【论文阅读】3D点云 -- VoteNet:Deep Hough Voting for 3D Object Detection in Point Clouds
前言
该篇论文是对3D室内点云 进行目标检测的方法的研究。我们对该篇论文需要掌握的是
- 了解霍夫投票,知道votenet中如何应用了霍夫投票的思想,投票带来的改善
- 网络结构中的模块的设计,以及分别获取了信息:种子点、投票点、投票聚类(翻译与 投票簇 指的同一意思)、投票提案(投票预测)、结果解析以及NMS后处理
- lossfunction的设计
Abstract
【已有3D目标检测方法】当前的三维目标检测方法受到二维探测器的严重影响。为了利用2D探测器中的体系结构,通常将3D点云转换为规则网格(即,转换为体素网格或鸟瞰图图像),或者依靠2D图像中的检测来提出3D框。很少有工作试图直接检测点云中的对象。
【votenet的提出】在这项工作中,我们回到第一原则,为点云数据构建一个尽可能通用的3D检测管道。
然而,由于数据的稀疏性(来自3D空间中2D流形的样本),我们在从场景点直接预测边界框参数时面临一个重大挑战:3D对象质心可能远离任何曲面点,因此很难在一步中精确回归。为了应对这一挑战,我们提出了VoteNet:
- 一种基于深度点集网络和Hough投票的端到端3D目标检测网络。
- 我们的模型通过简单的设计、紧凑的模型尺寸和高效率,在两个大型真实3D扫描数据集ScanNet和SUN RGB-D上实现了最先进的3D检测。
- 值得注意的是,VoteNet在不依赖彩色图像的情况下使用纯几何信息,优于以前的方法。
1. Introduction
三维目标检测的目标是定位和记录三维场景中的对象。更具体地说,在这项工作中,我们的目标是从点云估计定向三维边界框以及对象的语义类。
【基于2D的3D目标检测方法】
与图像相比,3D点云提供了精确的几何图形和对照明变化的鲁棒性。另一方面,点云是不规则的。因此,典型的CNN不适合直接处理它们。为了避免处理不规则点云,当前的三维检测方法在各个方面严重依赖于基于二维的检测器。例如,
- 将二维检测框架,如 Faster/Mask R-CNN扩展到三维。他们将不规则的点云体素化为规则的3D网格,并应用3D CNN检测器,这无法利用数据中的稀疏性,并且由于昂贵的3D卷积,计算成本很高。
- 将点投影到常规二维鸟瞰图图像,然后应用二维探测器定位对象。然而,这会牺牲几何细节,而几何细节在杂乱的室内环境中可能至关重要。
- 提出了一种级联的两步管道,首先在前视图图像中检测对象,然后在从2D框中挤出的平截头体点云中定位对象,但这严格依赖于2D检测器,如果在2D中未检测到对象,则会完全遗漏对象。
【votenet的提出】
- 【不依赖2D检测器】我们介绍了一个以点云为中心的三维检测框架,该框架直接处理原始数据,无论是在体系结构还是在对象方案中都不依赖于任何二维检测器。
- 【借鉴霍夫投票思想】 我们的检测网络VoteNet以点云3D深度学习模型的最新进展为基础,并受到目标检测广义Hough投票过程的启发。
- 【借鉴pointnet++】我们利用PointNet++,一种用于点云学习的分层深层网络,减少了将点云转化为常规结构的需要。通过直接处理点云,我们不仅可以通过量化过程避免信息丢失,还可以通过仅对感测点进行计算来利用点云中的稀疏性。
尽管PointNet++在对象分类和语义分割方面取得了成功[36],但很少有研究研究如何在具有此类结构的点云中检测3D对象。- 【基于2D检测器的方法不佳原因】一个简单的解决方案是遵循2D探测器中的常见做法,并执行稠密对象建议,即直接从感测点(及其学习的特征)提出3D边界框。然而,点云固有的稀疏性使得这种方法不可取。
在图像中,通常在对象中心附近存在一个像素,但在点云中通常不是这样。由于深度传感器只捕捉物体的表面,三维物体中心很可能位于空旷的空间,远离任何一点。因此,基于点的网络很难聚合对象中心附近的场景上下文。仅仅增加感受野并不能解决问题,因为当网络捕捉到更大的背景时,它也会导致更多地包含附近的物体和杂物。- 【借鉴霍夫投票思想的原因】为此,我们建议赋予点云深度网络类似于经典Hough投票的投票机制。通过投票,我们基本上可以生成靠近对象中心的新点,这些点可以进行分组和聚合以生成框建议。
传统的Hough投票存在多个单独的模块难以联合优化,与其相比,VoteNet具有端到端的可优化性。具体来说,在将输入点云通过主干网络后,我们对一组种子点进行采样,并根据其特征生成投票。投票的目标是到达目标中心。因此,投票群出现在对象中心附近,然后通过学习模块聚集,生成方框提案。其结果是一个功能强大的三维对象检测器,它是纯几何的,可以直接应用于点云。
我们在两个具有挑战性的3D目标检测数据集上评估了我们的方法:SUN RGB-D和ScanNet。在这两个数据集上,VoteNet仅使用几何图形,显著优于同时使用RGB和几何图形甚至多视图RGB图像的现有技术。我们的研究表明,投票方案支持更有效的上下文聚合,并验证了当对象中心远离对象表面(如桌子、浴缸等)时,VoteNet提供了最大的改进。
总之,我们的工作贡献如下:
- 通过端到端可微架构(我们称之为VoteNet),在深入学习的背景下重新表述Hough投票。
- 在SUN RGB-D和ScanNet上实现最先进的3D目标检测性能。
- 深入分析投票对点云中3D对象检测的重要性。
2 Related Work(了解)
【3D目标检测】
以前提出了许多方法来检测对象的三维边界框。如:[27],其中一对语义上下文势有助于指导提案对象性得分(提案: 预测结果;对象性: 是否为预测目标,此时不具有类别信息);基于模板的方法[26,32,28]; Sliding-shapes[41]及其基于深度学习的继承者[42];定向梯度云(COG)[38];以及最近的3D-SIS[12]。
由于直接在3D中工作的复杂性,特别是在大型场景中,许多方法采用某种类型的投影。例如,在MV3D[4]和体素网[55]中,3D数据首先简化为鸟瞰视图,然后再进入管道的其余部分。在平截头体点网[34]和[20]中都证明了通过首先处理2D输入来减少搜索空间。类似地,在[16]中,使用3D地图验证分割假设。最近,GSPN[54]和PointRCNN[39]使用点云上的深度网络来利用数据的稀疏性。
【用于目标检测的Hough投票】
霍夫变换(Hough transform)[13]最初引入于20世纪50年代末,它将检测点样本中简单模式的问题转化为检测参数空间中的峰值。广义Hough变换[2]进一步将该技术扩展到图像块,作为复杂对象存在的指示器。使用Hough投票的例子包括[24]的开创性工作,其中介绍了隐式形状模型、从3D点云中提取平面[3],以及6D姿势估计[44]等等。
Hough投票以前也与高级学习技术相结合。在[30]中,投票被分配了表明其重要性的权重,这些权重是使用最大差值框架学习的。[8,7]中介绍了用于目标检测的Hough森林。最近,[15]通过使用提取的深度特征构建码本,展示了改进的基于投票的6D姿势估计。类似地[31]学习了深度特征,以构建用于MRI和ultrasiounds图像分割的码本。在[14]中,使用经典的Hough算法提取汽车徽标中的圆形图案,然后将其输入深度分类网络。[33]提出了用于图像中二维实例分割的半进化算子,这也与Hough投票有关。
也有使用Hough投票进行3D物体检测的工作[50,18,47,19],其采用了与2D探测器类似的管道
【在点云上的深度学习】
最近,我们看到设计适合点云的深度网络架构的兴趣激增[35、36、43、1、25、9、48、45、46、22、17、53、52、49、51],这在3D对象分类、对象部分分割以及场景分割方面表现出了卓越的性能。在三维对象检测的背景下,体素网[55]从体素中的点学习体素特征嵌入,而在[34]中,点网用于定位从二维边界框挤出的平截体点云中的对象。然而,很少有方法研究如何在原始点云表示中直接提出和检测三维对象。
3 Deep Hough Voting
传统的Hough投票2D检测器[24]包括离线和在线步骤。首先,给定一组带有注释对象边界框的图像,通过存储图像面片(或其特征)及其到相应对象中心的偏移之间的映射来构造码本。在推断时,从图像中选择兴趣点以提取其周围的面片。然后将这些补丁( patches)与代码本中的补丁进行比较,以检索偏移量并计算投票。由于对象面片倾向于一致投票,因此在对象中心附近将形成簇。最后,通过将簇投票回溯到其生成的面片来检索对象边界。
我们确定了这项技术非常适合我们感兴趣的问题的两种方式。首先,基于投票的检测比区域建议网络(RPN)[37]更兼容稀疏集。对于后者,RPN必须在对象中心附近生成建议,该对象中心可能位于空空间中,从而导致额外的计算。第二,它基于自底向上的原理,即积累少量的部分信息以形成可靠的检测。尽管神经网络可以潜在地从一个大的接受域聚合上下文,但在投票空间聚合仍然是有益的。传统的霍夫投票过程如下图:
step1: 兴趣点,通过SIFT算子之类的方式找到一些图像上的关键特征;
step2:根据兴趣点来提取 Image pathes;
step3: 将每一个 Patch 都与 Code Book中的 Patch 比较,检索出偏移量,并计算投票
step4: 生成Cluster,通过一些聚类算法可以得到需要检测物体的中心
step5: 通过 Cluster ,使用一些分类器和回归器得到需要预测的bounding box。
可以看到,传统霍夫投票不是一个端到端的过程,需要离线训练一个code book;同时所用到的特征是人工提取的一些特征。

4 VoteNet Architecture
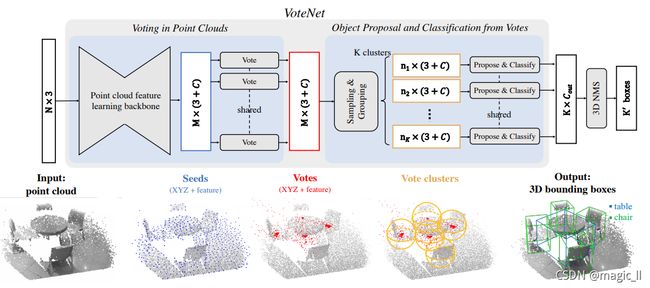
图2说明了我们的端到端检测网络(VoteNet)。整个网络可分为两部分:
- 处理现有点以生成投票的点
- 操作虚拟点 — 投票 — 提案(预测的意思)和分类 objects.
图2.用于点云中三维对象检测的VoteNet体系结构示意图。
- 【输入】给定具有XYZ坐标的N个点的输入点云
- 【种子点】主干网络(使用PointNet++[36]层实现)对点进行下采样、学习深层特征,输出M个点的子集,并将 C C C-dim特征进行扩展。此点子集被视为种子点。
- 【投票点】每个种子通过投票模块独立生成投票。投票点数与种子点数相同。
- 【投票聚类】球邻域方法
- 【投票提案】由提案模块处理投票分组,以生成最终提案。【NMS后处理】分类和NMS后的方案将成为最终的3D边界框输出。
4.1. 学习投票点
从大小为N×3的输入点云,N个点的每个点都有一个三维坐标,我们的目标是生成M个投票,其中每个投票都有一个三维坐标和一个高维特征向量。有两个主要步骤:通过骨干网络学习点云特征、从种子点学习Hough投票。
- 【种子点的特征的学习】
我们采用PointNet++[36]作为我们的主干(生成准确的投票需要几何推理和上下文),并在从正态估计[10]、语义分割[21]到三维对象定位[34]的任务中取得了成功。
主干网络具有多个集合抽象层和具有跳跃连接的特征传播(上采样)层,其输出具有XYZ和丰富的C维特征向量的输入点子集。结果是M个维数为(3+C)的种子点。每个种子点生成一个vote。- 【Hough投票与深度网络】
与传统的Hough投票相比,在传统的Hough投票中,投票(从本地关键点的偏移量)由预先计算的代码簿中的查找确定。
我们使用基于深度网络的投票模块生成投票,该模块更高效(无kNN查找),并且更准确,因为它与管道的其余部分联合训练。- 【种子点生成投票点】
【种子点】 给定一组种子点 s i i = 1 M {s_i}^{M}_{i=1} sii=1M 这里 s i = [ x i ; f i ] s_i=[x_i;f_i] si=[xi;fi] 和 x i ∈ R 3 , f i ∈ R C x_i \in R^3,f_i \in R^C xi∈R3,fi∈RC ( x x x 为种子点的具体坐标, f f f 为种子点的特征向量),每个独立的种子,通过共享的投票模块生成投票。
【投票模块】 投票模块是通过多层感知器(MLP)网络实现的,该网络具有完全连接的层、ReLU和批量规范化。
【模块输出】 MLP 采用 seed feature 来输出欧氏空间的偏移 Δ x i ∈ R 3 \Delta x_i \in R^3 Δxi∈R3 以及 Δ f i ∈ R C \Delta f_i \in R^C Δfi∈RC,种子 具有 y i = x i + Δ x i y_i = x_i + \Delta x_i yi=xi+Δxi 和 g i = f i + Δ f i g_i = f_i + \Delta f_i gi=fi+Δfi,来生成投票 v i = [ y i ; g i ] v_i = [y_i; g_i] vi=[yi;gi] 。
【损失函数】 预测的3D偏移量由回归损失明确监督: L v o t e − r e g = 1 M p o s ∥ Δ x i − Δ x i ∗ ∥ 1 [ s i o n o b j e c t ] L_{vote-reg} = \frac{1}{M_{pos}}\left \| \Delta x_i-\Delta x^*_i \right \| 1[s_i \, \, on \, \, object] Lvote−reg=Mpos1∥Δxi−Δxi∗∥1[sionobject]其中 1 [ s i o n o b j e c t ] 1[s_i \, \, on \, \, object]{\color{Magenta} }{\color{Green} } 1[sionobject] 表示种子点 s i s_i si 是否位于对象表面上, M p o s M_{pos} Mpos 是对象表面上种子总数的计数。 Δ x i ∗ \Delta x^*_i Δxi∗ 是从种子位置 x i x_i xi 到它所属物体的包围盒中心的真实偏移。
投票点与种子点的维度相同,但不再基于对象表面。但更本质的区别在于它们的位置——从同一对象上的种子生成的投票现在比种子更接近彼此,这使得组合来自对象不同部分的线索更容易。接下来,我们将利用这种语义感知的局部性来聚合对象提案的投票特征。
4.2 对象提案和投票分类
投票为对象不同部分的上下文聚合创建规范的“集合点”。在对这些投票进行聚类后,我们聚合它们的特征以生成对象建议并对它们进行分类。
- 【通过采样和分组 获取投票聚类(投票簇)】
虽然有许多方法可以对投票进行聚类,但我们选择了一种简单的策略,即根据空间接近度进行统一采样和分组。具体地说,从一组投票 { v i = [ y i ; g i ] ∈ R 3 + C } i = 1 M \{v_i=[y_i;g_i]\in R^{3+C}\}^M_{i=1} {vi=[yi;gi]∈R3+C}i=1M ( x x x 为投票点的具体坐标, f f f 为投票点的特征向量)中,我们使用基于3D欧式空间中 { y i } \{y_i\} {yi} 的最远点采样,采样出K个投票的子集,以获得 { v i k } \{v_{i_k}\} {vik},其中。然后,我们通过查找每个的3D位置的相邻投票来形成K簇: C k = { v i ( k ) ∣ ∥ v i − v i k ∥ ≤ r } k = 1 , ⋯ , K C_k = \{v^{(k)}_i | \left \| v_i-v_{i_k} \right \|\leq r\} \, \, \, k=1,\cdots ,K Ck={vi(k)∣∥vi−vik∥≤r}k=1,⋯,K 虽然简单,但这种集群技术很容易集成到端到端管道中,并且在实践中效果良好- 【通过投票簇 进行提案和分类】
由于投票簇本质上是一组高维点,我们可以利用通用点集学习网络来聚合投票,以生成对象提案。与传统的Hough投票识别对象边界的回溯步骤相比,该过程允许根据部分观测值提出模型边界,以及预测其他参数,如方向、类别等。
在我们的实现中,我们使用一个共享点网[35]在集群中进行投票聚合和提案。给出一个投票点簇 C = { w i } C=\{w_i\} C={wi},其中 i = 1 , . . . , n i=1,...,n i=1,...,n,并且簇的中心 w i = [ z i ; h i ] w_i=[z_i;h_i] wi=[zi;hi],其中 z i ∈ R 3 z_i \in R^3 zi∈R3 作为投票的位置, h i ∈ R C h_i\in R^C hi∈RC 作为投票的特征。
要使用本地投票几何图形的使用,我们将投票位置转换为局部规范化坐标系,通过 z i ′ = ( z i − z j ) ) / r z^{'}_i=(z_i-z_j))/r zi′=(zi−zj))/r。然后,通过将集合输入传递给类似点网的模块,生成该集群 p ( C ) p(C) p(C) 的目标提案: p ( C ) = M L P 2 { m a x i = 1 , . . . , n { M L P 1 ( [ z 1 ′ ; h i ] ) } } ( 2 ) p(C)=MLP_2\left \{\underset{i=1,...,n}{max} \left \{ MLP_1([z_1^{'};h_i]) \right \} \right \} \,\,\,\,\,\,\,\,\,(2) p(C)=MLP2{i=1,...,nmax{MLP1([z1′;hi])}}(2) 其中,来自每个簇的投票在最大池(通道)到单个特征向量之前由MLP1独立处理,并传递到MLP2,其中来自不同投票的信息被进一步组合。我们将提案p作为多维向量发送,其中包含对象性得分、边界框参数(如[34]中参数化的中心、朝向和大小)以及语义分类得分。- 【损失函数】
提案和分类阶段的损失函数包括对象性、边界框估计和语义分类损失。
我们监督位于真实物体中心附近(0.3米以内)或远离任何中心(超过0.6米)的投票的客观分数。我们认为从这些投票中产生的提案分别是积极的和消极的提案。其他提案的对象性(对象性:是否为目标物体,与类别无关)预测不受惩罚。
对象性通过一个交叉熵损失进行监督,该损失由批中未被忽略的建议的数量标准化。
对于积极的提案,我们根据最接近的真实边界框,进一步监督边界框估计和类别预测。具体地说,我们遵循[34],它将框损失与中心回归、朝向角估计和框大小估计解耦。
对于语义分类,我们使用标准的交叉熵损失。
在检测损失的所有回归中,我们使用Huber(smooth-L1[37])损失。
4.3 Implementation Details
【输入和数据扩充】
- 我们网络的输入是 从深度图中提取来的(N=20k)或三维扫描(网格顶点,N=40k)中随机下采样N个点的点云。
- 除了XYZ坐标外,我们还包括每个点的高度特征,指其到地板的距离。地板高度估计为所有点高度的1%。
- 为了增加训练数据,我们动态地从场景点随机抽取子样本点。我们还将在两个水平方向上随机翻转点云,通过均匀旋转随机旋转场景点[−5,5],并通过均匀[0.9,1.1]随机缩放点。
【网络架构细节】
- 主干特征学习网络 基于PointNet++[36],它有四个集合抽象(SA)层和两个特征传播/上采样(FP)层。
其中SA层的接收半径以米为单位递增0.2、0.4、0.8和1.2,同时分别对2048、1024、512和256个点的输入进行子采样。两个FP层向上采样第四个SA层的输出,返回1024个点,具有256个尺寸特征和3D坐标(更多细节见附录)。- 投票层 通过多层感知器实现,FC输出大小为256、256、259,其中最后一个FC层输出XYZ偏移和特征残差。
- 提案模块 作为一个集合抽象层实现,带有后处理MLP2,以在最大池化后生成提案。SA使用半径0.3和MLP1,输出大小为128、128、128。MLP2进一步处理最大合并特征,输出大小为128、128、5+2NH+4NS+NC。其中输出包括
【2个对象性得分】
【3个中心回归值】
【方向回归的2NH数】:源码中2*12。NH表示将360度分成了多少个方向;2表示一份代表该物体方向距离最近的方向(onehot形式),一份代表这物体方向距离该方向的偏差(长度为NH,对应类别的位置上,赋值具体的偏差值的归一化值,范围[-1,1])
【框大小回归的4NS数】:源码中4*10。我们需要先知道,源码中作者计算了数据集中每个类别的框的均值。前一个NS 表示预测物体的长度 在框的均值中所属的类别,后3NS表示该物体的长宽高与对应的均值的偏移量(归一化后的)
【语义分类】的NC数。
【训练网络】
- 我们使用Adam优化器,批量大小为8,初始学习率为0.001,对整个网络进行端到端和从头开始的培训。
学习率在80个时期后下降10倍,在120个时期后又下降10倍。在一个Volta Quadro GP100 GPU上训练模型收敛,在SUN RGB-D上大约需要10个小时,在ScanNetV2上不到4个小时。
【推论】
- 我们的VoteNet能够获取整个场景的点云,并在一次前进过程中生成建议。提案由3D NMS模块进行后处理,IoU阈值为0.25。该评估采用与[42]中相同的协议,使用平均精度。

5 Experiments
在本节中,我们首先在两个大型3D室内目标检测基准(第5.1节)上,将我们的基于Hough投票的检测器与>之前最先进的方法进行比较。然后,我们提供分析实验,以了解投票的重要性、不同投票聚合方法的效果,并展示我们的方法在紧凑性和效率方面的优势(第5.2节)。最后,我们展示了探测器的定性结果(第5.3节)。附录中提供了更多的分析和可视化。
5.1 与最先进的方法比较
【数据集】
- SUN RGB-D[40]是用于3D场景理解的单视图RGB-D数据集。它包括∼5K RGB-D训练图像,带有37个对象类别的面向amodal的3D边界框注释。为了将数据提供给我们的网络,我们首先使用提供的摄像机参数将深度图像转换为点云。我们遵循标准评估协议,并报告10个最常见类别的性能。
- ScanNetV2[5]是一个具有丰富注释的室内场景三维重建网格数据集。它包含从数百个不同房间收集的1.2K训练示例,并对18个对象类别进行语义和实例分割注释。与SUN RGB-D中的部分扫描相比,ScanNetV2中的场景更完整,平均覆盖面积更大,对象更多。我们从重建的网格中采样顶点作为输入点云。由于ScanNetV2不提供amodal或定向边界框注释,我们的目标是预测轴对齐边界框。
表1. 在SUN RGB-D val集合上的3D对象检测结果。评估指标是[40]提出的3D IoU阈值为0.25的平均精度。请注意,COG[38]和2D驱动[20]都使用房间布局上下文来提高性能。为了与以前的方法进行公平比较,评估基于SUN RGB-D V1数据。
【不同方法的结果比较】
- 我们比较了各种现有技术方法。
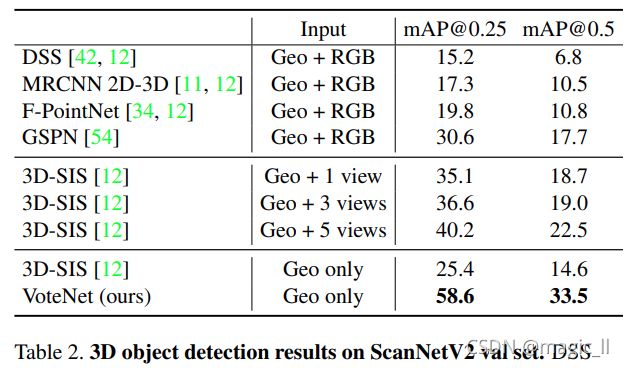
[1] 深度滑窗(DSS)[42]和3D-SIS[12]都是基于3D CNN的检测器,它们结合了几何体和RGB线索,以更快的R-CNN[37]管道为基础进行对象建议和分类。[2] 与DSS相比,3D-SIS引入了更复杂的传感器融合方案(将RGB特征反向投影到3D体素),因此能够使用多个RGB视图来提高性能。[3] 2D驱动[20]和F-PointNet[34]是基于2D的3D探测器,依靠2D图像中的物体检测来减少3D检测搜索空间。[4] 梯度云[38]是一种基于滑动窗口的检测器,使用新设计的3D弓形特征。[5] MRCNN 2D-3D是一个简单的基线,它直接将Mask RCNN[11]实例分割结果投影到3D中,以获得边界框估计。[6] GSPN[54]是一种最新的实例分割方法,使用生成模型提出对象实例,该方法也基于PointNet++主干。- 结果汇总在表1和表2中。VoteNet在SUN RGB-D和ScanNet中的mAP分别至少增加了3.7和18.4,优于所有以前的方法。值得注意的是,对于使用几何和RGB图像,我们只使用几何输入(点云)实现了这样的改进。
表1显示,在训练样本最多的“椅子”类别中,我们的方法比以前的最新水平提高了11个AP以上。
表2显示,当仅采用几何输入时,我们的方法比基于3D CNN的方法3D-SIS的性能好33倍以上。附录中提供了ScanNet的每类评估。重要的是,两个数据集中使用了相同的网络超参数集
5.2 实验分析
【投票还是不投票?】
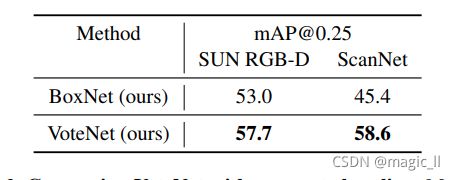
VoteNet的一个简单的基线是一个网络,它直接从采样的场景点提出长方体。这样一个基线,我们称之为BoxNet,它对于提取投票带来的改进至关重要。BoxNet与VoteNet具有相同的主干,但它不是投票,而是直接从种子点生成盒子(更多细节见附录)。表3显示,投票在SUN RGB-D上显著提高了5个mAP,在ScanNet上显著提高了13个mAP。
表3:将VoteNet与无投票基线进行比较。指标是3D检测的mAP。VoteNet根据投票簇估计对象边界框。BoxNet直接从对象表面上的种子点提出长方体,无需投票
【投票的原因】那么,投票有什么帮助呢?我们认为,由于在稀疏的3D点云中,现有的场景点通常远离对象质心,因此直接预测可能具有较低的置信度和不准确的边界框。相反,投票将这些较低的置信点更紧密地结合在一起,并允许通过聚集来强化他们的假设。我们在图3中的典型ScanNetV2场景中演示了这种现象。我们只使用那些种子点覆盖场景,如果对这些种子点进行采样,将生成一个精确的提案。可以看出,与BoxNet(左)相比,VoteNet(右)提供了更广泛的“良好”种子点覆盖范围,显示了投票带来的健壮性。
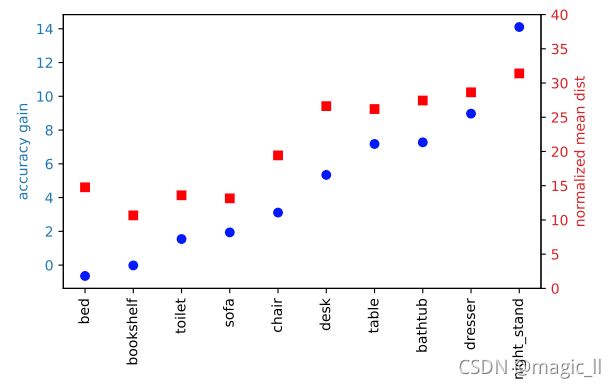
投票有助于增加检测上下文。生成好框的种子点(BoxNet)或生成好框的投票(VoteNet)覆盖在具有代表性的ScanNet场景的顶部(蓝色)。由于投票步骤有效地增加了背景,VoteNet展示了更密集的场景,因此增加了准确检测的可能性。【投票实验表现】我们继续进行图4中的第二次分析,在同一个图上(以单独的比例)显示每个SUNRGB-D类别:(蓝色点)VoteNet和BoxNet之间的mAP增益,以及(红色正方形)对象点(在其表面上)和其边界框中心之间的最近距离,每个类别的平均值,并通过平均类大小进行归一化(大距离意味着对象中心通常远离其表面)。根据前者对类别进行排序,我们会看到一个很强的相关性。即,当对象点倾向于离边界框中心更远时,投票帮助更大。
在对象点远离对象中心的情况下,投票更有帮助。我们为每个类别显示:VoteNet的投票准确度增益(蓝点);和(红色方块)平均对象中心距离,由平均类大小标准化【选票聚合的效果】 选票聚合是VoteNet中的一个重要组成部分,因为它允许选票之间的通信。因此,分析不同的聚合方案如何影响性能是非常有用的。
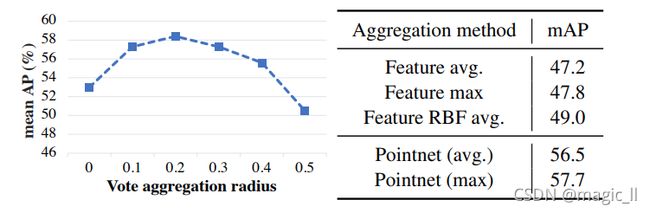
图5. 投票汇总分析。左:mAP@0.25在SUN RGB-D上,用于在通过点网聚合时改变聚合半径(最大值)。右:不同聚合方法的比较(所有方法的radius=0.3)。使用学习的投票聚合比在邻域里人工下采样要有效得多。【选票聚合的方法】在图5(右图)中,我们显示,由于存在杂点投票(即来自非对象种子的投票),使用learned Pointnet和最大池的投票聚合 比手动聚合局部区域中的投票特征 获得更好的结果。我们测试了三种类型的聚合(前三行):最大、平均和RBF权重(基于到聚类中心的投票距离)。与使用Pointnet(公式2)进行聚合不同,投票功能是直接池化的,例如用于平均池化
【选票聚合的半径】 在图5(左)中,我们展示了投票聚合半径如何影响检测(使用最大池使用Pointent进行测试)。随着聚合半径的增加,VoteNet会得到改善,直到在半径约为0.2时达到峰值。但是,关注更大的区域会引入更多的杂波投票,从而污染好的投票,并导致性能下降。
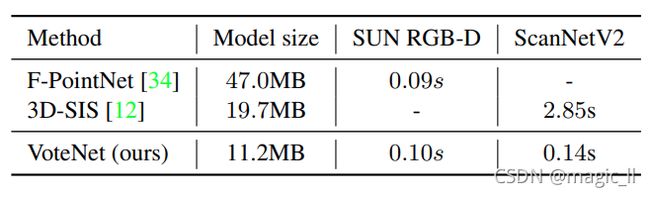
【模型大小和速度】我们提出的模型非常有效,因为它利用了点云中的稀疏性,避免了在空白空间中搜索。
与以前的最佳方法(表4)相比,我们的模型在尺寸上比F-PointNet(SUN RGB-D上的现有技术)小4倍以上,在速度上比3D-SIS(ScanNetV2上的现有技术)快20倍以上。请注意,3D-SIS的ScanNetV2处理时间计算为离线批处理模式下的平均时间,而我们的处理时间是通过可在在线应用程序中实现的顺序处理来测量的。
表4. 模型大小和处理时间(每帧或扫描)。我们的方法在模型尺寸上比[34]紧凑4倍以上,比[12]快20倍以上
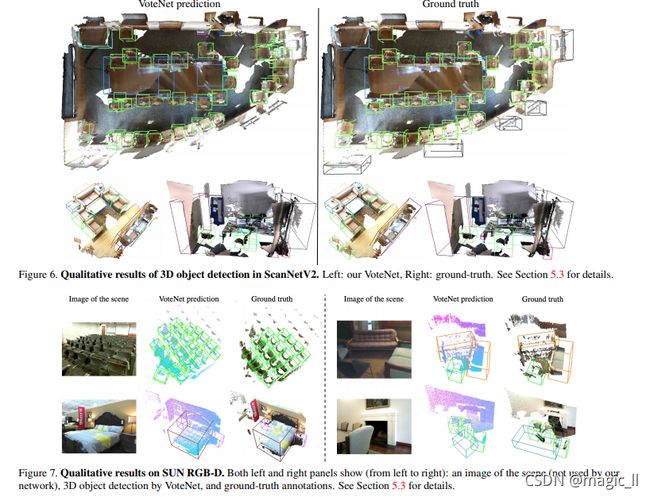
5.3 定性结果和讨论
图6和图7分别显示了扫描网和SUNRGB-D场景上VoteNet检测结果的几个代表性示例。可以看出,场景非常多样化,并带来了多种挑战,包括杂波、偏好、扫描伪影等。尽管存在这些挑战,我们的网络展示了非常稳健的结果。例如,参见图6,在顶部场景中如何正确检测绝大多数椅子。我们的方法能够很好地区分附加的沙发椅和左下角场景中的沙发;并预测了右下角场景中非常零碎和凌乱的桌子的完整边界框。
不过,我们的方法仍然存在局限性。常见的故障案例包括非常薄的对象(如门、窗和顶部场景中用黑色边框表示的图片)上的未命中(图6)。由于我们不使用RGB信息,检测这些类别几乎是可能的。SUN RGB-D上的图7还显示了我们的方法在单视图深度图像部分扫描中的优势。例如,它在左上方的场景中检测到的椅子比真实提供的椅子多。在右上方的场景中,我们可以看到,尽管只看到了沙发的一部分,但VoteNet还是能很好地对amodal包围盒产生幻觉。在右下角的场景中显示了一个不太成功的amodal预测,其中给出了一个非常大的表的极部分观测