【翻译】Neural Collaborative Filtering--神经协同过滤
【说明】
本文翻译自新加坡国立大学何向南博士 et al.发布在《World Wide Web》(2017)上的一篇论文《Neural Collaborative Filtering》。本人英语水平一般+学术知识匮乏+语文水平拙劣,翻译权当进一步理解论文和提高专业英语水平,translate不到key point还请见谅。
何博士的主页:http://www.comp.nus.edu.sg/~xiangnan/
本文原文:http://www.comp.nus.edu.sg/~xiangnan/papers/ncf.pdf
P.S. 何博士的论文一般都是paper+slide+code齐全,学习起来很方便
翻译过程中,不确定的词组都会附英文原文,另外自己的补充会用括号+倾斜加粗的形式给出,以助于理解。
【翻译正文】
神经协同过滤
摘要
近年来,深层神经网络在语音识别,计算机视觉和自然语言处理方面都取得了巨大的成功。然而相对的,对应用深层神经网络的推荐系统的探索却受到较少的关注。在这项工作中,我们力求开发一种基于神经网络的技术,来解决在含有隐形反馈的基础上进行推荐的关键问题————协同过滤。
尽管最近的一些工作已经把深度学习运用到了推荐中,但是他们主要是用它(深度学习)来对一些辅助信息(auxiliary information)建模,比如描述文字的项目和音乐的声学特征。当涉及到建模协同过滤的关键因素(key factor)————用户和项目(item)特征之间的交互的时候,他们仍然采用矩阵分解的方式,并将内积(inner product)做为用户和项目的潜在特征点乘。通过用神经结构代替内积这可以从数据中学习任意函数,据此我们提出一种通用框架,我们称它为NCF(Neural network-based Collaborative Filtering,基于神经网络的协同过滤)。NCF是一种通用的框架,它可以表达和推广矩阵分解。为了提升NFC的非线性建模能力,我们提出了使用多层感知机去学习用户-项目之间交互函数(interaction function)。在两个真实世界(real-world)数据集的广泛实验显示了我们提出的NCF框架对最先进的方法的显著改进。
关键字
协同过滤,神经网络,深度学习,矩阵分解,隐性反馈(Implicit Feedback).
1. 引言
在信息爆炸的时代,推荐系统在减轻信息过载方面发挥了巨大的作用,被众多在线服务,包括电子商务,网络新闻和社交媒体等广泛采用。个性化推荐系统的关键在于根据过去用户交互的内容(e.g. 评分,点击),对用户对项目的偏好进行建模,就是所谓的协同过滤[31,46]。在众多的协同过滤技术中,矩阵分解(MF)[14,21]是最受欢迎的,它将用户和项目映射到共享潜在空间(shared latent space),使用潜在特征向量(latent features),用以表示用户或项目。这样一来,用户在项目上的交互就被建模为它们潜在向量之间的内积。
由于Netflix Prize的普及,MF已经成为了潜在因素(latent factor)建模推荐的默认方法。已经有大量的工作致力于增强MF(的性能),例如将其与基于邻居(相邻用户or项目)的模型集成[21],与项目内容的主题模型[38]相结合,还有将其扩展到因式分解机(factorization machines)[26],以实现特征的通用建模。尽管MF对协同过滤有效,但众所周知,其性能可以被简单选择交互函数(内积)所阻碍。例如,对于显式反馈的评估预测任务,可以通过将用户和项目偏移项纳入交互函数来改善MF模型的性能1。虽然内积算子[14]似乎只是一个微不足道的调整,但它指出了设计一个更好的专用交互函数,用于建模用户和项目之间的潜在特征交互的积极效果。简单地将潜在特征的乘积线性组合的内积可能不足以捕捉用户交互数据的复杂结构。
1http://alex.smola.org/teaching/berkeley2012/slides/8_Recommender.pdf
本文探讨了使用深层神经网络来学习数据的交互函数,而不是那些以前已经完成的手动工作(handcraft)[18,21]。神经网络已经被证明有拟合任何连续函数的能力[17],最近深层神经网络(DNN)被发掘出在几个领域的出色表现:从计算机视觉,语音识别到文本处理[5,10,15,47]。然而,与广泛的MF方法文献相比,使用DNNs进行推荐的工作相对较少。虽然最近的一些研究进展[37,38,45]已经将DNN应用于推荐任务,并展示出不错的效果,但他们大多使用DNN来建模一些辅助信息,例如物品的文字描述,音乐的音频特征和图像的视觉内容(描述)。对于影响建模效果的关键因素——协同过滤,他们仍然采用MF,使用内积结合用户和项目潜在特征。
我们这项工作是通过形式化用于协同过滤的神经网络建模方法来解决上述研究问题。我们专注于隐性反馈(implicit feedback),通过参考观看视频,购买产品和点击项目等间接反映用户偏好的行为。与显性反馈(explicit feedback)(i.e. 评级和评论)相比,隐性反馈可以自动跟踪,从而更容易为内容提供商所收集。但是,由于隐性反馈不能反映用户的满意度,并且负反馈(negative feedback)存在自然稀疏(natural scarcity)问题,使得这个问题更具挑战性。在本文中,我们探讨了如何利用DNN来模拟噪声隐性反馈信号的中心问题。
这项工作的主要贡献有如下几点:
1、我们提出了一种神经网络结构来模拟用户和项目的潜在特征,并设计了基于神经网络的协同过滤的通用框架NCF。
2、我们表明MF可以被解释为NCF的特例,并利用多层感知器来赋予NCF高水平的非线性建模能力。
3、我们对两个现实世界的数据集进行广泛的实验,以证明我们的NCF方法的有效性和对使用深度学习进行协作过滤的承诺。
2. 准备工作
我们首先把问题形式化,并讨论现有的隐性反馈协同过滤解决方案。然后,我们简要概括广泛使用的MF模型,重点指出使用内积所造成的对模型的限制。
2.1 学习隐性数据
令 M M 和 N N 分别表示用户和项目的数量。我们将从用户的隐性反馈得到的用户-项目交互矩阵 Y∈ℝM×N Y∈RM×N 定义为:
yui={1,if interaction(user u,item i)is observed;0,otherwise. (1)yui={0,otherwise.1,if interaction(user u,item i)is observed; (1)
这里 yui yui 为 1 表示用户 uu 和项目 ii 存在交互记录;然而这并不意味着 uu 真的喜欢 ii。同样的,值 0 也不是表明 uu 不喜欢 ii,也有可能是这个用户根本不知道有这个项目。这对隐性反馈的学习提出了挑战,因为它提供了关于用户偏好的噪声信号。虽然观察到的条目至少反映了用户对项目的兴趣,但是未查看的条目可能只是丢失数据,并且这其中存在自然稀疏的负反馈。
在隐性反馈上的推荐问题可以表达为估算矩阵 YY 中未观察到的条目的分数问题(这个分数被用来评估项目的排名)。基于模型的方法假定这些缺失的数据可以由底层模型生成(或者说描述)。形式上它可以被抽象为学习函数 ŷ ui=f(u,i|Θ)y^ui=f(u,i|Θ) ,其中 ŷ uiy^ui 表示交互 yui yui 的预测分数,ΘΘ 表示模型参数,ff 表示表示模型参数映射到预测分数的函数(我们把它称作交互函数)。
为了估计参数Θ,现有的方法一般是遵循机器学习范例,优化目标函数。在文献中最常用到两种损失函数:逐点损失[14,19](pointwise loss)和成对损失[27,33] (pairwise loss) 。由于显性反馈研究上丰富的工作的自然延伸[21,46],在逐点的学习方法上通常是遵循的回归模式,最小化 ŷ uiy^ui 及其目标值 yui yui 之间的均方误差。同时为了处理没有观察到的数据,他们要么将所有未观察到的条目视作负反馈,要么从没有观察到条目中抽样作为负反馈实例[14]。对于成对学习[27,44],做法是,观察到的条目应该比未观察到的那些条目的排名更高。因此,成对学习最大化观察项 ŷ uiy^ui 和未观察到的条目 ŷ uiy^ui 之间的空白,而不是减少 ŷ uiy^ui 和 yui yui 之间的损失误差。
更进一步,我们的NCF框架利用神经网络,参数化相互作用函数 ff,从而估计 ŷ uiy^ui。因此,它就很自然地同时支持点损失和成对损失。
2.2 矩阵分解
MF(Matrix Factorization)用一个潜在特征向量实值将每个用户和项目关联起来。令 pupu 和 qiqi 分别表示用户 uu 和项目 ii的潜在向量;MF评估相互作用 yui yui 作为 pupu 和 qiqi 的内积:
ŷ u,i=f(u,i|pu,qi)=pTuqi=∑Kk=1pukqik, (2)y^u,i=f(u,i|pu,qi)=puTqi=∑k=1Kpukqik, (2)
这里的 KK 表示潜在空间(latent space)的维度。正如我们所看到的,MF模型是用户和项目的潜在因素的双向互动,它假设潜在空间的每一维都是相互独立的并且用相同的权重将它们线性结合。因此,MF可视为潜在因素(latent factor)的线性模型。
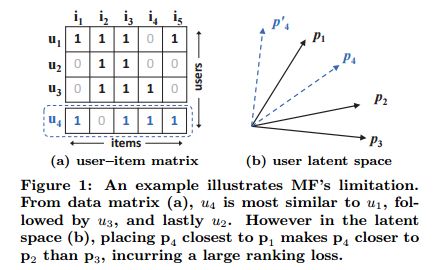
图1(Figure 1)展示了的内积函数(inner product function)如何限制MF的表现力。这里有两个背景必须事先说明清楚以便于更好地了解例子。第一点,由于MF将用户和项目映射到同一潜在空间中,两个用户之间的相似性也可以用内积,或者潜在向量之间的角度的余弦值来衡量2。第二点,不失一般性,我们使用Jaccard系数3作为MF需要恢复的两个用户的真实状况之间的相似度。
2假定潜在向量都是单位长度
3令 RuRu 表示与用户 uu 交互的项目集,那么用户 uu 和 jj 之间的Jaccard相似系数就被定义为:
sij=|Ri|∩|Rj||Ri|∪|Rj|sij=|Ri|∩|Rj||Ri|∪|Rj|
我们首先关注的图1(a)中的前三行(用户)。很容易可以计算出 s23(0.66)>s12(0.5)>s13(0.4)s23(0.66)>s12(0.5)>s13(0.4) 。这样,p1p1,p2p2 和 p3p3 在潜在空间中的几何关系可绘制成图1(b)。现在,让我们考虑一个新的用户 u4u4,它的输入在图1(a)中的用虚线框出。我们同样可以计算出 s41(0.6)>s43(0.4)>s42(0.2)s41(0.6)>s43(0.4)>s42(0.2) ,表示 u4u4 最接近 u1u1,接着是 u3u3 ,最后是 u2u2 。然而,如果MF模型将 p4p4 放在了 最接近 p1p1 的位置(图1(b) 中的虚线展示了两种不同的摆放 p4p4 的方式,结果一样),那么会使得 p4p4 相比与 p3p3 更接近于 p2p2 (显然,根据图1(a),u4u4 应该更接近 u3u3),这会导致很大的排名误差(ranking loss)。
上面的示例显示了MF因为使用一个简单的和固定的内积,来估计在低维潜在空间中用户-项目的复杂交互,从而所可能造成的限制。我们注意到,解决该问题的方法之一是使用大量的潜在因子 KK (就是潜在空间向量的维度)。然而这可能对模型的泛化能力产生不利的影响(e.g. 数据的过拟合问题),特别是在稀疏的集合上。在本文的工作中,我们通过使用DNNs从数据中学习交互函数,突破了这个限制。
3. 神经协同过滤
我们首先提出的总体框架NCF,阐述NCF如何学习强调了隐式数据的二进制属性的概率模型。然后,我们展示了,MF能够表达为NCF 的推广(MF矩阵分解模型是NCF的一个特例)。我们探索DNNs在协同过滤上的应用,提出了NCF的一个实例,它采用了多层感知器(MLP)来学习用户-项目交互函数。最后,我们在NCF框架下结合了MF和MLP,提出了一种新的神经矩阵分解模型(neural matrix factorization model);它统一了在建模用户项目潜在结构方面,MF的线性建模优势和MLP的非线性优势。
3.1 通用框架
为了允许神经网络对协同过滤进行一个完整的处理,我们采用图2(Figure 2)展示的多层感知机去模拟一个用户项目交互 yuiyui ,它的一层的输出作为下一层的输入。底部输入层包括两个特征向量 vUuvuU 和 vIiviI ,分别用来描述用户 uu 和项目 ii 。 他们可以进行定制,用以支持广泛的用户和项目的建模,例如上下文感知[28,1],基于内容[3],和基于邻居的构建方式[26]。由于本文工作的重点是纯的协同过滤模型设置,我们仅使用一个用户和一个项目作为输入特征,它使用one-hot编码将它们转化为二值化稀疏向量。注意到,我们对输入使用这样的通用特征表示,可以很容易地使用的内容特征来表示用户和项目,以调整解决冷启动问题。

输入层上面是嵌入层(Embedding Layer);它是一个全连接层,用来将输入层的稀疏表示映射为一个稠密向量(dense vector)。所获得的用户(项目)的嵌入(就是一个稠密向量)可以被看作是在潜在因素模型的上下文中用于描述用户(项目)的潜在向量。然后我们将用户嵌入和项目嵌入送入多层神经网络结构,我们把这个结构称为神经协作过滤层,它将潜在向量映射为预测分数。NCF层的每一层可以被定制,用以发现用户-项目交互的某些潜在结构。最后一个隐含层 XX 的维度尺寸决定了模型的能力。最终输出层是预测分数 yˆuiy^ui ,训练通过最小化 yˆuiy^ui 和其目标值 yuiyui 之间逐点损失进行。我们注意到,另一种方式来训练模型是通过成对学习,如使用个性化贝叶斯排名[27]和基于余量的损失(margin-based)[33]。由于本文的重点是对神经网络建模部分,我们将使用成对学习训练NCF留给今后的工作。
当前我们制定的NCF预测模型如下:
yˆui=f(PTvUu,QTvIi|P,Q,Θf), (3)y^ui=f(PTvuU,QTviI|P,Q,Θf), (3)
其中 P∈ℝM×KP∈RM×K, Q∈ℝN×KQ∈RN×K,分别表示用户和项目的潜在因素矩阵;ΘjΘj 表示交互函数 ff 的模型参数。由于函数 ff 被定义为多层神经网络,它可以被定制为:
f(PTvUu,QTvIi)=ϕout(ϕX(...ϕ2(ϕ1(PTvUu,QTvIi))...)), (4)f(PTvuU,QTviI)=ϕout(ϕX(...ϕ2(ϕ1(PTvuU,QTviI))...)), (4)
其中 ϕoutϕout 和 ϕxϕx 分别表示为输出层和第 xx 个神经协作过滤(CF)层映射函数,总共有 XX 个神经协作过滤(CF)层。
3.1.1 NCF学习
学习模型参数,现有的逐点学习方法[14,39]主要运用均方误差(squared loss)进行回归:
Lsqr=∑(u,i)∈y∪y−wui(yui−yˆui)2, (5)Lsqr=∑(u,i)∈y∪y−wui(yui−y^ui)2, (5)
其中 yy 表示交互矩阵 YY 中观察到的条目(如对电影有明确的评分,评级), y−y− 表示消极实例(negative instances,可以将未观察的样本全体视为消极实例,或者采取抽样的方式标记为消极实例); wuiwui 是一个超参数,用来表示训练实例 (u,i)(u,i)的权重。虽然均方误差可以通过假设观测服从高斯分布[29]来作出解释,我们仍然指出,它不适合处理隐性数据(implicit data)。这是因为对于隐含数据来说,目标值 yuiyui 是二进制值1或0,表示 uu 是否与 ii 进行了互动。在下文中,我们提出了逐点学习NCF的概率学方法,特别注重隐性数据的二进制属性。
考虑到隐性反馈的一类性质,我们可以将 yuiyui 的值作为一个标签————1表示项目 ii 和用户 uu 相关,否则为0。这样一来预测分数 yˆuiy^ui 就代表了项目 ii 和用户 uu 相关的可能性大小。为了赋予NCF这样的概率解释,我们需要将网络输出限制到[0,1]的范围内,通过使用概率函数(e.g. 逻辑函数sigmoid或者probit函数)作为激活函数作用在输出层 ϕoutϕout ,我们可以很容易地实现数据压缩。经过以上设置后,我们这样定义似然函数:
p(y,y−|P,Q,Θf)=∏(u,i)∈yyˆui∏(u,i)∈y−(1−yˆui). (6)p(y,y−|P,Q,Θf)=∏(u,i)∈yy^ui∏(u,i)∈y−(1−y^ui). (6)
对似然函数取负对数,我们得到(负对数可以用来表示Loss函数,而且还能消除小数乘法的下溢出问题):
L=−∑(u,i)∈ylogyˆui−∑(u,i)∈y−log(1−yˆui)=∑(u,i)∈y∪y−yuilogyˆui+(1−yui)log(1−yˆui). (7)L=−∑(u,i)∈ylogy^ui−∑(u,i)∈y−log(1−y^ui)=∑(u,i)∈y∪y−yuilogy^ui+(1−yui)log(1−y^ui). (7)
这是NCF方法需要去最小化的目标函数,并且可以通过使用随机梯度下降(SGD)来进行训练优化。细心的读者可能发现了,这个函数和二类交叉熵损失函数(binary cross-entropy loss,又被成为log loss)是一样的。通过在NCF上使用这样一个概率处理(probabilistic treatment),我们把隐性反馈的推荐问题当做一个二分类问题来解决。由于分类用的交叉熵损失很少出现在有关推荐的文献中,我们将在这项工作中对它进行探讨,并在4.3节展示它的有效性。对于消极实例 y−y− ,我们在每次迭代均匀地从未观察到的相互作用中采样(作为消极实例)并且对照可观察到交互的数量,控制采样比率。虽然非均匀采样策略(例如,基于项目流行度进行采样[14,12])可能会进一步提高模型性能,我们将这方面的探索作为今后的工作。
3.2 广义矩阵分解
我们现在来证明MF是如何被解释为我们的NCF框架的一个特例。由于MF是推荐领域最流行的模型,并已在众多文献中被广泛的研究,复现它能证明NCF可以模拟大部分的分解模型[26]。由于输入层是用户(项目)ID中的一个one-hot encoding编码,所获得的嵌入向量可以被看作是用户(项目)的潜在向量。我们用 PTvUuPTvuU 表示用户的潜在向量 pupu ,QTvIiQTviI 表示项目的潜在向量 qiqi ,我们定义第一层神经CF层的映射函数为:
ϕ1(pu,qi)=pu⊙qi, (8)ϕ1(pu,qi)=pu⊙qi, (8)
其中 ⊙⊙ 表示向量的逐元素乘积。然后,我们将向量映射到输出层:
yˆui=aout(hT(pu⊙qi)), (9)y^ui=aout(hT(pu⊙qi)), (9)
其中 aoutaout 和 hh 分别表示输出层的激活函数和连接权。直观地讲,如果我们将 aoutaout 看做一个恒等函数, hh 权重全为1,显然这就是我们的MF模型。在NCF的框架下,MF可以很容易地被泛化和推广。例如,如果我们允许从没有一致性约束(uniform constraint)的数据中学习 hh ,则会形成MF的变体,它允许潜在维度的不同重要性(这句话不好翻译,原文放在这里For example, if we allow hh to be learnt from data without the uniform constraint, it will result in a variant of MF that allows varying importance of latent dimensions)。如果我们用一个非线性函数 aoutaout ,将进一步推广MF到非线性集合,使得模型比线性MF模型更具有表现力。在本文的工作中,我们在NCF下实现一个更一般化的MF,它使用Sigmoid函数 σ(x)=1/(1+e−x)σ(x)=1/(1+e−x) 作为激活函数,通过log loss(第3.1.1节)学习 hh 。我们称她为GMF(Generalized Matrix Factorization,广义矩阵分解)。
3.3 多层感知机(MLP)
由于NCF用两条路线来对用户和项目建模(图2中可以明显看出用户和项目两个输入),自然地,需要通过两个路线,把他们各自的特征连接结合起来。这种设计已经在多模态深度学习工作中[47,34]被广泛采用。然而,简单地对向量的连接不足以说明用户和项目之间的潜在特征,这对协同过滤建模来说是不够的。为了解决这个问题,我们提出在向量连接上增加隐藏层,使用标准的MLP(多层感知机)学习用户和项目潜在特征之间的相互作用。在这个意义上,我们可以赋予模型高水平的灵活性和非线性建模能力,而不是GMF(广义矩阵分解)那样的简单使用逐元素相乘的内积来描述用户和项目之间的潜在交互特征。更确切地说,我们的NCF框架下的MLP模型定义为:
z1=ϕ1(pu,qi)=[puqi]z1=ϕ1(pu,qi)=[puqi]
ϕ2(z1)=a2(WT2z1+b2),ϕ2(z1)=a2(W2Tz1+b2),
......
ϕL(zL−1)=aL(WTLzL−1+bL),ϕL(zL−1)=aL(WLTzL−1+bL),
yˆui=σ(hTϕL(zL−1)), (10)y^ui=σ(hTϕL(zL−1)), (10)
这里的 WxWx, bxbx 和 axax 分别表示 xx 层的感知机中的的权重矩阵,偏置向量(神经网络的神经元阈值)和激活函数。对于MLP层的激活函数,可以选择sigmoid,双曲正切(tanh)和ReLU,等等。我们分析一下每个函数:1)sigmoid函数将每个神经元的输出限制在(0,1),这有可能限制该模型的性能;并且它存在过饱和的问题,当输出接近1或者0的时候,神经元就会陷入停止学习的困境(这里应该指的是“早停的问题”)。2)虽然双曲正切是一个更好的选择,并已被广泛使用[6,44],但它只是在一定程度上缓和了sigmoid的问题,因为它可以被看作是sigmoid的缩放的版本(tanh(x/2)=2σ(x)−1tanh(x/2)=2σ(x)−1)。3)因此,我们选择ReLU,它更具生物合理性(biologically plausible),并且已经被证明不会导致过饱和[9];此外,它支持稀疏的激活(sparse activations),非常适合稀疏的数据,使模型不至于过拟合。我们的实验结果表明,ReLU的表现略好于双曲正切函数tanh和sigmoid。
至于网络结构的设计,一种常见的解决方案是设计一个塔式模型,其中,底层是最宽的,并且每个相继的层具有更少的神经元数量(如图2(Figure 2))。(设计这种结构的)前提是,通过在更高层使用少量的隐藏单元,它们可以从数据中学习到更多的抽象特征[10]。根据经验,我们搭建这样的塔结构:对于更高的层,相比于之前一层,缩减一半规模。
3.4 结合GMF和MLP
到目前为止,我们已经开发了NCF的两个实例:GMF,它应用了一个线性内核来模拟潜在的特征交互;MLP,使用非线性内核从数据中学习交互函数。接下来的问题是:我们如何能够在NCF框架下融合GMF和MLP,使他们能够相互强化,以更好地对复杂的用户-项目交互建模?
一个直接的解决方法是让GMF和MLP共享相同的嵌入层(Embedding Layer),然后再结合它们分别对相互作用的函数输出。这种方式和著名的神经网络张量(NTN,Neural Tensor Network)[33]有点相似。具体地说,对于结合GMF和单层MLP的模型可以公式化为:
yˆui=σ(hTa(pu⊙qi)+W[puqi]+b). (11)y^ui=σ(hTa(pu⊙qi)+W[puqi]+b). (11)
然而,共享GMF和MLP的嵌入层可能会限制融合模型的性能。例如,它意味着,GMF和MLP必须使用的大小相同的嵌入(embedding,这里指的应该是潜在向量维度,下面的embedding都被译为嵌入);对于数据集,两个模型的最佳嵌入尺寸差异很大,使得这种解决方案可能无法获得最佳的组合。

为了使得融合模型具有更大的灵活性,我们允许GMF和MLP学习独立的嵌入,并结合两种模型通过连接他们最后的隐层输出。图3(Figure 3)展示了我们的方案,公式如下:
ϕGMF=pGu⊙qGi,ϕMLP=aL(WTL(aL−1(...a2(WT2[pMuqMi]+b2)...))+bL),yˆui=σ(hT[ϕGMFϕMLP]), (12)ϕGMF=puG⊙qiG,ϕMLP=aL(WLT(aL−1(...a2(W2T[puMqiM]+b2)...))+bL),y^ui=σ(hT[ϕGMFϕMLP]), (12)
这里的 pGupuG 和 pMupuM 分别表示 GMF 部分和 MLP 部分的用户嵌入(user embedding);同样的,qGiqiG 和 qMiqiM 分别表示项目的嵌入。如之前所讨论的,我们使用ReLU作为 MLP层的激活功能。该模型结合MF的线性度和DNNs的非线性度,用以建模用户-项目之间的潜在结构。我们将这一模式称为“NeuMF”,简称神经矩阵分解(Neural Matrix Factorization)。该模型的每个模型参数都能使用标准反向传播(back-propagation)计算,由于空间限制这里就不再展开。
3.4.1 预训练
由于NeuMF的目标函数的非凸性,使得基于梯度的优化方法只能找到局部最优解(这也是训练一般神经网络所面临的问题)。研究表明,初始化(initialization)在深度学习模型的收敛性和性能的方面起到了重要的作用[7]。由于 NeuMF 是 GMF 和 MLP 的组合,我们建议使用 GMF 和 MLP 的预训练模型来初始化NeuMF。
我们首先训练随机初始化的 GMF 和 MLP 直到模型收敛。然后,我们用它们的模型参数初始化 NeuMF 相应部分的参数。唯一的调整是在输出层,在那里我们将两者用权重连接起来:
h←[αhGMF(1−α)hMLP], (13)h←[αhGMF(1−α)hMLP], (13)
这里 hGMFhGMF 和 hMLPhMLP 分别表示 GMF 和 MLP 模型预训练的 hh 向量; αα 是一个超参数,用来权衡两个预训练模型(的比重)。
对于从头开始训练的 GMF 和 MLP ,我们采用自适应矩估计(Adam,Adaptive Moment Estimation)[20],它通过对不频繁的参数进行频繁和更大幅度的更新来适应每个参数的学习速率。Adam方法在两种模型上的收敛速度都比普通SGD快,并缓解了调整学习率的痛苦。在将预先训练的参数输入NeuMF之后,我们用普通SGD而不是Adam进行优化。 这是因为Adam需要保存更新参数的动量信息(momentum information)。因为我们用预先训练的模型参数初始化NeuMF,并且放弃保存动量信息,不适合用基于动量的方法进一步优化NeuMF。
4. 实验
在本节中,我们指导实验的进行,用以回答以下研究问题:
RQ1RQ1 我们提出的NCF方法是否胜过 state-of-the-art 的隐性协同过滤方法?
RQ2RQ2 我们提出的优化框架(消极样本抽样的log loss)怎样为推荐任务服务?
RQ3RQ3 更深的隐藏单元是不是有助于对用户项目交互数据的学习?
接下来,我们首先介绍实验设置,其次是回答上述三个问题。
4.1 实验设置
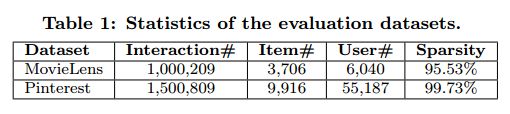
DatasetsDatasets。 我们尝试了两个可公开访问的数据集: MovieLens4 和 Pinterest5 两个数据集,它们的特征总结在表1中。
4http://grouplens.org/datasets/movielens/1m/
5https://sites.google.com/site/xueatalphabeta/ academic-projects
1.MovieLens1.MovieLens。 这个电影评级数据集被广泛地用于评估协同过滤算法。我们使用的是包含一百万个评分的版本,每个用户至少有20个评分。 虽然这是显性反馈数据集,但我们有意选择它来挖掘(模型)从显式反馈中学习隐性信号[21]的表现。为此,我们将其转换为隐式数据,其中每个条目被标记为0或1表示用户是否已对该项进行评级。
2.Pinterest2.Pinterest。这个隐含的反馈数据的构建[8]用于评估基于内容的图像推荐。原始数据非常大但是很稀疏。 例如,超过20%的用户只有一个pin(pin类似于赞一下),使得难以用来评估协同过滤算法。 因此,我们使用与MovieLens数据集相同的方式过滤数据集:仅保留至少有过20个pin的用户。处理后得到了包含55,187个用户和1,580,809个项目交互的数据的子集。 每个交互都表示用户是否将图像pin在自己的主页上。
评估方案。 为了评价项目推荐的性能,我们采用了leave-one-out方法评估,该方法已被广泛地应用于文献[1,14,27]。即:对于每个用户,我们将其最近的一次交互作为测试集(数据集一般都有时间戳),并利用余下的培训作为训练集。由于在评估过程中为每个用户排列所有项目花费的时间太多,所以遵循一般的策略[6,21],随机抽取100个不与用户进行交互的项目,将测试项目排列在这100个项目中。排名列表的性能由命中率(HR)和归一化折扣累积增益(NDCG)[11]来衡量。 没有特别说明的话,我们将这两个指标的排名列表截断为10。如此一来,HR直观地衡量测试项目是否存在于前10名列表中,而NDCG通过将较高分数指定为顶级排名来计算命中的位置。我们计算了每个测试用户的这两个指标,并求取了平均分。
基准线(Baselines)。我们NCF方法(GMF,MLP和NeuMF)和下列方法进行了比较:
−ItemPop−ItemPop。按项目的互动次数判断它的受欢迎程度,从而对项目进行排名。 这对基于评估推荐性能来说是一种非个性化的方法[27]。
−ItemKNN−ItemKNN[31]。这是基于项目的标准协同过滤方法。我们遵循[19]的设置来适应隐含数据。
−BPR−BPR[27]。该方法优化了使用公式(2)的MF模型,该模型具有成对排序损失,BPR调整它使其可以从隐式反馈中学习。它是项目推荐基准的有力竞争者。我们使用固定的学习率,改变它并报告了它最佳的性能。
−eALS−eALS[14]。这是项目推荐的 state-of-the-art 的MF方法。 它优化了公式(5)的均方误差,将所有未观察到的交互视作消极实例,并根据项目流行度对它们进行不均匀的加权。由于 eALS 显示出优于WMF[19]均匀加权方法的性能,我们不再进一步展示报告 WMF 的性能。
我们提出的方法旨在建模用户和项目之间的关系,我们主要比较用户-项目模型。因为性能差异可能是由个性化的用户模型引起的(因为它们是项目-项目模型),所以我们忽略了与项目-项目模型的比较,项目-项目模型有 SLIM[25] 和 CDAE[44]。
参数设置。我们基于Keras6实现了我们提出的方法。为了确定NCF方法的超参数,我们为每个用户随机抽取一个交互作为验证数据并调整其超参数。通过优化公式(7)的对数损失(log loss)来学习所有NCF模型,其中我们对每个积极实例进行四个消极实例的采样。对于从头开始训练的NCF模型,我们采用高斯分布随机初始化模型参数(平均值为0,标准差为0.01),用小批次Adam[20]优化模型。我们分别测试了批次大小[128,256,512,1024],学习速率为[0.0001,0.0005,0.001,0.005]。 由于NCF的最后一层隐藏层决定了模型的性能,所以我们将其作为预测因子(predictive factors),并分别使用[8,16,32,64]的因素大小进行了模型评估。值得注意的是,大的因子可能导致过拟合,降低性能。 没有特别说明,我们采用了三层隐藏的MLP; 例如,如果预测因子的大小为8,则神经CF层的结构为32→16→8,嵌入大小为16。对于预训练过的NeuMF,αα 设置为0.5,允许预训练的 GMF 和 MLP 对 NeuMF 的初始化做出同样的贡献(相同权重)。
4.2 性能比较(RQ1RQ1)
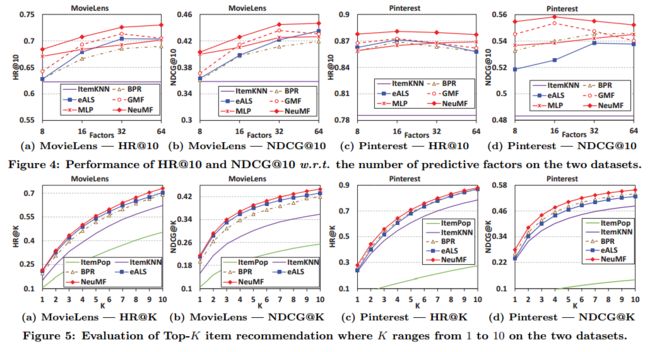
图4(Figure 4)显示了 HR@10 和 NDCG@10 相对于预测因素数量的性能。对于使用MF的方法BPR和eALS,预测因子的数量等于潜在因素的数量。对于ItemKNN,我们测试了不同的邻居大小并报告了最佳性能。由于ItemPop的性能较差,所以在图4中略去,以更好地凸显个性化方法的性能差异。
首先,我们可以看到,NeuMF在两个数据集上都取得了最好的表现,远远超过了最先进的方法eALS和BPR(平均而言,相对于eALS和BPR的相对改善分别为4.5%和4.9%) )。对于Pinterest而言,即使是8的小预测因子,NeuMF也远远优于在64维潜在因子下的eALS和BPR。这展现了NeuMF通过融合线性MF和非线性MLP模型的高水平的表达能力。其次,另外两种NCF方法:GMF和MLP,也表现出相当强劲的性能。其中,MLP略逊于GMF。请注意,MLP可以通过添加更多的隐藏层来进一步改进(参见第4.4节),这里我们只展示使用三层的性能。对于小数目的预测因子,GMF在两个数据集上都优于eALS;虽然GMF在高纬因子的情况下受到过拟合的影响,但其获得的最佳性能优于eALS(或差不多)。最后,GMF显示出与BPR一致的进步,说明了在推荐任务的分类问题中使用log loss的有效性,因为GMF和BPR学习相同的MF模型但具有不同的目标函数。
图5(Figure 5)显示了Top-K推荐列表的性能,排名位置K的范围为1到10。为了使图像更加清晰,我们仅仅展示了NeuMF的性能,而不是所有三种NCF方法。可以看出,NeuMF表现出与其他方法在位置上的一致性改进,我们进一步进行单样本配对的t检验,验证所有的改善对p <0.01有统计学意义(这里有点迷)。对于基准方法,eALS在MovieLens上的性能优于BPR大约5.1%,而在NDCG方面则逊于BPR。 这与[14]发现吻合,它指出:由于BPR学习和感知成对排名,它可能在排名上表现出强劲的性能。 基于相邻(用户或者项目)的ItemKNN表现则逊于基于模型的方法。 而ItemPop表现最差,表明用户对个人喜好的建模是必要的,而不是仅向用户推荐热门项目。
4.2.1 预训练的作用
为了展示NeuMF预训练的效果,我们比较了NeuMF两种版本的性能,并且没有预训练。 对于没有预训练的NeuMF,我们使用了Adam随机初始化。如表2所示,在大多数情况下,具有预训练的NeuMF表现出了更好的性能; 只有对于具有8的小预测因子的MovieLens,预训练方法执行稍差一些。 对于MovieLens和Pinterest,NeuMF与预训练的相对改进分别为2.2%和1.1%。 这个结果证明了我们的预训练方法对初始化NeuMF是有用的。

4.3 对消极采样使用Log Loss(RQ2RQ2)
为了处理隐性反馈的一类性质,我们将推荐作为一个二分类任务。我们将NCF视为概率模型,使用log loss对其进行了优化。图6(Figure 6)显示了NCF方法在MovieLens上每次迭代的训练损失(所有实例的平均值)和推荐性能。在Pinterest上的结果显示相同的趋势,由于空间限制而被省略。首先,我们可以看到,随着迭代次数的增多,NCF模型的训练损失逐渐减少,推荐性能得到提高。最有效的更新发生在前10次迭代中,更多的迭代可能使模型过拟合(例如,虽然NeuMF的训练损失在10次迭代之后持续下降,但其推荐性能实际上降低)。其次,在三种NCF方法中,NeuMF达到最低的训练损失,其次是MLP,然后是GMF。推荐性能也显示出与NeuMF> MLP> GMF相同的趋势。上述实验结果为优化从隐性数据学习的log loss的合理性和有效性提供了经验证据。
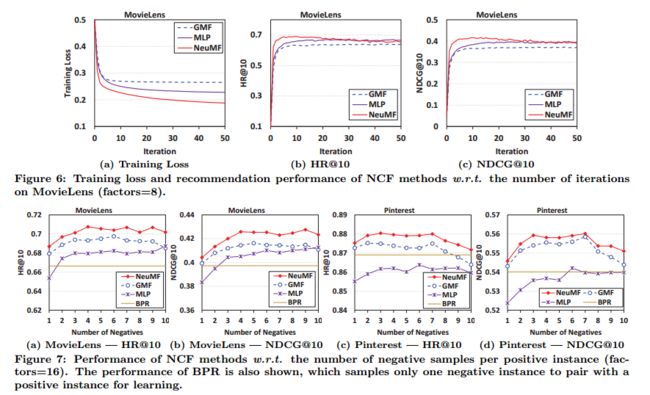
对于成对目标函数的逐点log loss(对数损失)的优势[27,33]是对于消极实例的灵活采样率。不像成对目标函数只能将一个采样消极实例与一个积极实例配对,逐点损失我们可以灵活地控制采样率。为了说明消极采样对NCF方法的影响,我们在不同的消极实例采样比下展示了NCF方法的性能。如图7所示。可以清楚地看到,每个积极实例只有一个消极实例不足以达到模型的最佳性能,而抽样更多的消极实例则是有益的。将GMF与BPR进行比较,我们可以看出,采样率为1成的GMF的性能与BPR相当,而GMF在采样率较高的情况下性能明显高于BPR。这表明了相较于成对BPR损失,逐点对数损失的优势所在。对于两个数据集,最佳采样率约为3比6。在Pinterest上,我们发现当采样率大于7时,NCF方法的性能开始下降。这说明,设置过大的采样率可能会对性能产生不利影响。
4.4 深度学习helpful?(RQ3RQ3)
由于使用神经网络学习用户-项目之间交互函数的工作很少,因此,使用深层网络结构是否有利于推荐任务是值得思考的。 为此,我们进一步研究了具有不同隐藏层数的MLP。 结果总结在表3和表4中。MLP-3表示具有三个隐藏层(除了嵌入层)的MLP方法,其他类似的符号具有相似的意义。 我们可以看到,即使具有相同能力的模型,堆叠更多的层也有利于性能的提升。 这个结果非常令人鼓舞,它表明使用深层模型进行协同推荐的有效性。 我们将性能提升归功于堆叠更多非线性层所带来的高非线性度。 为了验证这一点,我们进一步尝试堆叠线性层,使用恒等函数作为激活函数。 性能比使用ReLU单元差很多。
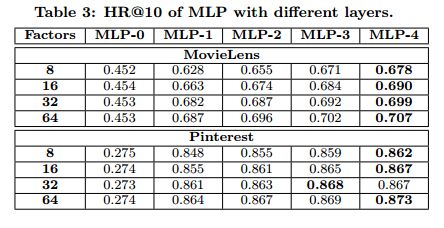

对于没有隐藏层(即,嵌入层直接映射到预测结果)的MLP-0,性能非常弱,不过比非个性化ItemPop更好。这验证了我们在3.3节中的观点:简单地连接用户和项目的潜在向量不足以对其特征的相互作用进行建模,因此需要使用隐藏层进行变换。
5. 相关工作
关于推荐的早期文献主要集中在显性反馈[30,31],而最近工作的重心越来越多地转向隐性数据[1,14,23]。具有隐性反馈的协同过滤(CF)任务通常被转化为项目推荐问题,其目的是向用户推荐一个简短的项目列表。 与被广泛采用的通过显性反馈进行评级预测相反,解决项目推荐的问题更具实践性,但同时也富有挑战性[1,11]。 一个关键的先验是对丢失的数据进行建模,这些数据在显式反馈的工作中常常被忽略[21,48]。为了建立具有隐性反馈的项目推荐的潜在因素模型,早期工作[19,27]使用均匀加权,其中提出了两种策略,即将所有缺失数据作为消极实例[19]或从缺失数据中抽样作为消极实例[27]。最近,He等[14]和Liang等人[23]提出了专门的模型来减少丢失的数据,而Rendle等人[1]为基于特征的因式分解模型开发了隐式坐标下降解法(iCD),实现了项目推荐的state-of-the-art。下面我们将讨论使用神经网络的推荐工作。
早期的先驱工作是由Salakhutdinov等人[30]提出的一种两层限制玻尔兹曼机(RBM)来模拟用户对项目的明确评级。这项工作后来被扩展到对等级的序数性质进行建模[36]。最近,自动编码器(autoencoders)已成为构建推荐系统的一般选择[32,22,35]。基于用户的AutoRec[32]的想法是学习隐藏的结构,根据用户的历史评级作为输入,可以重建用户的评分。在用户个性化方面,这种方法与项目-项目模型[31,25]具有相似之处,它表示用户作为其评分项目。为了避免自动编码器学习恒等函数,并且不能将其推广到不可观察的数据,它已经应用了去噪自动编码器(DAE)来学习人为损坏的输入[22,35]。最近,Zheng等人[48]提出了一种用于CF的神经自回归(neural autoregressive )方法。虽然以前的努力证明了神经网络解决CF的有效性,但大多数重点放在明确的评级上,并仅对观察到的数据进行建模。因此,他们不易于从只有积极样例的隐性数据中学习用户的偏好。
虽然最近的工作[6,37,38,43,45]已经探索了基于隐性反馈的深入学习模型,但它们主要使用DNN来建模辅助信息,例如文字描述[38],音乐的声学特征[37,43],用户的跨域行为[6]以及知识库中的丰富信息[45]。然后由MF和CF相结合DNN学习特征。与我们工作最相关的工作是[44],它为CF提供了一个隐性反馈的协同去噪自动编码器(CDAE)。与基于DAE的CF [35]相反,CDAE还将用户节点插入自动编码器的输入端,以重建用户的评级。如作者所展示的,当使用恒等函数作为激活函数作用在CDAE的隐藏层时,CDAE相当于SVD++模型[21]。这意味着虽然CDAE虽然是CF的神经建模方法,但是它仍然使用线性内核(即内积)来模拟用户-项目交互。这可能部分解释了为什么使用深层CDAE不会提高性能(参见[44]第6节)。与CDAE不同,我们的NCF采用双通道结构,建立多层前馈神经网络的模型模拟用户项目交互。这允许NCF从数据中学习任意函数,比固定内部函数有更强大的表达能力。
顺着相似的研究方向,学习两个实体的关系已经在知识图(knowledge graphs)的文献中得到了深入的研究[2,33]。 许多有关的机器学习方法[24]已经被设计出来。 与我们提出的方案最相似的是神经张量网络(NTN,Neural Tensor Network)[33],它使用神经网络来学习两个实体的相互作用并表现出很强劲的性能。这里我们专注于=它与CF的不同设置问题。 尽管将MF与MLP结合在一起的NeuMF的想法是受到了NTN的一定程度的启发,但是我们的NeuMF比NTN更灵活和通用,它允许MF和MLP学习不同的嵌入式组合。
最近,谷歌公布了他们的通用深度学习方法的App推荐[4]。 深层组件类似地使用特征嵌入的MLP,据称具有很强的泛化能力。 虽然他们的工作集中在结合用户和项目的各种特征,但我们的目标是使用DNN探索纯粹的协同过滤系统的。我们显示了对于建模用户-项目交互,DNN是一个有前途的选择,以前没有对此进行调查。
6. 总结和展望
在这项工作中,我们探索了用于协同过滤的神经网络结构。我们设计了一个通用框架NCF,并提出了三种实例:GMF,MLP和NeuMF,以不同的方式模拟用户-项目交互。我们的框架简单而通用; 它不仅限于本文提出的模型,它对深入学习推荐方法的也具有指导意义。这项工作补充了主流浅层协同过滤模型,为深入学习推荐研究开辟了新途径。
在将来的工作中,我们将研究NCF模型在成对学习中的应用,并将NCF扩展到建模辅助信息,如用户评论[11],知识库[45]和时间信号[1]。现有的个性化模式主要集中在个人身上,为用户群体开发模型将会是一个有趣的发展,这有助于社会团体的决策[15,42]。此外,我们特别感兴趣的是建立多媒体项目的推荐系统,这是一个有趣的任务,但在推荐社区中受到相对较少的关注[3]。多媒体项目(如图像和视频)包含更丰富的视觉语义[16,41],可以反映用户的兴趣。 要构建多媒体推荐系统,我们需要开发有效的方法来学习多视图和多模态数据[13,40]。 另一个新出现的方向是探索循环神经网络和散列方法(hashing methods)[46]的潜力,以提供有效的在线推荐[14]。
鸣谢
作者感谢匿名评审者的宝贵意见,给作者对推荐系统的思考和论文的修订提供了极大的帮助。
7. 参考文献
[1] I. Bayer, X. He, B. Kanagal, and S. Rendle. A generic coordinate descent framework for learning from implicit feedback. In WWW, 2017.
[2] A. Bordes, N. Usunier, A. Garcia-Duran, J. Weston, and O. Yakhnenko. Translating embeddings for modeling multi-relational data. In NIPS, pages 2787–2795, 2013.
[3] T. Chen, X. He, and M.-Y. Kan. Context-aware image tweet modelling and recommendation. In MM, pages 1018–1027, 2016.
[4] H.-T. Cheng, L.Koc, J. Harmsen, T. Shaked, T. Chandra, H. Aradhye, G. Anderson, G. Corrado, W. Chai, M. Ispir,et al. Wide & deep learning for recommender systems. arXiv preprint arXiv:1606.07792, 2016.
[5] R. Collobert and J. Weston. A unified architecture for natural language processing: Deep neural networks with multitask learning. In ICML, pages 160–167, 2008.
[6] A. M. Elkahky, Y. Song, and X. He. A multi-view deep learning approach for cross domain user modeling in recommendation systems. In WWW, pages 278–288, 2015.
[7] D. Erhan, Y. Bengio, A. Courville, P.-A. Manzagol, P. Vincent, and S. Bengio. Why does unsupervised pre-training help deep learning? Journal of Machine Learning Research, 11:625–660, 2010.
[8] X. Geng, H. Zhang, J. Bian, and T.-S. Chua. Learning image and user features for recommendation in social networks. In ICCV, pages 4274–4282, 2015.
[9] X. Glorot, A. Bordes, and Y. Bengio. Deep sparse rectifier neural networks. In AISTATS, pages 315–323, 2011.
[10] K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for image recognition. In CVPR, 2016.
[11] X. He, T. Chen, M.-Y. Kan, and X. Chen. TriRank: Review-aware explainable recommendation by modeling aspects. In CIKM, pages 1661–1670, 2015.
[12] X. He, M. Gao, M.-Y. Kan, Y. Liu, and K. Sugiyama. Predicting the popularity of web 2.0 items based on user comments. In SIGIR, pages 233–242, 2014.
[13] X. He, M.-Y. Kan, P. Xie, and X. Chen. Comment-based multi-view clustering of web 2.0 items. In WWW, pages 771–782, 2014.
[14] X. He, H. Zhang, M.-Y. Kan, and T.-S. Chua. Fast matrix factorization for online recommendation with implicit feedback. In SIGIR, pages 549–558, 2016.
[15] R. Hong, Z. Hu, L. Liu, M. Wang, S. Yan, and Q. Tian. Understanding blooming human groups in social networks. IEEE Transactions on Multimedia, 17(11):1980–1988, 2015.
[16] R. Hong, Y. Yang, M. Wang, and X. S. Hua. Learning visual semantic relationships for efficient visual retrieval. IEEE Transactions on Big Data, 1(4):152–161, 2015.
[17] K. Hornik, M. Stinchcombe, and H. White. Multilayer feedforward networks are universal approximators. Neural Networks, 2(5):359–366, 1989.
[18] L. Hu, A. Sun, and Y. Liu. Your neighbors affect your ratings: On geographical neighborhood influence to rating prediction. In SIGIR, pages 345– 354, 2014.
[19] Y. Hu, Y. Koren, and C. Volinsky. Collaborative filtering for implicit feedback datasets. In ICDM, pages 263–272, 2008.
[20] D. Kingma and J. Ba. Adam: A method for stochastic optimization. In ICLR, pages 1–15, 2014.
[21] Y. Koren. Factorization meets the neighborhood: A multifaceted collaborative filtering model. In KDD, pages 426–434, 2008.
[22] S. Li, J. Kawale, and Y. Fu. Deep collaborative filtering via marginalized denoising auto-encoder. In CIKM, pages 811–820, 2015.
[23] D. Liang, L. Charlin, J. McInerney, and D. M. Blei. Modeling user exposure in recommendation. In WWW, pages 951–961, 2016.
[24] M. Nickel, K. Murphy, V. Tresp, and E. Gabrilovich. A review of relational machine learning for knowledge graphs. Proceedings of the IEEE, 104:11– 33, 2016.
[25] X. Ning and G. Karypis. Slim: Sparse linear methods for top-n recommender systems. In ICDM, pages 497–506, 2011.
[26] S. Rendle.Factorization machines. In ICDM, pages 995–1000, 2010.
[27] S. Rendle, C. Freudenthaler, Z. Gantner, and L. Schmidt-Thieme. Bpr: Bayesian personalized ranking from implicit feedback. In UAI, pages 452– 461, 2009.
[28] S. Rendle, Z. Gantner, C. Freudenthaler, and L. Schmidt-Thieme. Fast context-aware recommendations with factorization machines. In SIGIR, pages 635–644, 2011.
[29] R. Salakhutdinov and A. Mnih. Probabilistic matrix factorization. In NIPS, pages 1–8, 2008.
[30] R. Salakhutdinov, A. Mnih, and G. Hinton. Restricted boltzmann machines for collaborative filtering. In ICDM, pages 791–798, 2007.
[31] B. Sarwar, G. Karypis, J. Konstan, and J. Riedl. Item-based collaborative filtering recommendation algorithms. In WWW, pages 285–295, 2001. [32] S. Sedhain, A. K. Menon, S. Sanner, and L. Xie. Autorec: Autoencoders meet collaborative filtering. In WWW, pages 111–112, 2015.
[33] R. Socher, D. Chen, C. D. Manning, and A. Ng. Reasoning with neural tensor networks for knowledge base completion. In NIPS, pages 926–934, 2013.
[34] N. Srivastava and R. R. Salakhutdinov. Multimodal learning with deep boltzmann machines. In NIPS, pages 2222–2230, 2012.
[35] F. Strub and J. Mary. Collaborative filtering with stacked denoising autoencoders and sparse inputs. In NIPS Workshop on Machine Learning for eCommerce, 2015.
[36] T. T. Truyen, D. Q. Phung, and S. Venkatesh. Ordinal boltzmann machines for collaborative filtering. In UAI, pages 548–556, 2009.
[37] A. Van den Oord, S. Dieleman, and B. Schrauwen. Deep content-based music recommendation. In NIPS, pages 2643–2651, 2013.
[38] H. Wang, N. Wang, and D.-Y. Yeung. Collaborative deep learning for recommender systems. In KDD, pages 1235–1244, 2015.
[39] M. Wang, W. Fu, S. Hao, D. Tao, and X. Wu. Scalable semi-supervised learning by efficient anchor graph regularization. IEEE Transactions on Knowledge and Data Engineering, 28(7):1864–1877, 2016.
[40] M. Wang, H. Li, D. Tao, K. Lu, and X. Wu. Multimodal graph-based reranking for web image search. IEEE Transactions on Image Processing, 21(11):4649–4661, 2012.
[41] M. Wang, X. Liu, and X. Wu. Visual classification by l1 hypergraph modeling. IEEE Transactions on Knowledge and Data Engineering, 27(9):2564– 2574, 2015.
[42] X. Wang, L. Nie, X. Song, D. Zhang, and T.-S. Chua. Unifying virtual and physical worlds: Learning towards local and global consistency. ACM Transactions on Information Systems, 2017.
[43] X. Wang and Y. Wang. Improving content-based and hybrid music recommendation using deep learning. In MM, pages 627–636, 2014.
[44] Y. Wu, C. DuBois, A. X. Zheng, and M. Ester. Collaborative denoising auto-encoders for top-n recommender systems. In WSDM, pages 153–162, 2016.
[45] F. Zhang, N. J. Yuan, D. Lian, X. Xie, and W.-Y. Ma. Collaborative knowledge base embedding for recommender systems. In KDD, pages 353–362, 2016.
[46] H. Zhang, F. Shen, W. Liu, X. He, H. Luan, and T.-S. Chua. Discrete collaborative filtering. In SIGIR, pages 325–334, 2016.
[47] H. Zhang, Y. Yang, H. Luan, S. Yang, and T.-S. Chua. Start from scratch: Towards automatically identifying, modeling, and naming visual attributes. In MM, pages 187–196, 2014.
[48] Y. Zheng, B. Tang, W. Ding, and H. Zhou. A neural autoregressive approach to collaborative filtering. In ICML, pages 764–773, 2016.
转自:https://www.cnblogs.com/HolyShine/p/6728999.html