学习python第5天
循环控制语句
循环控制语句描述:在程序中,用于重复执行一段代码逻辑的语法结构称为循环控制语句
解释:
循环就是重复的意思,在程序设计中往往将一个重复执行的代码用于循环体,以保证以最少的代码达到多次执行的目的,减少代码的冗余。
1、 for 循环
Python中的for语句接收可迭代对象,如序列和迭代器作为参数,每次循环可以调取其中一个元素,执行相同的操作。
语法格式为:
for 临时变量 in 循环变量(如字符串|列表|元组|字典|集合)∶
循环执行的代码块
临时变量与循环变量:
1).临时变量是循环变量的元素,比如循环变量是一个字符串,临时变量就是循环变量的每一个字符
2).for循环也称为遍历或迭代,要求循环变量是一个“可迭代对象”。
代码执行特点:
可迭代对象里面有几个元素,就重复执行几次for循环的代码块
for循环适用场景
1.遍历出循环变量的元素做出指定的操作
2.控制循环次数重复执行同一段代码
for循环语句的执行流程图:
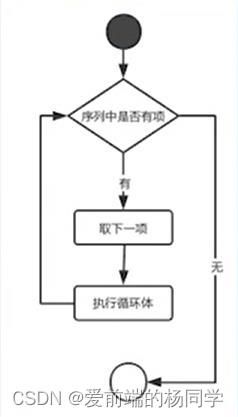
for…else…语法
1.语法:
for 临时变量 in 循环变量
代码块
else:
代码块
2.代码执行:
else这里的代码块是在我们执行完for循环以后再去执行的
3.注意:做理解即可,不常用
1.1 for循环遍历列表
使用for循环打印班级学生名单列表中所有名字:
names =["王玉梅","张勇","王杰","胡平","陈康"]
for name in names:
print (name)
运行结果为:

1.2 for循环遍历字典
for循环遍历字典用到和字典相关的方法:
items ( )、keys( ) 、 values( )
如果使用for循环直接遍历字典,则迭代变量会被先后赋值为每个键值对中的键。
循环输出字典中的value的代码:
my_dic = {'王海': "32",'杨梅': "36",'龙元': "12"}
for dic in my_dic.keys():
print (dic)
print("******************************")
for dic in my_dic:
print (dic)
运行结果如下:

由上述可知,直接遍历字典,和遍历字典keys(方法的返回值是相同的。
遍历字典values( )、items()方法的返回值。
遍历字典的items(和values()返回值的代码:
my_dic = {'王海': "32",'杨梅': "36",'龙元': "12"}
# 遍历字典的 items() 值
for ele in my_dic.items():
print (ele)
print("******************************")
# 遍历字典的 values()值
for ele in my_dic.values():
print (ele)
运行结果为:

1.3 for循环遍历元组
my_tuple = ('王海','杨梅','龙云')
for value in my_tuple:
print (value)
运行结果为:

1.4 for循环遍历集合
for循环遍历集合与元组类似,只是把圆括号换成了大括号。
使用for循环对集合进行了遍历:
my_tuple = {'王海','杨梅','龙云'}
for value in my_tuple:
print (value)
运行结果为:

用for循环打印星星
# hs= 10
# for i in range(1,hs+1):
# xgeshu = 2*i-1 #*个数
# kggeshu =hs -i# 空格的个数
# print(kggeshu * " " + xgeshu * "*")
运行结果为:

2、while 循环
while循环和if条件分支语句相同:
即在条件为真的情况下,会执行相应的代码块。
while循环和if条件分支语句不同:
只要条件为True,while会一直重复执行那段代码块,直到指定的条件不满足为止。
语法格式如下:
while 条件(表达式):
代码块条件成立时执行的代码
代码块:
指缩进格式相同的多行代码,在循环结构中,又称为循环体。
代码执行特点:
条件为True时 会执行while缩进下的代码
while语句执行的具体流程为:
判断表达式的值,其值为真时,则执行while后面的代码块,当执行完毕后,再重新判断表达式的值是否为真,若仍为真,则继续重新执行代码块,如此循环,直到表达式的值为假,终止循环。
while循环结构的执行流程如下图所示:

Python 提供了 for 循环和 while 循环(在 Python 中没有 do…while 循环):

while循环可以用于有限循环和死循环,多用于死循环,有限循环多用于for循环
**使用while循环来数数:**
current_number = 1
while current_number <=5:
print (current_number)
current_number += 1
运行结果为:
#1
#2
#3
#4
#5
由于1小于5,因此打印1,并将current_number的值加1,使其为2;由于2小于5,因此打印出2,并将current_number加1,使其为3,以此类推,一旦current_number大于5,循环将终止,整个程序也将结束。
注意:
在使用while 循环时,一定要保证循环条件有变成False的时候,否则这将成为死循环。
死循环指无法结束循环的循环结构。
2.1 基础数据类型的布尔属性
想要判断一个数的布尔属性值 bool()
1.字符串:
True:非空字符串
False:空字符串
2.整型:
True:非0
False:0
3.列表:
True:非空列表
False:空列表
4.元组:
True:非空元组
False:空元组
5.字典:
True:非空字典
False:空字典
6.集合:
True:非空集合
False:空集合
2.1 while循环遍历字符串
while循环常用来遍历列表、字典、元组和字符串,因为它们支持通过下标索引获取指定位置的元素。
如何使用while循环遍历一个字符串变量:
my_char= "学习Python,我是认真的"
# print(len(my_char)) #14
i = 0
#定义变量i作为列表的下标,通过下标的方式获取元素
while i < len(my_char):#len函数返回列表元素个数
print (my_char[i],end="")
i = i +1
运行效果:
学习Python,我是认真的
2.2 while循环遍历列表
while遍历列表与遍历字符串类似,需要定义一个下标变量,通过下标方式访问列表的元素。
while 循环遍历列表的示例:
names =["王玉梅","张勇","王杰","胡平","陈康"]
i=0
# 定义变量i 作为列表的下标,通过下标的方式获取元素
while i < len(names): #len函数返回列表元素个数
print(names[i])
i+=1
运行结果为:

2.3 while循环遍历字典
while循环遍历字典,通过字典的popitem( )方法删除并返回最后一个元素的方式实现。
示例代码如下:
my_dic ={'王海':"32",'杨梅':"36",'龙云':"12"}
while my_dic:
#popitem() 随机返回并删除字典中的最后一对键和值。
print (my_dic.popitem())
运行结果为:

补充:
Python 字典 popitem() 方法返回并删除字典中的最后一对键和值。
如果字典已经为空,却调用了此方法,就报出 KeyError 异常。
语法
popitem()
参数
无
返回值
返回一个键值对(key,value)形式。
代码示例
site= {'语文': '99', '数学': 100, '英语': '89'}
pop_obj=site.popitem()
print(pop_obj)
print(site)
运行结果为:

使用while循环获取字典的value值时,使用list函数把字典的keys转换为列表,通过遍历列表的方式来获取字典的value值。
my_dic = {'王海':"32",'杨梅':"36",'龙云':"12"}
# #使用list函数把字典的 keys转换为列表
key_list = list(my_dic.keys())
i = 0
while i < len(key_list):
print (my_dic[key_list[i]])
i +=1
#运行结果为:
#32
#36
#12
2.3 while循环遍历元组
while遍历元组与遍历集合方法类似。
示例代码如下:
names = ("王玉梅","张勇","王杰")
i=0
while i < len(names):
print(names[i])
i +=1

3、循环结构中else用法
无论是while循环还是for循环,其后都可以紧跟着一个else 代码块,作用是当循环条件为False跳出循环时,程序会最先执行else代码块中的代码。
以while 循环为例:
str ="学习Python,我是认真的"
i = 0
while i < len(str) :
print(str[i], end="") #end意思就是以给定字符串或制表符结尾,但是不默认换行。
i = i + 1
else:
print("\n执行else代码块")
运行结果为:
注意:
当i等于str字符串长度结束循环时,解释器会执行while循环后的else代码块。
4、range函数
Python中range函数可以轻松的生成一系列的数字。
使用语法如下: range(start,stop[,step])
参数说明:
start ——: 计数从start开始。默认是从0开始。
例如range (5)等价于range (0,5);
stop ——: 计数到stop 结束,但不包括stop。(左闭右开)
例如:range (0,5)是[0, 1,2,3,4]没有5
step ——:步长,默认为1。例如:range (0,5) 等价于range(0,5,1)
for i in range(10,0,-1):
print(i)
#运行结果为:10,9,8,7,6,5,4,3,2,1
for循环道歉20次
# for循环道歉20次
for i in range(20):
print("对不起,我错了,这是我第%d次道歉了"%(i+1))
#%d用于在需要输出的长字符串中占位置 整型(表示格式化一个对象为十进制整数)
#"里面的%是个识别语句,会在"后面寻找%这个关键符号,寻找到了就会进行赋值,这里就是"里面的%d ="外面的 %x

用while循环打印星星
i = 0
while i < 10:
i += 1
xhgs = 2*i - 1
kegs = 10 - i
print(kegs * " " + xhgs * "*")
运行结果为:

练习:
str0 = “ahgajkndgehiuuasdnvmklsjghyeuisdfsdbfqwegsdbsdqdfnguwerihwekfnasd”
使用while遍历str0,统计每个字符出现的次数,要求将结果保存到字典中,例如:{“a”: 8, “g”: 6}
最后将结果打印输出
str0 = "ahgajkndgehiuuasdnvmklsjghyeuisdfsdbfqwegsdbsdqdfnguwerihwekfnasd"
dict0 = {}
list01=list(set(str0)) #转换成集合后再转换成列表,转换成集合可以去掉重复的元素
i= 0
while i < len(list01):
char0 = list01[i] #遍历list01里面的字符串存到char0中
cishu = str0.count(char0) #统计列表str0中char0里面字符串出现的次数,存到cishu中
dict0[char0] = cishu #改变dict0字典里面的char0这个属性的值为cishu
i += 1
print(dict0)
运行结果为:
#{'i': 3, 'r': 1, 'h': 4, 'v': 1, 'u': 4, 'l': 1, 'k': 3, 'g': 5, 'a': 4, 'q': 2, 'd': 8, 'j': 2, 'y': 1, 'm': 1, 'w': 3, 's': 7, 'b': 2, 'e': 5, 'f': 4, 'n': 4}
dict01 = {'a':1,'b':2,}
dict01['c'] = 3 #给dict01这个属性一个值,若字典中没有这个属性,会自动创建这个属性和值
dict01['a'] = 4 #若字典中有这个属性,就会改变这个属性的值
print(dict01)
#运行结果为:
#{'a': 4, 'b': 2, 'c': 3}
5、推导式
推导式又称解析式,是Python的一种独有特性。
推导式是可以从一个数据序列构建另一个新的数据序列的方式。
推导式包括列表推导式、字典推导式和集合推导式。
5.1 列表推导式
语法:
变量名=[表达式for变量in列表]
变量名=[表达式for变量in列表if 条件]
语法说明:
遍历出列表中的内容给变量,表达式根据变量值进行逻辑运算,或者遍历列表中的内容给变量,然后进行逻辑判断,把符合条件的值赋给变量。
用法:
list1 = [i for i in range (1,11)]
list2 = [i for i in range(1,11) if i % 2==0]
print(list1)
print(list2)
运行结果为:

5.2 字典推导式
列表推导式思想的延伸,语法相似,只不过产生的是字典而已。
将字典中的key和value 进行对换示例:
mydict = {"a": 1,"b":2,"c": 3}
mydict_new= {v: k for k,v in mydict. items()}
print (mydict_new)
运行效果:
{1: ‘a’, 2: ‘b’, 3: ‘c’}
names =["张三","李四"]
yingyu= [35,87]
dict = {k:v for k,v in zip(names,yingyu)}
print (dict)
newList = zip(names,yingyu,[18,17])
print (list(newList))
# zip()方法是将多个序列压缩(合并)成一个序列
#运行结果为:
#{'张三': 35, '李四': 87}
#[('张三', 35, 18), ('李四', 87, 17)]
5.3 集合推导式
跟列表推导式非常相似,区别在于用{ }代替[ ]。
示例:
set = {x for x in range(10) if x % 2==0}
squared = {x ** 2 for x in range(1,11)}
print(set)
print(squared)
运行效果:
{0,2,4,6,8}
{64,1,4,36,100,9,16,49,81,25}
6、多变量迭代
多变量迭代通过多个变量同时迭代列表中的数据。
示例:
tuple_list = [(1,5),(2,6),(3,7),(4,8)]
for x, y in tuple_list:
print (x, y)
print("两个元素之和:",x +y)
运行结果为:

names =["张三","李四","吴用"]
yingyu= [35,87,90]
age01= [18,17,19]
for n,y,a in zip(names,yingyu,age01):
#zip()方法是将多个序列压缩成一个,实际上就是合并成一个序列
print ("{0}的年龄为{2}岁,英语的成绩为{1}分".format(n,y,a))
#运行结果为:
#张三的年龄为18岁,英语的成绩为35分
#李四的年龄为17岁,英语的成绩为87分
#吴用的年龄为19岁,英语的成绩为90分
补充: zip() 函数
zip() 函数用于将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的列表。
如果各个迭代器的元素个数不一致,则返回列表长度与最短的对象相同,利用 * 号操作符,可以将元组解压为列表。
zip 语法:
zip([iterable, …])
示例:
a = [1,2,3]
b = [2,3,4]
c = [4,5,6,7,8]
zipped = zip(a,b)
print(zipped) # 返回一个对象
print(list(zipped)) # list() 转换为列表
print(list(zip(b,c))) # 元素个数与最短的列表一致
运行结果如下:

a = [1,2,3]
b = [2,3,4]
a1, a2 = zip(*zip(a,b)) # 与 zip 相反,zip(*) 可理解为解压,返回二维矩阵式
print(list(a1))
print(list(a2))
运行结果为:
[1, 2, 3]
[2, 3, 4]
案例:分析班级的BMI值
任务实现步骤
1.输入班级学生的姓名、身养高、体重信息
2.创建name、weight和height变量分别存储姓名、体重和身高信息
3.编写循环语句
4.根据if…elif…else分支控制语句和BMI分类信息表定义的BMI值分别输出不同的体质分类
5.输出个人BMII体质分类信息
代码如下:
print("---------------for循环---------------")
classesBMI = [('王玉梅',1.6,50),('张勇',1.75,57),('王杰',1.56,68),('王胡平',1.67,87),('陈康',1.78,73)]
for names,height,weight in classesBMI:
bmi = weight/pow(height,2)
who,nat = '','' #国际国内
if bmi < 18.5:
who,nat = '偏瘦','偏瘦'
elif 18.5 <= bmi <=24:
who,nat = '正常','正常'
elif 24 <= bmi <= 25:
who, nat = '正常', '偏胖'
elif 25 <= bmi <= 28:
who,nat = '偏胖', '偏胖'
elif 28 <= bmi <= 30:
who, nat = '偏胖', '肥胖'
else:
who,nat = '肥胖','肥胖'
print('{0}的BMI值为{1}:国际{2},国内{3}'.format(names,format(bmi,'2f'),who,nat))
print("---------------while循环---------------")
classesBMI = [('王玉梅', 1.6, 50), ('张勇', 1.75, 57), ('王杰', 1.56, 68), ('王胡平', 1.67, 87), ('陈康', 1.78, 73)]
while classesBMI:
person = classesBMI.pop()
names, height, weight = person[0], person[1], person[2]
bmi = weight / pow(height, 2)
who, nat = '', '' # 国际国内
if bmi < 18.5:
who,nat = '偏瘦','偏瘦'
elif 18.5 <= bmi <=24:
who,nat = '正常','正常'
elif 24 <= bmi <= 25:
who, nat = '正常', '偏胖'
elif 25 <= bmi <= 28:
who,nat = '偏胖', '偏胖'
elif 28 <= bmi <= 30:
who, nat = '偏胖', '肥胖'
else:
who,nat = '肥胖','肥胖'
print('{0}的BMI值为{1}:国际{2},国内{3}'.format(names,format(bmi,'2f'),who,nat))
运行结果为:

7、循环嵌套
执行流程为:
1. 当外层循环条件为True时则
执行外层循环结构中的循环体。
2. 外层循环体中包含了普通程序和内循环,当内层循环的循环条件为True时会执行此循环中的循环体,直到内层循环条件为False,跳出内循环。
3. 如果此时外层循环的条件仍为True则返回第2步,继续执行外层循环体直到外层循环的循环条件为False。
4. 当内层循环的循环条件为False且外层循环的循环条件也为False,则整个嵌套循环才算执行完毕。
7.1 for嵌套循环
定义:指for循环里面还包含for循环。
语法格式:
for 迭代变量 in 序列:
for 迭代变量 in 序列:
代码块1
代码块2
实例:使用嵌套循环输出2—50之间的素数(指除了1和它本身以外,不能被任何整数整除的数)。
num = []
i = 2
# 利用for循环遍历2-51之间的整数
for i in range(2,51): #range计数到51 结束,但不包括51。(左闭右开)
j = 2
# 遍历2到当前第一层遍历的整数
for j in range(2,i): #2-50之间的数
if i % j == 0: #因为要判断是否能被自身和1以外的正数整除,所以就要从2到这个数,不包括这个数的数字全部都要除一遍,看看是否能被整除
break #被整除就退出循坏
else:
num.append(i)
print("2-50包含的素数有:",num)
#运行结果为:2-50包含的素数有: [2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37, 41, 43, 47]
7.2 while嵌套循环
语法格式:
while 表达式1
while 表达式2:
代码块1
代码块2
实例:使用嵌套循环输出2—50之间的素数
i = 2
num = []
while i < 50:
j = 2
while j <= (i / j):
if not (i % j): #判断是否整除,有整除和不整除两种情况 如果整除就停止循环 not true==false,not false==true
break
j = j + 1
if j > i / j:
num.append(i)
i = i + 1
print("2-50包含的素数有:",num)
#执行结果为:2-50包含的素数有: [2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37, 41, 43, 47]
正三角形
i = 1
while i <= 5: #第一层的while循环是行
j = 1
while j <= i:
print("*",end=" ")
j += 1
print() #没有end=" "修改 都是换行效果。输出了就换行,相当于打印一个空,然后换行
i += 1

倒三角形
# 倒三角形
i = 1
while i <= 5: #第一层的while循环是行
j = 5
while j >= i:
print("*",end=" ")
j -= 1
print() #没有end=" "修改 都是换行效果。输出了就换行,相当于打印一个空,然后换行
i += 1

九九乘法表
#九九乘法表
# i = 1
# while i <= 9:
# j = 1
# while j <= i:
# print("%d*%d=%d" %(i,j,i*j),end=" ")
#print(str(j)+"X"+str(i)+"="+str(i*j),end=" ")
# j += 1
# print()
# i += 1
i=1
while i<=9:
str0=" "
j=1
while j<=i:
# str1 = str(j)+"X"+str(i)+"="+str(j*i)+" "
str1 = "{0}X{1}={2}".format(j,i,i*j)+" "
str0+=str1
j+=1
print(str0)
i+=1
#for循环九九乘法表
for i in range(1,10):
for j in range(1,i+1):
# print("%d*%d=%d"%(i,j,i*j),end="")
# print(str(j)+"X"+str(i)+"="+str(i*j),end=" ")
print("{0}X{1}={2}".format(j,i,i*j),end=" ")
print()

在执行while循环或者for循环时,只要循环条件满足,程序将会`一直执行循环体`。
7.3 跳出循环
Python中强制离开当前循环体的方法:
1.使用break语句,完全终止当前循环;
2.使用continue语句,跳过执行本次循环体中剩余的代码,转而执行下一次的循环。
break语句
用来终止循环语句,即循环条件没有False条件或者序列还没被完全递归完,也会停止执行循环语句。
如果使用嵌套循环,break语句将停止执行最深层的循环,并开始执行下一行代码,而不会作用于所有的循环体。
示例:
for letter in 'Python':
#当letter 参数值为 h 时,跳出当前循环
if letter == 'h': #与if语句配合使用,表示在某种条件下跳出循环体
break
print("当前字母:",letter)
运行结果为:

continue语句
会终止执行本次循环中剩下的代码,直接从下一次循环继续执行。
continue语句的用法:
只要 while或for语句中的相应位置加入即可。
示例:
for letter in 'Python':
if letter == 'h':
#此处跳出for语句,'h'的那一次循环
continue #在本次循环内,遇见了contine,那么continue后面的代码print不会执行,h不会被打印出来,会直接进行下一次循环 o
print("当前字母:", letter)
运行结果为:

计算1-100以内10的倍数相加的和
sum=0
for i in range(100):
if(i%10): #为真,if才执行 所以i没有被整除时,余数不为0,才执行continue
continue
sum=sum+i #执行了continue,这句代码就不会被执行
print(sum)
#执行结果为:450
8、pass语句
pass是Python中的关键字,用来让解释器跳过此处,什么都不做,使用pass语句比使用注释更加优雅。
例子:
for letter in 'Python':
if letter == 'h':
pass
print("这是pass块")
print("当前字母:", letter)
print("Good bye!")
运行结果为:

9、技能拓展
1.同时遍历多个容器
借助zip()函数可将多个容器集中在一起同时遍历,zip()是Python的内建函数,可以直接使用。
x = [1,2,3,4]
y = {'a','b','c','d'}
for i, j in zip(x,y):
print(i,j)
执行结果为:

2.循环技巧
利用Python内建函数包括reversed( )、sorted( )、set( )、enumerate()函数实现一些实用的技巧。
示例代码:
for i in reversed(range(10)):
#输出结果为10 9 8 7 6 5 4 3 2 1
print(i + 1,end='') #end意思就是以给定字符串或制表符结尾,但是不默认换行。
for c in sorted('hello world'):
#输出结果为d e h l l l o o r w
print(c,end='')
for x in {1,1,2,2,2,3,3}:
#输出结果为:1 2 3
print(x,end='')
# 示例:
# 一年365天,按照每天比前1天进步或者退步1%,第1天按照能力
# 值为1计算,一年之后每天进步1%的人能力将达37.78,每天退步1%的人,能力值只剩0.03。
dayfactor = 0.01 #每天进步或退步参数
dayup = 1.0 #第一天能力值基数
daydown = 1.0 #第一天能力值基数
for i in range(365):
dayup *= 1 + dayfactor #每天比前1天进步1%
daydown *= 1 - dayfactor #每天比前1天退步1%
print("按照一年365天计算,每天提升1%,一年后能力值为:{:.2f} ".format(dayup))
print("按照一年365天计算,每天退步1%,一年后能力值为:{:.2f}".format(daydown))

案例:分年级的MIB指数
具体实现步骤如下:
1.输入年级和班级的学生姓名、身高、体重信息;
⒉创建className、name,weight和height变量分别存储班级名称、姓名、体重和身高信息;
3.编写嵌套循环语句,分别遍历年级里的班级信息和学生信息;
4.根据if…elif…else分支控制语句和BMI分类信息表定义的BMI值分别赋值不同的体质分类;
5.输出班级BMI体质分类信息;
gradsBims = [
[('19大数据1班', '王玉梅', 1.6, 50), ('19大数据1班', '张勇', 1.75, 57), ('19大数据1班', '王杰', 1.56, 68),
('19大数据1班', '胡平', 1.67, 87), ('19大数据1班', '陈康', 1.78, 73)],
[('19大数据2班', '杨子', 1.73, 86), ('19大数据2班', '常博', 1.56, 78), ('19大数据2班', '张宇', 1.75, 73),
('19大数据2班', '唐梦', 1.86, 76), ('19大数据2班', '王硕', 1.8, 73)]
]
while gradsBims: # 当列表里面的值不为空
classes = gradsBims.pop() # pop()方法用于删除列表中的最后一个元素,并返回该元素本身
# for classes in gradsBims:
print('\n-------------班级分割线--------------')
while classes:
person = classes.pop() #
# for person in classes:
className, name, height, weight = person[0], person[1], person[2], person[3]
bmi = weight / pow(height, 2)
who, nat = '', ''
if bmi < 18.5:
who, nat = '偏瘦', '偏瘦'
elif 18.5 <= bmi <= 24:
who, nat = '正常', '正常'
elif 24 <= bmi <= 25:
who, nat = '正常', '偏胖'
elif 25 <= bmi <= 28:
who, nat = '偏胖', '偏胖'
elif 28 <= bmi <= 30:
who, nat = '偏胖', '肥胖'
else:
who, nat = '肥胖', '肥胖'
print('{0}{1}的BMI数值是{2},BMI指标为:国际{3}', '国内:{4}'.format(className, name,format(bmi, '.2f'), who, nat))
运行结果为:
