Word2Vec原理以及实战详解
文章目录
- 前言
- 0、序言(词嵌入介绍)
- 一、Word2vec详解。
- 二、CBOW 和 Skip-Gram详解。
-
- 2-1、CBOW模型:(已知周围词预测中心词)
- 2-2、Skip-Gram模型(已知中心词预测周围词)
- 2-3、词嵌入的缺点
- 三、Word2vec实战(使用Gensim包)
-
- 3-1、Gensim包概述以及API介绍
- 3-2、实战
- 总结
前言
这里什么玩意都没有。
0、序言(词嵌入介绍)
- 在进行自然语言处理任务之前,我们首先需要将句子中一个个词语转变为数值型的输入,(即词向量:一个词的向量表示)
- 最初的词向量是由one-hot进行编码表示的,这种方式通俗易懂,即代表一个词的0-1列表只有1个位置为1,其他位置为0。
比如:su [0, 0, 1] yan[1, 0, 0] yang[0, 1, 0]
这种方式占用内存大,且词语之间没有语义关联。(上面的例子代表着一个包含三个单词的词典,所以词典长度为3,每一个位置代表一个词)
- 为了克服onehot表示的两个缺点,词嵌入(wrod embedding)应运而生,词嵌入的原理是将高维词向量(一般指的是one-hot编码)嵌入一个低维空间中去,同时,低维空间的词向量还能表达出一些语义。比如,词的相似性(similarity)或者一对词与一对之间的类比关系(analogy)。
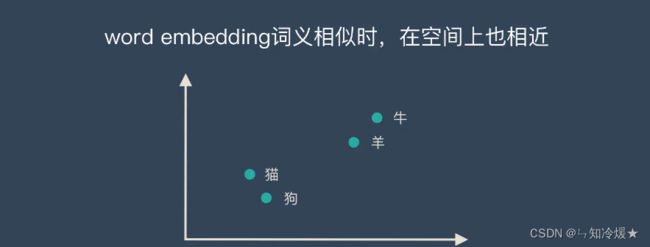
一、Word2vec详解。
word2vec的模型结构如下(词嵌入的一种):
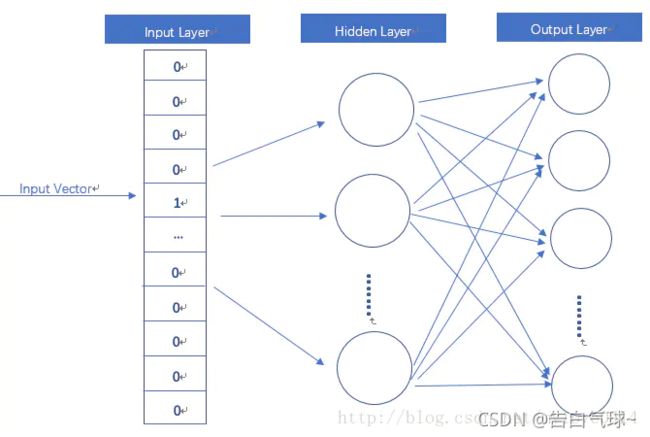
词向量: 模型输入的是One-Hot Vector,隐藏层并没有激活函数,只是线性的单元,输入层维度和输出层维度是一样的,使用的是Softmax回归,模型训练完成后,我们需要的是这个模型通过训练数据所学到的参数。而这些参数,就是输入x的向量化表示,这个向量便是词向量。
Word2vec主要分为两种模型:Skip-gram模型和CBOW模型。
Skip-gram模型是用一个词语作为输入,来预测它周围的上下文。(已知中心词预测周围词)其中设置的参数window-size主要决定了目标词会与多远距离的上下文产生关系,CBOW同理。
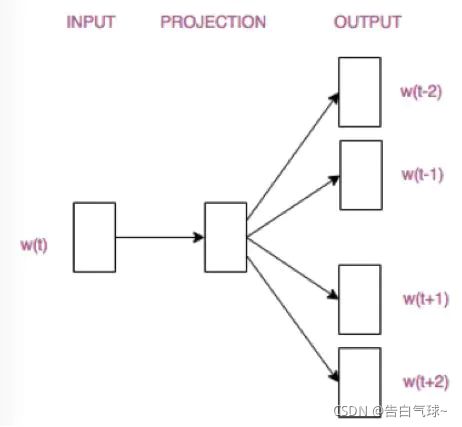
CBOW模型是拿一个词语的上下文作为输入,来预测这个词语本身。

二、CBOW 和 Skip-Gram详解。
2-1、CBOW模型:(已知周围词预测中心词)

流程:输入为上下文单词的one-hot编码,之后乘以共享的输入权重矩阵W,所得到的向量相加求平均作为隐层向量,乘以输出权重矩阵W’,得到的向量经过激活函数的处理得到一个V维的概率分布,其中每一维代表的是一个单词,概率最大的是预测出来的中间词。
使用梯度下降来更新W和W’。训练完毕后,输入层的每个单词与矩阵W相乘得到的向量就是word embedding。(已知周围词预测中心词)
2-2、Skip-Gram模型(已知中心词预测周围词)
周围词y只有一个(最简单情况):x是word2vec的输入one-hot编码,y是在这V个词输出的概率。

周围词y有多个(一般情况):即单个x对应多个y。

2-3、词嵌入的缺点
- 由于词和向量是一对一的关系,所以多义词的问题无法解决。
- Word2vec 是一种静态的方式,虽然通用性强,但是无法针对特定任务做动态优化
三、Word2vec实战(使用Gensim包)
3-1、Gensim包概述以及API介绍
- 是一款开源的第三方python工具包, 主要用来以无监督的方式从原始的非结构化文本中学习到文本隐藏层的主题向量表达,支持包括TF-IDF、LSA、LDA和word2vec在内的多种模型算法。
- 使用Gensim训练Word2vec步骤如下:
1、将语料库预处理:一行一个文档或句子,将文档或句子分词(以空格分割,英文可以不用分词,英文单词之间已经由空格分割,中文预料需要使用分词工具进行分词,常见的分词工具有StandNLP、ICTCLAS、Ansj、FudanNLP、HanLP、结巴分词等);
2、将原始的训练语料转化成一个sentence的迭代器,每一次迭代返回的sentence是一个word(utf8格式)的列表。可以使用Gensim中word2vec.py中的LineSentence()方法实现;
3、将上面处理的结果输入Gensim内建的word2vec对象进行训练即可: - word2vec API介绍:
# sentences:可以是一个list,对于大语料集,建议使用BrownCorpus,Text8Corpus或lineSentence构建。
# size:是指词向量的维度,默认为100。这个维度的取值一般与我们的语料的大小相关,如果是不大的语料,比如小于100M的文本语料,则使用默认值一般就可以了。如果是超大的语料,建议增大维度。大的size需要更多的训练数据,但是效果会更好. 推荐值为几十到几百。
# window:窗口大小,即词向量上下文最大距离,这个参数在我们的算法原理篇中标记为c。window越大,则和某一词较远的词也会产生上下文关系。默认值为5。在实际使用中,可以根据实际的需求来动态调整这个window的大小。如果是小语料则这个值可以设的更小。对于一般的语料这个值推荐在[5,10]之间。个人理解应该是某一个中心词可能与前后多个词相关,也有的词在一句话中可能只与少量词相关(如短文本可能只与其紧邻词相关)。
# min_count: 需要计算词向量的最小词频。这个值可以去掉一些很生僻的低频词,默认是5。如果是小语料,可以调低这个值。可以对字典做截断, 词频少于min_count次数的单词会被丢弃掉。
# negative:即使用Negative Sampling时负采样的个数,默认是5。推荐在[3,10]之间。这个参数在我们的算法原理篇中标记为neg。
# cbow_mean: 仅用于CBOW在做投影的时候,为0,则算法中的为上下文的词向量之和,为1则为上下文的词向量的平均值。在我们的原理篇中,是按照词向量的平均值来描述的。个人比较喜欢用平均值来表示,默认值也是1,不推荐修改默认值。
# iter: 随机梯度下降法中迭代的最大次数,默认是5。对于大语料,可以增大这个值。
# alpha: 是初始的学习速率,在训练过程中会线性地递减到min_alpha。在随机梯度下降法中迭代的初始步长。算法原理篇中标记为η,默认是0.025。
# min_alpha: 由于算法支持在迭代的过程中逐渐减小步长,min_alpha给出了最小的迭代步长值。随机梯度下降中每轮的迭代步长可以由iter,alpha, min_alpha一起得出。这部分由于不是word2vec算法的核心内容,因此在原理篇我们没有提到。对于大语料,需要对alpha, min_alpha,iter一起调参,来选择合适的三个值。
# max_vocab_size: 设置词向量构建期间的RAM限制,设置成None则没有限制。
# sample: 高频词汇的随机降采样的配置阈值,默认为1e-3,范围是(0,1e-5)。
# seed:用于随机数发生器。与初始化词向量有关。
# workers:用于控制训练的并行数。
class Word2Vec(utils.SaveLoad):
def __init__(
self, sentences=None, size=100, alpha=0.025, window=5, min_count=5,
max_vocab_size=None, sample=1e-3, seed=1, workers=3, min_alpha=0.0001,
sg=0, hs=0, negative=5, cbow_mean=1, hashfxn=hash, iter=5, null_word=0,
trim_rule=None, sorted_vocab=1, batch_words=MAX_WORDS_IN_BATCH):
3-2、实战
texts:

vocabs(经过分词后即将要给到word2vec的对象):

# vocab在这里是一个无数分词后的列表组成的集合
vocabs = []
max_len = 0
for s in texts:
tokens = list(jieba.lcut(s))
vocabs.append(tokens)
if len(tokens) > max_len:
max_len = len(tokens)
# 参数好像和上边的介绍不太一样,emm,灵活使用吧,看版本号。
# vector_size:vector_size 是Word2Vec将单词映射到的N维空间的维数(N)就是说用N个特征来表示这个词向量
# min_count:min_count用于修剪内部字典。在十亿个单词的语料库中只出现一次或两次的单词可能是错别字和垃圾信息。此外,没有足够的数据来对这些单词进行任何有意义的训练,因此最好忽略它们
model_own = Word2Vec(sentences=vocabs, vector_size=100, sg=1, min_count=1)
# 模型保存
model_own.save("word2vec.model")
# 模型加载
new_model = Word2Vec.load('word2vec.model')
# 增量训练,total_examples:句子数;epochs:迭代次数
model_own.train(vocabs, total_examples=24162, epochs=10)
# model_own.wv: 向量表示,可以使用迭代器来输出所有向量表示。
# model_own.wv[char]: 获取某个词语的词嵌入表示
其他功能:语义推断。
model.most_similar(positive=['woman', 'king'], negative=['man'], topn=1)
[('queen', 0.50882536)]
model.doesnt_match("breakfast cereal dinner lunch";.split())
'cereal'
model.similarity('woman', 'man')
0.73723527
model.most_similar(['man'])
[(u'woman', 0.5686948895454407),
(u'girl', 0.4957364797592163),
(u'young', 0.4457539916038513),
(u'luckiest', 0.4420626759529114),
(u'serpent', 0.42716869711875916),
(u'girls', 0.42680859565734863),
(u'smokes', 0.4265017509460449),
(u'creature', 0.4227582812309265),
(u'robot', 0.417464017868042),
(u'mortal', 0.41728296875953674)]
参考链接:
通俗理解word2vec.
word2vec 中的数学原理详解.
[NLP] 秒懂词向量Word2vec的本质.
【转】深度学习word2vec笔记之基础篇 .
Word2Vec-——gensim实战教程.
词嵌入 | Word embedding.
Word2vec.
自然语言处理库——Gensim之Word2vec.
总结
看了一眼日期,今天是双十一哎,昨天晚上和小妲己扯皮到3点,有点困。