论文阅读笔记:RepVgg
1. RepVgg
Ding X, Zhang X, Ma N, et al. Repvgg: Making vgg-style convnets great again[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021: 13733-13742.
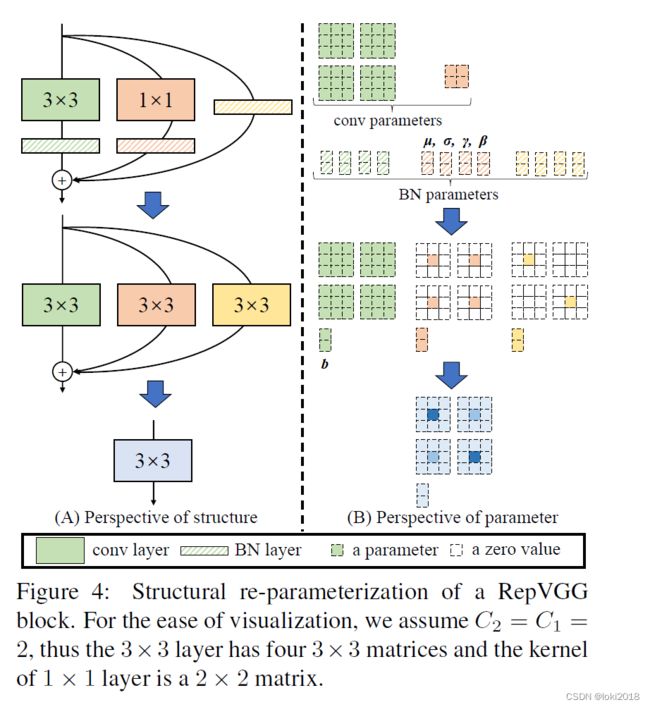
本文的核心思想是将繁杂的残差连接等价于简单的vgg块的形式。在训练时使用正常的残差结构来训练,在推理时使用等价的vgg块,这样可以使得模型推理时的速度大大提高,并且没有任何的性能的损失。
如下所示,左图是多分支的结构,我们的目标是将3x3,1x1,原输入以及BN层融合到一个3x3的卷积操作上。
首先我们回顾一下BN的公式:
y = x − E ( x ) D ( x ) + ξ ⋅ γ + β y = \frac{x-E(x)}{\sqrt{D(x)+\xi}} \cdot \gamma + \beta y=D(x)+ξx−E(x)⋅γ+β
我们令卷积后的输出为 c o n v ( x ) conv(x) conv(x),然后代入到上面的公式里:
y = c o n v ( x ) − E ( c o n v ( x ) ) D ( c o n v ( x ) ) + ξ ⋅ γ + β y = \frac{conv(x)-E(conv(x))}{\sqrt{D(conv(x))+\xi}} \cdot \gamma + \beta y=D(conv(x))+ξconv(x)−E(conv(x))⋅γ+β
那么仔细观察一下可以发现,我们可以将上面的表达看成是一个有偏置的卷积。权重为 c o n v ( x ) D ( c o n v ( x ) ) + ξ \frac{conv(x)}{\sqrt{D(conv(x))+\xi}} D(conv(x))+ξconv(x), 偏置为 β − E ( c o n v ( x ) ) D ( c o n v ( x ) ) + ξ \beta -\frac{E(conv(x))}{\sqrt{D(conv(x))+\xi}} β−D(conv(x))+ξE(conv(x))。
我们通过上面的操作,已经将卷积和BN融合到一起成了一个带偏置的卷积。而之前我们的卷积和BN都是分开写的,并且将卷积的bias设置为False。
接下来就需要将1x1卷积等价替换为3x3卷积,通常采用残差连接时,需要保证输入和输出的形状相等才可以进行相加,所以对于输入的特征图在3x3卷积时的padding要设置为1,因此我们仅仅需要将1x1卷积的卷积核用0填充为3x3卷积核即可,这样的操作和直接用1x1卷积的结果是等价的。
最后我们将原输入等价为3x3卷积也很简单,构建一个形状为[out_channels, in_channels, 3, 3]的全零卷积核即可,每个out_channel中的其中一个in_channel的中心点设置为1即可,这其实可以看成一个特殊的1x1卷积。
矩阵的乘法有分配律,假设3x3的卷积核为A,1x1为B,原输入为C,输入的特征图为X,那么存在 A X + A b + B X + B b + C X + C b = ( A + B + C ) X + A b + B b + C b AX+A_b+BX+B_b+CX+C_b = (A+B+C)X+A_b+B_b+C_b AX+Ab+BX+Bb+CX+Cb=(A+B+C)X+Ab+Bb+Cb,其中带下标的是偏置。可以看到我们已经成功将三个卷积以及BN融合为一个了。
2. 代码实现
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
def _conv_bn(in_channels, out_channels, kernel_size=3, padding=1, stride=1,groups=1):
# 卷积+bn
res = nn.Sequential()
res.add_module("conv", nn.Conv2d(in_channels=in_channels,
out_channels=out_channels,
kernel_size=kernel_size,
stride=stride,
padding=padding,
padding_mode="zeros",
groups=groups,
bias=True))
res.add_module("bn", nn.BatchNorm2d(num_features=out_channels))
return res
class RepBlock(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size=3, stride=1, groups=1, deploy=False):
super(RepBlock, self).__init__()
self.in_channels = in_channels
self.out_channels = out_channels
self.deploy = deploy
self.kernel_size = kernel_size
self.padding = kernel_size // 2
self.groups = groups
self.activation = nn.ReLU()
assert self.kernel_size == 3
assert self.padding == 1
if not self.deploy:
# 训练模式,正常的带分支的结构
self.brb_3x3 = _conv_bn(in_channels=in_channels,
out_channels=out_channels,
kernel_size=self.kernel_size,
stride=stride,
padding=self.padding,
groups=groups)
self.brb_1x1 = _conv_bn(in_channels=in_channels,
out_channels=out_channels,
kernel_size=1,
stride=1,
padding=0,
groups=groups)
self.brb_identity = nn.BatchNorm2d(self.in_channels) if self.in_channels == self.out_channels else None
else:
# 推理模式,需要进行重参数
self.brb_rep = nn.Conv2d(in_channels=in_channels,
out_channels=out_channels,
kernel_size=self.kernel_size,
padding=self.padding,
stride=stride,
bias=True)
def forward(self, inputs):
if(self.deploy):
# 推理模式
return self.activation(self.brb_rep(inputs))
if(self.brb_identity==None):
identity_out=0
else:
identity_out=self.brb_identity(inputs)
return self.activation(self.brb_1x1(inputs)+self.brb_3x3(inputs)+identity_out)
def _switch_to_deploy(self):
self.deploy = True
kernel, bias = self._get_equivalent_kernel_bias()
self.brb_rep=nn.Conv2d(in_channels=self.brb_3x3.conv.in_channels,out_channels=self.brb_3x3.conv.out_channels,
kernel_size=self.brb_3x3.conv.kernel_size,padding=self.brb_3x3.conv.padding,
padding_mode=self.brb_3x3.conv.padding_mode,stride=self.brb_3x3.conv.stride,
groups=self.brb_3x3.conv.groups,bias=True)
self.brb_rep.weight.data=kernel
self.brb_rep.bias.data=bias
for para in self.parameters():
para.detach_()
#删除没用的分支
self.__delattr__('brb_3x3')
self.__delattr__('brb_1x1')
self.__delattr__('brb_identity')
def _pad_1x1_kernel(self,kernel):
# 把1x1卷积填充为3x3卷积
if(kernel is None):
return 0
else:
return F.pad(kernel,[1]*4)
#将identity,1x1,3x3的卷积融合到一起,变成一个3x3卷积的参数
def _get_equivalent_kernel_bias(self):
brb_3x3_weight,brb_3x3_bias=self._fuse_conv_bn(self.brb_3x3)
brb_1x1_weight,brb_1x1_bias=self._fuse_conv_bn(self.brb_1x1)
brb_id_weight,brb_id_bias=self._fuse_conv_bn(self.brb_identity)
return brb_3x3_weight+self._pad_1x1_kernel(brb_1x1_weight)+brb_id_weight,brb_3x3_bias+brb_1x1_bias+brb_id_bias
### 将卷积和BN的参数融合到一起
def _fuse_conv_bn(self,branch):
bias = torch.tensor(0, dtype=torch.float32)
if(branch is None):
return 0, 0
elif(isinstance(branch,nn.Sequential)):
# 传入的是卷积+bn块
kernel = branch.conv.weight #[out_channels, in_channels, kernel_H, kernel_W]
if branch.conv.bias is not None:
bias = branch.conv.bias # [out_channels]
running_mean = branch.bn.running_mean # [out_channels]
running_var = branch.bn.running_var # [out_channels]
gamma = branch.bn.weight # [out_channels]
beta = branch.bn.bias # [out_channels]
eps = branch.bn.eps # [out_channels]
else:
assert isinstance(branch, nn.BatchNorm2d)
if not hasattr(self, 'id_tensor'):
input_dim = self.in_channels // self.groups
kernel_value = np.zeros((self.out_channels, input_dim, 3, 3), dtype=np.float32)
for i in range(self.out_channels):
kernel_value[i, i % input_dim, 1, 1] = 1
self.id_tensor = torch.from_numpy(kernel_value).to(branch.weight.device)
kernel = self.id_tensor
running_mean = branch.running_mean
running_var = branch.running_var
gamma = branch.weight
beta = branch.bias
eps = branch.eps
std=(running_var+eps).sqrt()
t=gamma/std
t=t.view(-1,1,1,1) # 扩充为四维,广播机制来加上bias
return kernel*t,beta + (bias - running_mean*gamma)/std
input=torch.randn(3,3,49,49)
repblock=RepBlock(3,128)
repblock.eval()
out=repblock(input)
repblock._switch_to_deploy()
out2=repblock(input)
print('difference between vgg and repvgg')
print(((out2-out)**2).sum())