod。
作为渗透单元的自循环权重由遗忘门和舒入门控制。
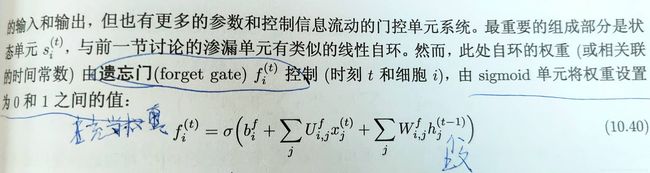


并通过输出门控制输出
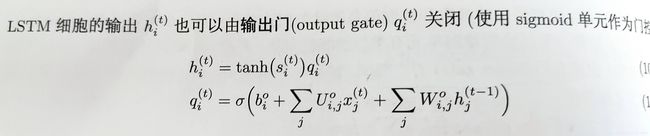
研究发现,向LSTM的遗忘门加1的偏置可以让LSTM变得与已探索的最佳变种一样健壮。
(2)、其他门控RNN**
GRU与LSTM的主要区别是,单个门控单元同时控制遗忘因子和更新状态单元的决定。
其中的复位门类似遗忘门,更新门类似输入控制门

11、优化长期依赖
(1)、截断梯度**
循环神经网络和一些具有强非线性函数单元的梯度的目标函数可能会存在悬崖地形的分布:
当参数梯度非常大时,梯度下降的参数更新可以将参数抛出去很远。梯度告诉我们,围绕当前参数的无穷小区域内最速下降的方向,这个无穷小区域以外,代价函数可能开始沿曲线背面而上。
截断梯度在参数更新之前截断梯度g的二范数:
这里虽然小批量截断后和的平均的梯度方向不等于小批量和的平均的梯度方向(真实梯度方向)
但是仍然是一个下降方向。只不过引入了经验上有用的启发式配置。
(2)、引导信息正则化**
梯度截断有助于处理爆炸的梯度,但无助于消失的梯度。我们的目标是在展开的计算图中构建梯度乘积接近一的连接,在之前的描述中通过引入LSTM和GRU等来解决,这里通过正则化的思想,确保梯度在隐藏单元之间传递的时候不会损失。
12、外显记忆
神经网络很难记住事实,同时神经网络的重要作用是用它来实现循序推论,而不是直观的反映,可以让他处理隐含的,潜意识的表达。这就需要网络可以由大量的事实进行学习。因此外显记忆相当于引入工作存储系统,成为记忆网络(NTM)。
通过寻址机制访问记忆单元,了通过基于内容的软注意机制,允许端到端学习。
[1]、寻址
网络输出内部状态选择从哪个单元读取或者写入,往往是多个记忆单元。读取时采用多个单元的加权平均。这些系数被集中在小数目的单元中,如通过softmax函数产生,可以通过梯度下降优化。
[2]、基于内容
记忆单元通常扩充为向量,一是为了抵消访问记忆单元所用的成本,二是这允许基于内容的寻址。比如通过几个字的歌词回忆整首歌。这是每一个字母单独存储在记忆单元中(基于位置)所做不到的。
[3]、总结
外显记忆的方法由存储器耦合“任务神经网络”组成,任务神经网络可以是前馈或者循环。但是整体是一个循环网络。优点是信息和梯度可以在非常长的持续时间内传播。
莫烦python
1、RNN简介
序列数据,预测单个数据都是基于单个,每次使用同一个网络。
以做饭放料为背景,各个数据之间是有关联的,如何实现关联,以人来说就是记住之前发生的事。分析data0的时候将结果储存,当分析data1的时候,因为data0与data1没有关联,因此就把data0调用过来一起分析,分析更多数据就会累计起来一起分析。
用于分类问题,看积极还是消极,则可以利用这样的RNN:
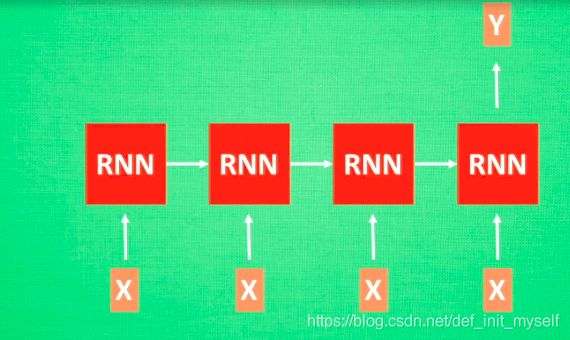
对于图片描述的RNN,只需要一个输入:
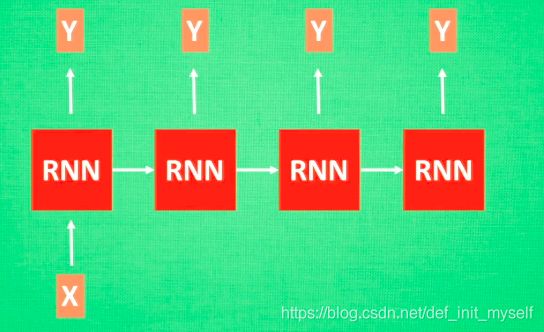
语言翻译RNN:

1、LSTM介绍
从背景出发,看RNN能否知道今天做了什么采
计算梯度的时候有一直乘自身的一项,容易导致梯度消失或者梯度爆炸。
使用LSTM可以避免这个情况
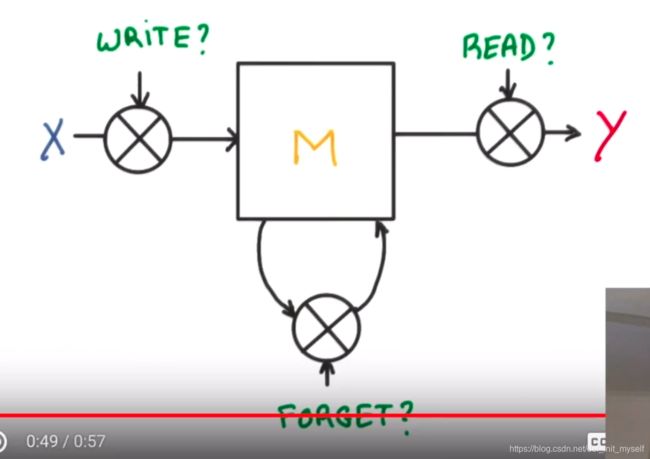
李宏毅深度学习视频笔记
哔俚哔哩链接如下
【李宏毅 深度学习19(完整版)国语】机器学习 深度学习
首先是介绍两种常见的RNN
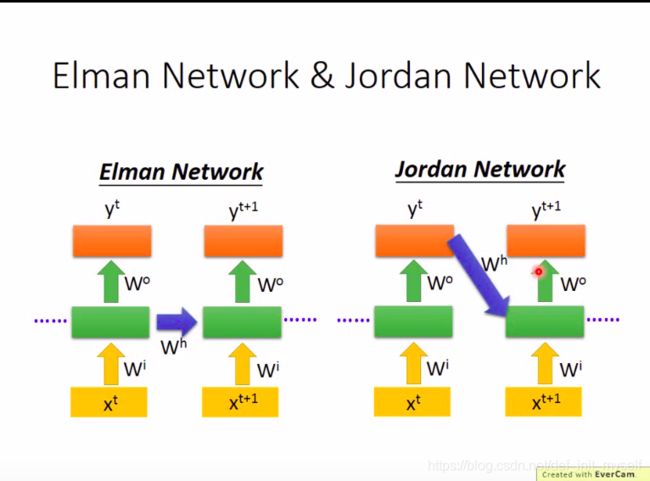
然后是双向RNN

(2)、LSTM比普通RNN好的原因:
(1)、普通RNN 可能会造成梯度爆炸或者消失,但是LSTM不会,因为他可以通过遗忘门,动态改变累计的时间尺度,使其在1左右。就算比1大,只要设置小的学习率,并且用梯度截断,也是可以解决问题的。
(2)、记忆单独通过遗忘门(确保大多数情况下开启)储存,通过与x相加,再把值放入cell,不能通过x刷新。记忆可以长时间存在,所以不存在梯度消失问题。***
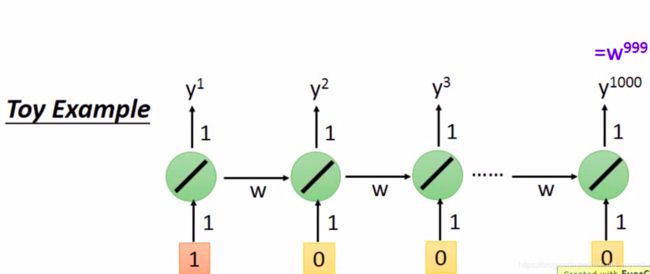
LSTM,应该断句为长的短期记忆

RNN不好训练的原因是梯度,不在于激活函数。
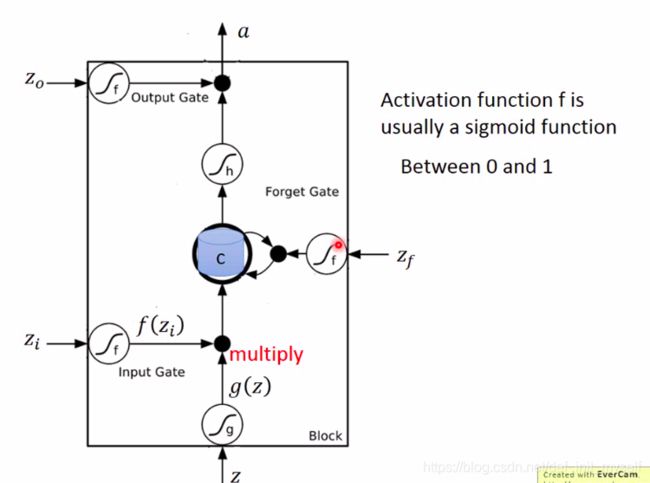
有四个输入
输入z经过非线性压缩变为g(z)
输入门控信号zi,非线性变为f(zi)
遗忘门控信号zf,非线性变为f(zf)
输出门控信号zo,非线性变为f(zo)
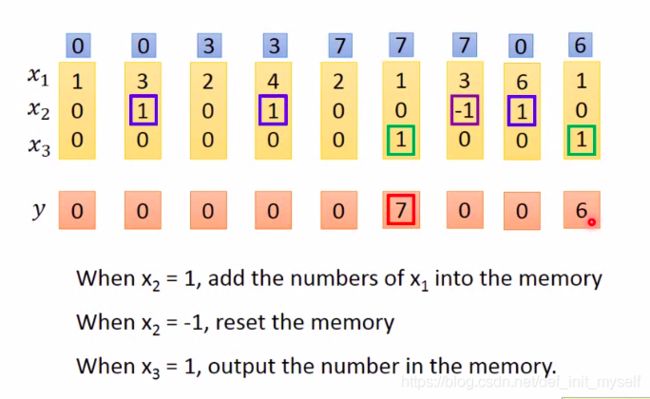
假设输入门为常开,x1为输入数据,x2为遗忘们,x3为输出门的小例子
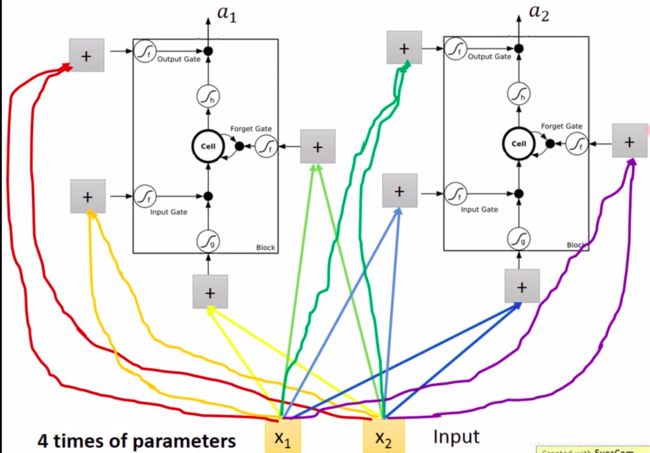
真实的RNN中,这些门控信号的值都是由网络自己习得。
每个x都通过乘以不同的权重,作为四个输入的信号,学习的门控信号,也就是学习权重参数。
当然这里的输入可以不仅是x还可以是h和c。
gru:少了一个gate,可减少国拟合。当inputgate打开的时候,forgetgate就会关闭;如果forgetgate需要开启的时候inputgate就会关闭。

一些应用场景:
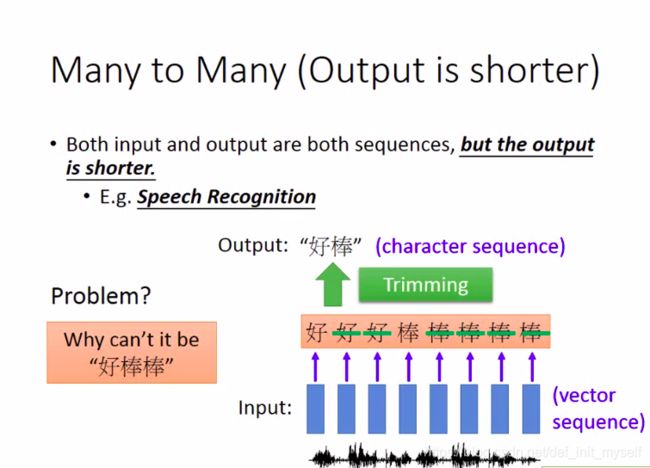
trimming的方式显示不会得出“好棒棒”。
在这里可以让机器学习“断”。
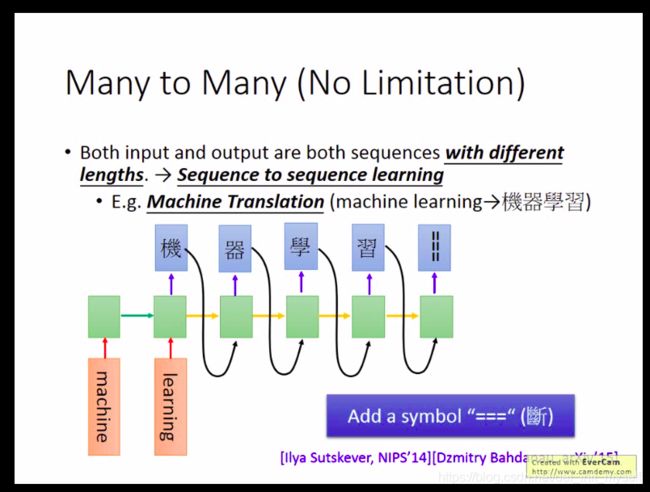
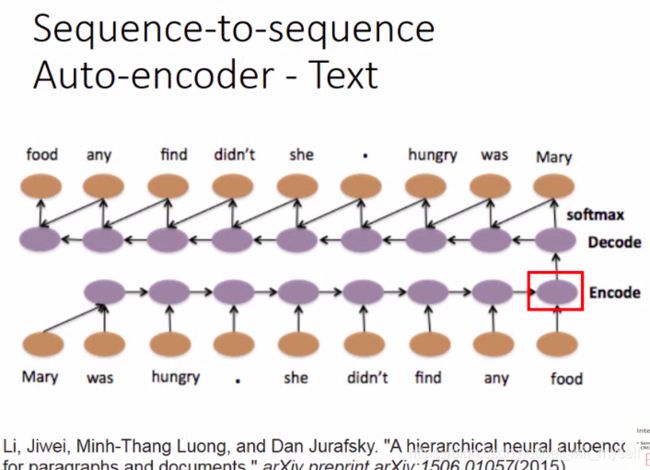
自动编码,解码,前一个RNN 的最后一个单元是句子的语义概括,decode可以学习解码。两者同时进行。


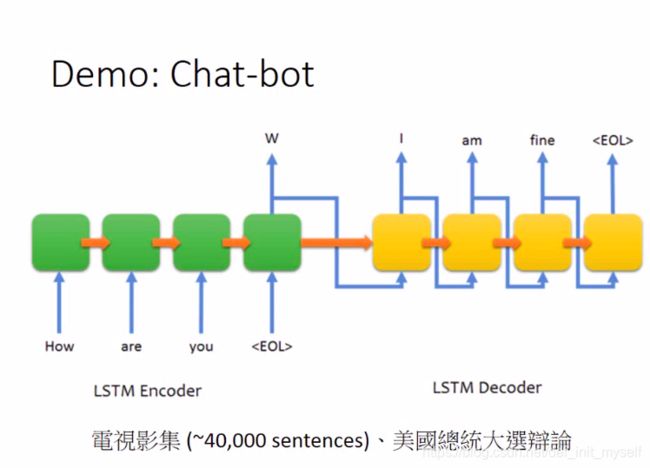
即前面讲的外显记忆

可以通过CNN概括语义
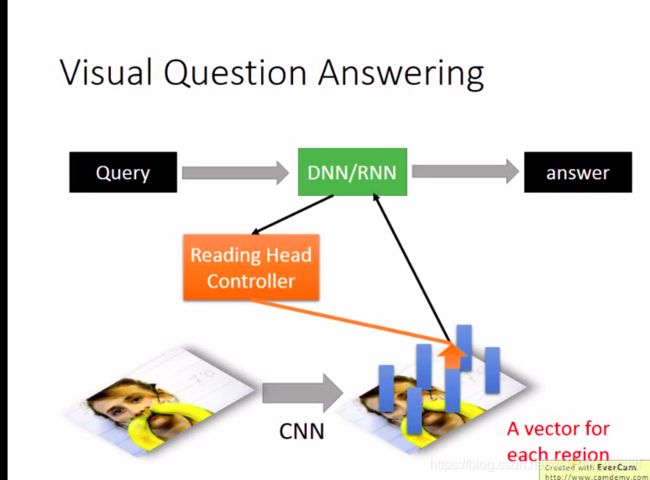
二、tensorflow实现
莫烦教学
终于到了实践的环节了,基础还是必要的。
https://www.sohu.com/a/128669963_642762
代码部分,见另一篇博文
https://blog.csdn.net/def_init_myself/article/details/105372941
三、总结
RNN的学习终于告一段落,希望可以学好RNN!加油~