2022_WWW_Improving Graph Collaborative Filtering with Neighborhood-enriched Contrastive Learning
[论文阅读笔记]2022_WWW_Improving Graph Collaborative Filtering with Neighborhood-enriched Contrastive Learning
论文下载地址: https://doi.org/10.1145/3485447.3512104
发表期刊:WWW
Publish time: 2022
作者及单位:
- Zihan Lin1†, Changxin Tian1†, Yupeng Hou2†, Wayne Xin Zhao2,3B
- 1School of Information, Renmin University of China, China
- 2Gaoling School of Artificial Intelligence, Renmin University of China, China
- 3Beijing Key Laboratory of Big Data Management and Analysis Methods, China {zhlin, tianchangxin, houyupeng}@ruc.edu.cn, [email protected]
数据集: 正文中的介绍
- MovieLens-1M(ML-1M) ---- (2015. The movielens datasets: History and context.)
- Yelp https://www.yelp.com/dataset
- Amazon Books ---- (2015. Image-based recommendations on styles and substitutes.)
- Gowalla ---- (2011. Friendship and mobility: user movement in location-based social networks.)
- Alibaba-iFashion ---- ( 2019. POG: personalized outfit generation for fashion recommendation at Alibaba iFashion.)
代码:
- https://github.com/RUCAIBox/NCL (文中作者给的)
其他:
其他人写的文章
简要概括创新点: 可以看做是对positive contrastive pairs的改进,negative还是 uniformly smaples
(1) 缝合了(i)structual space/neighbors (ii)semantic space/neighbors
(2)分别对应 structure-contrastive objective(用GNN提取,视为正对比对) + prototype-contrastive objective(用K-Means)
(3)用EM方法优化(因为这一过程无法进行端到端的优化,其实K-Means本就是EM算法的一个例子)
(4)是一个model-agnostic constative learning framework
(5)Loss 是3个loss的权重和,要用multi-task learning strategy
(6) 没用social, user-user靠 偶数步
- we propose a novel contrastive learning approach, named Neighborhood-enriched Contrastive Learning, named NCL, which explicitly incorporates the potential neighbors into contrastive pairs. (为了解决上述问题,我们提出了一种新的对比学习方法,称为邻域丰富对比学习(NCL),它将潜在的邻域明确地整合到对比对中。)
- Specifically, we introduce the neighbors of a user (or an item) from graph structure and semantic space respectively. (具体来说,我们分别从图结构和语义空间引入用户(或项目)的邻居。)
- For the structural neighbors on the interaction graph, we develop a novel structure-contrastive objective that regards users (or items) and their structural neighbors as positive contrastive pairs. (对于交互图上的结构邻居,我们提出了一种新的结构对比目标,将用户(或项目)及其结构邻居视为正对比对。)
- In implementation, the representations of users (or items) and neighbors correspond to the outputs of different GNN layers. (在实现中,用户(或项目)和邻居的表示对应于不同GNN层的输出。)
- Furthermore, to excavate the potential neighbor relation in semantic space, we assume that users with similar representations are within the semantic neighborhood, and incorporate these semantic neighbors into the prototype-contrastive objective. (此外,为了挖掘语义空间中潜在的邻域关系,我们假设具有相似表示的用户位于语义邻域内,并将这些语义邻域合并到原型对比目标中。)
- The proposed NCL can be optimized with EM algorithm and generalized to apply to graph collaborative filtering methods. (所提出的NCL可以用EM算法进行优化,并可推广应用于图协同过滤方法。)
- We propose a model-agnostic contrastive learning framework named NCL, which incorporates both structural and semantic neighbors for improving the neural graph collaborative filtering. (我们提出了一个模型不可知的对比学习框架NCL,它结合了结构和语义邻域来改进神经图协同过滤。)
- We propose to learn representative embeddings for both kinds of neighbors, such that the constative learning can be only performed between a node and the corresponding representative embeddings, which largely improves the algorithm efficiency. (我们建议学习这两种邻居的代表性嵌入,这样只能在一个节点和相应的代表性嵌入之间进行约束学习,这大大提高了算法的效率。)
ABSTRACT
-
(1) Recently, graph collaborative filtering methods have been proposed as an effective recommendation approach, which can capture users’ preference over items by modeling the user-item interaction graphs. (近年来,图协同过滤方法作为一种有效的推荐方法被提出,它通过对用户-项目交互图的建模来捕获用户对项目的偏好。)
- Despite the effectiveness, these methods suffer from data sparsity in real scenarios. (尽管有效,但这些方法在实际场景中存在数据稀疏的问题)
- In order to reduce the influence of data sparsity, contrastive learning is adopted in graph collaborative filtering for enhancing the performance. (为了减少数据稀疏性的影响,在图协同过滤中采用对比学习来提高性能。)
- However, these methods typically construct the contrastive pairs by random sampling, which neglect the neighboring relations among users (or items) and fail to fully exploit the potential of contrastive learning for recommendation. (然而,这些方法通常是通过随机抽样来构建对比对,忽略了用户(或项目)之间的相邻关系,未能充分利用对比学习的潜力进行推荐。)
-
(2) To tackle the above issue, we propose a novel contrastive learning approach, named Neighborhood-enriched Contrastive Learning, named NCL, which explicitly incorporates the potential neighbors into contrastive pairs. (为了解决上述问题,我们提出了一种新的对比学习方法,称为邻域丰富对比学习(NCL),它将潜在的邻域明确地整合到对比对中。)
- Specifically, we introduce the neighbors of a user (or an item) from graph structure and semantic space respectively. (具体来说,我们分别从图结构和语义空间引入用户(或项目)的邻居。)
- For the structural neighbors on the interaction graph, we develop a novel structure-contrastive objective that regards users (or items) and their structural neighbors as positive contrastive pairs. (对于交互图上的结构邻居,我们提出了一种新的结构对比目标,将用户(或项目)及其结构邻居视为正对比对。)
- In implementation, the representations of users (or items) and neighbors correspond to the outputs of different GNN layers. (在实现中,用户(或项目)和邻居的表示对应于不同GNN层的输出。)
- Furthermore, to excavate the potential neighbor relation in semantic space, we assume that users with similar representations are within the semantic neighborhood, and incorporate these semantic neighbors into the prototype-contrastive objective. (此外,为了挖掘语义空间中潜在的邻域关系,我们假设具有相似表示的用户位于语义邻域内,并将这些语义邻域合并到原型对比目标中。)
- The proposed NCL can be optimized with EM algorithm and generalized to apply to graph collaborative filtering methods. (所提出的NCL可以用EM算法进行优化,并可推广应用于图协同过滤方法。)
- Extensive experiments on five public datasets demonstrate the effectiveness of the proposed NCL, notably with 26% and 17% performance gain over a competitive graph collaborative filtering base model on the Yelp and Amazon-book datasets, respectively. Our implementation code is available at: https://github.com/RUCAIBox/NCL. (在五个公共数据集上进行的大量实验证明了所提出的NCL的有效性,与Yelp和Amazon book数据集上的竞争图协同过滤基础模型相比,性能分别提高了26%和17%。我们的实施代码可从以下网址获得:https://github.com/RUCAIBox/NCL.)
CCS CONCEPTS
• Information systems → Recommender systems.
KEYWORDS
Recommender System, Collaborative Filtering, Contrastive Learning, Graph Neural Network
1 INTRODUCTION
-
(1) In the age of information explosion, recommender systems occupy an important position to discover users’ preferences and deliver online services efficiently [23]. (在信息爆炸的时代,推荐系统在发现用户偏好和高效提供在线服务方面占据着重要地位[23]。)
- As a classic approach, collaborative filtering (CF) [10, 24] is a fundamental technique that can produce effective recommendations from implicit feedback (expression, click, transaction et al.). (作为一种经典方法,协同过滤(CF)[10,24]是一种基本技术,可以从隐式反馈(表达、点击、交易等)中产生有效的建议。)
- Recently, CF is further enhanced by the powerful graph neural networks (GNN) [9, 31], which models the interaction data as graphs (e.g., the user-item interaction graph) and then applies GNN to learn effective node representations [9,31] for recommendation, called graph collaborative filtering. (最近,功能强大的图神经网络(GNN)[9,31]进一步增强了CF,该网络将交互数据建模为图形(例如,用户项交互图),然后应用GNN学习有效的节点表示[9,31]进行推荐,称为图协同过滤。)
-
(2) Despite the remarkable success, existing neural graph collaborative filtering methods still suffer from two major issues. (尽管取得了显著的成功,但现有的神经图协同过滤方法仍然存在两个主要问题。)
- Firstly, user-item interaction data is usually sparse or noisy, and it may not be able to learn reliable representations since the graph-based methods are potentially more vulnerable to data sparsity [33]. (首先,用户项交互数据通常是稀疏的或有噪声的,它可能无法学习可靠的表示,因为基于图形的方法可能更容易受到数据稀疏性的影响[33]。)
- Secondly, existing GNN based CF approaches rely on explicit interaction links for learning node representations, while high-order relations or constraints (e.g., user or item similarity) cannot be explicitly utilized for enriching the graph information, which has been shown essentially useful in recommendation tasks [24, 27, 35]. (其次,现有的基于GNN的CF方法依赖于显式的交互链接来学习节点表示,而高阶关系或约束(例如,用户或项目相似性)不能明确用于丰富图形信息,这在推荐任务中基本上是有用的[24、27、35]。)
- Although several recent studies leverage constative learning to alleviate the sparsity of interaction data [33, 39], they construct the contrastive pairs by randomly sampling nodes or corrupting subgraphs. (尽管最近的几项研究利用constative learning来缓解交互数据的稀疏性[33,39],但它们通过随机采样节点或损坏子图来构建对比对。)
- It lacks consideration on how to construct more meaningful contrastive learning tasks tailored for the recommendation task [24, 27, 35]. (它缺乏对如何构建针对推荐任务的更有意义的对比学习任务的考虑[24,27,35]。)
-
(3) Besides direct user-item interactions, there exist multiple kinds of potential relations (e.g., user similarity) that are useful to the recommendation task, and we aim to design more effective constative learning approaches for leveraging such useful relations in neural graph collaborative filtering. (除了直接的用户项交互,还存在多种对推荐任务有用的潜在关系(例如,用户相似性),我们旨在设计更有效的约束学习方法,以便在神经图协同过滤中利用这些有用的关系。)
- Specially, we consider node-level relations w.r.t. a user (or an item), which is more efficient than the graph-level relations. (特别地,我们考虑节点级关系W.R.T.一个用户(或一个项目),它比图级关系更有效。)
- We characterize these additional relations as enriched neighborhood of nodes, which can be defined in two aspects: (我们将这些附加关系描述为节点的丰富邻域,可以从两个方面进行定义)
- (1) structural neighbors refer to structurally connected nodes by high-order paths, (结构邻居是指通过高阶路径在结构上连接的节点,)
- and (2) semantic neighbors refer to semantically similar neighbors which may not be directly reachable on graphs. (语义邻居指的是语义相似的邻居,它们在图上可能无法直接访问。)
- We aim to leverage these enriched node relations for improving the learning of node representations (i.e., encoding user preference or item characteristics). (我们的目标是利用这些丰富的节点关系来改进节点表示(即编码用户偏好或项目特征)的学习。)
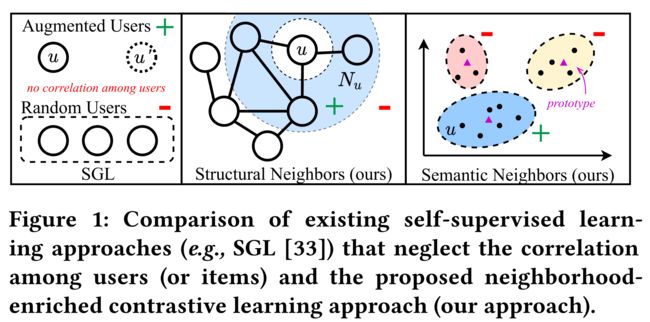
-
(4) To integrate and model the enriched neighborhood, we propose Neighborhood-enriched Contrastive Learning (NCL for short), a model-agnostic constative learning framework for the recommendation.
- As introduced before, NCL constructs node-level contrastive objectives based on two kinds of extended neighbors. (如前所述,NCL基于两种扩展邻居构建节点级对比目标。)
- We present a comparison between NCL and existing constative learning methods in Figure 1. (我们在图1中比较了NCL和现有的限制性学习方法。)
- However, node-level contrastive objectives usually require pairwise learning for each node pair, which is time-consuming for large-sized neighborhoods. (然而,节点级对比目标通常需要对每个节点对进行成对学习,这对于大型社区来说是非常耗时的。)
- Considering the efficiency issue, we learn a single representative embedding for each kind of neighbor, such that the constative learning for a node can be accomplished with two representative embeddings (either structural or semantic). (考虑到效率问题,我们为每种邻居学习一个单个代表性嵌入,这样一个节点的约束性学习可以通过 两个代表性嵌入(结构或语义) 来完成。)
-
(5) To be specific,
- for structural neighbors, we note that the outputs of k k k-th layer of GNN involve the aggregated information of k k k-hop neighbors. (对于结构邻居,我们注意到GNN的第 k k k层的输出包含 k k k-hop邻居的聚合信息。)
- Therefore, we utilize the k k k-th layer output from GNN as the representations of k k k-hop neighbors for a node. (因此,我们利用GNN输出的第 k k k层作为节点的 k k k-hop邻居的表示。)
- We design a structure-aware contrastive learning objective that pulls the representations of a node (a user or item) and the representative embedding for its structural neighbors. (我们设计了一个结构感知的对比学习目标,该目标提取节点(用户或项目)的表示及其结构邻居的代表性嵌入。)
- For the semantic neighbors, we design a prototypical contrastive learning objective to capture the correlations between a node (a user or item) and its prototype. (对于语义邻居,我们设计了一个原型对比学习目标来捕捉节点(用户或项目)与其原型之间的相关性。)
- Roughly speaking, a prototype can be regarded as the centroid of the cluster of semantically similar neighbors in representation space. (粗略地说,原型可以被视为表示空间中语义相似邻居簇的质心。)
- Since the prototype is latent, we further propose to use an expectation maximization (EM) algorithm [19] to infer the prototypes. (由于原型是潜在的,我们进一步建议使用期望最大化(EM)算法[19]来推断原型。)
- By incorporating these additional relations, our experiments show that it can largely improve the original GNN based approaches (also better than existing constative learning methods) for implicit feedback recommendation. (通过加入这些额外的关系,我们的实验表明,它可以在很大程度上改进原有的基于GNN的内隐反馈推荐方法(也优于现有的约束性学习方法)。)
- for structural neighbors, we note that the outputs of k k k-th layer of GNN involve the aggregated information of k k k-hop neighbors. (对于结构邻居,我们注意到GNN的第 k k k层的输出包含 k k k-hop邻居的聚合信息。)
-
(6) Our contributions can be summarized threefold: (我们的贡献可以概括为三个方面:)
- We propose a model-agnostic contrastive learning framework named NCL, which incorporates both structural and semantic neighbors for improving the neural graph collaborative filtering. (我们提出了一个模型不可知的对比学习框架NCL,它结合了结构和语义邻域来改进神经图协同过滤。)
- We propose to learn representative embeddings for both kinds of neighbors, such that the constative learning can be only performed between a node and the corresponding representative embeddings, which largely improves the algorithm efficiency. (我们建议学习这两种邻居的代表性嵌入,这样只能在一个节点和相应的代表性嵌入之间进行约束学习,这大大提高了算法的效率。)
- Extensive experiments are conducted on five public datasets, demonstrating that our approach is consistently better than a number of competitive baselines, including GNN and contrastive learning-based recommendation methods. (在五个公共数据集上进行了大量实验,证明我们的方法始终优于许多竞争基线,包括GNN和基于对比学习的推荐方法。)
2 PRELIMINARY
-
(1) As the fundamental recommender system, collaborative filtering (CF) aims to recommend relevant items that users might be interested in based on the observed implicit feedback (e.g., expression, click and transaction). (作为最基本的推荐系统,协同过滤(CF)旨在根据观察到的隐性反馈(如表达、点击和交易)推荐用户可能感兴趣的相关项目。)
- Specifically, given the user set U = { u } \mathcal{U} = \{u\} U={u} and item set I = { i } \mathcal{I} = \{i\} I={i}, the observed implicit feedback matrix is denoted as R ∈ { 0 , 1 } ∣ U ∣ × ∣ I ∣ R \in \{0,1\} ^ {|U |×|I |} R∈{0,1}∣U∣×∣I∣,
- where each entry R u , i = 1 R_{u, i} = 1 Ru,i=1 if there exists an interaction between the user u u u and item i i i, otherwise R u , i = 0 R_{u, i} = 0 Ru,i=0.
- Based on the interaction data R R R, the learned recommender systems can predict potential interactions for recommendation. (学习的推荐系统可以预测推荐的潜在交互)
- Furthermore, Graph Neural Network (GNN) based collaborative filtering methods organize the interaction data R R R as an interaction graph G = { V , E } \mathcal{G} = \{\mathcal{V}, \mathcal{E} \} G={V,E}, (此外,基于图神经网络(GNN)的协同过滤方法将交互数据 R R R组织为交互图 G = { V , E } \mathcal{G} = \{\mathcal{V}, \mathcal{E} \} G={V,E})
- where V = { U ∪ I } \mathcal{V} = \{\mathcal{U} \cup \mathcal{I}\} V={U∪I} denotes the set of nodes and E = { ( u , i ) ∣ u ∈ U , i ∈ I , R u , i = 1 } \mathcal{E} = \{(u,i) | u \in \mathcal{U}, i \in \mathcal{I}, R_{u, i} = 1 \} E={(u,i)∣u∈U,i∈I,Ru,i=1} denotes the set of edges.
- Specifically, given the user set U = { u } \mathcal{U} = \{u\} U={u} and item set I = { i } \mathcal{I} = \{i\} I={i}, the observed implicit feedback matrix is denoted as R ∈ { 0 , 1 } ∣ U ∣ × ∣ I ∣ R \in \{0,1\} ^ {|U |×|I |} R∈{0,1}∣U∣×∣I∣,
-
(2) In general, GNN-based collaborative filtering methods [9, 31, 32] produce informative representations for users and items based on the aggregation scheme, which can be formulated to two stages: (一般来说,基于GNN的协同过滤方法[9,31,32]基于聚合方案为用户和项目生成信息表示,可分为两个阶段:)

- where N u \mathcal{N}_u Nu denotes the neighbor set of user u u u in the interaction graph G \mathcal{G} G (表示交互图 G \mathcal{G} G中用户 u u u的邻居集)
- and L L L denotes the number of GNN layers. ( L L L表示GNN层的数量。)
- Here, z u ( 0 ) z^{(0)}_u zu(0) is initialized by the learnable embedding vector e u e_u eu. (由可学习的嵌入向量 e u e_u eu初始化 .)
- For the user u u u, the propagation function f p r o p a g a t e ( ⋅ ) f_{propagate}(·) fpropagate(⋅) aggregates the ( l − 1 ) (l − 1) (l−1)-th layer’s representations of its neighbors to generate the l l l-th layer’s representation z u ( l ) z^{(l)}_u zu(l). (对于用户uu,传播函数 f p r o p a g a t e ( ⋅ ) f_{propagate}(·) fpropagate(⋅)聚合第 ( l − 1 ) (l − 1) (l−1)层邻居的表示,以生成第 l l l层的表示 z u ( l ) z^{(l)}_u zu(l).)
- After l l l times iteratively propagation, the information of l l l-hop neighbors is encoded in z u ( l ) z^{(l)}_u zu(l). (经过 l l l次迭代传播后, l l l跳邻居的信息被编码为 z u ( l ) z^{(l)}_u zu(l).)
- And the readout function f r e a d o u t ( ⋅ ) f_{readout}(·) freadout(⋅) further summarizes all of the representations [ z u ( 0 ) , z u ( 1 ) , . . . , z u ( L ) ] [z^{(0)}_u, z^{(1)}_u, ..., z^{(L)}_u] [zu(0),zu(1),...,zu(L)] to obtain the final representations of user u u u for recommendation. (以及读出函数 f r e a d o u t ( ⋅ ) f_{readout}(·) freadout(⋅) 进一步总结了所有的表示 [ z u ( 0 ) , z u ( 1 ) , . . . , z u ( L ) ] [z^{(0)}_u, z^{(1)}_u, ..., z^{(L)}_u] [zu(0),zu(1),...,zu(L)]获取用户 u u u的最终表示以供推荐。)
- The informative representations of items can be obtained analogously. (项目的信息表示可以类似地获得。)
3 METHODOLOGY
- In this section, we introduce the proposed Neighborhood-enriched Contrastive Learning method in three parts. (在这一部分中,我们将分三部分介绍所提出的邻域丰富对比学习方法)
- We first introduce the base graph collaborative filtering approach in Section 3.1, which outputs the final representations for recommendation along with the integrant representations for structural neighbors. (我们首先在第3.1节中介绍了基础图协同过滤方法,该方法输出推荐的最终表示以及结构邻居的被积表示。)
- Then, we introduce the structure-contrastive strategies and prototype-contrastive strategies in Section 3.2 and Section 3.3 respectively, which integrate the relation of neighbors into contrastive learning to coordinate with collaborative filtering properly. (然后,我们分别介绍了第3.2节和第3.3节中的结构对比策略和原型对比策略,它们将邻居关系融入对比学习中,从而与协同过滤进行适当的协调。)
- Finally, we propose a multi-task learning strategy in Section 3.4 and further present the theoretical analysis and discussion in Section 3.5. The overall framework of NCL is depicted in Figure 2. (最后,我们在第3.4节中提出了一种多任务学习策略,并在第3.5节中进一步进行了理论分析和讨论。NCL的总体框架如图2所示。)
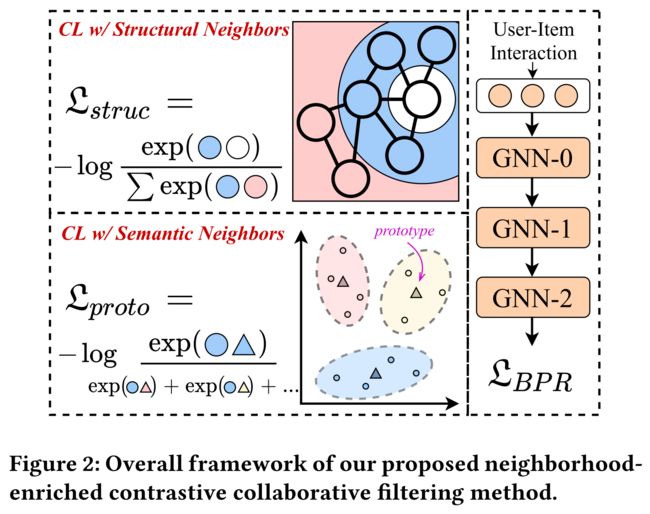
3.1 Graph Collaborative Filtering BackBone (图形协同过滤主干网)
-
(1) As mentioned in Section 2, GNN-based methods produce user and item representations by applying the propagation and prediction function on the interaction graph G \mathcal{G} G. (如第2节所述,基于GNN的方法通过在交互图 G \mathcal{G} G上应用传播和预测函数来生成用户和项目表示。)
- In NCL, we utilize GNN to model the observed interactions between users and items. (在NCL中,我们利用GNN对观察到的用户和项目之间的交互进行建模。)
- Specifically, following LightGCN [9], we discard the nonlinear activation and feature transformation in the propagation function as: (具体来说,像LightGCN[9]那样,我们放弃了传播函数中的非线性激活和特征变换,如下所示:)

-
(2) After propagating with L L L layers, we adopt the weighted sum function as the readout function to combine the representations of all layers and obtain the final representations as follows:(在使用 L L L层进行传播后,我们采用加权和函数作为读出函数,组合所有层的表示,并获得如下最终表示:)
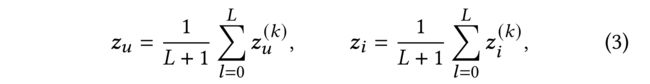
- where z u z_u zu and z i z_i zi denote the final representations of user u u u and item i i i. ( z u z_u zu和 z i z_i zi表示用户 u u u和项目 i i i的最终表示。)
-
(3) With the final representations, we adopt inner product to predict how likely a user u u u would interact with items i i i: (在最终表述中,我们采用内积来预测用户 u u u与第 i i i项交互的可能性:)
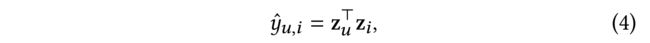
- where y ^ u , i \hat{y}_{u, i} y^u,i is the prediction score of user u u u and items i i i. (是用户 u u u和项目 i i i的预测分数)
-
(4) To capture the information from interactions directly, we adopt Bayesian Personalized Ranking (BPR) loss [22], which is a welldesigned ranking objective function for recommendation. (为了直接从交互中获取信息,我们采用了贝叶斯个性化排名(BPR)损失[22],这是一个精心设计的推荐排名目标函数。)
- Specifically, BPR loss enforces the prediction score of the observed interactions higher than sampled unobserved ones. (具体来说,BPR损失会使观察到的交互作用的预测得分高于抽样的未观察到的交互作用。)
- Formally, the objective function of BPR loss is as follows: (形式上,BPR损失的目标函数如下)
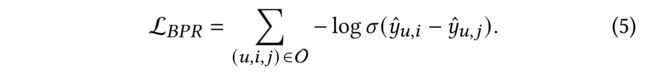
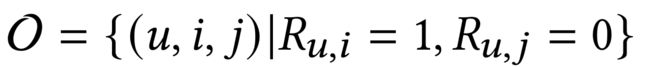
- where σ ( ⋅ ) \sigma(\cdot) σ(⋅) is the sigmoid function,
- O = { ( u , i , j ) ∣ R u , i = 1 , R u , j = 0 } O = \{(u, i, j) | R_{u, i} = 1, R_{u, j} = 0\} O={(u,i,j)∣Ru,i=1,Ru,j=0} denotes the pairwise training data, and j j j denotes the sampled item that user u u u has not interacted with. (表示成对的训练数据, j j j表示用户 u u u未与之交互的采样项。)
-
(5) By optimizing the BPR loss L B P R L_{BPR} LBPR, our proposed NCL can model the interactions between users and items. (通过优化BPR损失 L B P R L_{BPR} LBPR , 我们提出的NCL可以对用户和项目之间的交互进行建模。)
- However, high-order neighbor relations within users (or within items) are also valuable for recommendations. (然而,用户(或项目)内的高阶邻居关系对于推荐也很有价值。)
- For example, users are more likely to buy the same product as their neighbors. (例如,用户更有可能购买与邻居相同的产品。)
- Next, we will propose two contrastive learning objectives to capture the potential neighborhood relationships of users and items. (接下来,我们将提出两个对比学习目标,以捕捉用户和项目的潜在邻域关系。)
3.2 Contrastive Learning with Structural Neighbors (结构邻居对比学习)
-
(1) Existing graph collaborative filtering models are mainly trained with the observed interactions (e.g., user-item pairs), while the potential relationships among users or items cannot be explicitly captured by learning from the observed data. (现有的图协同过滤模型主要是利用观察到的交互(如用户-项目对)进行训练,而用户或项目之间的潜在关系不能通过从观察到的数据中学习来明确捕获。)
- In order to fully exploit the advantages of contrastive learning, we propose to contrast each user (or item) with his/her structural neighbors whose representations are aggregated through layer propagation of GNN. (为了充分利用对比学习的优势,我们提出将每个用户(或项目)与他/她的结构邻居进行对比,这些邻居的表示通过GNN的层传播进行聚合。)
- Formally, the initial feature or learnable embedding of users/items are denoted by z ( 0 ) z^{(0)} z(0) in the graph collaborative filtering model [9]. (形式上,在图协同过滤模型[9]中,用户/项目的初始特征或可学习嵌入由 z ( 0 ) z^{(0)} z(0)表示。)
- And the final output can be seen as a combination of the embeddings within a subgraph that contains multiple neighbors at different hops. (最终的输出可以看作是一个子图中嵌入的组合,该子图包含不同跳数的多个邻居。)
- Specifically, the l l l-th layer’s output z ( l ) z^{(l)} z(l) of the base GNN model is the weighted sum of l l l−hop structural neighbors of each node, as <>there is no transformation and self-loop when propagation [9].
-
(2) Considering that the interaction graph G \mathcal{G} G is a bipartite graph, information propagation with GNN-based model for even times on the graph naturally aggregates information of homogeneous structural neighbors which makes it convenient to extract the potential neighbors within users or items. (考虑到交互图 G \mathcal{G} G是一个二部图,基于GNN模型的偶数次信息传播自然地聚集了同质结构邻居的信息,这便于提取用户或项目中的潜在邻居。)
- In this way, we can obtain the representations of homogeneous neighborhoods from the even layer (e.g., 2, 4, 6) output of the GNN model. (通过这种方式,我们可以从GNN模型的偶数层(例如2、4、6)输出中获得同质邻居的表示。)
- With these representations, we can efficiently model the relation between users/items and their homogeneous structural neighbors. (通过这些表示,我们可以有效地建模用户/项目与其同质结构邻居之间的关系。)
- Specifically, we treat the embedding of users themself and the embedding of the corresponding output of the even-numbered layer GNN as positive pairs. (具体来说,我们将用户自身的嵌入和偶数层GNN的相应输出的嵌入视为正对。)
- Based on InfoNCE [20], we propose the structure-contrastive learning objective to minimize the distance between them as follows: (基于InfoNCE[20],我们提出了结构对比学习目标,以最小化二者之间的距离,如下所示:)
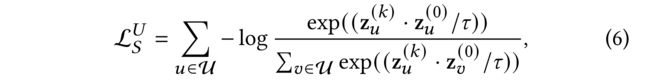
- where z u ( k ) z^{(k)}_u zu(k) is the normalized output of GNN layer k k k and k k k is even number. (GNN k k k层的标准化输出, k k k是偶数。)
- τ \tau τ is the temperature hyper-parameter of softmax. (是softmax的温度超参数。)
-
(3) In a similar way, the structure-contrastive loss of the item side L s t r u c i t e m L^{item}_{struc} Lstrucitem can be obtained as: (以类似的方式,项目侧的结构对比损失 L s t r u c i t e m L^{item}_{struc} Lstrucitem可通过以下方式获得:)

-
(4) And the complete structure-contrastive objective function is the weighted sum of the above two losses: (完整的结构对比目标函数是上述两种损失的加权和:)
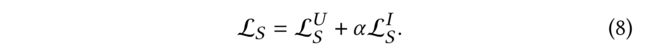
- where α \alpha α is a hyper-parameter to balance the weight of the two losses in structure-contrastive learning. (是平衡结构对比学习中两种损失权重的超参数。)
3.3 Contrastive Learning with Semantic Neighbors (语义邻居对比学习)
-
(1) The structure-contrastive loss explicitly excavates the neighbors defined by the interaction graph. (结构对比损失明确挖掘由交互图定义的邻域。)
- However, the structure-contrastive loss treats the homogeneous neighbors of users/items equally, which inevitably introduces noise information to contrastive pairs. (然而,结构对比损失同等对待用户/项目的同质邻居,这不可避免地会给对比对引入噪声信息。)
- To reduce the influence of noise from structural neighbors, we consider extending the contrastive pairs by incorporating semantic neighbors, which refer to unreachable nodes on the graph but with similar characteristics (item nodes) or preferences (user nodes). (为了减少来自结构邻居的噪声的影响,我们考虑通过引入语义邻居来扩展对比对,所述语义邻居指的是图上的不可达节点,但具有相似的特性(项目节点)或偏好(用户节点)。)
-
(2) Inspired by previous works [16], we can identify the semantic neighbors by learning the latent prototype for each user and item. (受之前工作[16]的启发,我们可以通过学习每个用户和项目的潜在原型来识别语义邻居)
- Based on this idea, we further propose the prototype-contrastive objective to explore potential semantic neighbors and incorporate them into contrastive learning to better capture the semantic characteristics of users and items in collaborative filtering. (基于这一思想,我们进一步提出了原型对比目标,以探索潜在的语义邻居,并将其纳入对比学习中,从而更好地捕捉协同过滤中用户和项目的语义特征。)
- In particular, similar users/items tend to fall in neighboring embedding space, and the prototypes are the center of clusters that represent a group of semantic neighbors. (特别是,相似的用户/项目往往落在相邻的嵌入空间中,原型是表示一组语义邻居的集群的中心。)
- Thus, we apply a clustering algorithm on the embeddings of users and items to obtain the prototypes of users or items. (因此,我们将聚类算法应用于用户和项目的嵌入,以获得用户或项目的原型。)
- Since this process cannot be end-to-end optimized, we learn the proposed prototype-contrastive objective with EM algorithm. (由于这一过程无法进行端到端的优化,我们使用EM算法学习提出的原型对比目标。)
- Formally, the goal of GNN model is to maximize the following log-likelihood function: (从形式上讲,GNN模型的目标是最大化以下对数似然函数)
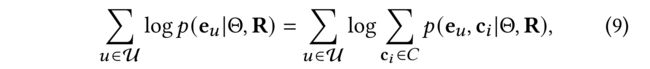
- where Θ \Theta Θ is a set of model parameters and (是一组模型参数)
- R R R is the interaction matrix. (是交互矩阵)
- And c i c_i ci is the latent prototype of user u u u. (是用户 u u u的潜在原型)
- Similarly, we can define the optimization objective for items. (同样,我们可以为项目定义优化目标)
-
(3) After that, the proposed prototype-contrastive learning objective is to minimize the following function based on InfoNCE [20]: (之后,提出的原型对比学习目标是基于InfoNCE最小化以下功能[20]:)

- where c i c_i ci is the prototype of user u u u which is got by clustering over all the user embeddings with K K K-means algorithm and there are k k k clusters over all the users. ( c i c_i ci是用户 u u u的原型,它是通过使用 K K K-means算法对所有用户嵌入进行聚类得到的,所有用户上都有k个聚类。)
-
(4) The objective on the item side is identical: (项目侧的目标是相同的)
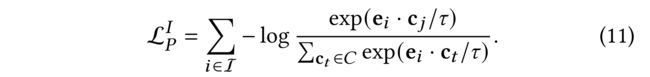
- where c j c_j cj is the protype of item i. ( c j c_j cj是项目 i i i的原型。)
-
(5) The final prototype-contrastive objective is the weighted sum of user objective and item objective: (最终原型对比目标是用户目标和项目目标的加权和:)
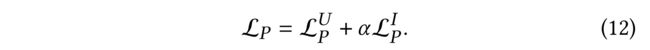
-
(6) In this way, we explicitly incorporate the semantic neighbors of users/items into contrastive learning to alleviate the data sparsity. (通过这种方式,我们明确地将用户/项目的语义邻居纳入对比学习中,以缓解数据稀疏性)
3.4 Optimization
- In this section, we introduce the overall loss and the optimization of the proposed prototype-contrastive objective with EM algorithm. (在这一部分中,我们介绍了总体损失和EM算法对所提出的原型对比目标的优化。)
3.4.1 Overall Training Objective. (总体训练目标)
- As the main target of the collaborative filter is to model the interactions between users and items, we treat the proposed two contrastive learning losses as supplementary and leverage a multi-task learning strategy to jointly train the traditional ranking loss and the proposed contrastive loss. (由于协同过滤的主要目标是对用户和项目之间的交互进行建模,我们将提出的两个对比学习损失作为补充,并利用多任务学习策略来联合训练传统的排名损失和提出的对比损失。)

- where λ 1 \lambda_1 λ1, λ 2 \lambda_2 λ2 and λ 3 \lambda_3 λ3 are the hyper-parameters to control the weights of the proposed two objectives and the regularization term, respectively, (分别是控制所提出的两个目标和正则化项权重的超参数)
- and Θ \Theta Θ denotes the set of GNN model parameters. (表示GNN模型参数集)
3.4.2 Optimize L P \mathcal{L}_P LP with EM algorithm.
-
(1) As Eq. (9) is hard to optimize, we obtain its Lower-Bound (LB) by Jensen’s inequality:
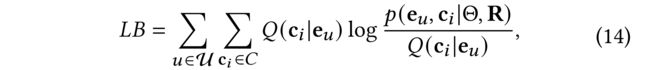
- where Q ( c i ∣ e u ) Q (c_i | e_u) Q(ci∣eu) denotes the distribution of latent variable c i c_i ci when e u e_u eu is observed. (表示潜当 e u e_u eu观察到时,潜在变量 c i c_i ci的分布)(可以通过K-均值算法在所有用户 E E E的嵌入上进行估计)
- The target can be redirected to maximize the function over e u e_u eu when Q ( c i ∣ e u ) Q (c_i | e_u) Q(ci∣eu) is estimated. (当 Q ( c i ∣ e u ) Q (c_i | e_u) Q(ci∣eu)别评估,目标可以重定向去最大化基于 e u e_u eu的函数)
- The optimization process is formulated in EM algorithm. (优化过程用EM算法描述。)
-
(2) In the E-step, e u e_u eu is fixed and Q ( c i ∣ e u ) Q (c_i | e_u) Q(ci∣eu) can be estimated by K-means algorithm over the embeddings of all users E E E. (可以通过K-均值算法在所有用户 E E E的嵌入上进行估计)
- If user u u u belongs to cluster i i i, then the cluster center c i c_i ci is the prototype of the user. (如果用户 u u u属于集群 i i i,那么集群中心 c i c_i ci是用户的原型。)
- And the distribution is estimated by a hard indicator Q ^ ( c i ∣ e u ) = 1 \hat{Q} (c_i | e_u) = 1 Q^(ci∣eu)=1 for c i c_i ci and Q ^ ( c j ∣ e u ) = 0 \hat{Q} (c_j | e_u) = 0 Q^(cj∣eu)=0 for other prototypes c j c_j cj.
-
(3) In the M-step, the target function can be rewritten with Q ^ ( c i ∣ e u ) \hat{Q} (c_i | e_u) Q^(ci∣eu): (在M步中,目标函数可以写为)
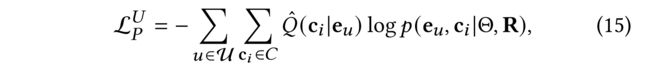
-
(4) we can assume that the distrubution of users is isotropic Gaussian over all the clusters. So the function can be written as: (我们可以假设用户在所有集群上的分布是各向同性的高斯分布。所以这个函数可以写成)
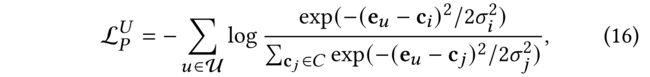
- As x u x_u xu and c i c_i ci are normalizated beforehand, then ( e u − c i ) 2 = 2 − 2 e u ⋅ c i (e_u − c_i) ^ 2 = 2 − 2e_u · c_i (eu−ci)2=2−2eu⋅ci. ( x u x_u xu和 c i c_i ci都是先前归一化的,)
- Here we make an assumption that each Gussian distribution has the same derivation, which is written to the temperature hyperparameter τ \tau τ. (在这里,我们假设每个高斯分布都有相同的导数,它被写入温度超参数 τ \tau τ。)
- Therefore, the function can be simplified as Eq. (10). (因此,该函数可以简化为等式(10))
3.5 Discussion
3.5.1 Novelty and Differences. (创新和不同)
-
(1) For graph collaborative filtering, the construction of neighborhood is more important than other collaborative filtering methods [36], since it is based on the graph structure. (对于图协同过滤,邻域的构建比其他协同过滤方法更重要[36],因为它基于图结构。)
- To our knowledge, it is the first attempt that leverages both structural and semantic neighbors for graph collaborative filtering. (据我们所知,这是首次尝试利用结构和语义邻居进行图形协同过滤。)
- Although several works [14, 16, 21] treat either structural or sematic neighbors as positive contrastive pairs, our work differs from them in several aspects. (虽然有几个工作[14,16,21]将结构或语义邻域视为积极对比对,但我们的工作在几个方面与它们不同。)
- For structural neighbors, existing graph contrastive learning methods [8, 17, 33, 34, 44] mainly take augmented representations as positive samples, while we take locally aggregated representations as positive samples. (对于结构邻居,现有的图对比学习方法[8,17,33,34,44]主要将 增强表示 作为正样本,而我们将 局部聚集表示 作为 正样本。)
- Besides, we don’t introduce additional graph construction or neighborhood iteration, making NCL more efficient than previous works (e.g., SGL [33]). (此外,我们没有引入额外的图构造或邻域迭代,使得NCL比以前的工作(例如SGL[33])更有效。)
- Besides, some works [21, 34, 44] make the contrast between the learned node representations and the input node features, while we make the contrast with representations of homogeneous neighbors, which is more suited to the recommendation task. (此外,一些文献[21,34,44]将学习到的节点表示与输入节点特征进行了对比,而我们将学习到的节点表示与同质邻居的表示进行了对比,这更适合于推荐任务。)
-
(2) Furthermore, semantic neighbors have seldom been explored in GNNs for recommendation, while semantic neighbors are necessary to be considered for graph collaborative filtering due to the sparse, noisy interaction graphs. (此外,在GNNs中,语义邻居很少被用于推荐,而由于交互图稀疏、有噪声,在图协同过滤中需要考虑语义邻居。)
- In this work, we apply the prototype learning technique to capture the semantic information, which is different from previous works from computer vision [14] and graph mining [11, 16, 38]. (在这项工作中,我们应用原型学习技术来捕获语义信息,这与计算机视觉[14]和图形挖掘[11,16,38]的以往工作不同。)
- First, they aim to learn the inherent hierarchical structure among instances, while we aim to identify nodes with similar preferences/characteristics by capturing underlying associations. (首先,它们的目标是了解实例之间固有的层次结构,而我们的目标是通过捕获潜在关联来识别具有相似偏好/特征的节点。)
- Second, they model prototypes as clusters of independent instances, while we model prototypes as clusters of highly related users (or items) with similar interaction behaviors. (其次,他们将原型建模为独立实例的集群,而我们将原型建模为具有相似交互行为的高度相关用户(或项目)的集群。)
3.5.2 Time and Space Complexity.
- (1) In the proposed two contrastive learning objectives, assume that we sample S S S users or items as negative samples. (在提出的两个对比学习目标中,假设我们抽样 S S S个用户或项目作为负样本。)
- (2) Then, the time complexity of the proposed method can be roughly estimated as O ( N ⋅ ( S + K ) ⋅ d ) O(N · (S + K) · d) O(N⋅(S+K)⋅d) (然后,该方法的时间复杂度可以粗略估计为)
- where N N N is the total number of users and items, (其中 N N N是用户和项目的总数)
- K K K is the number of prototypes we defined (是我们定义的原型数量)
- and d d d is the dimension embedding vector. (是嵌入向量的维数)
- (3) When we set S ≪ N S \ll N S≪N and S ≪ N S\ll N S≪N the total time complexity is approximately linear with the number of users and items. (总时间复杂度与用户数和项目数近似线性。)
- (4) As for the space complexity, the proposed method does not introduce additional parameters besides the GNN backbone. (在空间复杂度方面,除了GNN主干外,该方法没有引入额外的参数。)
- (5) In particular, our NCL save nearly half of space compared to other self-supervised methods (e.g., SGL [33]), as we explicitly utilize the relation within users and items instead of explicit data augmentation. (特别是,与其他 自监督方法(如 SGL [33])相比,我们的NCL节省了近一半的空间,因为我们明确利用了用户和项目之间的关系,而不是明确的数据扩充。)
- (6) In a word, the proposed NCL is an efficient and effective contrastive learning paradigm aiming at collaborative filtering tasks. (总之,NCL是一种针对协同过滤任务的高效对比学习范式。)
4 EXPERIMENTS
- To verify the effectiveness of the proposed NCL, we conduct extensive experiments and report detailed analysis results. (为了验证所提出的NCL的有效性,我们进行了大量实验,并报告了详细的分析结果。)
4.1 Experimental Setup
4.1.1 Datasets.
- (1) To evaluate the performance of the proposed NCL, we use five public datasets to conduct experiments: (为了评估提议的NCL的性能,我们使用五个公共数据集进行实验)
- MovieLens-1M (ML-1M) [7], Yelp1, Amazon Books [18], Gowalla [4] and Alibaba-iFashion [3].
- These datasets vary in domains, scale, and density. (这些数据集在域、规模和密度上各不相同)
- For Yelp and Amazon Books datasets, we filter out users and items with fewer than 15 interactions to ensure data quality. (对于Yelp和Amazon Books数据集,我们筛选出少于15次交互的用户和项目,以确保数据质量。)
- The statistics of the datasets are summarized in Table 1. (表1总结了数据集的统计数据。)
- For each dataset, we randomly select 80% of interactions as training data and 10% of interactions as validation data. (对于每个数据集,我们随机选择80%的交互作为培训数据,10%的交互作为验证数据。)
- The remaining 10% interactions are used for performance comparison. (其余10%的交互用于性能比较。)
- We uniformly sample one negative item for each positive instance to form the training set. (我们为每一个积极的例子均匀地抽样一个消极的项目来形成训练集。)

4.1.2 Compared Models.
We compare the proposed method with the following baseline methods. (我们将提出的方法与以下基线方法进行比较)
- −BPRMF[22] optimizes the BPR loss to learn the latent representations for users and items with matrix factorization (MF) framework. (使用 矩阵分解(MF) 框架优化 BPR损失,以了解用户和项目的潜在表示。)
- − NeuMF [10] replaces the dot product in MF model with a multilayer perceptron to learn the match function of users and items. (用多层感知器代替MF模型中的 点积 ,学习用户和项目的 匹配函数。)
- − FISM [12] is an item-based CF model which aggregates the representation of historical interactions as user interest. (是一个 基于项目的CF模型 ,它将历史交互的表示聚合为用户兴趣。)
- − NGCF [31] adopts the user-item bipartite graph to incorporate high-order relations and utilizes GNN to enhance CF methods. (采用用户项二部图合并 高阶 关系,并利用 GNN 增强CF方法。)
- − Multi-GCCF [27] propagates information among high-order correlation users (and items) besides user-item bipartite graph. (除了用户项二部图之外,在高阶 相关用户(和项)之间 传播信息。)
- − DGCF [32] produces disentangled representations for user and item to improve the performance of recommendation. (为用户和项目生成分离的表示,以提高推荐的性能。)
- − LightGCN [9] simplifies the design of GCN to make it more concise and appropriate for recommendation. (简化了GCN的设计,使其更简洁,更适合推荐。)
- − SGL [33] introduces self-supervised learning to enhance recommendation. (引入自监督学习以增强推荐。)
- We adopt SGL-ED as the instantiation of SGL. (我们采用SGL-ED作为SGL的实例化。)
4.1.3 Evaluation Metrics.
- To evaluate the performance of top- K K K recommendation, we adopt two widely used metrics (为了评估top K推荐的性能,我们采用了两个广泛使用的指标)
- Recall@ K K K
- and NDCG@ K K K,
- where K K K is set to 10, 20 and 50 for consistency.
- Following [9, 33], we adopt the full-ranking strategy [42], which ranks all the candidate items that the user has not interacted with. (在[9,33]之后,我们采用了 完整的排名策略 [42],对用户未交互的所有候选项进行排名。)
4.1.4 Implementation Details. (实施细节)
- We implement the proposed model and all the baselines with RecBole2[43], https://github.com/RUCAIBox/RecBole (我们用RecBole实现了所提出的模型和所有基线)
- which is a unified opensource framework to develop and reproduce recommendation algorithms. (这是一个统一的开源框架,用于开发和再生产推荐算法。)
- To ensure a fair comparison, we optimize all the methods with Adam optimizer and carefully search the hyper-parameters of all the baselines. (为了确保公平比较,我们使用Adam optimizer对所有方法进行优化,并仔细搜索所有基线的超参数。)
- The batch size is set to 4,096
- and all the parameters are initialized by the default Xavier distribution. (所有参数都由默认的Xavier分布初始化。)
- The embedding size is set to 64.
- We adopt early stopping with the patience of 10 epoch to prevent overfitting,
- and NDCG@10 is set as the indicator.
- We tune the hyper-parameters λ 1 \lambda_1 λ1 and λ 2 \lambda_2 λ2 in [1e-10,1e-6],
- τ \tau τ in [0.01,1]
- and k k k in [5,10000].
4.2 Overall Performance (整体表现)

Table 2 shows the performance comparison of the proposed NCL and other baseline methods on five datasets. From the table, we find several observations: (表2显示了提出的NCL和其他基线方法在五个数据集上的性能比较。从表中,我们发现了几个观察结果:)
-
(1) Compared to the traditional methods, such as BPRMF, GNN-based methods outperform as they encode the high-order information of bipartite graphs into representations. (与传统的方法(如BPRMF)相比,基于GNN的方法在将二部图的高阶信息编码为表示时表现更好。)
- Among all the graph collaborative filtering baseline models, LightGCN performs best in most datasets, which shows the effectiveness and robustness of the simplified architecture [9]. (在所有图协同过滤基线模型中,LightGCN在大多数数据集中表现最好,这表明了简化架构的有效性和健壮性[9]。)
- Surprisingly, Multi-GCCF performs worse than NGCF on ML-1M, probably because the projection graphs built directly from user-item graphs are so dense that the neighborhoods of different users or items on the projection graphs are overlapping and indistinguishable. (令人惊讶的是,Multi-GCCF在ML-1M上的性能比NGCF差,这可能是因为直接从用户项目图构建的投影图非常密集,以至于投影图上不同用户或项目的邻域重叠且无法区分。)
- Besides, the disentangled representation learning method DGCF is worse than LightGCN, especially on the sparse dataset. (此外,解耦表示学习方法DGCF比LightGCN更差,尤其是在稀疏数据集上。)
- We speculate that the dimension of disentangled representation may be too low to carry adequate characteristics as we astrict the overall dimension. (我们推测,当我们限制整体维度时,解构表征的维度可能太低,无法承载足够的特征。)
- In addition, FISM performs better than NGCF on three datasets (ML-1M, Yelp, and AmazonBooks), indicating that a heavy GNN architecture is likely to overfit over sparse user-item interaction data. (此外,FISM在三个数据集(ML-1M、Yelp 和 AmazonBooks)上的性能优于NGCF,这表明重型GNN体系结构可能会过度拟合稀疏的用户项交互数据。)
-
(2) For the self-supervised method, SGL [33] consistently outperforms other supervised methods on five datasets, which shows the effectiveness of contrastive learning for improving the recommendation performance. (对于自监督方法,SGL [33]在五个数据集上始终优于其他监督方法,这表明了对比学习对于提高推荐性能的有效性。)
- However, SGL contrasts the representations derived from the original graph with an augmented graph, which neglects other potential relations (e.g., user similarity) in recommender systems. (然而,SGL将源于原始图的表示与增广图进行了对比,增广图忽略了推荐系统中的其他潜在关系(例如,用户相似性)。)
-
(3) Finally, we can see that the proposed NCL consistently performs better than baselines. (最后,我们可以看到,提议的NCL始终比基线表现更好。)
- This advantage is brought by the neighborhood-enriched contrastive learning objectives. (这种优势是由丰富的对比学习目标带来的。)
- Besides, the improvement at smaller positions (e.g., top 10 ranks) is greater than that at larger positions (e.g., top 50 ranks), indicating that NCL tends to rank the relevant items higher, which is significative in real-world recommendation scenario. (此外,较小位置(如前10名)的改善程度大于较大位置(如前50名)的改善程度,表明NCL倾向于将相关项目排名更高,这在现实推荐场景中很有意义。)
- In addition, our method yields more improvement on small datasets, such as ML-1M and Yelp datasets. (此外,我们的方法对小型数据集(如ML-1M和Yelp数据集)有更大的改进。)
- We speculate that a possible reason is that the interaction data of those datasets are more sparse, and there are not sufficient neighbors to construct the contrastive pairs. (我们推测一个可能的原因是这些数据集的交互数据更稀疏,并且没有足够的邻居来构建对比对。)
4.3 Further Analysis of NCL
- In this section, we further perform a series of detailed analysis on the proposed NCL to confirm its effectiveness. Due to the limited
space, we only report the results on ML-1M and Yelp datasets, and the observations are similar on other datasets. (在本节中,我们进一步对提议的NCL进行了一系列详细分析,以确认其有效性。由于篇幅有限,我们仅在ML-1M和Yelp数据集上报告结果,在其他数据集上的观察结果类似。)
4.3.1 Ablation Study of NCL.
- Our proposed approach NCL leverages the potential neighbors in two aspects. (我们提出的方法NCL在两个方面利用了潜在的邻居。)
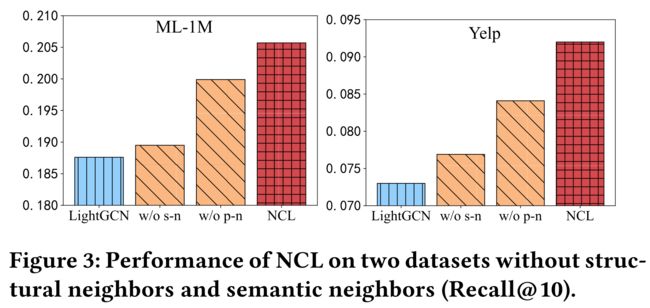
- To verify the effectiveness of each kind of neighbor, we conduct the ablation study to analyze their contribution. (为了验证每种邻居的有效性,我们进行了消融研究,以分析它们的贡献。)
- The results are reported in Figure 3, where “w/o s-n” and “w/o p-n” denote the variants by removing structural neighbors and semantic neighbors, respectively. (结果如图3所示,“w/o s-n”和“w/o p-n”分别通过删除结构邻居和语义邻居来表示变体。)
- From this figure, we can observe that removing each of the relations leads to the performance decrease while the two variants are both perform better than the baseline LightGCN. (从这个图中,我们可以观察到,删除每个关系都会导致性能下降,而这两个变量都比基线LightGCN性能更好。)
- It indicates that explicitly modeling both kinds of relations will benefit the performance in graph collaborative filtering. (这表明,对这两种关系进行显式建模将有助于提高图形协同过滤的性能。)
- Besides, these two relations complement each other and improve the performance in different aspects. (此外,这两种关系相辅相成,在不同方面提高了绩效。)
4.3.2 Impact of Data Sparsity Levels. (数据稀疏程度的影响)
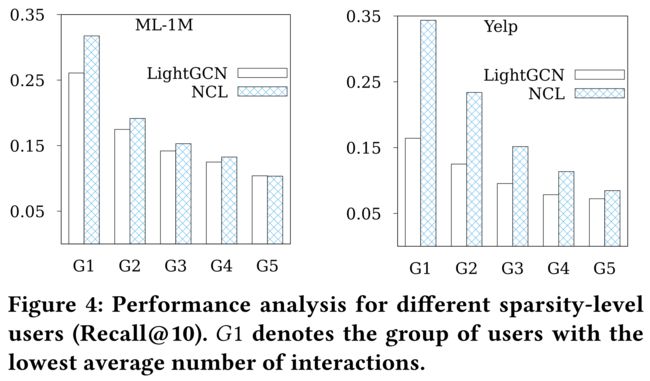
- To further verify the proposed NCL can alleviate the sparsity of interaction data, we evaluate the performance of NCL on users with different sparsity levels in this part. (为了进一步验证所提出的NCL能够缓解交互数据的稀疏性,我们在这一部分评估了NCL在不同稀疏度用户上的性能。)
- Concretely, we split all the users into five groups based on their interaction number, while keeping the total number of interactions in each group constant. (具体来说,我们根据用户的交互次数将所有用户分成五个组,同时保持每个组中的交互总数不变。)
- Then, we compare the recommendation performance of NCL and LightGCN on these five groups of users and report the results in Figure 4. (然后,我们比较了NCL和LightGCN在这五组用户上的推荐性能,结果如图4所示。)
- From this figure, we can find that the performance of NCL is consistently better than LightGCN. (从这个图中,我们可以发现NCL的性能始终优于LightGCN。)
- Meanwhile, as the number of interactions decreases, the performance gain brought by NCL increases. (同时,随着交互次数的减少,NCL带来的性能增益也会增加。)
- This implies that NCL can perform high-quality recommendation with sparse interaction data, benefited by the proposed neighborhood modeling techniques. (这意味着NCL可以利用稀疏的交互数据执行高质量的推荐,受益于提出的邻域建模技术。)
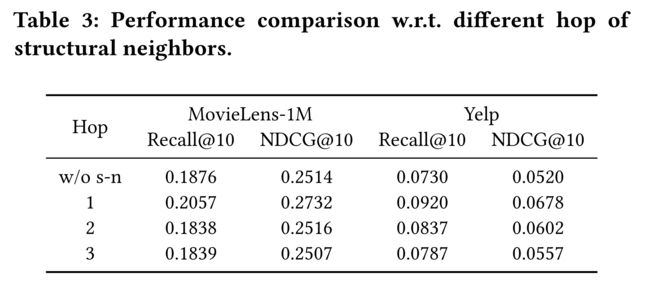
4.3.3 Effect of Structural Neighbors. (结构邻居的效应)
-
(1) In NCL , the structural neighbors correspond to different layers of GNN. To investigate the impact of different structural neighbors, we select the nodes in one-, two-, and three-hop as the structural neighbors and test the effectiveness when incorporating them with contrastive learning. (在NCL中,结构邻居对应于GNN的不同层。为了研究不同结构邻居的影响,我们选择一跳、二跳和三跳中的节点作为结构邻居,并测试它们与对比学习结合时的有效性。)
-
(2) The results are shown in Table 3. We can find that the three variants of NCL all perform similar or better than LightGCN, which further indicates the effectiveness of the proposed hop-contrastive strategy. (结果如表3所示。我们可以发现,NCL的三个变体的性能都与LightGCN相似或更好,这进一步表明了所提出的hop对比策略的有效性。)
- Specifically, the results of the first even layer are the best among these variants. (具体来说,第一个偶数层的结果是这些变体中最好的。)
- This accords with the intuition that users or items should be more similar to their direct neighbors than indirect neighbors. (这符合一种直觉,即用户或项目应该与其直接邻居更相似,而不是间接邻居。)
- Besides, in our experiments, one-hop neighbors seem to be sufficient for NCL , making a good trade-off between effectiveness and efficiency. (此外,在我们的实验中,单跳邻居似乎足以实现NCL,在有效性和效率之间做出了很好的权衡。)
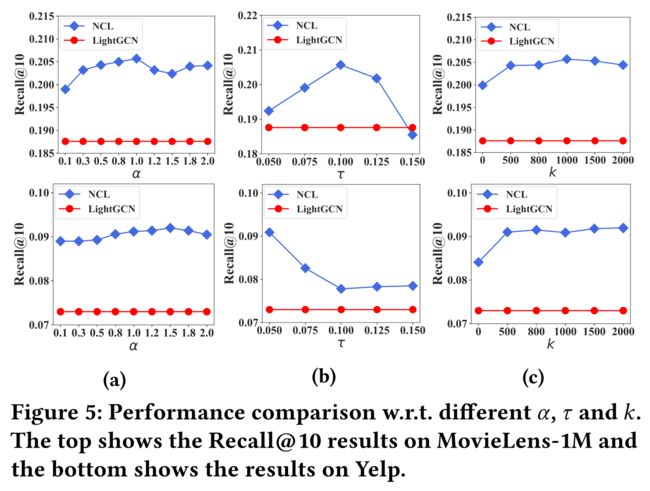
4.3.4 Impact of the Coefficient α \alpha α. (系数α的影响)
- In the structure-contrastive loss defined in Eq. (8), the coefficient α \alpha α can balance the two losses for structural neighborhood modeling. (在等式(8)中定义的结构对比损失中,系数 α \alpha α可以平衡结构邻域建模的两种损失)
- To analyze the influence of α \alpha α, we vary α \alpha α in the range of 0.1 to 2 and report the results in Figure 5a. (为了分析 α \alpha α的影响,我们在0.1到2的范围内改变α,并在图5a中报告结果。)
- It shows that an appropriate α \alpha α can effectively improve the performance of NCL. (结果表明,合适的 α \alpha α可以有效地提高NCL的性能。)
- Specifically, when the hyperparameter α \alpha α is set to around 1, the performance is better on both datasets, indicating that the high-order similarities of both users and goods are valuable. (具体来说,当超参数 α \alpha α设置为1左右时,两个数据集的性能都会更好,这表明用户和商品的高阶相似性是有价值的。)
- In addition, with different α \alpha α, the performance of NCL is consistently better than that of LightGCN, which indicates that NCL is robust to parameter α \alpha α. (此外,对于不同的 α \alpha α,NCL的性能始终优于LightGCN,这表明NCL对参数 α \alpha α具有鲁棒性。)
4.3.5 Impact of the Temperature τ \tau τ.
- As in previous works mentioned [2, 41], the temperature τ \tau τ defined in Eq.(6) and Eq.(10) plays an important role in contrastive learning. (正如前面提到的[2,41]一样,式(6)和式(10)中定义的温度 τ \tau τ在对比学习中起着重要作用。)
- To analyze the impact of temperature on NCL, we vary τ \tau τ in the range of 0.05 to 0.15 and show the results in Figure 5(b). (为了分析温度对NCL的影响,我们在0.05到0.15的范围内改变 τ \tau τ,结果如图5(b)所示。)
- We can observe that a too large value of τ \tau τ will cause poor performance, which is consistent with the experimental results reported in [41]. (我们可以观察到, τ \tau τ值太大会导致性能不佳,这与[41]中报道的实验结果一致。)
- In addition, the suitable temperature corresponding to Yelp dataset is smaller, which indicates that the temperature of NCL should be smaller on more sparse datasets. (此外,Yelp数据集对应的适宜温度较小,这表明在更稀疏的数据集上,NCL的温度应该较小。)
- Generally, a temperature in the range of [0.05,0.1] can lead to good recommendation performance. (一般来说,温度在[0.05,0.1]范围内可以产生良好的推荐性能。)
4.3.6 Impact of the Prototype Number k k k. (原型数量 k k k的影响)
- To study the effect of prototype-contrastive objective, we set the number of prototypes k k k from hundreds to thousands and remove it by setting k k k as zero. (为了研究原型对比目标的效果,我们将原型数量 k k k从数百个设置为数千个,并通过将 k k k设置为零来消除它。)
- The results are reported in Figure 5 ( c ). As shown in Figure 5( c ), NCL with different k k k consistently outperforms the baseline and the best result is achieved when k k k is around 1000. (结果如图5©所示。如图5©所示,具有不同 k k k的NCL始终优于基线,当 k k k在1000左右时达到最佳结果。)
- It indicates that a large number of prototypes can better the noise introduced by structural neighbors. (这表明,大量的原型可以改善结构邻居引入的噪声。)
- When we set k k k as zero, the performance decreases significantly, which shows that semantic neighbors are very useful to improve the recommendation performance. (当 k k k为零时,性能会显著下降,这表明语义邻居对提高推荐性能非常有用)
4.3.7 Applying NCL on Other GNN Backbones. (在其他GNN主干上应用NCL)
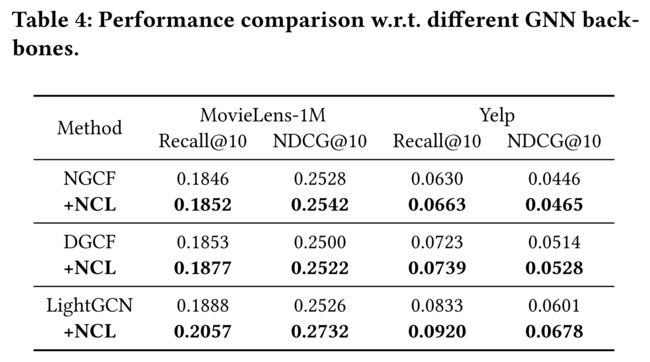
-
(1) As the proposed NCL architecture is model agnostic, we further test its performance with other GNN architectures. The results are reported in Table 4. (由于所提出的NCL体系结构是模型无关的,因此我们将用其他GNN体系结构进一步测试其性能。结果见表4。)
-
(2) From this table, we can observe that the proposed method can consistently improve the performance of NGCF, DGCF, and LightGCN, which further verifies the effectiveness of the proposed method. (从这个表中,我们可以观察到,所提出的方法可以持续改善NGCF、DGCF和LightGCN的性能,这进一步验证了所提出方法的有效性。)
- Besides, the improvement on NGCF and DGCF is not as remarkable as the improvement on LightGCN. (此外,NGCF和DGCF的改善不如LightGCN的改善显著。)
- A possible reason is that LightGCN removes the parameter and non-linear activation in layer propagation which ensures the output of different layers in the same representation space for structural neighborhood modeling. (一个可能的原因是,LightGCN消除了层传播中的参数和非线性激活,从而确保在结构邻域建模的相同表示空间中不同层的输出。)
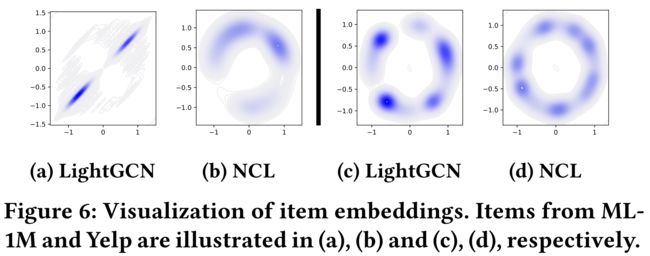
4.3.8 Visualizing the Distribution of Representations. (可视化表示的分布)
- A key contribution of the proposed NCL is to integrate two kinds of neighborhood relations in the contrastive tasks for graph collaborative filtering. (提出的NCL的一个关键贡献是将两种邻域关系整合到图形协同过滤的对比任务中。)
- To better understand the benefits brought by NCL, we visualize the learned embeddings in Figure 6 to show how the proposed approach affects representation learning. (为了更好地理解NCL带来的好处,我们将图6中学习到的嵌入可视化,以展示所提出的方法如何影响表征学习。)
- We plot item embedding distributions with Gaussian kernel density estimation (KDE) in two-dimensional space. We can see that, embeddings learned by LightGCN fall into several coherent clusters, while those representations learned by NCL clearly exhibit a more uniform distribution. (我们用**高斯核密度估计(KDE)**在二维空间绘制项目嵌入分布。我们可以看到,LightGCN学习到的嵌入分为几个连贯的簇,而NCL学习到的那些表示显然表现出更均匀的分布。)
- We speculate that a more uniform distribution of embeddings endows a better capacity to model the diverse user preferences or item characteristics. (我们推测,更均匀的嵌入分布可以更好地模拟不同的用户偏好或项目特征。)
- As shown in previous studies [30], there exists strong correlation between contrastive learning and uniformity of the learned representations, where it prefers a feature distribution that preserves maximal information about representations. (如之前的研究[30]所示,对比学习和学习表征的一致性之间存在着很强的相关性,它更倾向于保留表征的最大信息的特征分布。)
5 RELATED WORK
- In this section, we briefly review the related works in two aspects, namely graph-based collaborative filtering and contrastive learning. (在这一部分中,我们从两个方面简要回顾了相关的工作,即基于图的协同过滤和对比学习。)
5.1 Graph-based collaborative filtering. (基于图形的协同过滤)
- Different from traditional CF methods, such as matrix factorization-based methods [13, 22] and auto-encoder-based methods [15, 25], graph-based collaborative filtering organize interaction data into an interaction graph and learn meaningful node representations from the graph structure information. (与传统的CF方法不同,如基于矩阵分解的方法[13,22]和基于自动编码器的方法[15,25],基于图的协同过滤将交互数据组织到交互图中,并从图结构信息中学习有意义的节点表示。)
- Early studies [1, 6] extract the structure information through random walks in the graph. (早期研究[1,6]通过图中的随机游走提取结构信息。)
- Next, Graph Neural Networks (GNN) are adopted on collaborative filtering [9,31,32,40]. (接下来,将图神经网络(GNN)用于协同过滤[9,31,32,40]。)
- For instance, NGCF [31] and LightGCN [9] leverage the high-order relations on the interaction graph to enhance the recommendation performance. (例如,NGCF[31]和LightGCN[9]利用交互图上的高阶关系来提高推荐性能。)
- Besides, some studies [27] further propose to construct more interaction graphs to capture more rich association relations among users and items. (此外,一些研究[27]进一步建议构建更多的交互图,以捕获用户和项目之间更丰富的关联关系。)
- Despite the effectiveness, they don’t explicilty address the data sparsity issue. (尽管有效,但它们并没有明确地解决数据稀疏性问题。)
- More recently, self-supervised learning is introduced into graph collaborative filtering to improve the generalization of recommendation. (最近,自监督学习被引入到图协同过滤中,以提高推荐的泛化能力。)
- For example, SGL [33] devise random data argumentation operator and construct the contrastive objective to improve the accuracy and robustness of GCNs for recommendation. (例如,SGL[33]设计了随机数据论证算子,并构建了对比目标,以提高推荐GCN的准确性和稳健性。)
- However, most of the graph-based methods only focus on interaction records but neglect the potential neighbor relations among users or items. (然而,大多数基于图的方法只关注交互记录,而忽略了用户或项目之间潜在的邻居关系。)
5.2 Contrastive learning. (对比学习)
- Since the success of contrastive learning in CV [2], contrastive learning has been widely applied on NLP [5], graph data mining [17, 34] and recommender systems [28, 37]. (自对比学习在CV[2]中取得成功以来,对比学习已广泛应用于NLP[5]、图数据挖掘[17,34]和推荐系统[28,37]。)
- As for graph contrastive learning, existing studies can be categorized into node-level contrastive learning [29, 45] and graph-level contrastive learning [26, 41]. (关于图对比学习,现有的研究可分为节点级对比学习[29,45]和图级对比学习[26,41]。)
- For instance, GRACE [44] proposes a framework for node-level graph contrastive learning, and performs corruption by removing edges and masking node features. (例如,GRACE[44]提出了一个用于节点级图对比学习的框架,并通过删除边缘和屏蔽节点特征来执行损坏。)
- MV- GRL [8] transforms graphs by graph diffusion, which considers the augmentations in both feature and structure spaces on graphs. (MV-GRL[8]通过图扩散对图进行变换,它考虑了图的特征空间和结构空间的增广。)
- Besides,inspired by the pioneer study in computer vision [14], several methods [11, 16, 38] are proposed to adopt prototypical contrastive learning to capture the semantic information in graphs. (此外,受计算机视觉先驱研究[14]的启发,提出了几种方法[11,16,38]来采用原型对比学习来捕获图形中的语义信息。)
- Related to our work, several studies also apply contrastive learning to recommendation, such as SGL [33]. (与我们的工作相关的几项研究也将对比学习应用于推荐,例如SGL[33]。)
- However, existing methods construct the contrastive pairs by random sampling, and do not fully consider the relations among users (or items) in recommendation scenario. (然而,现有的方法通过随机抽样来构造对比对,而没有充分考虑推荐场景中用户(或项目)之间的关系。)
- In this paper, we propose to explicilty model these potential neighbor relations via contrastive learning. (在本文中,我们建议通过对比学习来明确地建模这些潜在的邻居关系。)
6 CONCLUSION AND FUTURE WORK
-
(1) In this work, we propose a novel contrastive learning paradigm, named Neighborhood-enriched Contrastive Learning (NCL), to explicitly capture potential node relatedness into contrastive learning for graph collaborative filtering. (在这项工作中,我们提出了一种新的对比学习范式,称为邻域丰富的对比学习(NCL),以明确地捕捉潜在的节点关联性,用于图协同过滤的对比学习)
- We consider the neighbors of users (or items) from the two aspects of graph structure and semantic space, respectively. (我们从图形结构和语义空间两个方面考虑用户(或项目)的邻居。)
- Firstly, to leverage structural neighbors on the interaction graph, we develop a novel structure-contrastive objective that can be combined with GNN-based collaborative filtering methods. (首先,为了利用交互图上的结构邻居,我们开发了一种新的结构对比目标,可以与基于GNN的协同过滤方法相结合。)
- Secondly, to leverage semantic neighbors, we derive the prototypes of users/items by clustering the embeddings and incorporating the semantic neighbors into the prototype-contrastive objective. (其次,为了利用语义邻域,我们通过聚类嵌入并将语义邻域合并到原型对比目标中,来获得用户/项目的原型。)
- Extensive experiments on five public datasets demonstrate the effectiveness of the proposed NCL . (在五个公共数据集上的大量实验证明了所提出的NCL的有效性。)
-
(2) As future work, we will extend our framework to other recommendation tasks, such as sequential recommendation. (作为未来的工作,我们将把我们的框架扩展到其他推荐任务,例如顺序推荐。)
- Besides, we will also consider developing a more unified formulation for leveraging and utilizing different kinds of neighbors. (此外,我们还将考虑制定一个更统一的公式来利用和利用不同种类的邻居。)
ACKNOWLEDGMENTS
References

A PSEUDO-CODE FOR NCL (NCL的伪代码)

B CASE STUDY ON SELECTED NEIGHBORS (关于选定邻居的案例研究)
- To further analyze the difference between structural neighbors and semantic neighbors, we randomly select a central item on Alibaba-iFashion dataset and extract its structural neighbors and semantic neighbors, respectively. (为了进一步分析结构邻居和语义邻居之间的差异,我们在Alibaba iFashion数据集中随机选择一个中心项,分别提取其结构邻居和语义邻居。)
- For the two types of neighbors extracted, we count the number of items in each category, respectively. (对于提取的两类邻居,我们分别统计每个类别中的项目数。)
- The number is normalized and visualized in Fig. 7. (数字在图7中被标准化和可视化。)
- For comparison, we also report the collection of randomly sampled items. (为了进行比较,我们还报告了随机抽样项目的收集情况。)
- As shown in the figure, the randomly sampled neighbors are uncontrollable, which astrict the potential of contrastive learning. (如图所示,随机抽样的邻居是不可控的,这限制了对比学习的潜力。)
- Meanwhile, the proposed structural and semantic neighbors are more related, which are more suitable to be contrastive pairs. (同时,所提出的结构和语义邻域更为相关,更适合作为对比对。)