pytorch -YOLOV3 WIN10 CUDA10.1 使用过程
工程代码:https://github.com/eriklindernoren/PyTorch-YOLOv3
1, 配置
pytorch 1.6 cuda10.1 python3.6
libtorch1.6 cuda10.1
opencv-3.4.6-vc14_vc15
vs2017
我模型转换的工作是在ubuntu上的。
pytorch 1.6 的安装 ,建议用官网的安装方式:pip install torch==1.6.0+cu101 torchvision==0.7.0+cu101 -f https://download.pytorch.org/whl/torch_stable.html。我之前用anaconda 发现经常使用不上cuda,但是用pip就行。
libtorch1.6 也是直接官网选择对应配置的版本下载下来https://download.pytorch.org/libtorch/cu101/libtorch-win-shared-with-deps-1.6.0%2Bcu101.zip ,有release 和debug 版, 我用前者
opencv 我用3.4 的,官网下载,可执行程序执行完就行
vs2017 下载地址:可执行程序,执行即可
https://pan.baidu.com/s/1fNTe6z6jJscAXMrycPFwPQ
win10 cuda 安装。官网下载 https://developer.nvidia.com/cuda-toolkit-archive 选择自己的配置文件,2.4GB的可执行文件下载下来直接安装就好,这个比较顺利。
cudnn 的安装。 下载好cudnn后,解压,得到三个文件夹 bin, include ,lib 然后分别把这三个文件夹中的文件拷贝到cuda安装的文件夹对应的bin, include ,lib 下面, 一般cuda安装路径在 C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.1
win10 记得要安装驱动,安装好cuda10.1 检查自己的驱动版本,我的是1060显卡。由于之前一直在ubuntu 下跑window没装驱动折腾了好一会。到设备管理器中有显示适配器,查看显卡,双击它可以看到驱动程序。因为我之前没装,这里的显示适配器就没有NVIDIA 显卡的显示,结果我跑到NVIDIA官网下载https://www.nvidia.cn/Download/index.aspx?lang=cn,用了几个版本都不行提示不兼容,可我下载的都是对应的版本。而且选择版本的时候下载类型只有game ready 和studio,并没有standard。 然后我根据nvidia 报错提示出来的窗口的一个nvidia 地址进去,找到了相关驱动,并且有选择standard的版本。这个地址https://www.nvidia.com/Download/Find.aspx# 。结果我下载之后安装还是报错 不兼容。。。。。。心塞!
最后我找了很多资料,可行的办法是直接更新电脑程序。单击开始菜单进入-选择设置-更新和安全, 更新需要很长时间。然后重新启动,就有了下面这个显示适配器的图标 GTX1060。 如果cuda和驱动没装好,使用torch::cuda::is_availble() 会是0 或者False。我电脑更新完之后浏览器居然用不了。。。又折腾了我不少时间。
![]()
2,模型转换
2.1 模型下载
以上工程使用的预训练模型是原版Darknet的 yolov3.weights
下载地址:
2.2 Darknet 模型转为 pytorch 的.pth模型。 这个过程花了很长时间,之前找资料也说很多坑,发现很多人用tensorrt部署。
遇到很多报错,都是check_trace=False 这个参数没写上;
第一步:下载Darknet 版的yolov3.weights
第二部:使用以上工程代码加载模型:model.load_darknet_weights() 并保存为pytorch模型格式yolov3.pth:
torch.save(model.state_dict(), pytorch_model)第三步:用 torch.jit.trace convert 模型为 .pt 格式。 这里注意:参数check_trace=False,不然会报错
traced_script_module = torch.jit.trace(model, example,check_trace=False)参考:https://github.com/pytorch/pytorch/issues/23993
注意:torch.jit.trace()不支持控制流语句,需将models.py 中 if targets is None 以下语句注释掉,增加
return output,0 因为作为推断,所以注释掉的语句不影响。import numpy as np
import torch
# import torchsnooper
from models import Darknet
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# with torch.jit.optimized_execution(True):
def save_pytorch_model(darknet_model,pytorch_model,config_file):
model = Darknet(config_file).to(device)
model.load_darknet_weights(darknet_model)
torch.save(model.state_dict(), pytorch_model)
print('pytorch model saved!')
def convert_pytorch_model_to_libtorch(config_file,pytorch_model,libtorch_model):
model = Darknet(config_file).to(device)
model.load_state_dict(torch.load(pytorch_model))
model.eval()
example = torch.rand(1,3,416,416).cuda()
with torch.jit.optimized_execution(True):
print('pp')
# example 报错 Expected type 'tuple', got 'Tensor' instead ,可能是input没有放cuda上
traced_script_module = torch.jit.trace(model, example,check_trace=False)# save the converted model
print('oo')
traced_script_module.save(libtorch_model)
output = traced_script_module(torch.rand(1,3,416,416).cuda())
print(output)
print('trace model saved!')2.3 libtorch 推理
转换为c++ 模型后就可以切换到vs2017 平台进行推理使用了;
这里我参考 https://zhuanlan.zhihu.com/p/246156517 这篇文章的代码,使用起来没发现特别的问题。
先配置好VS2017,libtorch,opencv,cuda,这里提到的一点是Torch::cuda::is_available()返回值为False时:在链接器中->命令行->其他选项中添加/INCLUDE:?warp_size@cuda@at@@YAHXZ
我还没验证这个问题的存在,因为我是Torch::cuda::is_available()返回值为False,但加了/INCLUDE:?warp_size@cuda@at@@YAHXZ 这个发现也没用,后来才发现是自己windows 显卡1060驱动没安装,安装后就解决了。
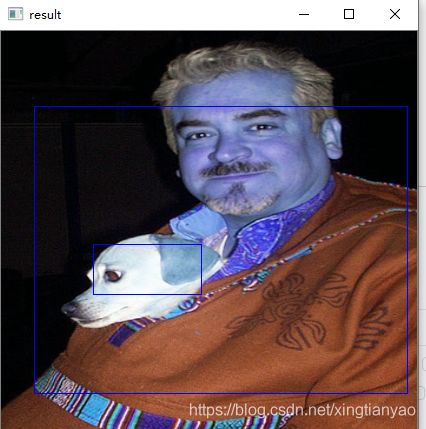
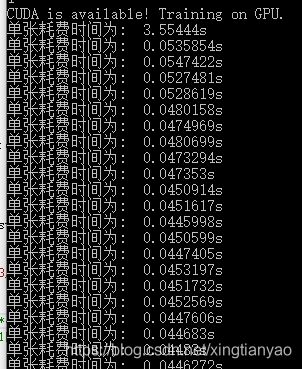
推理结果如下:
第一次调用模型的时间比较长:
而且这个定位精度比较差啊,目前先到这里,还要再进一步摸索: