超好用,18 个 Jupyter Notebook 使用技巧助你快速腾飞
Jupyter Notebook 是干嘛的就不再过多介绍了,这篇文章收集了一些顶级的 Jupyter Notebook 技巧,可以让你迅速成为一个 Jupyter 超级使用者!
作为一款完全免费的产品,它的身上有太多值得探索的内容了,这里整理了28个,希望能够对你有所帮助。
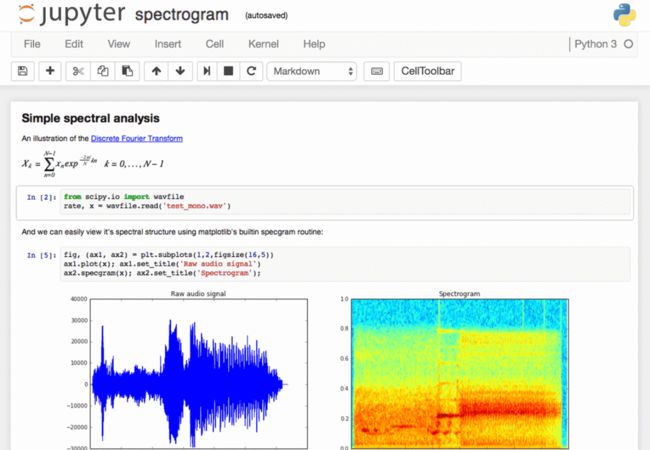
干货推荐
- 深度盘点:这20套可视化炫酷大屏真香啊(附源码)
- 值得收藏,这6种制作竞赛动图的方法妙不可言
- 绝了,这6个精挑细选的机器学习资料简直太香了
- Python数据分析三剑客真香啊,还有高清思维导图
- Python编程从入门到实战,看这一篇足够了
1、快捷键
任何重度用户应该都知道,键盘快捷键的有效使用可以节省大量时间。Jupyter 在顶部的菜单下存储了一个 keybord 快捷键列表:Help>Keyboard shortcuts,或者在命令模式下按H键也可以调出。我们每次更新 Jupyter 时都需要检查一下快捷键的情况,因为很多时候总是会添加更多的快捷方式。
另一种访问快捷键的方法,也是学习快捷键的一种简便方法,就是使用命令面板:Cmd+Shift+P(在Linux和Windows上是Ctrl+Shift+P)。这个对话框可帮助我们按名称运行任何命令—如果我们不知道某个操作的键盘快捷键,或者想要执行的操作没有键盘快捷键,那么该对话框将是非常有用。它的功能类似于 Mac 上的 Spotlight 搜索,一旦我们开始使用它,你就会依赖它,以至于会想没有它你会怎么生活!
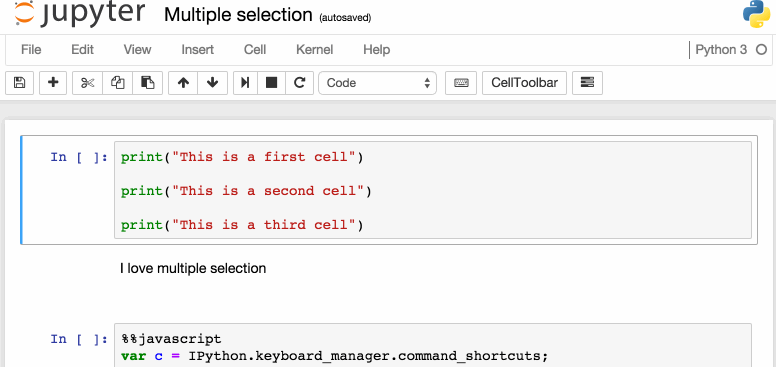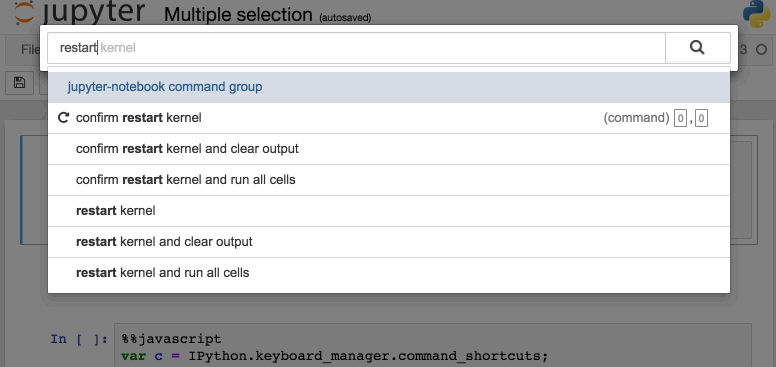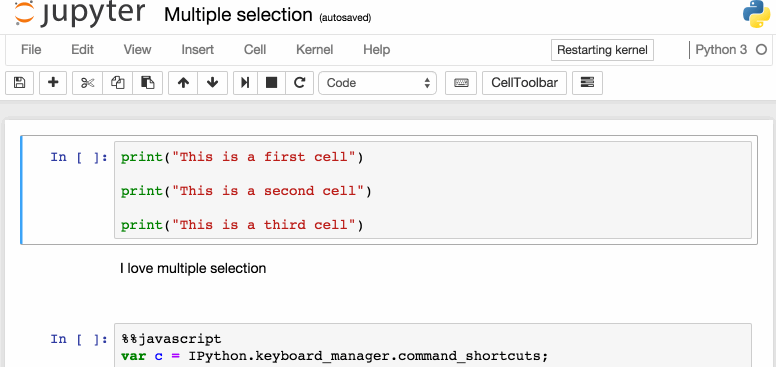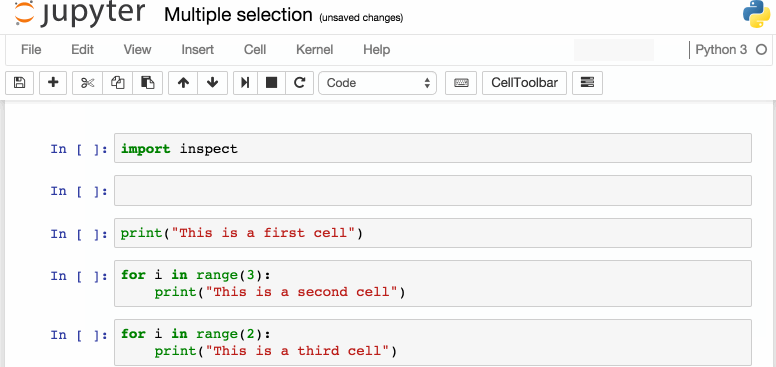
下面是一些我个人比较喜欢的快捷键:
Esc 进入命令模式
在命令模式下:
-
A要在当前单元格上方插入新单元格,B将在下面插入新单元格。
-
M要将当前单元格更改为标记,Y将其更改为代码
-
D+D(按两次键)删除当前单元格
Enter将使我们从命令模式返回到给定单元格的编辑模式。
Shift+Tab将显示刚输入代码单元的对象的Docstring(文档)——可以继续按此键切换以循环使用几种文档模式。
Ctrl+Shift±将当前单元格从光标所在的位置拆分为两个。
Esc+F查找并替换代码,但不是输出。
Esc+O切换单元格输出。
选择多个单元格:
-
Shift+J或Shift+Down选择下一个单元格,也可以使用Shift+K或Shift+Up选择向上一个单元格。
-
一旦我们选择了多个单元格,就可以对它们进行批量的删除/复制/剪切/粘贴/运行,这个功能在需要修改部分脚本是是很有帮助的。
-
可以使用Shift+M合并多个单元格。
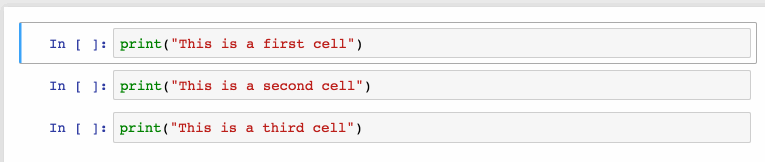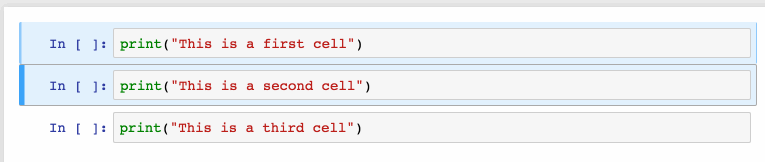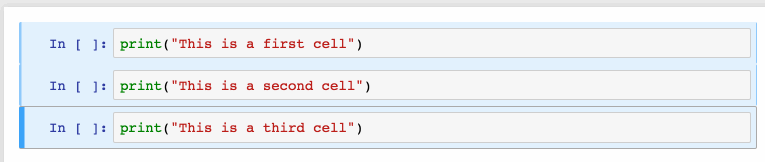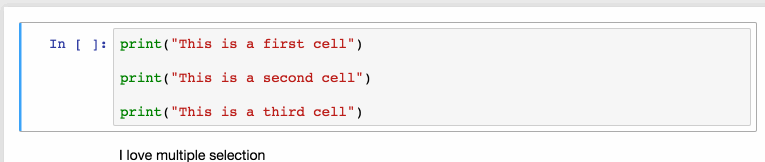
2、漂亮的显示变量
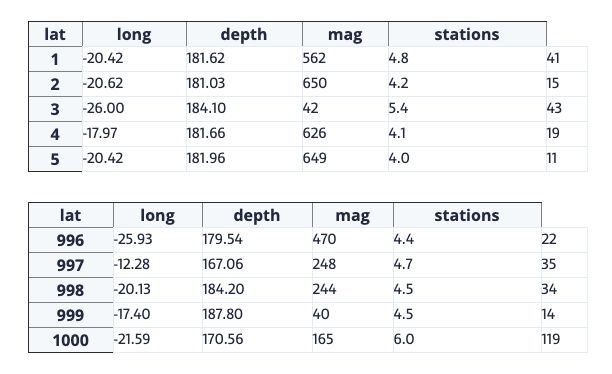
我们都知道,通过使用变量名或语句的未赋值输出完成Jupyter单元格,Jupyter将显示该变量,而不需要print语句。这在处理数据帧时特别有用,因为输出被整齐地格式化为一个表。
但是鲜为人知的是,我们可以修改一个 ast_note_interactivity 选项,使Jupyter对自己行中的任何变量或语句执行此操作,这样我们就可以一次看到多个语句的值。
from IPython.core.interactiveshell import InteractiveShell
InteractiveShell.ast_node_interactivity = "all"
from pydataset import data
quakes = data('quakes')
quakes.head()
quakes.tail()
如果要为所有Jupyter实例(笔记本和控制台)设置这个行为,只需创建一个文件~/.ipython/profile_default/ipython_config.py,通过下面的代码实现
c = get_config()
# Run all nodes interactively
c.InteractiveShell.ast_node_interactivity = "all"
3、文档的简单链接
在“帮助”菜单中,可以找到指向常用库(包括NumPy、Pandas、SciPy和Matplotlib)的联机文档链接。
但是我们也应该知道,在库、方法或变量前面加上?,也可以访问Docstring以快速参考语法。
?str.replace()
Docstring:
S.replace(old, new[, count]) -> str
Return a copy of S with all occurrences of substring
old replaced by new. If the optional argument count is
given, only the first count occurrences are replaced.
Type: method_descriptor
4、绘图
有许多方法可以在notebook中绘制图片
-
matplotlib,用%matplotlib inline激活–大部分情况下,使用matplotlib绘图是实际上的标准
-
%matplotlib notebook提供了交互性,但是速度可能有点慢,因为所有的渲染都是在服务器端完成的。
-
Seaborn是建立在Matplotlib之上的,它使得建造更具吸引力的图片变得更加容易。只需导入Seaborn,matplotlib绘图就变得“更漂亮”,无需任何代码修改。
-
mpld3为matplotlib代码提供了可选的呈现器(使用d3)。很好,可以选择尝试下。
-
bokeh是一个更好的选择,可以建立互动的场景。
-
ploy.ly可以绘制一些很棒的动态图表-虽然曾经是一个付费服务,但是现在已经开源了。
-
Altair是一个相对较新的Python可视化库。很容易使用,并且可以生成非常好看的绘图,但是定制这些绘图的功能远不如Matplotlib强大。
5、IPython 魔法命令行
上面看到的%matplotlib就是IPython魔术命令的一个示例,基于IPython内核,Jupyter可以访问IPython内核中的所有魔法,它们可以让我们更轻松的使用 Jupyter!
# This will list all magic commands
%lsmagic
Available line magics:
%alias %alias_magic %autocall %automagic %autosave %bookmark %cat %cd %clear %colors %config %connect_info %cp %debug %dhist %dirs %doctest_mode %ed %edit %env %gui %hist %history %killbgscripts %ldir %less %lf %lk %ll %load %load_ext %loadpy %logoff %logon %logstart %logstate %logstop %ls %lsmagic %lx %macro %magic %man %matplotlib %mkdir %more %mv %notebook %page %pastebin %pdb %pdef %pdoc %pfile %pinfo %pinfo2 %popd %pprint %precision %profile %prun %psearch %psource %pushd %pwd %pycat %pylab %qtconsole %quickref %recall %rehashx %reload_ext %rep %rerun %reset %reset_selective %rm %rmdir %run %save %sc %set_env %store %sx %system %tb %time %timeit %unalias %unload_ext %who %who_ls %whos %xdel %xmode
Available cell magics:%%! %%HTML %%SVG %%bash %%capture %%debug %%file %%html %%javascript %%js %%latex %%perl %%prun %%pypy %%python %%python2 %%python3 %%ruby %%script %%sh %%svg %%sx %%system %%time %%timeit %%writefile
Automagic is ON, % prefix IS NOT needed for line magics.
6、IPython 魔法-%env 设置环境变量
我们可以管理notebook的环境变量,而无需重新启动jupyter服务器进程。有些库是(比如theano)使用环境变量来控制行为的,%env 就是最方便的方法。
# Running %env without any arguments
# lists all environment variables# The line below sets the environment
# variable
%env OMP_NUM_THREADS%env OMP_NUM_THREADS=4
env: OMP_NUM_THREADS=4
7、IPython 魔法-%run 执行Python代码
%run可以从.py文件执行python代码——这是一个有很好方法,但是却很少有人知道,它还可以执行其他jupyter notebook,这也非常有用。
需要注意的是,使用%run与导入python模块不同。
# this will execute and show the output from
# all code cells of the specified notebook
%run ./two-histograms.ipynb
8、IPython 魔法-%load 从外部脚本插入代码
这个魔法语言,可以用外部脚本替换单元格的内容,可以使用计算机上的文件作为源,也可以使用URL。
# Before Running
%load ./hello_world.py
# After Running
# %load ./hello_world.py
if __name__ == "__main__":
print("Hello World!")
Hello World!
9、IPython 魔法-%store 在notebook之间传递变
%store命令允许我们在两个不同的notebook之间传递变量。
data = 'this is the string I want to pass to different notebook'
%store data
del data # This has deleted the variable
Stored 'data' (str)
然后在一个新的notebook中
%store -r data
print(data)
this is the string I want to pass to different notebook
10、IPython 魔法-%who 列出全局范围的所有变量
不带任何参数的%who命令将列出全局范围中存在的所有变量,传递类似str的参数将只列出该类型的变量。
one = "for the money"
two = "for the show"
three = "to get ready now go cat go"
%who str
one three two
11、IPython 魔法-计时功能
有两个IPython魔术命令对计时很有用–%%time和%timeit,当我们有一些慢代码需要执行并且试图找出问题所在的时候,这就特别方便了。
%%time会给你关于代码里一次代码运行的信息。
%%time
import time
for _ in range(1000):
time.sleep(0.01) # sleep for 0.01 seconds
CPU times: user 21.5 ms, sys: 14.8 ms, total: 36.3 ms Wall time: 11.6 s
%%timeit使用Python timeit模块,该模块运行一条语句100000次(默认情况下),然后提供最快三次的平均值。
import numpy
%timeit numpy.random.normal(size=100)
The slowest run took 7.29 times longer than the fastest. This could mean that an intermediate result is being cached.
100000 loops, best of 3: 5.5 µs per loop
12、IPython 魔法-%%writefile和%pycat 导出单元格的内容/显示外部脚本的内容
使用%%writefile将该单元格的内容保存到外部文件中,%pycat的作用正好相反,它(在弹出窗口中)可以显示外部文件的内容。
%%writefile
%%writefile pythoncode.py
import numpy
def append_if_not_exists(arr, x):
if x not in arr:
arr.append(x)def some_useless_slow_function():
arr = list()
for i in range(10000):
x = numpy.random.randint(0, 10000)
append_if_not_exists(arr, x)
Writing pythoncode.py
%%pycat
%pycat pythoncode.py
import numpy
def append_if_not_exists(arr, x):
if x not in arr:
arr.append(x)def some_useless_slow_function():
arr = list()
for i in range(10000):
x = numpy.random.randint(0, 10000)
append_if_not_exists(arr, x)
13、IPython 魔法-%prun 显示程序在每个函数中花费的时间
使用%prun statement_name将生产一个有序表,显示在语句中调用每个内部函数的次数、每次调用所占用的时间以及函数的所有运行的累计时间。
%prun some_useless_slow_function()
26324 function calls in 0.556 seconds
Ordered by: internal time
ncalls tottime percall cumtime percall filename:lineno(function)
10000 0.527 0.000 0.528 0.000 :2(append_if_not_exists)
10000 0.022 0.000 0.022 0.000 {method 'randint' of 'mtrand.RandomState' objects}
1 0.006 0.006 0.556 0.556 :6(some_useless_slow_function)
6320 0.001 0.000 0.001 0.000 {method 'append' of 'list' objects}
1 0.000 0.000 0.556 0.556 :1()
1 0.000 0.000 0.556 0.556 {built-in method exec}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
14、IPython 魔法-使用%pdb进行调试
Jupyter有自己的Python调试器(pdb)接口,这样就可以进入函数内部并调查那里发生了什么。
%pdb
def pick_and_take():
picked = numpy.random.randint(0, 1000)
raise NotImplementedError()
pick_and_take()
Automatic pdb calling has been turned ON
--------------------------------------------------------------------
NotImplementedError Traceback (most recent call last)
in ()
5 raise NotImplementedError()
6
----> 7 pick_and_take()
in pick_and_take()
3 def pick_and_take():
4 picked = numpy.random.randint(0, 1000)
----> 5 raise NotImplementedError()
6
7 pick_and_take()
NotImplementedError:
> (5)pick_and_take()
3 def pick_and_take():
4 picked = numpy.random.randint(0, 1000)
----> 5 raise NotImplementedError()
6
7 pick_and_take()
ipdb>
15、执行Shell命令
从notebook内部执行shell命令很容易,可以使用此选项检查工作文件夹中的可用数据集
!ls *.csv
nba_2016.csv titanic.csv pixar_movies.csv whitehouse_employees.csv
检查安装的库
!pip install numpy !pip list | grep pandas
Requirement already satisfied (use --upgrade to upgrade): numpy in /Library/Frameworks/Python.framework/Versions/3.4/lib/python3.4/site-packages pandas (0.18.1)
16、使用LaTeX格式化
在markdown单元格中写入LaTeX时,将使用MathJax将其呈现为公式。
$P(A mid B) = frac{P(B mid A)P(A)}{P(B)}$
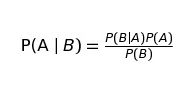
我们要时刻谨记,MarkDown 是 Jupyter 的非常重要的一部分,一定要好好利用
17、在一个notebook中使用不同的kernel运行代码
如果需要,可以将多个内核中的代码合并到一个notebook中。
只需在每个要使用内核的单元格的开头使用ipython magics和内核名称:
-
%%bash
-
%%HTML
-
%%python2
-
%%python3
-
%%ruby
-
%%perl
%%bash
for i in {1..5}
do echo "i is $i"
done
i is 1
i is 2
i is 3
i is 4
i is 5
18、在同一个notebook上运行R和Python
最好的解决方案是安装rpy2,这可以通过pip轻松完成:
pip install rpy2
接下来就是同时使用两种语言了
%load_ext rpy2.ipython
%R require(ggplot2)
array([1], dtype=int32)
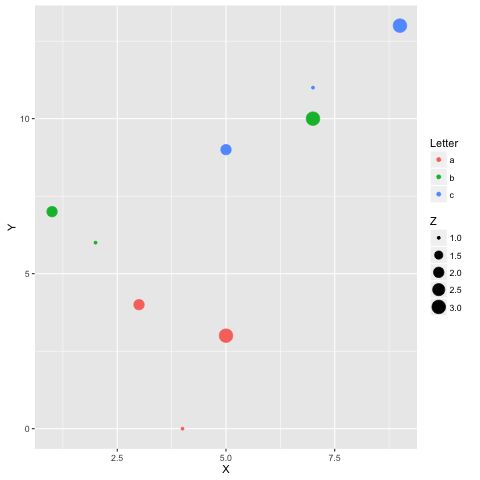
import pandas as pd df = pd.DataFrame({
'Letter': ['a', 'a', 'a', 'b', 'b', 'b', 'c', 'c', 'c'],
'X': [4, 3, 5, 2, 1, 7, 7, 5, 9],
'Y': [0, 4, 3, 6, 7, 10, 11, 9, 13],
'Z': [1, 2, 3, 1, 2, 3, 1, 2, 3]
})
%%R -i df ggplot(data = df) + geom_point(aes(x = X, y= Y, color = Letter, size = Z))
好了,今天的分享就到这里,记得点个赞哦
技术交流
欢迎转载、收藏、有所收获点赞支持一下!
目前开通了技术交流群,群友已超过1000人,添加时最好的备注方式为:来源+兴趣方向,方便找到志同道合的朋友
- 方式①、发送如下图片至微信,长按识别,后台回复:加群;
- 方式②、添加微信号:dkl88191,备注:来自CSDN
- 方式③、微信搜索公众号:Python学习与数据挖掘,后台回复:加群
