[2022]李宏毅深度学习与机器学习第二讲(必修)听课笔记
[2022]李宏毅深度学习与机器学习第二讲(必修)听课笔记
- 做笔记的目的
- 机器学习的任务攻略
-
- 当在训练集上损失较大
- Train loss小但是test loss大
-
- 这里就出现了过拟合,应对过拟合的方法如下
- mismatch
- local minima 和 saddle point
-
- local minima VS saddle point
- Batch 和 monmentum
-
- Batch
- monmentum技术
- Adaptive Learning Rate
- 损失函数Loss
- 浅谈机器学习的原理——为什么参数越多越容易overfitting
-
- 发展趋势
- Deep Learning的三个步骤
- 反向传播
- 预测神奇宝贝CP,线性回归
-
-
- 模型改进
-
- 神奇宝贝的分类
-
- Generative Model
- Discriminative Model
- Discriminative Vs Generative
-
- Multi-class Classification
做笔记的目的
1、监督自己把50多个小时的视频看下去,所以每看一部分内容做一下笔记,我认为这是比较有意义的一件事情。
2、路漫漫其修远兮,学习是不断重复和积累的过程。怕自己看完视频不及时做笔记,学习效果不好,因此想着做笔记,提高学习效果。
3、因为刚刚入门深度学习,听课的过程中,理解难免有偏差,也希望各位大佬指正。
机器学习的任务攻略
李宏毅老师用比较有趣的方法给我们讲了如何进行模型的优化,仅仅围绕下图展开。
![[2022]李宏毅深度学习与机器学习第二讲(必修)听课笔记_第1张图片](http://img.e-com-net.com/image/info8/2316b5e575764314b2718f10e5bf2043.jpg)
当在训练集上损失较大
可能出现两个问题,第一个问题是模型很简单,或者是因为optimization的并不好。
解决模型简单的方法当然是把模型调复杂一点,如下图:
![[2022]李宏毅深度学习与机器学习第二讲(必修)听课笔记_第2张图片](http://img.e-com-net.com/image/info8/b64ed0cf30c14d0e925e42bfd7ed475d.jpg)
![[2022]李宏毅深度学习与机器学习第二讲(必修)听课笔记_第3张图片](http://img.e-com-net.com/image/info8/47b33497b3cd4626a3f262a84f51d10f.jpg)
当损失较大时如何判断遇到了什么问题,是一个问题,方法如下:
- 做比较,看看大的模型和小的模型哪个在训练资料上损失大。
![[2022]李宏毅深度学习与机器学习第二讲(必修)听课笔记_第4张图片](http://img.e-com-net.com/image/info8/c07a28a262b043a7a9f30d4087f67d44.jpg)
所以当作一个不太清楚的问题时,先从小的模型开始训练,小的模型可以更好的optimize。在尝试大的模型。因为复杂的模型弹性大,小的模型能达到的loss,大的模型理论上也能达到,如果大的模型比小的模型loss大,那么说明optimize没有做好。
Train loss小但是test loss大
这里就出现了过拟合,应对过拟合的方法如下
![[2022]李宏毅深度学习与机器学习第二讲(必修)听课笔记_第5张图片](http://img.e-com-net.com/image/info8/388daa12721d4b90931ba56ee36ecf65.jpg)
- 让模型变小;
- 减少特征数量;
- 提前结束训练
- 正则化技术,让模型变平缓
- Dropout
![[2022]李宏毅深度学习与机器学习第二讲(必修)听课笔记_第6张图片](http://img.e-com-net.com/image/info8/fa0f4856898648ffa776ac7e7dc732da.jpg)
如何选出这个比较好的model那?可以用N-fold cross validation 的方法,防止在训练集上比较不错,但是在测试集上不行。
![[2022]李宏毅深度学习与机器学习第二讲(必修)听课笔记_第7张图片](http://img.e-com-net.com/image/info8/307fa95a76ec4ce4af0da2576c124584.jpg)
这个是3-Fold cross的做法,选出平均mse最小的,然后交上去,可以在测试集上得到比较真是的结果。
mismatch
训练数据和测试数据有不同的分布,遇到这种情况后面会将
如何判断是mismatch还是overfitting需要靠个人的经验。
local minima 和 saddle point
![[2022]李宏毅深度学习与机器学习第二讲(必修)听课笔记_第8张图片](http://img.e-com-net.com/image/info8/331918451d654ddcaa1b65c82991da78.jpg)
当梯度为0时,可能找到了local minima或者在saddle point。所以如何判断是local minima还是saddle point那?可以用如下方法,这个方法很想泰勒公式,然后用极限的思想去判断正负号。
![[2022]李宏毅深度学习与机器学习第二讲(必修)听课笔记_第9张图片](http://img.e-com-net.com/image/info8/b85ee2689bfb47f9b0b4d5c15f187a39.jpg)
这里要计算H是什么,H是一个矩阵计算方法下图给出来了,就是算二阶导数。
![[2022]李宏毅深度学习与机器学习第二讲(必修)听课笔记_第10张图片](http://img.e-com-net.com/image/info8/17776705bab84c15abc91263ef51a46c.jpg)
当计算出H之后,如果是saddle point,那么可以用H来找到更新的方向,这里设计到了一些线性代数的知识点,截图如下:
![[2022]李宏毅深度学习与机器学习第二讲(必修)听课笔记_第11张图片](http://img.e-com-net.com/image/info8/5a5bb90eb20c497391ccb5410773c0f0.jpg)
但是在实际运用上一般不会把H给算出来,因为H的计算量比较大。
local minima VS saddle point
![[2022]李宏毅深度学习与机器学习第二讲(必修)听课笔记_第12张图片](http://img.e-com-net.com/image/info8/63a24673e126459fa1c6ec6b5b9fcb96.jpg)
从图中可以看出,在低维空间,是local minima在高维空间可能是saddle point。现在的模型参数很多,所以一般saddle point更加常见。在实验的时候其实验证了这个观点。
Batch 和 monmentum
Batch
什么是batch?如下图,每个batch更新一次参数。在batch的时候经常需要shuffle,shuffle的一种方法是每次epoch都重新划分batch。
![[2022]李宏毅深度学习与机器学习第二讲(必修)听课笔记_第13张图片](http://img.e-com-net.com/image/info8/085fd46b2e304643a3826d4541506fa7.jpg)
为什么需要batch那?
![[2022]李宏毅深度学习与机器学习第二讲(必修)听课笔记_第14张图片](http://img.e-com-net.com/image/info8/969f9e9718ad4140824ff19c2ea4e36f.jpg)
大的batch更新的尺度大,方向更加正确,每步走的更加稳;小的batch,是在不断探索,有很多可能性,所以更有可能走到最优解。一般认为大的batch时间长,其实并不是,因为是并行运算,所以其实在一定范围内计算的时间是差不多的。
![[2022]李宏毅深度学习与机器学习第二讲(必修)听课笔记_第15张图片](http://img.e-com-net.com/image/info8/f4a18c6d363d465394bcab994c1a6dfb.jpg)
在实验里小的batch在train里表现得更好,同时当train效果一样时,小的batch在test里面效果更好,如下图。
![[2022]李宏毅深度学习与机器学习第二讲(必修)听课笔记_第16张图片](http://img.e-com-net.com/image/info8/037c22e16c4c461b9d02f0e8590d0b76.jpg)
为什么小的batch更好那?
![[2022]李宏毅深度学习与机器学习第二讲(必修)听课笔记_第17张图片](http://img.e-com-net.com/image/info8/a9230e9a4d274d80b6bfcd2258cfd41c.jpg)
首先平滑的minima比峡谷里的minima更好,因为当test上的分布有一些不同时,平滑的minima结果不会差很多,但是狭窄的minima结果就会比较差,而小的batch更容易走到平滑的minima。 之后我看了一篇博客?深度学习中的batch的大小对学习效果有何影响?可以总结为一下几点:
- LB过度拟合模型
- LB更容易陷入鞍点
- LB缺少SB的随机探索性,更依赖于初始值,容易陷入初始点周围的最小值,而SB可以探索到离初始点更远的最小值
- LB和SB收敛到具有不同泛化特性的最小化点
因此,batch_size是有一个阙值的,一旦超过这个阙值,模型性能就会退化。通俗解释一下,大的batch_size本质上是对训练数据更优的一种选择,但是同时也会限制模型的探索能力,模型训练的时候极易陷入这种很尖的极小值很难跳脱出来,但是相对小一些的batch_size就很容易能检索到一个非常好的极小值点。
monmentum技术
![[2022]李宏毅深度学习与机器学习第二讲(必修)听课笔记_第18张图片](http://img.e-com-net.com/image/info8/54e4d6a02a10432f87e72b8b0a6f43c6.jpg)
如果有动量也就是update的方向也受上一次update的方向的影响。那么可能能跳出局部最优解。具体做法如下:
![[2022]李宏毅深度学习与机器学习第二讲(必修)听课笔记_第19张图片](http://img.e-com-net.com/image/info8/48247d1c7d504f2a98d7c47b077d5ffd.jpg)
Adaptive Learning Rate
在训练的时候loss下降到一定数值后,可能就不在下降了,这个时候一般认为gradient比较小,但是实时并不是这样,可能此时gradient任然比较大,但是在峡谷两边震荡。
![[2022]李宏毅深度学习与机器学习第二讲(必修)听课笔记_第20张图片](http://img.e-com-net.com/image/info8/bb8cdace070b480c8677e80679746992.jpg)
按照经验,在平缓的地方learn rate要大一点,而在狭窄的时候,learn rate要小,所以进行一个改进,如下图:
![[2022]李宏毅深度学习与机器学习第二讲(必修)听课笔记_第21张图片](http://img.e-com-net.com/image/info8/0f42945459394812860b58cb3d58beb8.jpg)
一种方法Adagrad,具体步骤如下,这样就实现了陡峭的地方learn rate 小,平坦的地方learn rate 大。因为当平缓时gradient比较小,所以 σ i t \sigma_i^t σit也比较小,所以最终比较大,反过来狭窄时,一样的理解。
![[2022]李宏毅深度学习与机器学习第二讲(必修)听课笔记_第22张图片](http://img.e-com-net.com/image/info8/d974b9eb993e435687b99bd56dbd82fb.jpg)
![[2022]李宏毅深度学习与机器学习第二讲(必修)听课笔记_第23张图片](http://img.e-com-net.com/image/info8/50c72296228a41818c518b6cba772716.jpg)
这种自动更新learn rate的方法感觉挺不错的,但是还可以优化,该方法叫RMSProp,具体计算方法如下:
![[2022]李宏毅深度学习与机器学习第二讲(必修)听课笔记_第24张图片](http://img.e-com-net.com/image/info8/4f88f19428204d819ed7f912d9534901.jpg)
这种方法可以在从狭窄地方到平坦地方时让learn rate快速变大,从平坦的地方到狭窄的地方让learn rate 快速变小,通过调节参数 α \alpha α
![[2022]李宏毅深度学习与机器学习第二讲(必修)听课笔记_第25张图片](http://img.e-com-net.com/image/info8/278b8e28365b48729ec30c3b40b7ffbb.jpg)
现阶段,主要用的优化方法是Adam,pytorch里面已经预置了一定的参数。
![[2022]李宏毅深度学习与机器学习第二讲(必修)听课笔记_第26张图片](http://img.e-com-net.com/image/info8/06694cda3565445db621c685bd09900d.jpg)
用这种方法得到的结果是
![[2022]李宏毅深度学习与机器学习第二讲(必修)听课笔记_第27张图片](http://img.e-com-net.com/image/info8/3c9c11f7dd374861a335aec9c1b52e6c.jpg)
因为,当gradient一直非常小的时候 σ i t \sigma_i^t σit就会非常小,然后整体就会非常大,然后就会发生偏差,但是会慢慢训练回去。克服这种方法,可以让learn rate 随时间变化 η t \eta^t ηt,原理和结果如下图:
![[2022]李宏毅深度学习与机器学习第二讲(必修)听课笔记_第28张图片](http://img.e-com-net.com/image/info8/aa8892cbc2d6420784a6db3e6825ad55.jpg)
另外一种策略就是 Warm up,就是 η t \eta^t ηt先从小变大,之后又从大变小,如下图:
![[2022]李宏毅深度学习与机器学习第二讲(必修)听课笔记_第29张图片](http://img.e-com-net.com/image/info8/a08ef7ad6a4d47f89251439e447fd118.jpg)
这个warm up 在residual network和transformer里又有应用。![[2022]李宏毅深度学习与机器学习第二讲(必修)听课笔记_第30张图片](http://img.e-com-net.com/image/info8/8207af58b6284cc09d61f62fbe479680.jpg)
老师说的解释是,一开始因为什么信息都没有,所以需要先探索,探索不能走的很快,所以让learn rate从小开始,随着信息地不断收集让learn rate不断变大,之后快到最优解时,learn rate 在变小。一帮常用的优化方法是这样的
![[2022]李宏毅深度学习与机器学习第二讲(必修)听课笔记_第31张图片](http://img.e-com-net.com/image/info8/6e2271b0568f4977af85c0de34273e21.jpg)
损失函数Loss
这一部分其实之前讲过,其实就是看这个图,也就是MSE在离最优解很远时,gradient非常小,更新不动。
![[2022]李宏毅深度学习与机器学习第二讲(必修)听课笔记_第32张图片](http://img.e-com-net.com/image/info8/95bf796cb4e5443c90df35ac91e7cfd8.jpg)
浅谈机器学习的原理——为什么参数越多越容易overfitting
这个是从数据的角度来说的为什么超参数越多越容易overfitting,放一个例子:
![[2022]李宏毅深度学习与机器学习第二讲(必修)听课笔记_第33张图片](http://img.e-com-net.com/image/info8/3ef375e8ce624e6a80c2b8f2692bd27e.jpg)
抽样数据和全局数据的分布并不一样,所以抽样数据并不好,所以什么样的抽样数据时好的抽样数据吗?这里给了一个定义,并且给出来什么情况下成立。
![[2022]李宏毅深度学习与机器学习第二讲(必修)听课笔记_第34张图片](http://img.e-com-net.com/image/info8/2553f9c1c52c4a5a9584d01dbe298b85.jpg)
所以我们得到坏的训练集的概率是多少那?
也就是,因为h让 D t r a i n D_{train} Dtrain变坏的并集,之后进行一个放缩,直接得到结论(下面的第二张图)
![[2022]李宏毅深度学习与机器学习第二讲(必修)听课笔记_第35张图片](http://img.e-com-net.com/image/info8/3c9c0b154a094479ad9d2575bba4aae6.jpg)

![[2022]李宏毅深度学习与机器学习第二讲(必修)听课笔记_第36张图片](http://img.e-com-net.com/image/info8/218bc9af8bc240cda7dfa1a9dacbf825.jpg)
对于上面的问题,可以训练资料越多,H的绝对值越小,都可以让simple到坏资料的概率变低。
我们算到的这个是上限,实际可能和上限差距很大,所以一般很少人用这个理论,只是用来解释为什么参数越多越容易过拟合。因为这个上界算出来的值,很多情况下大于1,就等于没有算。
那么如何估算H那?其实我也不会,老师也没有讲,那就截个图把
![[2022]李宏毅深度学习与机器学习第二讲(必修)听课笔记_第37张图片](http://img.e-com-net.com/image/info8/4a8b3af931374b5bb38cfb4b4d39536a.jpg)
最后,一般训练数据是一定的,所以当H小的时候可能包含的模型里面没有很好的会让后面的Loss很大,而当H大时,Train data更大概率会取到坏的数据,所以就出现了,鱼和熊掌可以兼得的问题。这个要下节课要讲的
![[2022]李宏毅深度学习与机器学习第二讲(必修)听课笔记_第38张图片](http://img.e-com-net.com/image/info8/56c3fe6b245b4c8585b90006f386a45f.jpg)
发展趋势

方法如下
- 要多少个layer,每个layer要多少个neurons: 需要根据经验和不断自己尝试,所以DL让问题从抽取特征变为定义结构。之前很多工作都是关注在如何抽取特征,有DL之后主要是如何构造网络结构。
- 为什么DL在NLP上的效果并不是很好? 老师给的猜想是,人对于文本提取特征能力很强,人设计的规则可能就能达到一个比较不错的效果。但是长久而言,DL在NLP里面的应用还是很广阔的。
Deep Learning的三个步骤

在第一步中,我们要自己决定结构
![[2022]李宏毅深度学习与机器学习第二讲(必修)听课笔记_第39张图片](http://img.e-com-net.com/image/info8/ded9f72a1474407d993e35beff9d5002.jpg)
涉及的问题:
- 要多少个layer,每个layer要多少个neurons: 需要根据经验和不断自己尝试,所以DL让问题从抽取特征变为定义结构。之前很多工作都是关注在如何抽取特征,有DL之后主要是如何构造网络结构。
- 为什么DL在NLP上的效果并不是很好? 老师给的猜想是,人对于文本提取特征能力很强,人设计的规则可能就能达到一个比较不错的效果。但是长久而言,DL在NLP里面的应用还是很广阔的。
反向传播
首先是要记住什么是链式法则大概张这样。![[2022]李宏毅深度学习与机器学习第二讲(必修)听课笔记_第40张图片](http://img.e-com-net.com/image/info8/d4faeb9d895a4ded8e93edc29bc58030.jpg)
计算的第一步从这里开始

考虑如何计算红框内的公式。

公式可以分为Forward pass和Backward pass
Forward pass 非常直观解释 x 1 x_1 x1,所以现在主要是算Backward pass。Backward pass的计算公式推导如下:
![[2022]李宏毅深度学习与机器学习第二讲(必修)听课笔记_第41张图片](http://img.e-com-net.com/image/info8/ac96dc83febd4cd7acacd6fbad7a5f87.jpg)
我们看输出层
![[2022]李宏毅深度学习与机器学习第二讲(必修)听课笔记_第42张图片](http://img.e-com-net.com/image/info8/cfe1cfde6e2b43d6b1cbcf43defd2c7d.jpg)
输出层的梯度可以很快算出来,但是隐藏层是比较难算的。

所以,我们使用反向传播

先算输出层,然后往前算,这样就可以减少计算量了。所以整个计算梯度的过程是先前向传播,然后反向传播,两个相乘就出来了。
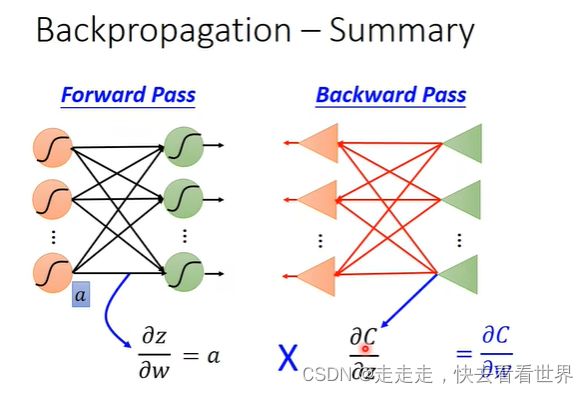
预测神奇宝贝CP,线性回归
第一步确定模型,这里是线性回归模型。

第二部,定义损失函数
![[2022]李宏毅深度学习与机器学习第二讲(必修)听课笔记_第43张图片](http://img.e-com-net.com/image/info8/b461051d8fe6404782cf071b078556ab.jpg)
第三步,找到比较好的 W , b W,b W,b

这里涉及到如何找,就是用梯度下降去更新。梯度下降有可能找到局部最优解,但是因为线性回归是类似与等高线,并不存在局部最优解,如图:
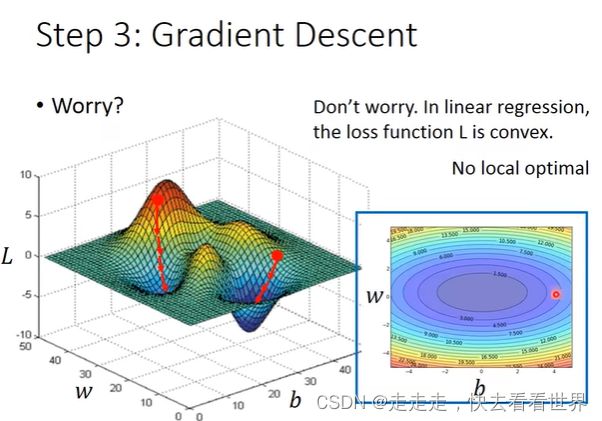
模型改进
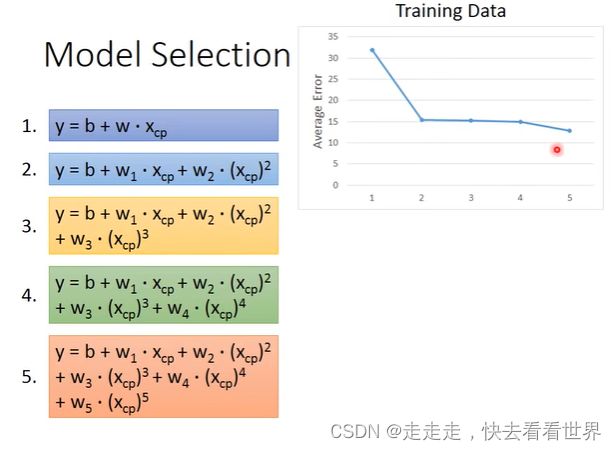
改进方法是在第一步定义模型时,把模型弄得更加复杂就可以,但是模型太过于复杂有可能过拟合,如下图:

所以这里可以用到正则化技术,正则化技术就改变损失函数,改变后的损失函数会让模型变得更加平滑,那么为什么平滑的模型更好那?
因为平滑的输出并不非常依赖输入,可以提高扛噪音能力

这里涉及到一个问题,为什么这里正则化没有加上b,因为我们加入正则化是要让函数变平滑,但是这里加上b,只是上下移动,所以没有必要加上去。加入正则化之后的结果
![[2022]李宏毅深度学习与机器学习第二讲(必修)听课笔记_第44张图片](http://img.e-com-net.com/image/info8/222c409efd404452a16d4f7ddd72e561.jpg)
从上图可以看出,我们喜欢平滑的Function,但是并不能太平滑,不然就成一条直线了。
神奇宝贝的分类
Generative Model

Generative model 需要提前人为设定,数据服从什么分布,这里给的是服从高斯分布。图中四个框里面的先验概率是非常容易算出来的。主要计算的是后验概率。我们假设服从高斯分布:

用最大似然估计去计算高斯分布的概率。

计算公式是可以推导出来,然后计算出来的。但是如果出现了过拟合。
![[2022]李宏毅深度学习与机器学习第二讲(必修)听课笔记_第45张图片](http://img.e-com-net.com/image/info8/469e54dcd8fd44b3af38dede1bdc46b1.jpg)
改进方法,这个方法也是一般方法:让两个分布的 ∑ \sum ∑一样,如下图:

改进之后变成了linear model

后面经过了一系列推导,把Generative Model与逻辑斯蒂回归联系起来了,推导过程如下图:

![[2022]李宏毅深度学习与机器学习第二讲(必修)听课笔记_第46张图片](http://img.e-com-net.com/image/info8/1bc7943c2a0c4f48a7df90d30684dc06.jpg)
![[2022]李宏毅深度学习与机器学习第二讲(必修)听课笔记_第47张图片](http://img.e-com-net.com/image/info8/d3c0e986359f4a108b956c976528ee7c.jpg)
Discriminative Model
第一步简历Function
![[2022]李宏毅深度学习与机器学习第二讲(必修)听课笔记_第48张图片](http://img.e-com-net.com/image/info8/8193f720c3574b37918de24d64f6cb56.jpg)
第二步定义损失函数,损失函数用的伯努利分布之间的交叉熵

逻辑斯蒂回归和线性归回对比

这里有一个问题,为什么逻辑斯蒂回归不用Square Error。
![[2022]李宏毅深度学习与机器学习第二讲(必修)听课笔记_第49张图片](http://img.e-com-net.com/image/info8/2cbf448241f34f0f94edfeae206ad138.jpg)
上面一段数学推导+举例子说明了,如果用Square Error那么离目标进的时候损失小这很OK,但是离目标远的时候损失也小。

在梯度下降的时候,当loss小的时候你并不知道是离目标远还是非常接近目标,很难去找到最优解。
Discriminative Vs Generative
![[2022]李宏毅深度学习与机器学习第二讲(必修)听课笔记_第50张图片](http://img.e-com-net.com/image/info8/a87c17a11d9e40d78522df2ecfaa105f.jpg)
两个模型都是算W和b,但是两个模型找到的W和b并不一样,一般而言判别式模型要比生成式模型好。但是也不一定。
这里老师总结了一下生成式模型的优点

- 提前知道符合什么分布同时训练数据少时,效果好
- 因为提前知道符合什么分布,所以鲁棒性好
- 先验概率和后验概率可以来源不同
Multi-class Classification
之间上做法

Softmax强化大的值,让大值更大,小值更小。
但是逻辑斯蒂回归做不到异或的任务,因为只是一条直线。

这里可以用Feature Transformation,但是Feature Transformation的设计是人为设计的,并不好想。
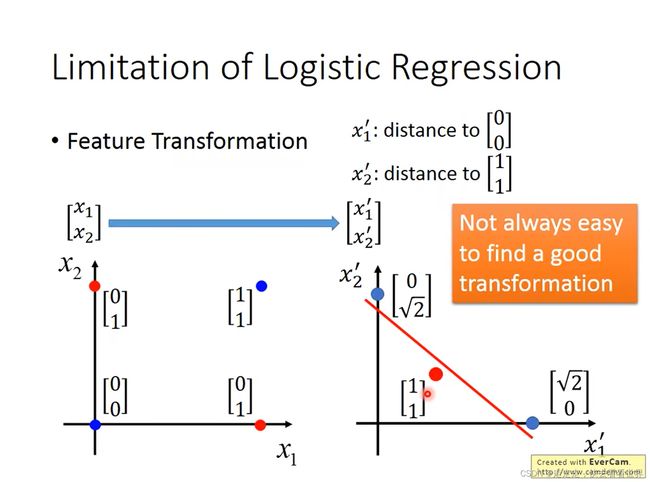
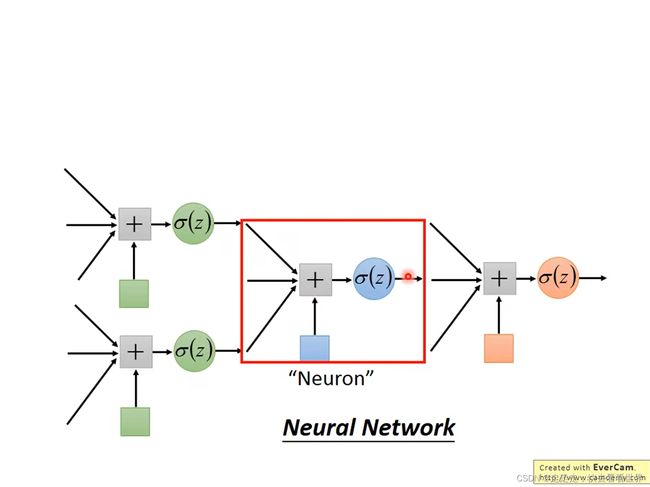
这里可以用一层layer来作feature Transformation

最好就变成了神经网络,多堆叠几个layer就成了深度神经网络。
11点开始写,写了两个小时终于写完了,下班,睡觉!