【吴恩达-course1-第二周-编程作业】实验记录-【Jupyter方式】
返回总目录
本文是个人学习【中文】【吴恩达课后编程作业】Course 1 - 神经网络和深度学习 - 第二周作业 的详细实现过程。下面会围绕这篇文章来叙述。
注意事项
抄写python代码时,要注意缩进和原文中要保持一致。
C++中空格多一个少一个没什么关系,但Python中不行。
环境
Anaconda 3
第一部分(就是到猫那张图片之前)
原博文:
在开始之前,首先声明本文参考【Kulbear】的github上的文章,本文参考Logistic Regression with a Neural Network mindset,我基于他的文章加以自己的理解发表这篇博客,力求让大家以最轻松的姿态理解吴恩达的视频,如有不妥的地方欢迎大家指正。
本文所使用的资料已上传到百度网盘【点击下载】,提取码:2u3w ,请在开始之前下载好所需资料,然后将文件解压到你的代码文件同一级目录下,请确保你的代码那里有lr_utils.py和datasets文件夹。
【博主使用的python版本:3.6.2】
我们要做的事是搭建一个能够**【识别猫】** 的简单的神经网络,你可以跟随我的步骤在Jupyter Notebook中一步步地把代码填进去,也可以直接复制完整代码,在完整代码在本文最底部。
在开始之前,我们有需要引入的库:
numpy :是用Python进行科学计算的基本软件包。
h5py:是与H5文件中存储的数据集进行交互的常用软件包。
matplotlib:是一个著名的库,用于在Python中绘制图表。
lr_utils :在本文的资料包里,一个加载资料包里面的数据的简单功能的库。
如果你没有以上的库,请自行安装。
import numpy as np
import matplotlib.pyplot as plt
import h5py
from lr_utils import load_dataset
1
2
3
4
5
lr_utils.py代码如下,你也可以自行打开它查看:
import numpy as np
import h5py
def load_dataset():
train_dataset = h5py.File('datasets/train_catvnoncat.h5', "r")
train_set_x_orig = np.array(train_dataset["train_set_x"][:]) # your train set features
train_set_y_orig = np.array(train_dataset["train_set_y"][:]) # your train set labels
test_dataset = h5py.File('datasets/test_catvnoncat.h5', "r")
test_set_x_orig = np.array(test_dataset["test_set_x"][:]) # your test set features
test_set_y_orig = np.array(test_dataset["test_set_y"][:]) # your test set labels
classes = np.array(test_dataset["list_classes"][:]) # the list of classes
train_set_y_orig = train_set_y_orig.reshape((1, train_set_y_orig.shape[0]))
test_set_y_orig = test_set_y_orig.reshape((1, test_set_y_orig.shape[0]))
return train_set_x_orig, train_set_y_orig, test_set_x_orig, test_set_y_orig, classes
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
解释以下上面的load_dataset() 返回的值的含义:
train_set_x_orig :保存的是训练集里面的图像数据(本训练集有209张64x64的图像)。
train_set_y_orig :保存的是训练集的图像对应的分类值(【0 | 1】,0表示不是猫,1表示是猫)。
test_set_x_orig :保存的是测试集里面的图像数据(本训练集有50张64x64的图像)。
test_set_y_orig : 保存的是测试集的图像对应的分类值(【0 | 1】,0表示不是猫,1表示是猫)。
classes : 保存的是以bytes类型保存的两个字符串数据,数据为:[b’non-cat’ b’cat’]。
现在我们就要把这些数据加载到主程序里面:
train_set_x_orig , train_set_y , test_set_x_orig , test_set_y , classes = load_dataset()
1
我们可以看一下我们加载的文件里面的图片都是些什么样子的,比如我就查看一下训练集里面的第26张图片,当然你也可以改变index的值查看一下其他的图片。
index = 25
plt.imshow(train_set_x_orig[index])
#print("train_set_y=" + str(train_set_y)) #你也可以看一下训练集里面的标签是什么样的。
1
2
3
运行结果如下:
操作步骤
下载作业包 提取码: 34rc
解压后,在这个文件夹里建一个main.py
如果你不会建.py,那就建立.txt,把代码复制进去,然后把.txt强制改为.py。(我没试,但我觉得可以)
把下面代码复制进去:
import numpy as np
import matplotlib.pyplot as plt
import h5py
from lr_utils import load_dataset
test_set_x_orig,test_set_y_orig,train_set_x_orig,train_set_y_orig, classes =load_dataset()
index=25
plt.imshow(train_set_x_orig[index])
打开Jupyter
新建一个文件夹
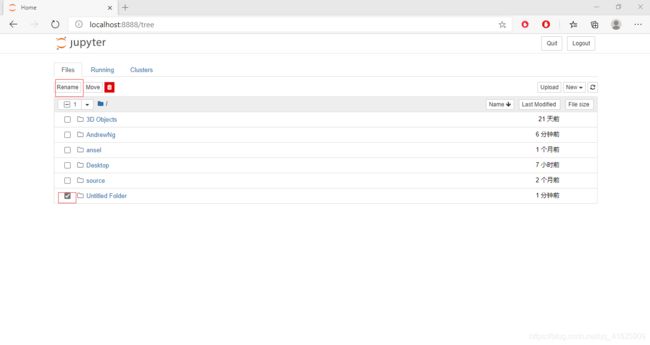
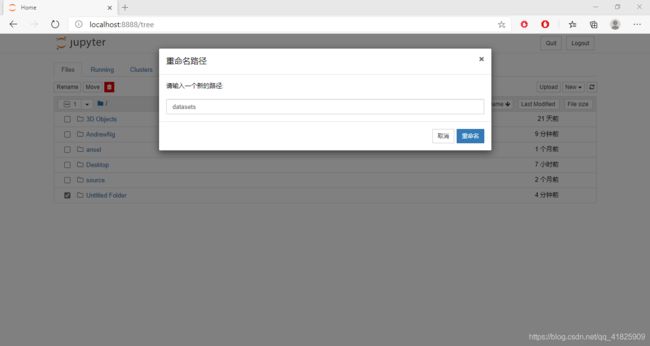
 此时得到的是名为“Untitled Folder”的文件夹。在前面打勾,上面出现一个“Rename”,点击,改名为“datasets”
此时得到的是名为“Untitled Folder”的文件夹。在前面打勾,上面出现一个“Rename”,点击,改名为“datasets”
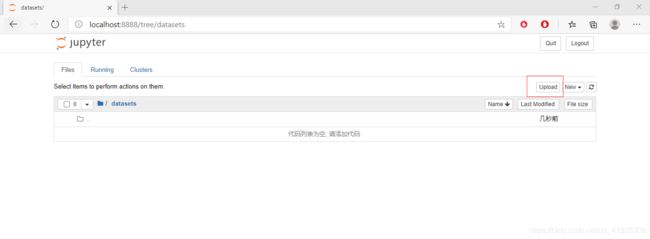
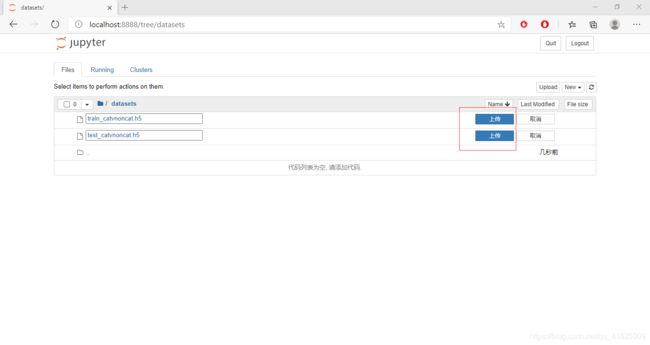
进入datasets文件夹,点击右上角的upload,把下载好的文件中的datasets里面的两个文件上传
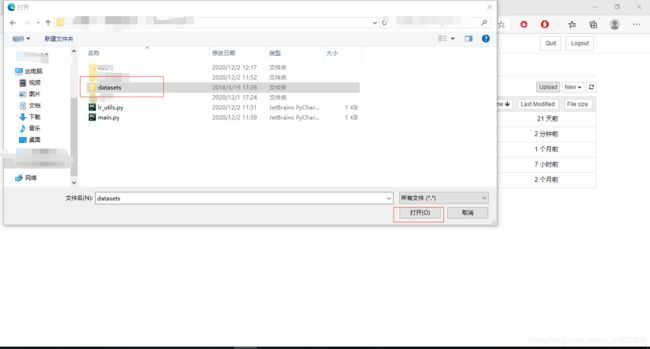 (ctrl+a 全选即可)
(ctrl+a 全选即可)
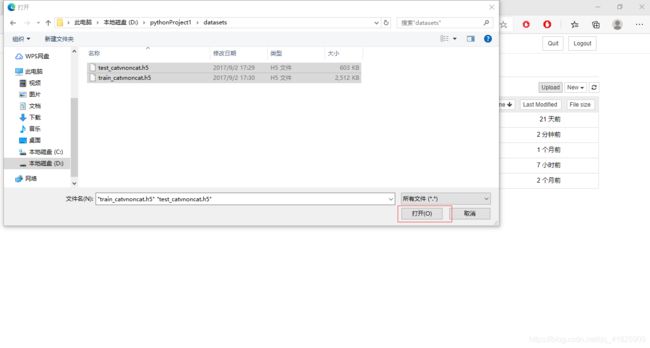 点击“上传”
点击“上传”
 回到home页面 点击右上角“new”,点击python3
回到home页面 点击右上角“new”,点击python3
 %run +【你的main路径】
%run +【你的main路径】
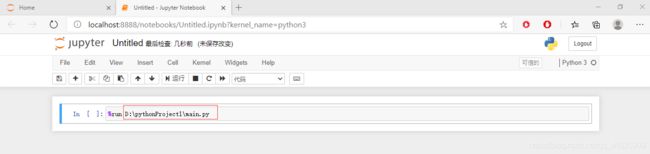 点击上面的“运行”
点击上面的“运行”
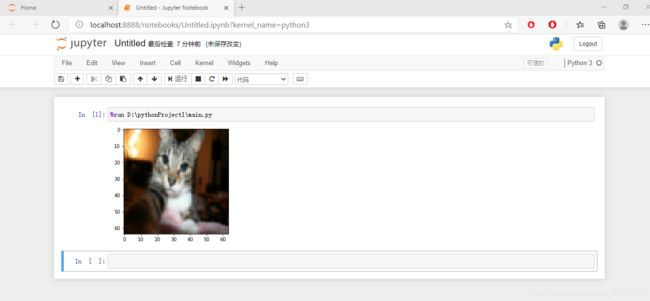
出来啦~~~真棒!第一部分就完成啦!