数据模型可训不可见?hfai同态加密深度学习训练实践
随着深度学习应用的广泛,我们时常能碰到这样的问题:数据持有者想对其持有的大量数据进行计算,利用深度学习模型挖掘其中价值,然而他所拥有的计算资源不足,需要借助云服务器等算力来完成。如果按照现在流行的做法,那当然是将数据传输到云服务器,然后在其上训练深度学习模型。但如此一来,敏感数据便在云服务器上暴露无遗。
以上问题在幻方萤火的对外实践中也经常遇到,我们的合作者必不可少都会问到我们的安全策略。除了隔离、私域访问、差分隐私等常规方法外,是否有其他更安全可靠的技术,能保障用户外用的数据和模型可训不可见呢?
同态加密能解决此类问题,其旨在让数据和模型都在加密条件下进行计算。数据持有者在传输数据前先将数据加密,发送到外部云端后,用于计算的深度学习模型在密文上运行。模型参数,checkpoint 都是密文,除数据持有者以外其他人无法解密获得数据。待计算结束后将结果的密文返还给数据持有者,持有者解开即可得到最终结果。
这是一个很完美的方案,能彻底解决外部算力的安全利用问题,但是否真的切实可行呢?本期幻方 AI 针对这个问题,进行实验测试,探索本地和萤火二号之间这一安全的交互模式。我们主要探索如下三个问题:
-
同态加密下的深度学习训练,是否可以保证训练结果一致?
-
使用了同态加密,训练性能会受到多大的影响?
-
同态加密可以保障数据的隐私安全吗?
同态加密
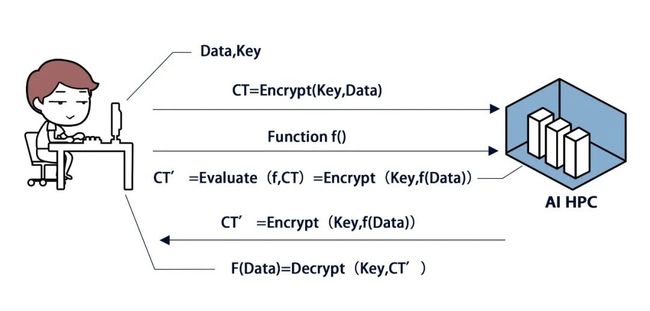
如上图所示,同态加密的思路,是直接将原文加密,然后用外部计算在密文上进行各种运算,最终得到结果的密文,形式化的可以表示为:
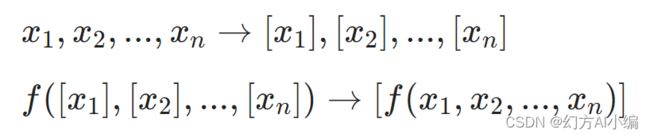
借助同态加密,需保证密文计算结果和原文计算结果一致。这里就需要密文也可以支持运算 ,简单来说就是加减乘除。
在密码学中,一般是以位(bit)为单位进行讨论的,数值操作中的加法和乘法分别对应位操作中的异或(XOR)和与(AND)操作。如果要掩盖一个位,最简单的方式就是加上一个随机数。

这里 2x 一定是偶数,不会影响加密的奇偶性。通过这种简单的加密方法似乎可以支持加法同态和乘法同态,但噪音 x 却会不停地增长。加法的噪音是线性增长的,但乘法的噪音却会爆炸式增长,这就意味着,随着计算的进行,噪音会越来越大,待噪音增长到一定程度,就会使得密文无法被解密,也就无法达到通用全同态的目的了。
2009 年 Gentry 提出了基于 Bootstrapping 的方案,全同态加密才有了实现的可能。该方法顾名思义,就是引导或启动另一轮加密。Gentry 的神来之笔在于想到了让解密过程本身也在密文情况下进行,也就是说,把解密过程当成是一种密文状态下的计算,输入是密文的密文以及密钥的密文。借助形式化的符号来讲解这一过程:假设一个明文 b 被密钥对 (pk1,sk1) 的公钥 pk1 加密为 [b]1,此时 [b]1 是新鲜出炉的,噪音含量极低。

但 [b]1 经过若干次计算后变为了 [b]′1,如果此时 [b]′1 包含的噪音已经多到不能忍了,就需要启用 Bootstrapping 过程。
我们首先生成一对密钥对 (pk2,sk2),并使用 pk2 分别加密 sk1 和 [b]′1 得到 [sk1]2 和 [[b]′1]2,然后使用同态计算将解密电路 Dec 作用于 [sk1]2 和 [[b]′1]2,得到 [Dec(sk1, [b]′1)]2,即 [b]2,这样就在未解密出明文的情况下又得到了新鲜出炉的密文了。这里,加密要以一次能顺利执行 Dec 解密电路为前提。为了减少 Bootstrapping 时 Dec 的复杂度,可以考虑在加密时先把解密需要的操作能做多少是多少,毕竟不是所有的操作都必须等到 Bootstrapping 时才能做的。
实验
我们采用 Crypten 框架进行同态加密的实践,其提供了比较完备的张量库,可以和 PyTorch 深度学习代码整合。我们以 ResNet 训练为例,在 ImageNet 数据集上进行测试。
代码改造
1. 数据加密,转 ffrecord
import pickle
import hfai.datasets
from ffrecord import FileWriter
import crypten
crypten.init(...)
dataset = hfai.datasets.ImageNet('train', transform=...)
dataloader = train_dataset.loader(batch_size=..., ...)
writer = FileWriter(new_dir, len(dataset))
for sample, label in dataloader:
sample, label = crypten.cryptensor(sample), crypten.cryptensor(label)
for item in zip(samples, labels):
bytes_ = pickle.dumps(item)
writer.write_one(bytes_)
writer.close()我们在本地机器初始化 crypten, 将读取的数据加密,数据从原来的 torch.Tensor 格式转化为密文 crypten.mpc.mpc.MPCTensor。
![]()
2. 模型加密,初始化密文参数
model = models.resnet50()
dummy_input = torch.empty((1, 3, 224, 224))
encrypted_model = crypten.nn.from_pytorch(model, dummy_input)
encrypted_model.encrypt()
criterion = crypten.nn.MSELoss()
save({'model': encrypted_model, 'criterion': criterion})将保存的模型参数和加密的数据一同通过 hfai workspace 上传到幻方萤火的工作区中。接下来就可以在密文上进行安全的训练了。
运行效果
我们在 ImageNet 的一个下采样数据集中进行测试,来尝试回答文章开头的三个问题。
1. 使用了同态加密,训练性能会受到多大的影响?
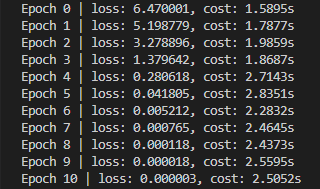
正常训练每Epoch的输出
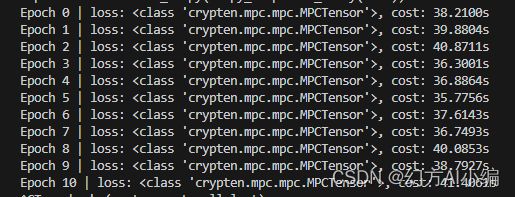
同态加密后,密文训练每Epoch的输出
可以看到,加密之后,输出的 Loss 也是密文状态。而从计算时间上说,使用密文计算,需要多耗费将近 20 倍的时间。从上面的介绍可以知道,同态加密过程为了防止误差无限扩大,会进行 Bootstrapping,这个过程在保证全同态加密的同时,必不可少会带来很大的训练性能下降。
2. 同态加密下的深度学习训练,是否可以保证训练结果一致?
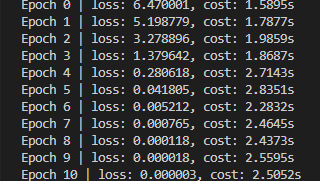
未加密模型训练结果
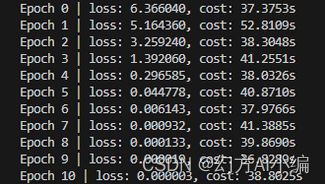
同态加密后训练结果
对输出的 Loss 通过 crypten.get_plain_text() 授权解密。可以看到,Loss 的下降基本和没加密时一致,深度学习运算可以在密文上正常运行。但需要注意是,使用了同态加密后,训练出现不稳定的情况,会经常出现梯度消失的问题,这可能来源于同态加密下的随机误差增大问题。另一方面,crypten 框架所支持的损失函数目前比较少,还有待进一步完善提升。
3. 同态加密可以保障数据的隐私安全吗?
使用 Crypten 进行加密训练,数据的格式都是密文状态。我们尝试用常规的算法方式,如计算均值,方差,所得到的也都是密文。而输出加密的 MPCTensor 的一些性质,比如 size,可以直接获取到。
![]()
其他没有发现明显可以被获取的信息。
总结
通过本次实践,我们验证了同态加密的可行性,其在保障数据在外部的计算资源隐私安全的同时,会极大得影响训练的性能。同时,我们在实验过程中,也发现了不少目前同态加密深度学习训练中的问题,比如不稳定,梯度消失,损失函数种类较少,这些问题还有待进一步技术突破。
目前同态加密处于不断研究优化的过程中,相信未来会有更多优化且可商用的技术突破和方案。我们将持续关注该领域的发展。