Mask R-CNN讲解
文章目录
- 一:Mask R-CNN的横空出世
- 二:网络架构
-
- 【Backbone】
- 【RPN】
- 【ProposalLayer】
- 【DetectionTargetLayer】
- 【ROIAlign】
- 【bbox检测】
- 【Mask分割】
- 三:损失函数
- 四:测试过程
- 五:总结
一:Mask R-CNN的横空出世
Mask R-CNN是何凯明大神的新作。Mask R-CNN是一种在有效检测目标的同时输出高质量的实例分割mask。是对faster r-cnn的扩展,与bbox检测并行的增加一个预测分割mask的分支。Mask R-CNN 可以应用到人体姿势识别。并且在实例分割、目标检测、人体关键点检测三个任务都取得了现在最好的效果,下图是Mask R-CNN的检测效果图:

可见,Mask R-CNN其实是将物体检测和语义分割结合起来,从而达到了实例分割的效果。
二:网络架构
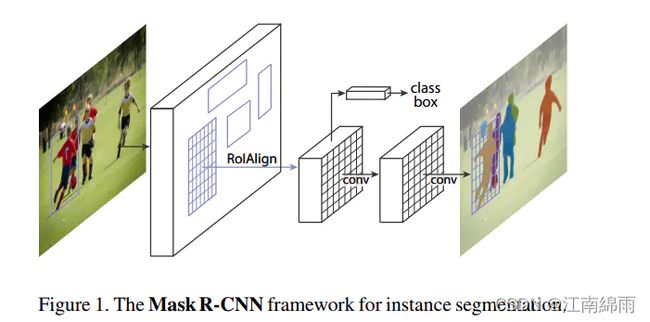
由上图可见,网络架构大概可分为以下几部分:
- Backbone
- RPN
- ProposalLayer
- DetectionTargetLayer
- ROIAlign
- bbox检测
- Mask分割
下面我将按部分讲解,强调:需要有一定的Faster R-CNN基础,还不太了解的小伙伴可移步本人另一篇文章Faster R-CNN最全讲解。
【Backbone】
与Faster R-CNN使用VGG作为backbone不同,Mask R-CNN使用50层和101层的ResNet网络作为backbone,同时作者还探究了另一种有效的主干结构,叫做FPN。所以,其实有四种backbone选择,ResNet50,ResNet101,ResNet50 + FPN,ResNet101 + FPN。选择不同的backbone,ROI生成方式、RP的选择以及RP投射到feature map上的选择会有所不同,并且进入Head层的特征图大小也不尽相同,见下图:
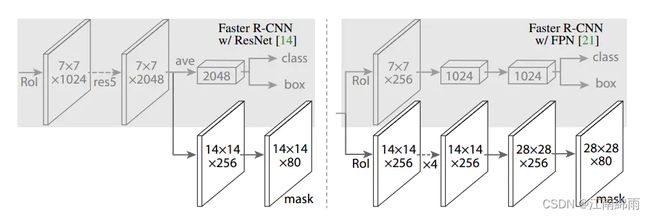
本文选择ResNet101 + FPN作为Backbone进行讲解,也是最复杂的一种选择,了解它的原理,其他类型的backbone自然也都掌握了。下面进入正式讲解:
首先我先来讲讲FPN的作用是什么,为什么现在这么火?
深层网络容易响应语义特征,浅层网络容易响应图像特征。但是到了物体检测领域,这个特征便成了一个重要的问题,高层网络虽然能响应语义特征,但是由于Feature Map的尺寸较小,含有的几何信息并不多,不利于物体检测;浅层网络虽然包含比较多的几何信息,但是图像的语义特征并不多,不利于图像的分类,这个问题在小尺寸物体检测上更为显著和,这也就是为什么物体检测算法普遍对小物体检测效果不好的最重要原因之一。很自然地可以想到,使用合并了的深层和浅层特征来同时满足分类和检测的需求,也就是FPN思想,其演变过程如下图:

FPN使用的是图像金字塔的思想以解决物体检测场景中小尺寸物体检测困难的问题,传统的图像金字塔方法(图a)采用输入多尺度图像的方式构建多尺度的特征,该方法的最大问题便是识别时间为单幅图的k倍,其中k是缩放的尺寸个数。Faster R-CNN等方法为了提升检测速度,使用了单尺度的Feature Map(图b),但单尺度的特征图限制了模型的检测能力,尤其是训练集中覆盖率极低的样本(例如较大和较小样本)。不同于Faster R-CNN只使用最顶层的Feature Map,SSD[6]利用卷积网络的层次结构,从VGG的第conv4_3开始,通过网络的不同层得到了多尺度的Feature Map(图c),该方法虽然能提高精度且基本上没有增加测试时间,但没有使用更加低层的Feature Map,然而这些低层次的特征对于检测小物体是非常有帮助的。
针对上面这些问题,FPN采用了SSD的金字塔内Feature Map的形式。与SSD不同的是,FPN不仅使用了VGG中层次深的Feature Map,并且浅层的Feature Map也被应用到FPN中。并通过自底向上的结构(bottom-up),自顶向下(top-down)以及横向连接(lateral connection)将这些Feature Map高效的整合起来,在提升精度的同时并没有大幅增加检测时间(图d)。
通过将Faster R-CNN的RPN和Fast R-CNN的骨干框架换成FPN,Faster R-CNN的平均精度从51.7%提升到56.9%。
FPN的代码出现在./mrcnn/model.py中,核心代码如下:
# Build the shared convolutional layers.
# Bottom-up Layers
# Returns a list of the last layers of each stage, 5 in total.
# Don't create the thead (stage 5), so we pick the 4th item in the list.
if callable(config.BACKBONE):
_, C2, C3, C4, C5 = config.BACKBONE(input_image, stage5=True, train_bn=config.TRAIN_BN)
else:
_, C2, C3, C4, C5 = resnet_graph(input_image, config.BACKBONE, stage5=True, train_bn=config.TRAIN_BN)
# Top-down Layers
# TODO: add assert to varify feature map sizes match what's in config
P5 = KL.Conv2D(config.TOP_DOWN_PYRAMID_SIZE, (1, 1), name='fpn_c5p5')(C5)
P4 = KL.Add(name="fpn_p4add")([
KL.UpSampling2D(size=(2, 2), name="fpn_p5upsampled")(P5),
KL.Conv2D(config.TOP_DOWN_PYRAMID_SIZE, (1, 1), name='fpn_c4p4')(C4)])
P3 = KL.Add(name="fpn_p3add")([
KL.UpSampling2D(size=(2, 2), name="fpn_p4upsampled")(P4),
KL.Conv2D(config.TOP_DOWN_PYRAMID_SIZE, (1, 1), name='fpn_c3p3')(C3)])
P2 = KL.Add(name="fpn_p2add")([
KL.UpSampling2D(size=(2, 2), name="fpn_p3upsampled")(P3),
KL.Conv2D(config.TOP_DOWN_PYRAMID_SIZE, (1, 1), name='fpn_c2p2')(C2)])
# Attach 3x3 conv to all P layers to get the final feature maps.
P2 = KL.Conv2D(config.TOP_DOWN_PYRAMID_SIZE, (3, 3), padding="SAME", name="fpn_p2")(P2)
P3 = KL.Conv2D(config.TOP_DOWN_PYRAMID_SIZE, (3, 3), padding="SAME", name="fpn_p3")(P3)
P4 = KL.Conv2D(config.TOP_DOWN_PYRAMID_SIZE, (3, 3), padding="SAME", name="fpn_p4")(P4)
P5 = KL.Conv2D(config.TOP_DOWN_PYRAMID_SIZE, (3, 3), padding="SAME", name="fpn_p5")(P5)
# P6 is used for the 5th anchor scale in RPN. Generated by
# subsampling from P5 with stride of 2.
P6 = KL.MaxPooling2D(pool_size=(1, 1), strides=2, name="fpn_p6")(P5)
# Note that P6 is used in RPN, but not in the classifier heads.
rpn_feature_maps = [P2, P3, P4, P5, P6]
mrcnn_feature_maps = [P2, P3, P4, P5]
自底向上方法反映在上面代码的第6行或者第8行,自底向上即是卷积网络的前向过程,在Mask R-CNN中,用户可以根据配置文件选择使用ResNet-50或者ResNet-101。代码中的resnet_graph就是一个残差块网络,其返回值C2,C3,C4,C5,是每次池化之后得到的Feature Map,该函数也实现在./mrcnn/model.py中(代码片段2)。需要注意的是在残差网络中,C2,C3,C4,C5经过的降采样次数分别是2,3,4,5即分别对应原图中的步长分别是4,8,16,32。
残差网络得到的C1-C5由于经历了不同的降采样次数,所以得到的Feature Map的尺寸也不同。为了提升计算效率,首先FPN使用1 × 1卷积进行了降维,得到P5,然后使用双线性插值进行上采样,将P5上采样到和C4相同的尺寸。
之后,FPN也使用1 × 1卷积 卷积对P4进行了降维,由于降维并不改变尺寸大小,所以P5和P4具有相同的尺寸,FPN直接把P5单位加到P4得到了更新后的P4。基于同样的策略,我们使用P4更新P3,P3更新P2。这整个过程是从网络的顶层向下层开始更新的,所以叫做自顶向下路径。
FPN使用单位加的操作来更新特征,这种单位加操作叫做横向连接。由于使用了单位加,所以P2,P3,P4,P5应该具有相同数量的Feature Map(源码中该值为256),所以FPN使用了1 × 1卷积 卷积进行降维。
在更新完Feature Map之后,FPN在P2,P3,P4,P5之后均接了一个3 × 3卷积操作,该卷积操作是为了减轻上采样的混叠效应(aliasing effect)。
至此,Backbone部分中的核心FPN结构讲解完成,附下图加深理解:

讲解完了FPN,我再补充一个重要细节。FPN输出了P2至P6五个特征图,它们都将输入进RPN网络中,用于ROI的产生。但是,只有P2~P5会用于ROI特征提取,稍微注意一下,后面会详细讲解。
【RPN】
Mask R-CNN中的RPN数据标注和训练的流程,和Faster R-CNN中的RPN基本没有任何区别,唯一的区别就是:Mask R-CNN会将五种不同尺寸大小的Anchors,分别在P2~P6这五个特征图上生成,并且一个锚点对应三种长宽比例。
【ProposalLayer】
将RPN网路的输出作为该模块的输入,首先利用rpn_bbox对anchors进行第一次修正,得到ROI并删除其中的一部分超界的ROI。接着,对剩下的ROI进行score排序,保留其中预测为前景色概率大的一部分(具体值可以在配置文件中进行配置)。最后,利用NMS获得最终的RP。
ProposalLayer的作用主要是:
1. 利用rpn_bbox对anchors进行修正,得到ROI
2. 舍弃掉修正后边框超过图片大小的anchor,由于我们的anchor的坐标的大小是归一化的,只要坐标不超过0 1区间即可
3. 根据rpn网络,获取score靠前的前6000个ROI
4. 利用非极大抑制的方法获得最后的RP
【DetectionTargetLayer】
DetectionTargetLayer的输入包含了,target_rois, input_gt_class_ids, gt_boxes, input_gt_masks。其中target_rois是ProposalLayer输出的结果。首先,计算target_rois中的每一个rois和哪一个真实的框gt_boxes iou值,如果最大的iou大于0.5,则被认为是正样本,负样本是是iou小于0.5。选择出了正负样本,还要保证样本的均衡性,具体可以才配置文件中进行配置。最后计算了正样本中的anchor和哪一个真实的框最接近,用真实的框和anchor计算出偏移值,并且将mask的大小resize成28*28,这些都是后面的分类和mask网络要用到的真实的值。下面是该层的主要代码:
获取的就是每个rois和哪个真实的框最接近,计算出和真实框的距离,以及要预测的mask,这些信息都会在网络的头的classify和mask网络
#所使用
def detection_targets_graph(proposals, gt_class_ids, gt_boxes, gt_masks, config):
"""Generates detection targets for one image. Subsamples proposals and
generates target class IDs, bounding box deltas, and masks for each.
Inputs:
proposals: [N, (y1, x1, y2, x2)] in normalized coordinates. Might
be zero padded if there are not enough proposals.
gt_class_ids: [MAX_GT_INSTANCES] int class IDs
gt_boxes: [MAX_GT_INSTANCES, (y1, x1, y2, x2)] in normalized coordinates.
gt_masks: [height, width, MAX_GT_INSTANCES] of boolean type.
Returns: Target ROIs and corresponding class IDs, bounding box shifts,
and masks.
rois: [TRAIN_ROIS_PER_IMAGE, (y1, x1, y2, x2)] in normalized coordinates
class_ids: [TRAIN_ROIS_PER_IMAGE]. Integer class IDs. Zero padded.
deltas: [TRAIN_ROIS_PER_IMAGE, NUM_CLASSES, (dy, dx, log(dh), log(dw))]
Class-specific bbox refinements.
masks: [TRAIN_ROIS_PER_IMAGE, height, width). Masks cropped to bbox
boundaries and resized to neural network output size.
Note: Returned arrays might be zero padded if not enough target ROIs.
"""
# Assertions
asserts = [
tf.Assert(tf.greater(tf.shape(proposals)[0], 0), [proposals],
name="roi_assertion"),
]
with tf.control_dependencies(asserts):
proposals = tf.identity(proposals)
# Remove zero padding
proposals, _ = trim_zeros_graph(proposals, name="trim_proposals")
#去除非零的真实的框,也就是只留下真实存在的有意义的框
gt_boxes, non_zeros = trim_zeros_graph(gt_boxes, name="trim_gt_boxes")
gt_class_ids = tf.boolean_mask(gt_class_ids, non_zeros,
name="trim_gt_class_ids")
gt_masks = tf.gather(gt_masks, tf.where(non_zeros)[:, 0], axis=2,
name="trim_gt_masks")
# Handle COCO crowds
# A crowd box in COCO is a bounding box around several instances. Exclude
# them from training. A crowd box is given a negative class ID.
#在coco数据集中,有的框会标注很多的物体,在训练中,去掉这些框
crowd_ix = tf.where(gt_class_ids < 0)[:, 0]
non_crowd_ix = tf.where(gt_class_ids > 0)[:, 0]
crowd_boxes = tf.gather(gt_boxes, crowd_ix)
crowd_masks = tf.gather(gt_masks, crowd_ix, axis=2)
#下面就是一张图片中真实存在的物体用于训练
gt_class_ids = tf.gather(gt_class_ids, non_crowd_ix)
gt_boxes = tf.gather(gt_boxes, non_crowd_ix)
gt_masks = tf.gather(gt_masks, non_crowd_ix, axis=2)
# Compute overlaps matrix [proposals, gt_boxes]
#计算iou的值
overlaps = overlaps_graph(proposals, gt_boxes)
# Compute overlaps with crowd boxes [anchors, crowds]
crowd_overlaps = overlaps_graph(proposals, crowd_boxes)
crowd_iou_max = tf.reduce_max(crowd_overlaps, axis=1)
no_crowd_bool = (crowd_iou_max < 0.001)
# Determine positive and negative ROIs
roi_iou_max = tf.reduce_max(overlaps, axis=1)
# 1. Positive ROIs are those with >= 0.5 IoU with a GT box
#和真实的框的iou值大于0.5时,被认为是正样本
positive_roi_bool = (roi_iou_max >= 0.5)
positive_indices = tf.where(positive_roi_bool)[:, 0]
# 2. Negative ROIs are those with < 0.5 with every GT box. Skip crowds.
#负样本是是iou小于0.5并且和crowd box相交不大的anchor
negative_indices = tf.where(tf.logical_and(roi_iou_max < 0.5, no_crowd_bool))[:, 0]
# Subsample ROIs. Aim for 33% positive
# Positive ROIs
positive_count = int(config.TRAIN_ROIS_PER_IMAGE *
config.ROI_POSITIVE_RATIO)
positive_indices = tf.random_shuffle(positive_indices)[:positive_count]
positive_count = tf.shape(positive_indices)[0]
# Negative ROIs. Add enough to maintain positive:negative ratio.
r = 1.0 / config.ROI_POSITIVE_RATIO
negative_count = tf.cast(r * tf.cast(positive_count, tf.float32), tf.int32) - positive_count
negative_indices = tf.random_shuffle(negative_indices)[:negative_count]
# Gather selected ROIs
#选择出正负样本
positive_rois = tf.gather(proposals, positive_indices)
negative_rois = tf.gather(proposals, negative_indices)
# Assign positive ROIs to GT boxes.
#计算正样本和哪个真实的框最接近
positive_overlaps = tf.gather(overlaps, positive_indices)
roi_gt_box_assignment = tf.cond(
tf.greater(tf.shape(positive_overlaps)[1], 0),
true_fn = lambda: tf.argmax(positive_overlaps, axis=1),
false_fn = lambda: tf.cast(tf.constant([]),tf.int64)
)
roi_gt_boxes = tf.gather(gt_boxes, roi_gt_box_assignment)
roi_gt_class_ids = tf.gather(gt_class_ids, roi_gt_box_assignment)
# Compute bbox refinement for positive ROIs
#用最接近的真实框修正rpn网络预测的框
deltas = utils.box_refinement_graph(positive_rois, roi_gt_boxes)
deltas /= config.BBOX_STD_DEV
# Assign positive ROIs to GT masks
# Permute masks to [N, height, width, 1]
transposed_masks = tf.expand_dims(tf.transpose(gt_masks, [2, 0, 1]), -1)
# Pick the right mask for each ROI
# 计算和每一个rois最接近的框的mask
roi_masks = tf.gather(transposed_masks, roi_gt_box_assignment)
# Compute mask targets
boxes = positive_rois
if config.USE_MINI_MASK:
# Transform ROI coordinates from normalized image space
# to normalized mini-mask space.
y1, x1, y2, x2 = tf.split(positive_rois, 4, axis=1)
gt_y1, gt_x1, gt_y2, gt_x2 = tf.split(roi_gt_boxes, 4, axis=1)
gt_h = gt_y2 - gt_y1
gt_w = gt_x2 - gt_x1
y1 = (y1 - gt_y1) / gt_h
x1 = (x1 - gt_x1) / gt_w
y2 = (y2 - gt_y1) / gt_h
x2 = (x2 - gt_x1) / gt_w
boxes = tf.concat([y1, x1, y2, x2], 1)
box_ids = tf.range(0, tf.shape(roi_masks)[0])
# crop_and_resize相当于roipolling的操作
masks = tf.image.crop_and_resize(tf.cast(roi_masks, tf.float32), boxes,
box_ids,
config.MASK_SHAPE)
# Remove the extra dimension from masks.
masks = tf.squeeze(masks, axis=3)
# Threshold mask pixels at 0.5 to have GT masks be 0 or 1 to use with
# binary cross entropy loss.
masks = tf.round(masks)
# Append negative ROIs and pad bbox deltas and masks that
# are not used for negative ROIs with zeros.
rois = tf.concat([positive_rois, negative_rois], axis=0)
N = tf.shape(negative_rois)[0]
P = tf.maximum(config.TRAIN_ROIS_PER_IMAGE - tf.shape(rois)[0], 0)
rois = tf.pad(rois, [(0, P), (0, 0)])
roi_gt_boxes = tf.pad(roi_gt_boxes, [(0, N + P), (0, 0)])
roi_gt_class_ids = tf.pad(roi_gt_class_ids, [(0, N + P)])
deltas = tf.pad(deltas, [(0, N + P), (0, 0)])
masks = tf.pad(masks, [[0, N + P], (0, 0), (0, 0)])
return rois, roi_gt_class_ids, deltas, masks
最后返回的是:
rois: [TRAIN_ROIS_PER_IMAGE, (y1, x1, y2, x2)] in normalized coordinates
class_ids: [TRAIN_ROIS_PER_IMAGE]. Integer class IDs. Zero padded.
deltas: [TRAIN_ROIS_PER_IMAGE, NUM_CLASSES, (dy, dx, log(dh), log(dw))]
Class-specific bbox refinements.
masks: [TRAIN_ROIS_PER_IMAGE, height, width). Masks cropped to bbox
boundaries and resized to neural network output size.
由于RP标注的操作和Faster R-CNN如出一辙,所以我来重点讲解一下mask训练样本的标注,下面开始讲解:

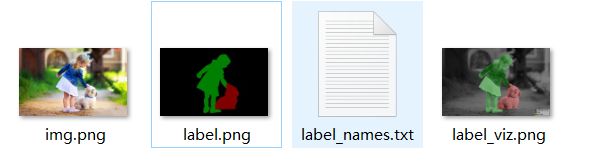
首先对于上面的原图,通过labelme将它标记,生成label.png,分离出person,dog,分别默认是1,2。其中0是背景,如下图实验可以证明:

可见,label.png虽然打印出来是0,1,2三个值的单通道组成,但显示出来的却是RGB图像,原因藏在labelme下的draw.py文件中,如下图:

所以,可以理解为最终的标记结果是一个shape为[3,W,H]的mask掩码,共三层掩码,每一层掩码由0,1构成(可以理解为True和False)。所以上图的label.png可以理解成是三种掩码共同作用在原图中的结果,第一层掩码的索引是0,正好对应背景,目标图像是黑色,然后贴到原图上。接着,第二层掩码索引是1,代表person,目标图像时绿色,然后贴到原图上,第三层掩码同理。
接着对mask进行最近邻插值方式的resize,将原图变为网络需要的输入图像大小,pytorch中默认resize是线性插值,那样会改变掩码中的值,会有小数出现,显然是不对的。(PIL中的Image方法中的resize默认的是最近邻插值方式)。
至此,输入图像的大掩码已经标注出来,每一个RP在原图中的mask自然也获得了。但是它还不是真正的用来与预测结果pixel-to-pixel比较的训练样本(和一般的图像分割不同),还得将每一个RP在原图中的mask转化成head层最后的28×28低分辨率的mask(此时是软掩码)。
具体做法是通过下图的公式计算出每一个RP属于的feature map,不同尺度的ROI使用不同特征层作为ROIAlign层的输入,大尺度ROI就用后面一些的金字塔层,比如P5;小尺度ROI就用前面一点的特征层,比如P3。定义了一个系数Pk,判断ROI该用那个层的输出。查询到了对应的特征图level后,将RP除以缩放倍数,投射到所属的特征图上,原图的大mask也倍数缩放。这样,得到了每一个RP对应的feature map上的mask。

最后,将RP在特征图上的mask输入进下一模块ROIAlign中,最后得到28×28的软掩码,取0.5的阈值进行二值化阈值处理(mask.round()即可),转化为硬掩码,用于后面的二分类交叉熵损失的计算。大功告成!!!!
【ROIAlign】
ROIAlign是ROIPooling的进化版,下面来具体讲解一下它的优化:
ROIAlign的提出是为了解决Faster R-CNN中RoI Pooling的区域不匹配的问题,下面我们来举例说明什么是区域不匹配。ROI Pooling的区域不匹配问题是由于ROI Pooling过程中的取整操作产生的(如下图),我们知道ROI Pooling是Faster R-CNN中必不可少的一步,因为其会产生长度固定的特征向量,有了长度固定的特征向量才能进行softmax计算分类损失。
如下图,输入是一张800×800 的图片,经过一个有5次降采样的卷机网络,得到大小为 25×25 的Feature Map。图中的ROI区域大小是 600×500 ,经过网络之后对应的区域为 600 32 {600}\over {32} 32600 × × × 500 32 500\over32 32500 = 18.75 × 15.625 = 18.75 × 15.625 =18.75×15.625,由于无法整除,ROI Pooling采用向下取整的方式,进而得到ROI区域的Feature Map的大小为 18 × 15 18 × 15 18×15,这就造成了第一次区域不匹配。
RoI Pooling的下一步是对Feature Map分bin,加入我们需要一个 7 × 7 7 × 7 7×7的bin,每个bin的大小为 18 7 {18}\over {7} 718 × × × 15 7 15\over7 715 ,由于不能整除,ROI同样采用了向下取整的方式,从而每个bin的大小为 2 × 2 2 × 2 2×2 ,即整个RoI区域的Feature Map的尺寸为 14 × 14 14 × 14 14×14 。第二次区域不匹配问题因此产生。
对比ROI Pooling之前的Feature Map,ROI Pooling分别在横向和纵向产生了4.75和1.625的误差,对于物体分类或者物体检测场景来说,这几个像素的位移或许对结果影响不大,但是语义分割任务通常要精确到每个像素点,因此ROI Pooling是不能应用到Mask R-CNN中的。

为了解决这个问题,作者提出了RoIAlign。RoIAlign并没有取整的过程,可以全程使用浮点数操作,步骤如下:
1. 计算RoI区域的边长,边长不取整;
2. 将ROI区域均匀分成k × k个bin,每个bin的大小不取整;
3. 每个bin的值为其最邻近的Feature Map的四个值通过双线性插值得到;
4. 使用Max Pooling或者Average Pooling得到长度固定的特征向量。
上面步骤如下图所示:
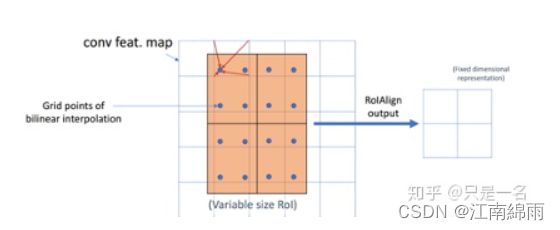
回到流程的正式讲解,首先输入RP特征图,用的是上一节所讲公式分配的feature map上投射出的,在此不再赘述。补充一下,训练时只传入挑选出的正负样本RP,测试时都传入。然后得到两张7×7和14×14大小的特征图,分别传入进Head层的两个功能分支。
【bbox检测】
这里原理和faster R-CNN一模一样,不再赘述,最后得到预测的类别概率和bbox回归参数。
【Mask分割】
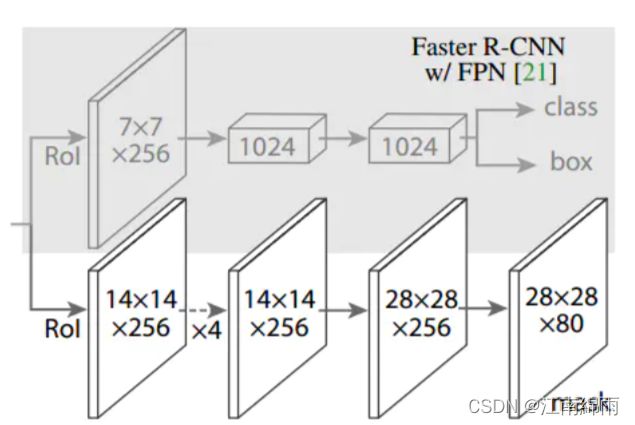
Mask分支用的就是传统的FCN图像分割方法,最后生成28×28×80的预测mask结果,注意得到的结果是软掩码,经过sigmoid后的0~1浮点数。
三:损失函数
最后,来讲一讲网络到底是如何训练的,贴上损失函数:
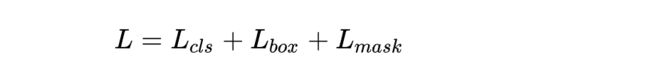
Mask R-CNN采用了和Faster R-CNN相同的两步走策略,即先使用RPN提取候选区域,关于RPN的详细介绍,可以参考Faster R-CNN一文。不同于Faster R-CNN中使用分类和回归的多任务回归,Mask R-CNN在其基础上并行添加了一个用于语义分割的Mask损失函数,所以Mask R-CNN的损失函数可以表示为上式。
上式的分类损失和回归框矫正损失,就不再赘述了,实在是老生常谈。我来主要讲解一下 L c l s L_{cls} Lcls语义分割损失。
在进行掩码预测时,FCN的分割和预测是同时进行的,即要预测每个像素属于哪一类。而Mask R-CNN将分类和语义分割任务进行了解耦,即每个类单独的预测一个位置掩码,这种解耦提升了语义分割的效果,从下图来看,提升效果还是很明显的:

所以根据RP训练样本所对应的类别,单独针对该类对应的mask通道,进行二值交叉熵损失计算。(不用训练背景mask通道,负样本RP直接不训练就行)
至此,Mask R-CNN的所有细节和训练损失函数计算全部讲解完成,下面再讲解一下测试流程。
四:测试过程
测试过程只有head层有一些区别,主要是bbox检测和语义分割的先后顺序问题。Head层先利用上分支,得到最终预测框和预测类别。再对它们进行语义分割,因为已知预测类别,所以相当于实例分割。
最后将28×28的mask线性插值成feature map中的ROI大小,再缩放倍数,得到原图中的ROI。最后,得到的是软掩码,进行阈值分割,得到真正的原图ROI掩码。还原代码如下:
def unmold_mask(mask, bbox, image_shape):
"""Converts a mask generated by the neural network to a format similar
to its original shape.
mask: [height, width] of type float. A small, typically 28x28 mask.
bbox: [y1, x1, y2, x2]. The box to fit the mask in.
Returns a binary mask with the same size as the original image.
"""
threshold = 0.5
y1, x1, y2, x2 = bbox
mask = resize(mask, (y2 - y1, x2 - x1))
mask = np.where(mask >= threshold, 1, 0).astype(np.bool)
# Put the mask in the right location.
full_mask = np.zeros(image_shape[:2], dtype=np.bool)
full_mask[y1:y2, x1:x2] = mask
return full_mask
五:总结
Mask R-CNN是一个很多state-of-the-art算法的合成体,并非常巧妙的设计了这些模块的合成接口:
1. 使用残差网络作为卷积结构
2. 使用FPN作为骨干架构
3. 使用Faster R-CNN的物体检测流程:RPN+Fast R-CNN
4. 增加FCN用于语义分割
Mask R-CNN设计的主要接口有:
1. 将FCN和Faster R-CNN合并,通过构建一个三任务的损失函数来优化模型
2. 使用RoIAlign优化了RoI Pooling,解决了Faster R-CNN在语义分割中的区域不匹配问题
最后,附上一个全局流程图,庆祝我们的大功告成:
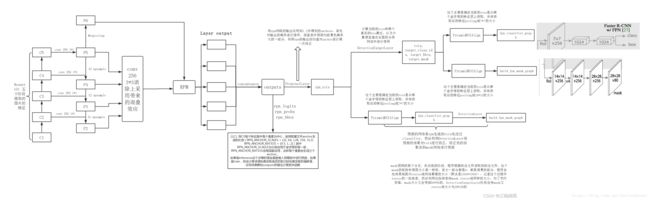
至此我对Mask R-CNN的细节原理,进行了全面讲解,希望对大家有所帮助,有不懂的地方或者建议,欢迎大家在下方留言评论。
我是努力在CV泥潭中摸爬滚打的江南咸鱼,我们一起努力,不留遗憾!