- 操作系统练习题
齐 飞
linux
文章目录一、单选题二、多选题三、填空题四、简答题一、单选题1、在计算机系统中配置操作系统的主要目的是()。A、增强计算机系统的功能B、提高系统资源的利用率C、提高系统的运行速度D、合理组织系统的工作流程,以提高系统吞吐量正确答案:B2、操作系统的主要功能是管理计算机系统中的(),其中包括处理机、存储器,以及文件和设备。这里的存储器管理主要是对进程进行管理。A、程序和数据B、资源C、软件D、硬件正确
- python基础之--面相对象--OOP基本特性
暴龙胡乱写博客
python开发语言人工智能
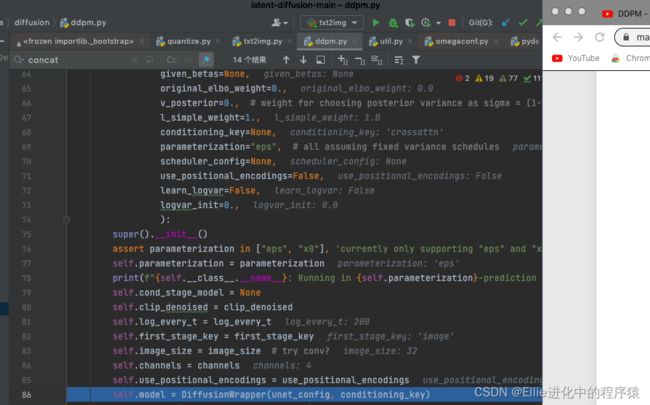
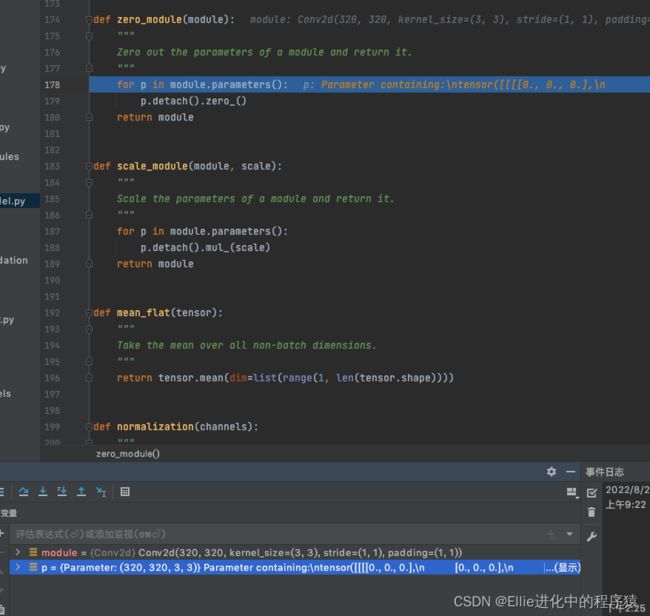
python基础之–面相对象–OOP基本特性文章目录python基础之--面相对象--OOP基本特性一,OOP基本特性1.1封装1.2继承/派生1.2.1基础概念1.2.3继承实现1.3多态1.4对象对成员的操作(补充)1.5私有属性1.6重写魔术方法二,super函数2.1基本使用2.2super().\__init__()一,OOP基本特性OOP的四大基本特性是封装、继承、多态和抽象。1.1封
- AI大模型产品经理学习路线,2025最新,从AI产品经理零基础入门到精通,非常详细收藏我这一篇够了!
AGI-杠哥
人工智能产品经理学习语言模型agi自然语言处理
随着人工智能技术的发展,尤其是大模型(LargeModel)的兴起,越来越多的企业开始重视这一领域的投入。作为大模型产品经理,你需要具备一系列跨学科的知识和技能,以便有效地推动产品的开发、优化和市场化。以下是一份详细的大模型产品经理学习路线,旨在帮助你构建所需的知识体系,从零基础到精通。一、基础知识阶段1.计算机科学基础数据结构与算法:理解基本的数据结构(如数组、链表、树、图等)和常用算法(如排序
- java集合数据复制到另外一个集合
hamish-wu
Java
文章目录Lsit中数据复制问题1.1浅拷贝1.2深拷贝1.3最终结论Lsit中数据复制问题这是由一道开放式面试题引发的文章,题目:加入内存足够大,一个集合中有100万条数据,怎么高效的把集合中的数据复制到另外一个集合1.1浅拷贝java中复制分为浅拷贝和深拷贝如果考察浅拷贝:直接使用clone方法System.out.println("测试开始时");Lista=newArrayList(1000
- 《Astro 3.0 岛屿架构实战:用「零JS」打造百万PV内容网站》
前端极客探险家
架构javascript开发语言
文章目录一、传统内容站点的性能困局1.1企业级项目性能调研(N=200+)1.2Astro核心优势矩阵二、十分钟构建高性能内容站点2.1项目初始化2.2核心配置文件三、六大企业级场景实战3.1场景一:多框架组件混用3.2场景二:交互增强型Markdown四、性能优化深度解析4.1优化前后数据对比4.2关键优化策略五、企业级架构方案5.1内容站点技术栈5.2流量突增应对方案六、调试与监控体系6.1性
- 论文翻译:ChatGPT: Bullshit spewer or the end of traditional assessments in higher education?
CSPhD-winston-杨帆
智慧教育论文翻译chatgpt
ChatGPT:Bullshitspewerortheendoftraditionalassessmentsinhighereducation?https://journals.sfu.ca/jalt/index.php/jalt/article/download/689/539/3059文章目录ChatGPT:废话制造者还是传统高等教育评估的终结者?摘要引言ChatGPT的功能ChatGPT对教
- 2025年第二届机器学习与神经网络国际学术会议(MLNN 2025)
分享学术科研与论文的禁小默
机器学习神经网络人工智能
重要信息官网:www.icmlnn.org时间:2025年4月22-24日地点:中国-重庆简介2025年第二届机器学习与神经网络国际学术会议(MLNN2025)围绕学习系统与神经网络的核心理论、关键技术和应用展开讨论,涵盖深度学习、计算机视觉、自然语言处理、强化学习等多个子领域,通过特邀报告、主题演讲、海报展示等形式,展示相关领域的最新研究成果和技术创新。征稿主题神经网络机器学习深度学习算法及应用
- 别只会用别人的模型了,自学Ai大模型,顺序千万不要搞反了!刚入门的小白必备!
鸡腿爱学习
人工智能学习自然语言处理服务器数据库
大家好,我是JackBytes,一个专注于将人工智能应用于日常生活的半吊子程序猿,平时主要分享AI、NAS、Docker、搞机技巧、开源项目等。在使用诸如DeepSeek、ChatGPT、豆包、文心一言等大模型之余,你是否知道这些大模型背后的技术原理是什么?假如让你从头开始学习大模型,你知道应该遵循什么样的路线嘛?今天给大家介绍一下Ai大模型的学习路线,顺序千万不要搞反了!,大家可以按照这个路线进
- BT-Basic函数之首字母O
可可南木
BT-Basic函数大全开发语言测试工具pcb工艺
BT-Basic函数之首字母O文章目录BT-Basic函数之首字母Oobjectcheckingoffbreakofferrorononbreakonerroroperatoroptionbitoroutputoutputusingobjectchecking在测试计划中使用objectchecking函数来开启或关闭对象检查。当对象检查开启时,每次运行测试时都会检查测试对象文件的时间戳,以确定对
- Docker搭建开源Web云桌面操作系统Puter和DaedalOS
没刮胡子
Linux服务器技术Linux1024程序员节puter云桌面云桌面操作系统daedalOSweb操作系统
文章目录Puter操作系统说明基于Docker启动Puter操作系统拉取镜像运行容器基于Docker-Compose启动Puter操作系统创建目录编写docker-compose.yml运行在本地直接运行puter操作系统puter界面截图puter个人使用总结构建自己的Puter镜像daedalos基于web的操作系统说明技术特点核心功能使用场景基于docker运行daedalos拉取镜像运行容
- 深度学习--概率
fantasy_arch
深度学习人工智能
1基本概率论1.1假设我们掷骰子,想知道1而不是看到另一个数字的概率,如果骰子是公司,那么所有6个结果(1..6),都有相同的可能发生,因此,我们可以说1发生的概率为1/6.然而现实生活中,对于我们从工厂收到的真实骰子,我们需要检查它是否有瑕疵,唯一的办法就是多投掷骰子,对于每个骰子观察到的[1.2...6]的概率随着投掷次数的增加,越来越接近1/6.导入必要的包%matplotlibinline
- 国内外的网络安全成难题,IPLOOK 2022年用产品筑起“护城墙”
爱浦路 IPLOOK
网络安全安全架构
《爱尔兰时报》和爱尔兰国家广播电台(RTE)于12月31日对2021年爱尔兰科技行业的赢家和弱点进行了年终盘点。双方纷纷表示,2021年爱尔兰科技行业最大的弱点是爱尔兰的网络安全,这一年是一场前所未有的灾难。随着人工智能、大数据、5G等新兴技术的发展,企业面临的威胁日益增加,信息安全的重要性变得越来越突显。现在我们把视线从爱尔兰的网络安全问题拉回到国内的网络安全现状。我国对网络安全问题保持时刻警惕
- 2-Spring-基于xml配置bean
技不如人,甘拜下风
javaspringspringxmljava
Spring-基于xml配置bean文章目录Spring-基于xml配置bean一.Bean实例化的4种方式1.1无参数构造方法(开发最常用)1.2静态工厂方法1.3实例工厂方法1.4FactoryBean方式(Spring底层使用较多)1.5FactoryBean与BeanFactory区别二.Bean相关知识2.1Bean的作用域2.2Bean的生命周期2.3Bean的属性注入2.3.1构造方
- Operating System Concepts读书笔记——操作系统本质、类型与发展【1】
墨汁儿
操作系统
文章目录一、操作系统基础概念1.操作系统功能2.计算机系统组成部分3.用户角度对操作系统的需求4.系统角度二、各类型操作系统1.大型机系统1.1批处理系统1.2多道程序系统1.3分时系统2.桌面系统3.多处理器系统4.分布式系统4.1客户机-服务器系统4.2对等系统5.集群系统6.实时系统7.手持系统三、其它1.功能迁移2.计算环境2.1传统计算2.2基于Web的计算2.3嵌入式计算一、操作系统基
- 《Java开发者必备:jstat、jmap、jstack实战指南》 ——从零掌握JVM监控三剑客
admin_Single
javajvm开发语言
《Java开发者必备:jstat、jmap、jstack实战指南》——从零掌握JVM监控三剑客文章目录**《Java开发者必备:jstat、jmap、jstack实战指南》**@[toc]**摘要****核心工具与场景****关键实践****诊断流程****工具选型决策表****调优原则****未来趋势****第一章:GC基础:垃圾回收机制与监控的关系****1.1内存世界的"垃圾分类"——GC分
- 【BUAA S4 OS】Lab2 内存管理
Roisy++
OSBUAA笔记linux
文章目录指导书梳理内核程序启动物理内存管理链表宏虚拟内存管理两级页表结构访问内存与TLB重填EntryHi、EntryLo0、EntryLo1TLB相关指令TLB的维护时纪exam前准备提醒参数、宏、函数缩写对照地址相互转换相关从地址中获取信息函数作用Exam翻车分析题目理解出现偏差——理解错题意&以为实现了自映射机制【疑问】页表在虚拟内存中不应该是连续的吗,这样怎么保证其连续性?【延伸】页表到底
- 深度讨论Python for循环
观智能
python开发语言
作者的其他文章推荐:强化学习再受关注!for循环使用于遍历可迭代对象的Python语句,工作原理如下:#for循环foriteminiterable:print(item)#等价于iterator=iter(iterable)#获取迭代器whileTrue:try:item=next(iterator)#获取下一个元素print(item)exceptStopIteration:break#迭代结
- Ubuntu & Debian 系统下挂载 Samba 共享目录的完整指南
YiYueHuan
ubuntudebianlinuxSambaNAS
文章目录Ubuntu&Debian系统下挂载Samba共享目录的完整指南前提条件挂载Samba共享临时挂载避免明文密码永久挂载常见选项卸载故障排查Ubuntu&Debian系统下挂载Samba共享目录的完整指南想把NAS中的内容通过Samba挂载到OrangePi5B,但是OrangePi5B提供的内核默认是没有开启CONFIG_CIFS的,所以就整理了一下。在Ubuntu/Debian系统上挂载
- 业务7——数据埋点
嚯嚯嚯嚯什么都不会
业务数据分析
文章目录一、数据生命周期:二、埋点是什么?1、含义2、方式三、埋点流程1、埋点生命周期2、业务需求分析3、埋点文档设计一、数据生命周期:还能从数据角度来看,数据在工作中的参与环节,帮助理清数据分析流程和思路。二、埋点是什么?1、含义数据埋点是数据采集的一种重要方式,是在有需要的位置采集相应的信息,主要是终端用户的操作行为,后续用于解决业务方提出的业务需求。2、方式全埋点代码埋点(百度统计、友盟、T
- macOS 使用 enca 识别 文件编码类型(比 file 命令准确)
知识搬运bot
软件工具/使用技巧macosencafileiconv文件编码
文章目录macOS上安装enca基本使用起因-iconv关于enca安装Encaenca&enconv其它用法macOS上安装encabrewinstallenca基本使用encafilepath.txt示例$enca动态规划算法.txt[0]SimplifiedChineseNationalStandard;GB2312CRLFlineterminators起因-iconv在macOS上打开一些
- STM32F1基于HAL库的学习记录实用使用教程分享(五、PWM驱动舵机、呼吸灯)
藤樂.
STM32学习stm32学习数据库
往期内容STM32F1基于HAL库的学习记录实用使用教程分享(一、GPIO_Output)STM32F1基于HAL库的学习记录实用使用教程分享(二、GPIO_Input按键)STM32F1基于HAL库的学习记录实用使用教程分享(三、外部中断按键)STM32F1基于HAL库的学习记录实用使用教程分享(四、OLEDIIC驱动软件IIC硬件IIC)文章目录往期内容前言一、PWMPWM如何控制LED亮度?
- 交换机救命命令手册:华为 & 思科平台最全运维指令速查表
IT程序媛-桃子
数通华为认证服务器运维
引言:这是一份救命的交换机运维秘籍在交换机配置与故障排查过程中,不论你是初入网络世界的小白,还是年资数年的资深工程师,总会遇到那些“关键时刻靠得住的命令”。这篇文章,我将整理一份覆盖华为+思科双平台的实战命令手册,从最基础的设备状态查看,到VLAN、STP、防环、LACP、QOS、抓包、限速、安全加固等操作,通通囊括。关键时刻,拿来即用,就是这篇的全部意义。01️⃣基础生存命令:先活下来再说场景华
- 利用AI与MySQL提升工业物联网健康监测的智慧水平——构建预测性维护的新纪元
墨夶
数据库学习资料1人工智能mysql物联网
在工业4.0和智能制造的大背景下,如何确保生产设备的高效稳定运行成为企业竞争力的核心要素之一。传统的事后维修方式已经难以满足现代制造业的需求,而基于人工智能(AI)的预测性维护系统则为这一挑战提供了全新的解决方案。今天,我们将深入探讨如何结合AI技术和MySQL数据库,打造一个智能、高效的工业物联网(IIoT)健康监测平台,助力企业在激烈的市场竞争中脱颖而出。一、为什么选择AI+MySQL?1.A
- springCloud集成tdengine(原生和mapper方式) 其二 原生篇
张小娟
springcloudtdenginespring
mapper篇请看另一篇文章一、引入pom文件com.taosdata.jdbctaos-jdbcdriver3.5.3二、在nacos中填写数据库各种value值tdengine:datasource:location:yourLocationusername:rootpassword:yourPassword三、编写TDengineUtil文件下方util文件里面,包含创建database的方
- 解决前后端分离跨域产生的session丢失问题
luckilyil
BUGjavaservlet
目录前言存储用户信息的方式Cookies:Token(令牌):LocalStorage/SessionStorage:Session:Redis:OAuth/OIDC:本篇文章主要讲使用session会话来存储信息会话机制1.何为一次会话,会话从什么时候开始,从什么时候结束?2.cookies如何保持会话,它的工作流程?3.什么是Session?Session的工作原理:问题出现解决方法总结前言现
- 31天Python入门——第11天:挑战一口气把闭包·装饰器讲明白
安然无虞
Python手把手教程python开发语言后端pyqt
你好,我是安然无虞。文章目录1.闭包扩展知识:闭包的自由变量是如何存储的2.装饰器装饰器的应用场景3.补充练习1.闭包闭包是指在一个函数内部定义的函数,并且这个内部函数可以访问外部函数的变量、参数.换句话说,闭包是一个包含了函数及其相关引用环境的组合体.在Python中,当一个函数返回了内部函数的引用时,这个内部函数可以访问并操作外部函数的局部变量,它就创建了一个闭包,即使外部函数已经执行完毕,它
- Open3D 点云DBSCAN聚类算法
MelaCandy
算法聚类numpy计算机视觉图像处理3d
目录一、DBSCAN基本原理二、代码实现2.1关键函数2.2完整代码三、实现效果3.1原始点云3.2聚类后点云Open3D点云算法汇总及实战案例汇总的目录地址:Open3D点云算法与点云深度学习案例汇总(长期更新)-CSDN博客一、DBSCAN基本原理DBSCAN(Density-BasedSpatialClusteringofApplicationswithNoise)是一种基于密度的聚类算法,
- 庖丁解java(一篇文章学java)
庖丁解java
java开发语言springboot后端
(大家不用收藏这篇文章,因为这篇文章会经常更新,也就是删除后重发)一篇文章学java,这是我滴一个执念...当然,真一篇文章就写完java基础,java架构,java业务实现,java业务扩展,根本不可能.所以,这篇文章,就是一个索引,索什么呢?请看下文...关于决定开始写博文的介绍(一切故事的起点源于这一次反省)中小技术公司的软扩展(微服务扩展是否有必要?)-CSDN博客SpringCloud(
- 【传输层协议】TCP协议详解(上)
望舒_233
Linux网络tcp/ip网络服务器
前言TCP(TransmissionControlProtocol,传输控制协议)是TCP/IP协议栈中的核心协议,作为互联网通信的基石,承担着确保数据可靠传输的重要职责。接下来我将分两篇文章,从四个部分带大家学习一些与TCP相关的基本概念和机制,首先我将带大家认识一下TCP报头字段的含义,然后了解TCP保证可靠性的一些机制,接下来是TCP进行效率优化的机制,最后是TCP与应用层相关的概念。本篇文
- 我与DeepSeek读《大型网站技术架构》- 总结
诺亚凹凸曼
架构
文章目录读后感一、总结二、反思三、创新四、展望当代大型网站架构一、架构分层模型二、关键组件与技术选型三、架构演进策略四、架构突破口读后感一、总结架构演化优先于设计大型网站架构不是预先设计的产物,而是通过反复迭代和试错演化形成的。技术选型的核心动机是对业务需求的深刻理解,而非盲目模仿。典型案例包括淘宝架构因业务爆发力被迫转型为分布式系统。开放与协作的价值互联网的开放生态通过API经济(如淘宝Open
- ASM系列五 利用TreeApi 解析生成Class
lijingyao8206
ASM字节码动态生成ClassNodeTreeAPI
前面CoreApi的介绍部分基本涵盖了ASMCore包下面的主要API及功能,其中还有一部分关于MetaData的解析和生成就不再赘述。这篇开始介绍ASM另一部分主要的Api。TreeApi。这一部分源码是关联的asm-tree-5.0.4的版本。
在介绍前,先要知道一点, Tree工程的接口基本可以完
- 链表树——复合数据结构应用实例
bardo
数据结构树型结构表结构设计链表菜单排序
我们清楚:数据库设计中,表结构设计的好坏,直接影响程序的复杂度。所以,本文就无限级分类(目录)树与链表的复合在表设计中的应用进行探讨。当然,什么是树,什么是链表,这里不作介绍。有兴趣可以去看相关的教材。
需求简介:
经常遇到这样的需求,我们希望能将保存在数据库中的树结构能够按确定的顺序读出来。比如,多级菜单、组织结构、商品分类。更具体的,我们希望某个二级菜单在这一级别中就是第一个。虽然它是最后
- 为啥要用位运算代替取模呢
chenchao051
位运算哈希汇编
在hash中查找key的时候,经常会发现用&取代%,先看两段代码吧,
JDK6中的HashMap中的indexFor方法:
/**
* Returns index for hash code h.
*/
static int indexFor(int h, int length) {
- 最近的情况
麦田的设计者
生活感悟计划软考想
今天是2015年4月27号
整理一下最近的思绪以及要完成的任务
1、最近在驾校科目二练车,每周四天,练三周。其实做什么都要用心,追求合理的途径解决。为
- PHP去掉字符串中最后一个字符的方法
IT独行者
PHP字符串
今天在PHP项目开发中遇到一个需求,去掉字符串中的最后一个字符 原字符串1,2,3,4,5,6, 去掉最后一个字符",",最终结果为1,2,3,4,5,6 代码如下:
$str = "1,2,3,4,5,6,";
$newstr = substr($str,0,strlen($str)-1);
echo $newstr;
- hadoop在linux上单机安装过程
_wy_
linuxhadoop
1、安装JDK
jdk版本最好是1.6以上,可以使用执行命令java -version查看当前JAVA版本号,如果报命令不存在或版本比较低,则需要安装一个高版本的JDK,并在/etc/profile的文件末尾,根据本机JDK实际的安装位置加上以下几行:
export JAVA_HOME=/usr/java/jdk1.7.0_25
- JAVA进阶----分布式事务的一种简单处理方法
无量
多系统交互分布式事务
每个方法都是原子操作:
提供第三方服务的系统,要同时提供执行方法和对应的回滚方法
A系统调用B,C,D系统完成分布式事务
=========执行开始========
A.aa();
try {
B.bb();
} catch(Exception e) {
A.rollbackAa();
}
try {
C.cc();
} catch(Excep
- 安墨移动广 告:移动DSP厚积薄发 引领未来广 告业发展命脉
矮蛋蛋
hadoop互联网
“谁掌握了强大的DSP技术,谁将引领未来的广 告行业发展命脉。”2014年,移动广 告行业的热点非移动DSP莫属。各个圈子都在纷纷谈论,认为移动DSP是行业突破点,一时间许多移动广 告联盟风起云涌,竞相推出专属移动DSP产品。
到底什么是移动DSP呢?
DSP(Demand-SidePlatform),就是需求方平台,为解决广 告主投放的各种需求,真正实现人群定位的精准广
- myelipse设置
alafqq
IP
在一个项目的完整的生命周期中,其维护费用,往往是其开发费用的数倍。因此项目的可维护性、可复用性是衡量一个项目好坏的关键。而注释则是可维护性中必不可少的一环。
注释模板导入步骤
安装方法:
打开eclipse/myeclipse
选择 window-->Preferences-->JAVA-->Code-->Code
- java数组
百合不是茶
java数组
java数组的 声明 创建 初始化; java支持C语言
数组中的每个数都有唯一的一个下标
一维数组的定义 声明: int[] a = new int[3];声明数组中有三个数int[3]
int[] a 中有三个数,下标从0开始,可以同过for来遍历数组中的数
- javascript读取表单数据
bijian1013
JavaScript
利用javascript读取表单数据,可以利用以下三种方法获取:
1、通过表单ID属性:var a = document.getElementByIdx_x_x("id");
2、通过表单名称属性:var b = document.getElementsByName("name");
3、直接通过表单名字获取:var c = form.content.
- 探索JUnit4扩展:使用Theory
bijian1013
javaJUnitTheory
理论机制(Theory)
一.为什么要引用理论机制(Theory)
当今软件开发中,测试驱动开发(TDD — Test-driven development)越发流行。为什么 TDD 会如此流行呢?因为它确实拥有很多优点,它允许开发人员通过简单的例子来指定和表明他们代码的行为意图。
TDD 的优点:
&nb
- [Spring Data Mongo一]Spring Mongo Template操作MongoDB
bit1129
template
什么是Spring Data Mongo
Spring Data MongoDB项目对访问MongoDB的Java客户端API进行了封装,这种封装类似于Spring封装Hibernate和JDBC而提供的HibernateTemplate和JDBCTemplate,主要能力包括
1. 封装客户端跟MongoDB的链接管理
2. 文档-对象映射,通过注解:@Document(collectio
- 【Kafka八】Zookeeper上关于Kafka的配置信息
bit1129
zookeeper
问题:
1. Kafka的哪些信息记录在Zookeeper中 2. Consumer Group消费的每个Partition的Offset信息存放在什么位置
3. Topic的每个Partition存放在哪个Broker上的信息存放在哪里
4. Producer跟Zookeeper究竟有没有关系?没有关系!!!
//consumers、config、brokers、cont
- java OOM内存异常的四种类型及异常与解决方案
ronin47
java OOM 内存异常
OOM异常的四种类型:
一: StackOverflowError :通常因为递归函数引起(死递归,递归太深)。-Xss 128k 一般够用。
二: out Of memory: PermGen Space:通常是动态类大多,比如web 服务器自动更新部署时引起。-Xmx
- java-实现链表反转-递归和非递归实现
bylijinnan
java
20120422更新:
对链表中部分节点进行反转操作,这些节点相隔k个:
0->1->2->3->4->5->6->7->8->9
k=2
8->1->6->3->4->5->2->7->0->9
注意1 3 5 7 9 位置是不变的。
解法:
将链表拆成两部分:
a.0-&
- Netty源码学习-DelimiterBasedFrameDecoder
bylijinnan
javanetty
看DelimiterBasedFrameDecoder的API,有举例:
接收到的ChannelBuffer如下:
+--------------+
| ABC\nDEF\r\n |
+--------------+
经过DelimiterBasedFrameDecoder(Delimiters.lineDelimiter())之后,得到:
+-----+----
- linux的一些命令 -查看cc攻击-网口ip统计等
hotsunshine
linux
Linux判断CC攻击命令详解
2011年12月23日 ⁄ 安全 ⁄ 暂无评论
查看所有80端口的连接数
netstat -nat|grep -i '80'|wc -l
对连接的IP按连接数量进行排序
netstat -ntu | awk '{print $5}' | cut -d: -f1 | sort | uniq -c | sort -n
查看TCP连接状态
n
- Spring获取SessionFactory
ctrain
sessionFactory
String sql = "select sysdate from dual";
WebApplicationContext wac = ContextLoader.getCurrentWebApplicationContext();
String[] names = wac.getBeanDefinitionNames();
for(int i=0; i&
- Hive几种导出数据方式
daizj
hive数据导出
Hive几种导出数据方式
1.拷贝文件
如果数据文件恰好是用户需要的格式,那么只需要拷贝文件或文件夹就可以。
hadoop fs –cp source_path target_path
2.导出到本地文件系统
--不能使用insert into local directory来导出数据,会报错
--只能使用
- 编程之美
dcj3sjt126com
编程PHP重构
我个人的 PHP 编程经验中,递归调用常常与静态变量使用。静态变量的含义可以参考 PHP 手册。希望下面的代码,会更有利于对递归以及静态变量的理解
header("Content-type: text/plain");
function static_function () {
static $i = 0;
if ($i++ < 1
- Android保存用户名和密码
dcj3sjt126com
android
转自:http://www.2cto.com/kf/201401/272336.html
我们不管在开发一个项目或者使用别人的项目,都有用户登录功能,为了让用户的体验效果更好,我们通常会做一个功能,叫做保存用户,这样做的目地就是为了让用户下一次再使用该程序不会重新输入用户名和密码,这里我使用3种方式来存储用户名和密码
1、通过普通 的txt文本存储
2、通过properties属性文件进行存
- Oracle 复习笔记之同义词
eksliang
Oracle 同义词Oracle synonym
转载请出自出处:http://eksliang.iteye.com/blog/2098861
1.什么是同义词
同义词是现有模式对象的一个别名。
概念性的东西,什么是模式呢?创建一个用户,就相应的创建了 一个模式。模式是指数据库对象,是对用户所创建的数据对象的总称。模式对象包括表、视图、索引、同义词、序列、过
- Ajax案例
gongmeitao
Ajaxjsp
数据库采用Sql Server2005
项目名称为:Ajax_Demo
1.com.demo.conn包
package com.demo.conn;
import java.sql.Connection;import java.sql.DriverManager;import java.sql.SQLException;
//获取数据库连接的类public class DBConnec
- ASP.NET中Request.RawUrl、Request.Url的区别
hvt
.netWebC#asp.nethovertree
如果访问的地址是:http://h.keleyi.com/guestbook/addmessage.aspx?key=hovertree%3C&n=myslider#zonemenu那么Request.Url.ToString() 的值是:http://h.keleyi.com/guestbook/addmessage.aspx?key=hovertree<&
- SVG 教程 (七)SVG 实例,SVG 参考手册
天梯梦
svg
SVG 实例 在线实例
下面的例子是把SVG代码直接嵌入到HTML代码中。
谷歌Chrome,火狐,Internet Explorer9,和Safari都支持。
注意:下面的例子将不会在Opera运行,即使Opera支持SVG - 它也不支持SVG在HTML代码中直接使用。 SVG 实例
SVG基本形状
一个圆
矩形
不透明矩形
一个矩形不透明2
一个带圆角矩
- 事务管理
luyulong
javaspring编程事务
事物管理
spring事物的好处
为不同的事物API提供了一致的编程模型
支持声明式事务管理
提供比大多数事务API更简单更易于使用的编程式事务管理API
整合spring的各种数据访问抽象
TransactionDefinition
定义了事务策略
int getIsolationLevel()得到当前事务的隔离级别
READ_COMMITTED
- 基础数据结构和算法十一:Red-black binary search tree
sunwinner
AlgorithmRed-black
The insertion algorithm for 2-3 trees just described is not difficult to understand; now, we will see that it is also not difficult to implement. We will consider a simple representation known
- centos同步时间
stunizhengjia
linux集群同步时间
做了集群,时间的同步就显得非常必要了。 以下是查到的如何做时间同步。 在CentOS 5不再区分客户端和服务器,只要配置了NTP,它就会提供NTP服务。 1)确认已经ntp程序包: # yum install ntp 2)配置时间源(默认就行,不需要修改) # vi /etc/ntp.conf server pool.ntp.o
- ITeye 9月技术图书有奖试读获奖名单公布
ITeye管理员
ITeye
ITeye携手博文视点举办的9月技术图书有奖试读活动已圆满结束,非常感谢广大用户对本次活动的关注与参与。 9月试读活动回顾:http://webmaster.iteye.com/blog/2118112本次技术图书试读活动的优秀奖获奖名单及相应作品如下(优秀文章有很多,但名额有限,没获奖并不代表不优秀):
《NFC:Arduino、Andro