Flink sql connector 集成 Phoenix 在 Dinky中的使用
Dlinky 集成 Flink sql connector Phoenix
- Dinky 集成 Flink sql connector Phoenix 使用方式
-
- 1.Dinky flink sql connector phoenix包的编译
- 2.Dinky flink sql connector phoenix包的部署
- 3.Dinky flink sql connector phoenix的使用
- 3.Dinky flink sql connector phoenix的使用样例
Dinky 集成 Flink sql connector Phoenix 使用方式
在Dinky 0.6.1版本后已经支持Flink sql phoenix 的connector
此连接器是基于flink-jdbc-connector改造成,可以使用flink sql insert select delete update 等方式操作phoenix表,可以实现mysqlcdc - phoenix表等多种方式。
同样改连接器也可以脱离dinky 使用,只需放入flink lib/ 下便可以通过sql-client等方式操作phoenix表。
下文说明如何进行使用 flink 操作 phoenix表。
1.Dinky flink sql connector phoenix包的编译
1.1下载源码:
https://github.com/DataLinkDC/dlink
1.2参考官网文档进行编译打包
http://www.dlink.top/#/zh-CN/quick_start/build
1.3 找到connector包

2.Dinky flink sql connector phoenix包的部署
使用方式:
-
2.1 通过flink 启动的flink任务,例如flinksession任务,需要将dlink-connector-phoenix-1.13-xxx.jar和phoenix-4.14.2-HBase-1.4-client.jar 、phoenix-core-4.14.2-HBase-1.4.jar 放入flink/lib目录下,可以直接在sql中建表使用。
-
2.2 dinky中使用集成
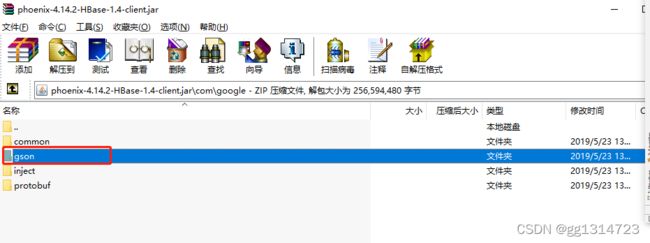
可用于 yarn-perjob等方式集群任务提交等,也就是通过dinky提交任务,此方式需要排除phoenix-4.14.2-HBase-1.4-client.jar 与dinky中冲突的依赖 servlet , gson类。参考官网进行http://www.dlink.top/#/zh-CN/quick_start/deploy ,将phoenix-4.14.2-HBase-1.4-client.jar 中的 servlet ,gson依赖项排除。
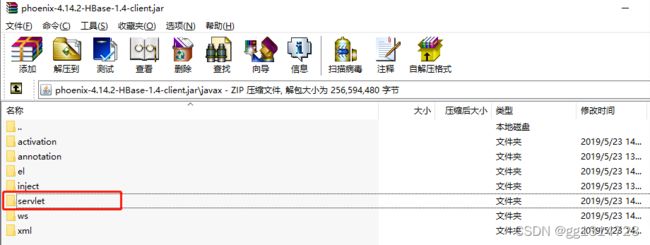
在这里直接删除了phoenix-4.14.2-HBase-1.4-client.jar包中的上述冲突类的包。
包flink-shaded-hadoop-3-uber-3.1.1.7.2.9.0-173-9.0.jar也是同样删除servlet包中的类
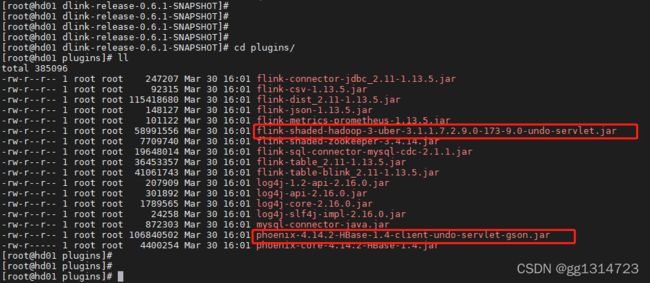
这里使用的版本为1.13.5 dinky plugins目录下的依赖如下所示:
3.Dinky flink sql connector phoenix的使用
3.1 dinky中使用
3.1.1 新建 flink sql studio
3.1.2 创建flink phoenix表
CREATE TABLE pv (
sid INT,
ucount BIGINT,
PRIMARY KEY (sid) NOT ENFORCED
) WITH (
'connector.type' = 'phoenix',
'connector.url' = 'jdbc:phoenix:xxxxxx:2181',
'connector.table' = 'TEST.PV',
'connector.driver' = 'org.apache.phoenix.jdbc.PhoenixDriver',
'connector.username' = '',
'connector.password' = '',
'phoenix.schema.isnamespacemappingenabled' = 'true',
'phoenix.schema.mapsystemtablestonamespace' = 'true',
'connector.write.flush.max-rows' = '1'
);
参数解释:
List item
phoenix-connector中拓展了
-
‘phoenix.schema.isnamespacemappingenabled’ = ‘true’,
-
‘phoenix.schema.mapsystemtablestonamespace’ = ‘true’
两个参数 用于连接开启schema配置的phoenix ,如果未开启则设置为false。 -
‘connector.write.flush.max-rows’ 参数为写入的数据批次条数,如果想提升写入phoenix性能可以设置较大。
3.Dinky flink sql connector phoenix的使用样例
通过模拟数据源,将关联mysql维表数据,然后将数据写入phoenix中。
由于phonix中的insert语义是upsert,相同的主键数据会覆盖。实现了实时pv数据的变动。
SET 'table.exec.mini-batch.enabled' = 'true';
SET 'table.exec.mini-batch.allow-latency' = '5 s';
SET 'table.exec.mini-batch.size' = '5000';
SET 'table.optimizer.agg-phase-strategy' = 'TWO_PHASE';
--模拟数据源
CREATE TABLE datagen (
userid int,
proctime as PROCTIME()
) WITH (
'connector' = 'datagen',
'rows-per-second'='10',
'fields.userid.kind'='random',
'fields.userid.min'='1',
'fields.userid.max'='100'
);
--创建mysql lookup维表
CREATE TABLE student (
sid INT,
name STRING,
PRIMARY KEY (sid) NOT ENFORCED
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://xxxx:3306/test',
'table-name' = 'student',
'username' = 'xxxx',
'password' = 'xxxxx',
'lookup.max-retries' = '1',
'lookup.cache.max-rows' = '1000',
'lookup.cache.ttl' = '60s'
);
--创建 phoenix pv表
CREATE TABLE pv (
sid INT,
ucount BIGINT,
PRIMARY KEY (sid) NOT ENFORCED
) WITH (
'connector.type' = 'phoenix',
'connector.url' = 'jdbc:phoenix:xxxx:2181',
'connector.table' = 'TEST.PV',
'connector.driver' = 'org.apache.phoenix.jdbc.PhoenixDriver',
'connector.username' = '',
'connector.password' = '',
'phoenix.schema.isnamespacemappingenabled' = 'true',
'phoenix.schema.mapsystemtablestonamespace' = 'true',
'connector.write.flush.max-rows' = '30'
);
insert into pv select student.sid as sid ,count(student.sid) as ucount from datagen left join student FOR SYSTEM_TIME AS OF datagen.proctime on student.sid = datagen.userid group by student.sid having student.sid is not null;
保存提交任务,在sql-client同样可以执行。
dinky任务提交方式,可以参考官网使用文档:
http://www.dlink.top/#/zh-CN/introduce