基于朴素贝叶斯模型进行垃圾邮件的分类
基于朴素贝叶斯模型进行垃圾邮件的分类
一、模型分析
贝叶斯方法是一个有着坚实的理论基础的一种方法,而且它在处理很多问题的时候直接而且高效。
贝叶斯公式:
条件独立性:如果事件x,y对于给定的事件z是相互独立的,也就是说,当z发生时,x发生与否与y发生与否时无关的。
条件独立性公式:![]()
加上条件独立假设的贝叶斯方法就是朴素贝叶斯模型,根据本工程需要解决的问题,应用朴素贝叶斯模型解决垃圾邮件的分类问题。
首先,要判断一个邮件是否为垃圾邮件的概率,只需要在已知该邮件的词向量![]()
的条件下,求出该邮件是否为垃圾邮件的概率。假设是垃圾邮件为事件s,不是垃圾邮件为事件h。
就是求:![]()
根据朴素贝叶斯公式和全概率公式,可以推导出

然后根据朴素贝叶斯的条件独立假设,并且在已知的信息中:正常邮件和垃圾邮件的数目相等,因此设先验概率![]() ,进而可以将上式化为:
,进而可以将上式化为: . . . . . . . . . . . . . . . . . 1式
. . . . . . . . . . . . . . . . . 1式
利用贝叶斯公式,可以1式进一步化简为:
 . . . . . . . . . . . . . . . . . 2式
. . . . . . . . . . . . . . . . . 2式
而解决这个问题的核心公式就是式2,而分类方法就是围绕式2进行的。
并且需要对数据集进行适当的处理。
二、系统设计
(1)收集数据集和设置训练集和测试集数量:
先从网站上下载有关垃圾邮件的数据集,其中含有垃圾邮件和非垃圾邮件的数据集,按照题目要求,我从中选取了80份正常邮件和80份垃圾邮件作为训练集,选择了20份邮件作为测试集(邮件文件名小于100的是正常邮件,大于100的是垃圾邮件)
(2)对训练集使用jieba进行分词,并且要用中文停用表进行简单的过滤,然后再使用正则表达式过滤邮件中的非中文字符
(3)建立词袋子模型(词语之间没有固定顺序):构成一个正常邮件组和垃圾邮件组的没有重复的词频字典,即每个词语的词频表示为正常邮件与垃圾邮件中该词语出现的次数。然后我依照词频词典做出了正常邮件和垃圾邮件的词云图,经过对比可以发现,正常邮件和垃圾邮件在词语的组成上是有区别的,因此可以根据词语特征来区别垃圾邮件和正常邮件。
(4)所以筛选出前20个出现频率高的词语作正常邮件组和垃圾邮件组的特征词向量来表示正常邮件和垃圾邮件。
(5)测试集的每一封邮件也需要做同样的处理,通过计算每个邮件的p(s/w)来得到对分类影响最大的20个词语。当测试集中的词语同时出现在垃圾邮件词典和正常邮件词典中,我们就需要计算 ,这表示测试集出现
,这表示测试集出现![]() 词时,它是垃圾邮件的概率;
词时,它是垃圾邮件的概率;
当测试集的词语只出现在正常邮件词典中,而没有出现在垃圾邮件的词典中,此时设![]() ,不将其设置为0的原因是为了防止
,不将其设置为0的原因是为了防止![]() 时,再计算贝叶斯公式概率是会使得整个概率变成0,朴素贝叶斯方法失效;同理当测试集的词语只出现在垃圾邮件词典中,而没有出现在正常邮件词典中时,要设
时,再计算贝叶斯公式概率是会使得整个概率变成0,朴素贝叶斯方法失效;同理当测试集的词语只出现在垃圾邮件词典中,而没有出现在正常邮件词典中时,要设![]() ;
;
最后如果测试集的词语既不出现在垃圾邮件词典中,也不出现在正常邮件词典中时,我就将![]() 因为它暂时无法其是垃圾邮件还是正常邮件,所以我就将其设置为判断垃圾邮件或者非垃圾邮件的概率临界点的值。计算之后得到了对测试集邮件中重要的20个词语是否为垃圾邮件的对应着“词语”:“概率”的字典表。
因为它暂时无法其是垃圾邮件还是正常邮件,所以我就将其设置为判断垃圾邮件或者非垃圾邮件的概率临界点的值。计算之后得到了对测试集邮件中重要的20个词语是否为垃圾邮件的对应着“词语”:“概率”的字典表。
(6)最后对得到的20个词利用2式的核心公式计算贝叶斯概率,如果P>阈值ɑ(我将其设置为0.5),则判定为垃圾邮件,否则则判定为正常邮件。
(7)最后根据其判断结果的正确的个数,计算模型的正确率。同时还可以计算出模型的准确率和召回率。
三.模型结果分析
(1)垃圾邮件和正常邮件的词云图:

垃圾邮件词云图

正常邮件词云图
从中可以发现正常邮件和垃圾邮件中的经常出现的词语是大不相同的,所以可以根据垃圾邮件和正常邮件中出现词语的频率作为垃圾邮件分类的标准。
(2)当阈值α设置为0.5时,实验结果如下:
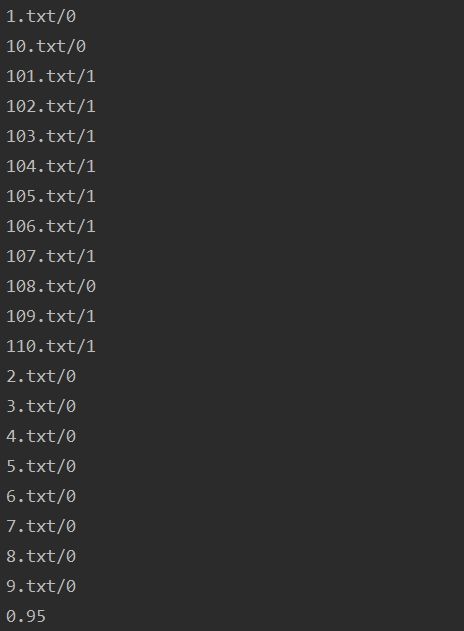
其中标号小于100则表示该邮件时正常邮件,从结果可以看到在20份测试集中只有108.txt原本为垃圾邮件而被错误判断为正常邮件,其正确率达到了95%,
经过计算可以得出该模型的准确率P=100%,召回率P=90%
若按照公式: 来计算模型的评分,则该模型的评分为:94.7
来计算模型的评分,则该模型的评分为:94.7
从这里可以看出朴素贝叶斯方法虽然简单直接,但是应用效果却很好。这说明有些独立假设在各个分类之间的分布都是均匀的,所以对于似然的相对大小不产生影响,即使不是这样,也有很大的可能性各个独立假设所产生的消极影响或者积极影响相互抵消,最终使得结果受到的影响不大。所以朴素贝叶斯模型在处理邮件分类时的效果较好。
(3)若将阈值设置为0.9时(只有非常确定时才预测其为垃圾邮件),实验结果如下:
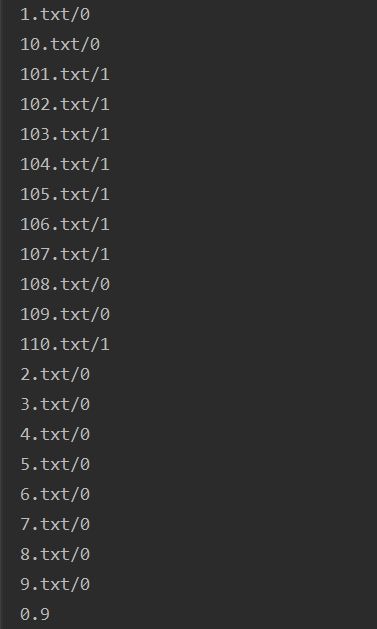
从结果看到其正确率降低了为90%,经过计算可以得出该模型的准确率P=100%,召回率P=80%
若按照公式:来计算模型的评分,则该模型的评分为:88.9
模型的评分降低了,这说明如果将阈值提高,即将判断为垃圾邮件的标准提高了,这时工程中正常邮件和垃圾邮件各80份的数据集已经无法支撑这种高阈值了,因此如果要提高阈值,那么就要扩大训练集和测试集的大小,来提高模型的正确率。
(4)改进方案:需要扩大模型的训练集和测试集,在更大的训练集上进行训练,这样可以得到更准确的正常邮件和垃圾邮件的特征词向量,然后在更大的测试集上进行测试,这样更容易看到调整参数对模型正确率的影响。
四、项目代码
import jieba
import os
import re
import wordcloud
spamDict={}
nomalDict={}
stopList=[]
wordList=[]
wordDict={}
testDict={}
testresult={}
#得到停用词表的列表
def getstopword():
stopList=[]
with open("./data/chinese_stop.txt") as f:
stopList=f.read().split('\n')
return stopList
#利用jieba分词得到邮件的词语
def get_word_list(content,wordlist,stopList):
result=list(set(jieba.cut(content)))
for i in result:
if i not in stopList and i.strip()!='' and i!=None:
if i not in wordList:
wordlist.append(i)
#制作词云图函数
def drawcloud(text):
lis=list(text.keys())
txt=" ".join(lis)
w = wordcloud.WordCloud(font_path="msyh.ttc", width=1000, height=800, max_words=100, background_color="white")
w.generate(txt)
w.to_file("cloud.png")
#根据记录每个词语在邮件中的出现的次数,记录在字典内
def get_word_dict(wordList,wordDict):
for i in wordList:
if i in wordDict.keys():
wordDict[i]=wordDict[i]+1
else:
wordDict.setdefault(i,1)
#得到测试文件中对它分类影响最大的20个词语
def getTestWords(testDict,spamDict,nomalDict,spamfileLen,nomalfilelen):
wordmaxlis={}
for key,vaule in testDict.items():
if key in spamDict.keys() and key in nomalDict.keys():
pw1s=spamDict[key]/spamfileLen;
pw1n=nomalDict[key]/nomalfilelen;
ps1w=pw1s/(pw1s+pw1n)
wordmaxlis.setdefault(key,ps1w)
if key in spamDict.keys() and key not in nomalDict.keys():
pw2s = spamDict[key] / spamfileLen;
pw2n = 0.001
ps2w = pw2s / (pw2s + pw2n)
wordmaxlis.setdefault(key, ps2w)
if key not in spamDict.keys() and key in nomalDict.keys():
pw3s = 0.001
pw3n = nomalDict[key]/nomalfilelen
ps3w = pw3s / (pw3s + pw3n)
wordmaxlis.setdefault(key, ps3w)
if key not in spamDict.keys() and key not in nomalDict.keys():
wordmaxlis.setdefault(key, 0.5)
sorted(wordmaxlis.items(), key=lambda d:d[1], reverse=True)[0:20]
return wordmaxlis
#贝叶斯公式
def Bayes(wodict,spamdict,normaldict):
ps_w=1
ps_n=1
for key,value in wodict.items():
#print(key+"***"+str(value))
ps_w=ps_w*(value)
ps_n=ps_n*(1-value)
p=ps_w/(ps_w+ps_n)
return p
#正确率
def Accuracy(test):
right=0
error=0
#文件名的数字低于100的是正常邮件
for name,signal in test.items():
if((int(name[:-4])<100 and signal==0) or (int(name[:-4])>100 and signal==1)):
right=right+1
else:
error=error+1
return right/(right+error)
def main():
stopList=getstopword()
#print(stopList)
#得到垃圾邮件中的词频
spamfileList= os.listdir("./data/spam")
spamlength=len(spamfileList)
for fileName in spamfileList:
wordList.clear()
for line in open("./data/spam/" + fileName):
line = re.compile(r"[^\u4e00-\u9fa5]").sub("", line)
get_word_list(line, wordList, stopList)
get_word_dict(wordList, spamDict)
spamDict1=sorted(spamDict.items(), key=lambda d: d[1], reverse=True)[0:20]
print(spamDict1)
drawcloud(dict(sorted(spamDict.items(), key=lambda d: d[1], reverse=True)))
#得到正常邮件中的词频
nomalfileList= os.listdir("./data/normal")
nomalength=len(nomalfileList)
wordDict.clear()
for filename in nomalfileList:
wordList.clear()
for l in open ("./data/normal/"+filename):
l=re.compile(r"[^\u4e00-\u9fa5]").sub("", l)
get_word_list(l, wordList, stopList)
get_word_dict(wordList, nomalDict)
nomalDict1=sorted(nomalDict.items(), key=lambda d: d[1], reverse=True)[0:20]
print(dict(nomalDict1))
#drawcloud(dict(sorted(nomalDict.items(), key=lambda d: d[1], reverse=True)))
testfileList=os.listdir("./data/test")
for fileName in testfileList:
wordDict.clear()
for l in open("./data/test/"+fileName):
wordList.clear()
#rule=re.compile(r"[^\u4e00-\u9fa5]")
l=re.compile(r"[^\u4e00-\u9fa5]").sub("",l)
get_word_list(l,wordList,stopList)
get_word_dict(wordList, wordDict)
testDict=wordDict.copy()
#通过测试文件得到来得到对分类影响最大的20个词
wordtextList=getTestWords(testDict, spamDict,nomalDict,nomalength,spamlength)
#对每封邮件的20个词计算贝叶斯概率
ff=Bayes(wordtextList,spamDict1,nomalDict1)
if(ff>0.5):
testresult.setdefault(fileName,1)
else:
testresult.setdefault(fileName,0)
testAccuracy=Accuracy(testresult)
for i,ic in testresult.items():
print(i+"/"+str(ic))
print(testAccuracy)
main()
五、相关数据集及中文停用表
百度网盘链接
提取码:gcca