特征工程(五)—(1)特征选择_更好的特征
1、特征选择,何为更好的特征?
特征选择是从原始数据中选择对于预测流水线而言最好的特征的过程。特征选择会尝试剔除数据中的噪声。
在特征工程中,什么是更好的特征呢?可以从下面几个纬度进行考虑:
1、实现更好的预测性能,比如分类任务的准确率、回归任务的均方根误差;
2、模型拟合/训练所需要的时间;
3、拟合后的模型预测新的实例所花费的时间;
4、需要持久化的数据大小。
# 从sklearn中导入网格搜索模块
from sklearn.model_selection import GridSearchCV
# 创建一个函数,用来评估模型
def get_best_model_and_accuracy(model, params, X, y):
grid = GridSearchCV(model, # 要搜索的模型
params, # 要尝试的参数
error_score=0.0 # 如果报错,结果为0
)
# 拟合模型和参数
grid.fit(X, y)
# 经典的性能指标
print('最佳的准确率为:{}'.format(grid.best_score_))
# 得到最佳准确率的最佳参数
print('得到最佳准确率的最佳参数:{}'.format(grid.best_params_))
# 拟合的平均时间
print('拟合的平均时间:{} 秒'.format(round(grid.cv_results_['mean_fit_time'].mean(), 3)))
# 预测的平均时间
print('预测的平均时间:{} 秒'.format(round(grid.cv_results_['mean_score_time'].mean(), 3)))
2、案例:信用卡预期数据集
1、数据探索
'''
案例:信用卡预期数据集
特征选择算法可能从数据中提取最重要的信号并且忽略噪声。
能够提升模型的性能、减少训练和预测的时间。
'''
import pandas as pd
import numpy as np
# 随机数种子保证随机数永远一致
# np.random.seed(123)
# 利用pandas读取数据集
credit_card_default = pd.read_csv("../data/credit_card_default.csv")
# 30000行,24列
credit_card_default.shape
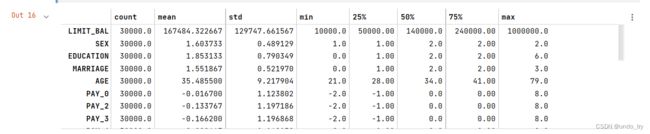
# 描述性统计
# 转置,方便观察
credit_card_default.describe().T
# default payment next month(下月逾期)是响应值,其他都是特征
# 检查缺失值
credit_card_default.isnull().sum()
# 可以看出 没有缺失值

# 构建特征矩阵和响应变量
X = credit_card_default.drop('default payment next month', axis=1)
y = credit_card_default['default payment next month']
# 取空准确率
y.value_counts(normalize=True)
# 可以看出空准确率为77.88%

2、选择合适的机器学习模型
# 寻找最符合需求的机器学习模型
# 导入4种模型
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
# 为网格搜索设置变量
# 1、先设置机器学习模型的参数
# 逻辑回归
lr_params = {
'C':[1e-1, 1e0, 1e1, 1e2],
'penalty':['l1', 'l2']
}
# KNN
knn_params = {
'n_neighbors':[1, 3, 5, 7]
}
# 决策树
tree_params = {
'max_depth':[None, 1, 3, 5, 7]
}
# 随机森林
forest_params = {
'n_estimators':[10, 50, 100],
'max_depth':[None, 1, 3, 5, 7]
}
# 2、实例化机器学习模型
lr = LogisticRegression()
knn = KNeighborsClassifier()
d_tree = DecisionTreeClassifier()
forest = RandomForestClassifier()
# 在所有的模型上运行评估函数(空准确率为77.88%)
# 逻辑回归
get_best_model_and_accuracy(lr, lr_params, X, y)

# knn
get_best_model_and_accuracy(knn, knn_params, X, y)

# 决策树
get_best_model_and_accuracy(d_tree, tree_params, X, y)

# 随机森林
get_best_model_and_accuracy(forest, forest_params, X, y)

'''
可以看出knn在拟合时间上表现更好,这是因为在拟合数据时候,knn只需要方便检索和及时处理的方法存储数据,但是值得注意的是,
knn的准确率不如空准确率,这是因为knn是按照欧几里得距离进行预测的,在非标准数据上可能会失效,而其他3种算法不受此影响。
因此,对于knn模型,为了更好评估knn模型,需要更复杂的流水线
'''
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
knn_pipe_params = {
'classifier__{}'.format(k): v for k,v in knn_params.items()
}
knn_pipe_params

knn_pipe = Pipeline(
[
('scale', StandardScaler()),
('classifier', knn)
]
)
get_best_model_and_accuracy(knn_pipe, knn_pipe_params, X, y)

'''
可以看出,加上z分数标准化处理后,预测的准确率高于空准确率,但是也影响了预测的时间,因为多了预处理步骤。
比较发现,决策树的准确率最高,而且拟合和预测的时间都较短,因此决策树是最适合下一步采用的模型。
注意:
这里使用在选择特征前选择模型,虽然不必要,但是在时间有限的情况下,这样做一般比较省时。
记住,在特征选择前,决策树的准确率是0.8206。后面进行特征选择。
'''