决策树算法学习
目录
一、什么是决策树
二、决策树生成原理(CART)
连续值处理
三、具体实现
四、实验总结
一、什么是决策树
决策树中每个内部节点都是一个分裂问题:指定了对实例的某个属性的测试,它将到达该节点的样本按照某个特定的属性进行分割,并且该节点的每一个后继分支对应于该属性的一个可能值。分类决策树叶节点所含样本中,其输出变量的众数就是分类结果。
决策树常用做分类预测,其叶子节点是决策结果,其他节点是属性测试,样本集合根据测试的结果划分到子节点中。
二、决策树生成原理(CART)
CART法构造决策树解决了ID3和C4.5中存在的问题,并且也是目前使用最多的方法
不同于ID3和C4.5采用信息增益和信息增益率的方式来构建决策树,CART是通过gini系数来决定划分
基尼系数计算公式如下:

其中K代表了K个类别,pi是X取第i种的概率,基尼系数越大表示越混乱。
在构造决策树的时候我们需要考虑先判断哪个特征,就是把哪个特征先作为节点进行分类,CART决策树就是通过gini系数来进行判断的,如果该特征分类完,gini系数越小则说明先用该特征作为节点能够更好地构建决策树,减少出现过拟合的情况。
连续值处理
当特征值是连续值时,先将该特征所有值进行一个排序,然后再不断的二分,分成两部分数据,计算它们的熵值
熵值计算公式: 
观察在哪个地方切分的效果最好,就以那个点为区分的点。
其实就可以理解为把连续值变成离散值来处理了
三、具体实现
假设有下表格数据
| 使用英雄数目(近10局) | 平均游戏时长(min) | 是否发言 | 大乱斗0或排位1 |
|---|---|---|---|
| 3 | 29 | 1 | 1 |
| 2 | 31 | 0 | 1 |
| 1 | 23 | 0 | 1 |
| 6 | 21 | 0 | 0 |
| 4 | 25 | 1 | 0 |
| 5 | 30 | 1 | 1 |
| 9 | 18 | 0 | 0 |
| 8 | 20 | 1 | 0 |
| 3 | 34 | 1 | 1 |
| 6 | 23 | 1 | 0 |
根据以上表格数据构建一个决策树,训练出一个决策树判断该玩家更喜欢玩大乱斗还是排位。
导入数据
import numpy as np
# 导入数据
X = np.array([[3, 29, 1],[2, 31, 0],[1, 23, 0],[6, 21, 0],
[4, 25, 1],[5, 30, 1],[9, 18, 0],[8, 20, 1],
[3, 34, 1],[6, 23, 1]])
y = np.array([[1], [1], [1], [0], [0],
[1], [0], [0], [1], [0]])通过sklearn中的决策树算法来构建决策树
# 构建树模型
tree_model = tree.DecisionTreeClassifier(criterion='gini',
max_depth=None,
min_samples_leaf=1,
ccp_alpha=0.0)
tree_model.fit(X, y) # 训练分类树用到DecisionTreeClassifier函数实现,
其中criterion是判断先构建哪个节点的标准,可以选择gini或者entropy;选择entropy就是通过信息增益来选择先判断的节点;选择gini则是计算基尼系数来判断。
max_depth表示构建树的最大深度,这里默认取None,没有限制;
min_samples_leaf是每个样本数叶子节点的最小值,也是选择默认的1;
在有需要的情况下可以通过调整上面两个参数达到预剪枝的效果。
ccp_alpha是后剪枝算法的参数,这里没有进行后剪枝就设置为0.0了。
dot_data = StringIO()
feature_names = ['numbers', 'time', 'talk']
target_names = ['ARAM', 'Rank']
tree.export_graphviz(tree_model,
out_file=dot_data,
feature_names=feature_names,
class_names=target_names,
filled=True,
rounded=True,
special_characters=True)
graph = pydotplus.graph_from_dot_data(dot_data.getvalue())
graph.write_pdf("tree.pdf")再通过可视化操作将生成的决策树保存为.pdf文件。通过export_graphviz函数将数据传入dot_data中,再用pydotplus画出树,并存到文件"tree.pdf"中。
这里在使用的时候出现了一下报错
pydotplus.graphviz.InvocationException:GraphViz's executables not found
具体解决办法通过以下博客解决,主要可能就是没下载graphviz,可以去官网下载
报错解决博客地址
经过sklearntree视化展示生成的决策树:
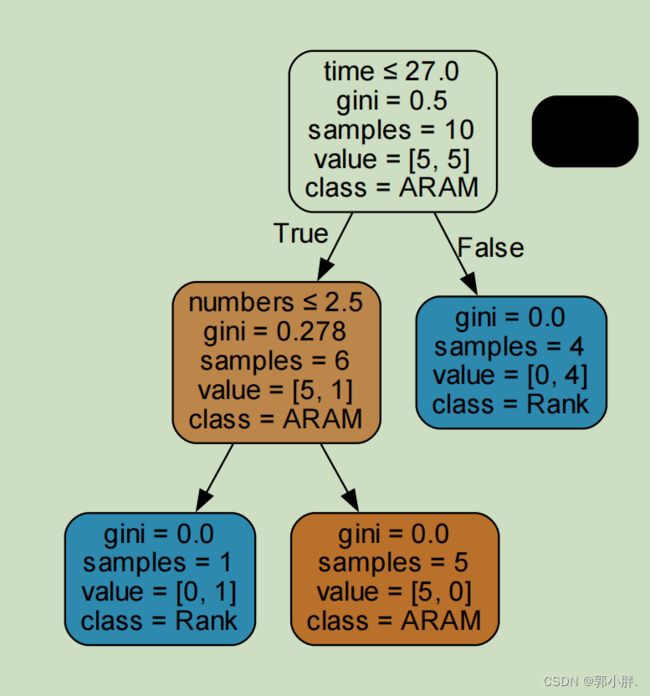
在这个决策树中,每个节点的第一行是区分的特征名字以及相关指标;第二行表示基尼系数;第三行是该节点所包含的样本数量;第四行的value数组表示不同的类别分别有多少样本数;最后一行class是该节点被标记的类别,将样本数量最多的那个类别标记为该节点的类别。
根据上图决策树可知,它将time平均游戏时长作为第一个判断指标,其次是numbers使用不同英雄数量。
其中class中的ARAM对应更喜爱极地大乱斗,Rank对应更喜爱排位模式。
预测效果
x = np.array([[5,20,1]])
print(tree_model.predict(x))
x2 = np.array([[4,29,1]])
print(tree_model.predict(x2))直接调用predict函数进行预测

0和1分别对应类别更爱玩大乱斗和更爱玩排位两个类别
完整代码
from sklearn import tree
import numpy as np
from io import StringIO
import pydotplus
# 导入数据
X = np.array([[3, 29, 1], [2, 31, 0], [1, 23, 0], [6, 21, 0],
[4, 25, 1], [5, 30, 1], [9, 18, 0], [8, 20, 1],
[3, 34, 1], [6, 23, 1]])
y = np.array([[1], [1], [1], [0], [0],
[1], [0], [0], [1], [0]])
# 构建决策树
tree_model = tree.DecisionTreeClassifier(criterion='gini',
max_depth=None,
min_samples_leaf=1,
ccp_alpha=0.0)
# 训练模型
tree_model.fit(X, y)
# 可视化操作
dot_data = StringIO()
feature_names = ['numbers', 'time', 'talk']
target_names = ['ARAM', 'Rank']
tree.export_graphviz(tree_model,
out_file=dot_data,
feature_names=feature_names,
class_names=target_names,
filled=True,
rounded=True,
special_characters=True)
graph = pydotplus.graph_from_dot_data(dot_data.getvalue())
graph.write_pdf("tree.pdf")
# 预测数据
x = np.array([[5, 20, 1]])
print(tree_model.predict(x))
x2 = np.array([[4, 29, 1]])
print(tree_model.predict(x2))四、实验总结
经过这次实验对决策树有了更深入的了解,同时也知道了不同决策树构建的算法(ID3、C4.5和CART),这几个算法在构建决策树不同的点在于他们采取不一样的指标来评判先用哪个属性进行测试然后分裂,这是构建决策树时十分重要的一个问题,直接影响到了决策树构建的好坏。
然后就是对连续值的处理,了解了背后算法的原理就是先进行排序然后再不断的进行二分,比较熵值选出最优的,可以理解为将连续数据变成了离散数据来处理了。
其次就是剪枝了,分为预剪枝和后剪枝,预剪枝比较简单就是通过设置树的最大深度和节点数来提前进行限制;后剪枝就是当决策树构建完,自底向上层序遍历对非叶子节点进行考察,如果将该节点换成叶子节点能够提升决策树的泛化性能,那就剪掉替换成叶子节点。