《Convolutional 2D Knowledge Graph Embeddings》论文学习
问题提出背景:知识图谱的链路预测是预测实体之间确实关系的任务,以前的链路任务只集中在比较浅层次的还有快速的模型,这些可以用来扩展到大型知识图谱,但是这些模型比深度多层模型表达的特征更少,会限制其性能。
方法:在这里我们介绍了convE,一个用于链路预测的多层神经网络,并报告了几个已经建立好的数据集的最新的成果。
效果:它具有比较高的参数效率,它的性能跟DisMult和R-GCN相同,但是他的参数比这两个少了8倍和17倍。对我们的模型分析发现,它在建模高度结点的时候特别有效,这在连接具有高度连接的复杂知识图谱中很常见。
WN18和FB15k数据集存在测试集泄漏,这是由于测试集中存在与训练集的逆关系,然而,这个问题的程度迄今为止还没有被量化。一个简单的基于规则的模型能够在WN18和FB15上实现最先进的结果,为了避免单纯利用逆关系无法产生竞争性结果的数据集上进行评估,我们调查和验证几个常用的数据集,并在必要的地方派生健壮的变体,在这些健壮的数据集上面用我们自己的还有之前提出的模型进行实验,最终结果发现convE具有最大的平均倒数秩。
一句话总结:以往的链路任务基于快速的,浅层次的模型,它们表达的特征比较少。ConvE,一个基于链路预测的多神经网络模型,它性能和DisMult和R-GCN一样,但是参数少,在建模高度结点的时候很有效。WN18和FB15k存在测试集泄露,因为测试集跟训练集之间存在逆关系,为了避免逆关系的影响,我们在必要的地方派生出健壮的变体,通过对比实验发现convE具有最大的平均倒数秩。
Introduction
知识图谱是一种图结构的知识库,事实以边的形式表示,在搜索,分析,推荐还有数据集成方面有重要的应用,但是往往不完整,缺少图中的链接。比如在Freebase and DBpedia中超过66%的人缺少出生地。这种缺失的链接称之为链接预测。链接预测器应该以一种可管理的关于参数数量和计算成本的方式进行扩展。(链接预测器的模型应该综合参数数量和计算成本来选择)
DisMult就是这样的模型,使用嵌入空间的内积和矩阵乘法,并且使用有限的参数,特征就是嵌入参数之间的三项交互作用,每个参数表示一个特征,但是这只是基于快速的浅层的,它只能学习表达性比较低的特征。
所以为了避免这个问题,我们要增加特征数量从而增加表达性。在浅层模型上实现这一想法的唯一办法就是增加嵌入的大小。但是存在的问题是这并不能够扩展到更大的知识图谱,嵌入参数的总数和实体跟关系的数量成正比。Dismult嵌入大小为200的浅层模型,应用到freebase,需要33GB的内存。所以需要独立嵌入大小增加特征的数量。以往的知识图谱嵌入架构特点是全连接的层容易过拟合。为了避免过拟合跟浅层结构的缩放问题,我们需要使用高效、快速的深度学习算子。
- 特征数量 2.全连接深度结构过拟合)
提出了convE,用二位卷积预测知识图谱中缺失链接的模型。它是链路预测中最简单的多层卷积结构:由单个卷积层、嵌入到维数的投影层和内积层定义。
文章贡献:
- 介绍了convE(简单、有竞争力)
- 开发了1-N评分模型,训练速度提高了3倍,评估速度提高了300倍
- 参数效率高,在FB15k-237上,参数比DisMult和R-GCN少了8倍和17倍,获得的分数也比它们高
- 对于越来越复杂的知识图谱,我们模型跟浅层模型之间的差异也在成比例增加
- 关于测试集泄露问题,在必要时引入数据集的健壮版本,不能用简单的基于规则的模型解决
- 在稳健的数据集中评估convE跟之前提出的模型,发现convE具有最先进的平均倒数秩
一句话总结:convE好!简单,参数效率高,具有最先进的平均倒数秩。对于泄露问题,要引入健壮版本数据集。开发了评分模型,提高了训练速度跟评估速度。
Related Work
文献中也提出了几种神经链路预测模型,比如TransE、DistMult、ComplEx等,与文中模型相关的是全息嵌入模型HolE,它使用互相关-圆形卷积的倒数-来匹配实体的嵌入。但是它不能学习多层非线性特征,也不如我们的模型。
ConvE是第一个使用二位卷积层的神经链路预测模型,GCNs是一个相关的研究方向,它的卷积算子被推广到使用图中的局部信息。GCN仅仅使用无向图,知识图谱是有向的,并存在潜在的禁止性内存需求。R-GCNs是GCNs的一种推广,用来处理高度多关系的数据,比如知识图谱-我们把它包含在我们的实验评估中。
自然语言处理也提出了一些卷积模型来解决各种任务,但是它们大多数工作使用一维卷积,也就是在嵌入的时间序列上面操作的卷积。在这项工作中,我们使用空间嵌入上操作的二维卷积。
一维与二维卷积的交互数:
使用二维而不是一维卷积,通过嵌入之间的交互点,来增加模型的表现力,例如:考虑两行一维嵌入,或者两行二维嵌入,跟一维卷积相比,二维卷积可以模拟更多的特征交互。
Background
知识图谱可以用三元组进行表示,两个实体和一个关系,链接预测问题可以转换成一个点学习排序问题,目标就是学习一个打分函数,给定一个输入三元组x = (s, r, o),它的分数与它编码为真的可能性成正比。
Neural Link Predictors

表中是来自文献中的神经链路评分函数,它们的关系相关参数和空间复杂度。
一句话总结:就是用打分函数与三元组事实编码为真的可能性成正比,可以通过打分函数来进行神经链路预测
Convolutional 2D Knowledge Graphs Embeddings
卷积2D知识图嵌入
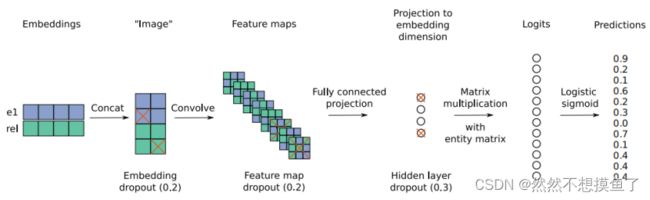
提出了神经链接预测模型,输入的实体跟关系二者之间的交互是由卷积和完全连接层进行建模的,模型的特点是评分,他是由一个卷积的二维形状嵌入定义的。它的架构在图1中进行了总结。以下是它的一个评分函数:


通过修正线性单元作为非线性函数进行更快的训练,并且在每一层后进行批量归一化从而实现稳定、规范还有提高收敛速度。通过在几个阶段使用dropout来调整我们的模型,比如在嵌入卷积操作后的特征映射以及完全连接层后面的隐藏单元上使用dropout。使用Adam作为优化器和使用标签平滑以减少由于标签上的输出非线性饱和而导致的过拟合。
Fast Evaluation for Link Prediction Tasks
链路预测任务的快速评估
在我们的体系结构中,卷积消耗了大约75-90%的时间,故最小化卷积的数量来尽可能的加快计算速度是很有必要的。I-N进行评分,在评分时间上提高超过了300倍。
图1:在ConvE模型中,实体和关系嵌入首先被重塑和连接(步骤1,2);然后将结果矩阵用作卷积层的输入(步骤3);得到的特征映射张量被向量化并投影到k维空间(步骤4),并与所有候选对象嵌入进行匹配
如果我们使用1-(0.1N)得分,而不是1-N得分——也就是说,对10%的实体得分——我们可以计算出25%的速度。然而,我们在训练集上的收敛速度大约慢了230%。因此,1-N评分有一个类似于批处理归一化的附加效果。
Experiments
知识图数据集
介绍了一些数据集WN18、FB15K、YAGO3-10、country等数据集。Toutanova和Chen(2015)首次发现WN18和FB15K存在试验泄露,例如测试集中有(s, hyponym, o),训练集中包含其逆(o,hypernym,s),为了避免这个问题,Toutanova和Chen(2015)引入了FB15k-237的一个子集FB15k,其中逆关系被删除。但是他们没有明确调查这个问题的严重性,也没有解决。(本文关注到了这一点,有没有解决呢?)
为了确保在没有逆关系测试的数据集上进行评估,推荐使用FB15k-237、WN18RR和YAGO3-10数据集。
Experimental Setup
我们根据验证集上的平均倒数秩(MRR),通过网格搜索来选择convE模型的超参数。网格搜索的范围如下:
嵌入dropout {0.0、0.1、0.2}、特征图dropout{0.0、0.1、0.2、0.3}、投影层dropout{0.0、0.1、0.3、0.5}、嵌入大小{100、200}、批大小{64、128、256}、学习率{0.001、0.003}、标签平滑{0.0、0.1、0.2、0.3}。
除了网格搜索外,我们还研究了对我们模型的二维卷积层的修改。采取过以下方法1,用全连接的层和一维卷积来代替它,但是降低了模型的预测精度。2、实验了不同大小的滤波器,只有当第一个卷积层使用小的滤波器,才能有良好的结果。
我们发现,以下参数组合对WN18、YAGO3-10和FB15k效果良好:嵌入dropout0.2,特征图dropout0.2,投影层dropout 0.3,嵌入大小200,批量大小128,学习率0.001,标签平滑0.1。国家数据集,我们将嵌入dropout增加到0.3,隐藏dropout增加到0.5,并将标签平滑设置为0。对于我们的1-1训练的干扰和补充结果,我们使用了一个为100的嵌入大小进行优化,我们通过在每次参数更新后强制实体嵌入的l2范数为1来规范我们的模型。

Inverse Model
Toutanova和Chen(2015)注意到,WN18和FB15k的训练数据集有94%和81%的测试泄漏为逆关系,即这些数据集中94%和81%的三元组与测试集有反向关系。这是很有问题的,在这些数据集上表现良好的链接预测器可能只是学习哪些关系与其他关系相反,而不是为实际的知识图建模。
解决办法:构建逆模型。从训练集中自动提取逆关系。例如:给定两个关系对r1,r2∈R,我们检查(s,r1,o)是否意味着(o,r2,s),或者反之亦然。
我们期望逆关系的数量与训练集的大小与总数据集的大小成正比。因此,因此,如果(s, r1, o)的存在与频率至少为0.99−(fv + ft)的(o, r2, s)同时出现,我们就可以检测出逆关系。
在测试时,我们检查测试三重是否在测试集之外有逆匹配:如果找到k个匹配,我们对这些匹配的前k个秩的排列进行抽样;如果没有找到匹配,我们为测试三重选择一个随机秩。
Results
我们对标准基准FB15k和WN18的结果如表3所示;去掉反向关系的数据集的结果如表4所示;对YAGO3-10和国家的结果如表5所示

ConvE在YAGO3-10的所有指标上都取得了最先进的性能,在FB15k的一些指标上,它在WN18上做得很好。在国家方面,它解决了S1和S2任务,在S3上表现良好,得分优于其他模型和cumulext。
ConvE参数效率
从表2中我们可以看到,在5个指标中,有3个参数的FB15k-237的ConvE优于有1.89M参数的DistMult。具有0.46M参数的ConvE在FB15k-237上仍然达到了0.425个最先进的结果。
对比之前的最佳模型,R-GCN(GCN等人,2017),在超过8M的参数下达到0.417次命中。
总体而言,ConvE比R-GCNs高17倍,参数效率比DistMult高8倍。对于整个Freebase,这些型号的大小将超过82GB,Distmult为21GB,而ConvE为5.2GB。