【NLP】对比学习——文本匹配(一)
文章目录
-
-
-
-
- 1. 任务简介
- 2. NLP的对比学习算法
-
- a.BERT-Flow 2020.11
- b.BERT-Whitening 2021.03
- c.ConSERT 2021.05
- 3. 总结
-
-
-
1. 任务简介
- 深度学习的本质是做两件事情:①表示学习 ②归纳偏好学习。对比学习 ( C o n t r a s t i v e L e a r n i n g ) \small(Contrastive\;Learning) (ContrastiveLearning)则是属于表示学习的范畴,它并不需要关注样本的每一个细节,但是学到的特征要使其能够和其他样本区分开。对比学习作为一种无监督表示学习方法,最开始也是在 C V \small CV CV领域掀起浪潮,之后 N L P \small NLP NLP跟进,在文本相似度匹配等任务上超过 S O T A \small SOTA SOTA。该任务主要是对文本进行表征,使相近的文本距离更近,差别大的文本距离更远。

- 对比学习的基础来自于度量学习 ( M e t r i c L e a r n i n g ) \small (Metric\;Learning) (MetricLearning),主要区别在于是否自监督构造训练数据。自监督主要体现在正负例样本根据规则生成,而不是人工标注。所以对比学习也可以称为自监督版的度量学习。
- 上图可以抽象成如下的等式:
s ( f ( x ) , f ( x + ) ) > > s ( f ( x ) , f ( x − ) ) x + 和 x 属于相似样本, x − 和 x 属于不相似样本, s 为度量相似度的函数 s(f(x),f(x^+)) >> s(f(x),f(x^-)) \\ \scriptsize x^+和x属于相似样本,x^-和x属于不相似样本,s为度量相似度的函数 s(f(x),f(x+))>>s(f(x),f(x−))x+和x属于相似样本,x−和x属于不相似样本,s为度量相似度的函数典型的 s s s函数是计算向量内积,即优化以下期望: E x , x + , x − [ − l o g ( e f ( x ) T f ( x + ) e f ( x ) T f ( x + ) + ∑ i = 1 N − 1 e f ( x ) T f ( x i − ) ) ] E_{x,x^+,x^-}\left[-log\left (\frac{e^{f(x)^Tf(x^+)}}{e^{f(x)^Tf(x^+)}+\sum^{N-1}_{i=1}e^{f(x)^Tf(x^-_i)}}\right)\right] Ex,x+,x−[−log(ef(x)Tf(x+)+∑i=1N−1ef(x)Tf(xi−)ef(x)Tf(x+))]任一 x x x,有1个正例和n-1个负例,将loss看做是N分类问题,实际就是交叉熵,对比学习中称为InfoNCE ( G l o b a l N C E ) (\small Global\;NCE) (GlobalNCE)。
InfoNCE loss的一般形式: L ( u , v + , { v − } ) = − l o g ( exp ( u ⋅ v + / τ ) ∑ v ∈ { v + , v − } exp ( u ⋅ v − / τ ) ) u , v + , v − 分别表示原、正、负样本, τ 为 s o f t m a x 的温度超参,主要控制模型对标签的信任程度, 越小 ( 趋于 0 ) 则表示越信任, s o f t m a x 越接近真实的 m a x 函数,越大则越接近均匀分布。 τ 小时,只有难区分的样本会对 l o s s 产生影响,对错分样本有更大的惩罚。对比学习对 τ 很敏感。 L_{(u,v^+,\{v^-\})}=-log\left(\frac{\exp(u\cdot v^+/\tau)}{\sum_{v\in \{v^+,v^-\}}\exp(u\cdot v^-/\tau)}\right) \\ \scriptsize u,v^+,v^-分别表示原、正、负样本,\tau为softmax的温度超参,主要控制模型对标签的信任程度,\\ 越小(趋于0)则表示越信任,softmax越接近真实的max函数,越大则越接近均匀分布。\\ \tau小时,只有难区分的样本会对loss产生影响,对错分样本有更大的惩罚。对比学习对\tau很敏感。 L(u,v+,{v−})=−log(∑v∈{v+,v−}exp(u⋅v−/τ)exp(u⋅v+/τ))u,v+,v−分别表示原、正、负样本,τ为softmax的温度超参,主要控制模型对标签的信任程度,越小(趋于0)则表示越信任,softmax越接近真实的max函数,越大则越接近均匀分布。τ小时,只有难区分的样本会对loss产生影响,对错分样本有更大的惩罚。对比学习对τ很敏感。对比学习优化的方向主要是针对上式的的两个方面:①如何构造目标函数 ②如何构建正负例。
但是在这之前,有一个更好的预训练模型则是十分必要的,所以本篇我们先介绍几种在encoder方面的改进算法。
2. NLP的对比学习算法
a.BERT-Flow 2020.11
很多研究发现BERT表示存在问题:未经微调的BERT模型在文本相似度匹配任务上表现不好,甚至不如Glove?作者通过分析BERT的性质,如图:
在理论上BERT确实提取到了足够的语义信息,只是这些信息无法通过简单的consine直接利用。主要是因为:
①BERT的词向量在空间中不是均匀分布,而是呈锥形。高频词都靠近原点,而低频词远离原点,相当于这两种词处于了空间中不同的区域,那高频词和低频词之间的相似度就不再适用;
②低频词的分布很稀疏。低频词表示得到的训练不充分,分布稀疏,导致该区域存在语义定义不完整的地方(poorly defined),这样算出来的相似度存在问题。
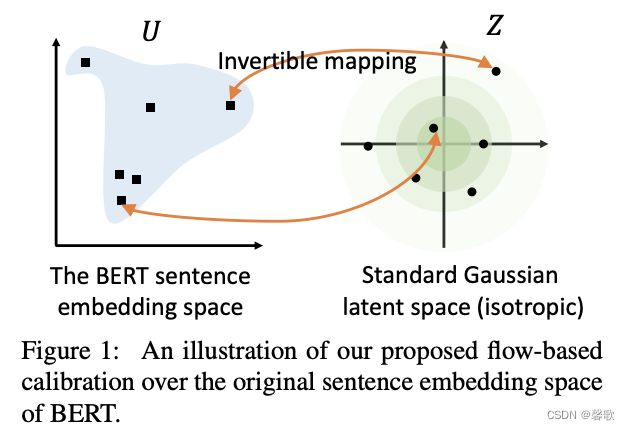
针对以上问题,提出了BERT-Flow,基于流式生成模型,将BERT的输出空间由一个锥形可逆地映射为标准的高斯分布空间。
Flow-based Generative Model:
基于流的生成模型建立了从潜在空间 z \LARGE z z到观测空间 u \LARGE u u的可逆转换,变换过程: z ∼ p z ( z ) , u ∼ f ϕ ( z ) z\sim pz(z),u\sim f_\phi(z) z∼pz(z),u∼fϕ(z) p u ( u ) = p z ( f ϕ − 1 ( u ) ) ∣ d e t ∂ f ϕ − 1 ( u ) ∂ u ∣ pu(u)=pz(f_\phi^{-1}(u))|det\frac{\partial f_\phi^{-1}(u)}{\partial u}| pu(u)=pz(fϕ−1(u))∣det∂u∂fϕ−1(u)∣
简单理解,就是将服从高斯分布的随机变量 z \Large z z映射到BERT编码的 u \Large u u,则反函数 f − 1 f^{-1} f−1就能把 u \Large u u映射到高斯分布上。在训练的过程中保持BERT的参数不变,只优化标准化流的参数,优化目标为最大化从高斯分布中产生BERT表示的概率: m a x ϕ E u = B E R T ( s e n t e n c e ) , s e n t e n c e ∼ D max_\phi\;E_u=BERT(sentence),sentence\sim D maxϕEu=BERT(sentence),sentence∼D l o g p z ( f ϕ − 1 ( u ) ) + l o g ∣ d e t ∂ f ϕ − 1 ( u ) ∂ u ∣ log\;pz(f_\phi^{-1}(u))+log\;|det\frac{\partial f_\phi^{-1}(u)}{\partial u}| logpz(fϕ−1(u))+log∣det∂u∂fϕ−1(u)∣
此外,作者还研究了语义相似度和词汇相似度的关系,将编辑距离作为文本词汇相似度的度量,分别计算了人类标注、BERT、BERT-Flow三者语义相似度和词汇相似度的Spearman相关系数 ρ \rho ρ:
由图可以看出真实的语义相似度和词汇相似度的相关性很弱 ρ = − 24.61 \rho=-24.61 ρ=−24.61,因为一个词的变动就可能使文本的语义完全相反(比如加入一个否定词),而BERT计算的语义相似度和词汇相似度表现出了较强的相关性 ρ = − 50.49 \rho=-50.49 ρ=−50.49,且当编辑距离小于4的时候( g r e e n \color{green}green green)相关性非常强,这会导致BERT可能难以区分like和dislike的语义差别。而引入flow之后,可以发现上述情况有明显的改善,尤其是当编辑距离小于4的时候改善更明显,这表明BERT-Flow计算的相似度相较于词汇相似度更接近于真实的语义相似度。
★ 作者还发现取BERT最后两层的平均要比取最后一层好很多 \bigstar\small\textbf{作者还发现取BERT最后两层的平均要比取最后一层好很多} ★作者还发现取BERT最后两层的平均要比取最后一层好很多


b.BERT-Whitening 2021.03
BERT-Whitening首先分析了余弦相似度为什么可以衡量向量的相似度。我们知道 A ⋅ B = ∣ A ∣ ∣ B ∣ c o s ( α ) ,即 c o s ( α ) = A ⋅ B ∣ A ∣ ∣ B ∣ A\cdot B=|A||B|cos(\alpha),即\;cos(\alpha)=\frac{A\cdot B}{|A||B|} A⋅B=∣A∣∣B∣cos(α),即cos(α)=∣A∣∣B∣A⋅B
向量 A A A与 B B B的乘积等于 A A A在 B B B所在直线上投影的长度。将两个向量扩展到 d d d维,则: c o s ( A , B ) = ∑ i = 1 d a i b i ∑ i = 1 d a i 2 ∑ i = 1 d b i 2 , 模的计算公式: ∣ A ∣ = a 1 2 + a 2 2 + . . . + a n 2 cos(A,B)=\frac{\sum^d_{i=1}a_ib_i}{\sqrt{\sum^d_{i=1}a^2_i}\sqrt{\sum^d_{i=1}b^2_i}}, \\ 模的计算公式:|A|=\sqrt{a^2_1+a^2_2+...+a^2_n} cos(A,B)=∑i=1dai2∑i=1dbi2∑i=1daibi,模的计算公式:∣A∣=a12+a22+...+an2
上述等式的成立,都是在标准正交基(忘了的同学可以自行复习一下)的条件下,也就是说向量依赖我们选择的坐标基,基底不同,内积对应的坐标公式就不一样,从而余弦值的坐标公式也不一样。
所以,BERT的句向量虽然包含了足够的语义,但有可能是因为此时句向量所属的坐标系并非标准正交基,而导致用基于标准正交基的余弦相似度公式计算时效果不好。那么怎么知道具体用了何种基底呢?可以依据统计学去判断,在给向量集合选择基底时,尽量平均地用好每一个基向量,这就体现为每个分量的使用都是独立的、均匀的,如果这组基是标准正交基,那么对应的向量集应该表现出“各向同性”来,如果不是,可以想办法让它变得更加各向同性一写,然后再用余弦公式计算,BERT-Flow正是想到了“flow模型”的办法,而作者则找到了一种更简单的线性变换的方法。
标准化协方差矩阵
思想很简单,因为标准正态分布的均值为0、协方差矩阵为单位阵,假设 { x i } i = 1 N \{x_i\}^N_{i=1} {xi}i=1N为向量集合,则执行变换 x ~ i = ( x i − μ ) W \tilde{x}_i=(x_i-\mu)W x~i=(xi−μ)W使得 { x i ~ } i = 1 N \{\tilde{x_i}\}^N_{i=1} {xi~}i=1N均值为0,协方差矩阵为单位阵。 μ = 1 N ∑ i = 1 N x i \mu=\frac{1}{N}\sum^N_{i=1}x_i μ=N1∑i=1Nxi,现在的问题就是矩阵 W \huge W W的求解。将原始协方差矩阵记为:
Σ = 1 N ∑ i = 1 N ( x i − μ ) T ( x i − μ ) = ( 1 N ∑ i = 1 N x i T x i ) − μ T μ \Sigma=\frac{1}{N}\sum^N_{i=1}(x_i-\mu)^T(x_i-\mu)=\left(\frac{1}{N}\sum^N_{i=1}x_i^Tx_i\right)-\mu^T\mu Σ=N1i=1∑N(xi−μ)T(xi−μ)=(N1i=1∑NxiTxi)−μTμ变换后的数据协方差为 Σ ~ = W T Σ W \tilde{\Sigma}=W^T\Sigma W Σ~=WTΣW,需要解的方程为: W T Σ W = I ⇒ Σ = ( W T ) − 1 W − 1 = ( W − 1 ) T W − 1 W^T\Sigma W=I \quad \Rightarrow\quad \Sigma=(W^T)^{-1}W^{-1}=(W^{-1})^TW^{-1} WTΣW=I⇒Σ=(WT)−1W−1=(W−1)TW−1
协方差矩阵 Σ \Sigma Σ是半正定对称矩阵,且数据多时通常是正定的,所以有SVD分解: Σ = U Λ U T \Sigma=U\Lambda U^T Σ=UΛUT U U U为正交矩阵, Λ \Lambda Λ为对角阵,且对角线元素都是正的,因此直接让 W − 1 = Λ U T W^{-1}=\sqrt{\Lambda}U^{T} W−1=ΛUT,求解得: W = U Λ − 1 W=U\sqrt{\Lambda^{-1}} W=UΛ−1
BERT-Whitening还支持降维操作,能达到提速和提效的效果。
★ \bigstar ★PCA和SVD差异分析:PCA可以将方阵分解为特征值和特征向量,SVD则可以分解任意形状的矩阵。

c.ConSERT 2021.05
美团技术团队提出了基于对比学习的句子表示迁移方法——ConSERT,主要证实了以下两点:
①BERT对所有的句子都倾向于编码到一个较小的空间区域内,这使得大多数的句子对都具有较高的相似度分数,即使是那些语义上完全无关的句子对。我们将此称为BERT句子表示的“坍缩(Collapse)”现象。
②BERT句向量表示的坍缩和句子中的高频词有关。当通过平均词向量的方式计算句向量时,高频词的词向量将会主导句向量,使之难以体现其原本的语义。当计算句向量时去除若干高频词时,坍缩现象可以在一定程度上得到缓解。
为了解决BERT存在的坍缩问题,作者提出了句子表示迁移框架:
对BERT encoder做了改进,主要包括三个部分:
①数据增强模块,作用于embedding层,为同一文本生成不同的编码。
shuffle:更换position id的顺序
token cutoff:在某个token维度把embedding置为0
feature cutoff:在embedding矩阵中,有768个维度,把某个维度的feature置为0
dropout:embedding中每个元素都有一定概率为0,没有行或列的约束
数据增强效果:Token Shuffle > Token Cutoff >> Feature Cutoff ≈ Dropout >> None
②共享的Bert encoder,生成句向量。
③一个对比损失层,在一个Batch内计算损失,拉近同一样本不同句向量的相似度,使不同样本之间相互远离。损失函数: L i , j = − l o g e x p ( s i m ( r i , r j ) / τ ) ∑ k = 1 2 N 1 [ k ≠ i ] e x p ( s i m ( r i , r k ) / τ ) N : B a t c h s i z e , 2 N 表示 2 种数据增强方式, s i m ( ) : 余弦相似度函数, r : 句向量, τ : 实验 0.08 − 0.12 最优 L_{i,j}=-log\;\frac{exp(sim(r_i,r_j)/\tau)}{\sum^{2N}_{k=1}1_{[k\neq i]}exp(sim(r_i,r_k)/\tau)} \\ \scriptsize N:Batch\;size,\;2N表示2种数据增强方式,sim():余弦相似度函数,\;r:句向量,\;\tau:实验0.08-0.12最优 Li,j=−log∑k=12N1[k=i]exp(sim(ri,rk)/τ)exp(sim(ri,rj)/τ)N:Batchsize,2N表示2种数据增强方式,sim():余弦相似度函数,r:句向量,τ:实验0.08−0.12最优
除了无监督训练之外,作者还提出了三种进一步融合监督信号的策略:①联合训练(joint):有监督的损失和无监督的损失通过加权联合训练模型。
②先有监督再无监督(sup-unsup):先使用有监督损失训练模型,再使用无监督的方法进行表示迁移。
③联合训练再无监督(joint-unsup):先使用联合损失训练模型,再使用无监督的方法进行表示迁移。



3. 总结
本篇主要介绍了在文本相似度匹配任务上Bert encoder存在的问题,以及三种针对此所做的改良算法。当然除此之外,还有SimBERT、Sentence BERT等算法,感兴趣的同学可以自行了解,总的来说,可以说是一脉相承的,不在赘述。后面将会以前面我们提到的对比学习最重要的两个优化方向来展开,剖析SimCSE、ESimCSE、SNCSE等算法原理。
参考文献:
1.《对比学习》https://zhuanlan.zhihu.com/p/434823574
2.《BERT-Flow:BERT词向量的性质分析+标准化流》https://zhuanlan.zhihu.com/p/337134133
3.《BERT-flow:CMUx字节提出的文本表示新SOTA》https://zhuanlan.zhihu.com/p/318061606
4.《BERT-flow: Sentence-BERT + Normalizing flows》https://zhuanlan.zhihu.com/p/331807184
5.《细说Bert-whitening的原理》https://zhuanlan.zhihu.com/p/380874824
6.《ACL 2021|美团提出基于对比学习的文本表示模型,效果相比BERT-flow提升8%》https://tech.meituan.com/2021/06/03/acl-2021-consert-bert.html