词语向量化 — word2vec简介和使用(一)
前期回顾
文本向量化
词向量介绍
一句话概括词向量用处:就是提供了一种数学化的方法,把自然语言这种符号信息转化为向量形式的数字信息。这样就把自然语言问题要转化为机器学习问题。
最常用的词向量模型无非是 one-hot Representation模型和 distributed representation 模型。
One-hot Representation
One-hot Representation 即用一个很长的向量来表示一个词,向量长度为词典的大小N,每个向量只有一个维度为1,表示该词语在词典的位置,其余维度全部为0。
举例:
“话筒”表示为 [0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 …]
“麦克”表示为 [0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 …]
这种 One-hot Representation 如果采用稀疏方式存储,会是非常简洁,也就是给每个词分配一个数字 ID。但这种表示方式有两个缺点:
(1)容易受维数灾难的困扰,每个词语的维度就是语料库字典的长度。
(2)词语编码往往是随机的,导致不能刻画词与词之间的相似性
Distributed representation
Distributed representation 最早由 Hinton在1986 年提出。其依赖思想是:词语的语义是通过上下文信息来确定的,即相同语境出现的词,其语义也相近。
Distributed Representation与one-hot representation对比
- 在形式上,one-hot representation 词向量是一种稀疏词向量,其长度就是字典长度,而Distributed Representation是一种固定长度的稠密词向量。一般长这样:[0.792, −0.177, −0.107, 0.109, −0.542, …]
- 在功能上,Distributed representation 最大的贡献就是让相关或者相似的词,在距离上更接近了。
关于生成 Distributed representation 形式的词向量,除了word2vec外,还有其他生成的方式。如:LSA矩阵分解模型、 PLSA 潜在语义分析概率模型、LDA 文档生成模型。但本文只关注 word2vec 这种方式,其他不做介绍。
将word映射到一个新的空间中,并以多维的连续实数向量进行表示叫做“Word Represention” 或 “Word Embedding”。自从21世纪以来,人们逐渐从原始的词向量稀疏表示法过渡到现在的低维空间中的密集表示。用稀疏表示法在解决实际问题时经常会遇到维数灾难,并且语义信息无法表示,无法揭示word之间的潜在联系。而采用低维空间表示法,不但解决了维数灾难问题,并且挖掘了word之间的关联属性,从而提高了向量语义上的准确度。
参考:http://ir.dlut.edu.cn/news/detail/291
神经网络训练词向量
NNLM 是 Neural Network Language Model 的缩写,即神经网络语言模型。这方面最值得阅读的文章:Bengio 的《A Neural Probabilistic Language Model》
这部分内容首先需理解下图。Bengio用了一个三层的神经网络来构建语言模型,同样也是 n-gram 模型。本小节即主要是对于这个图的理解:
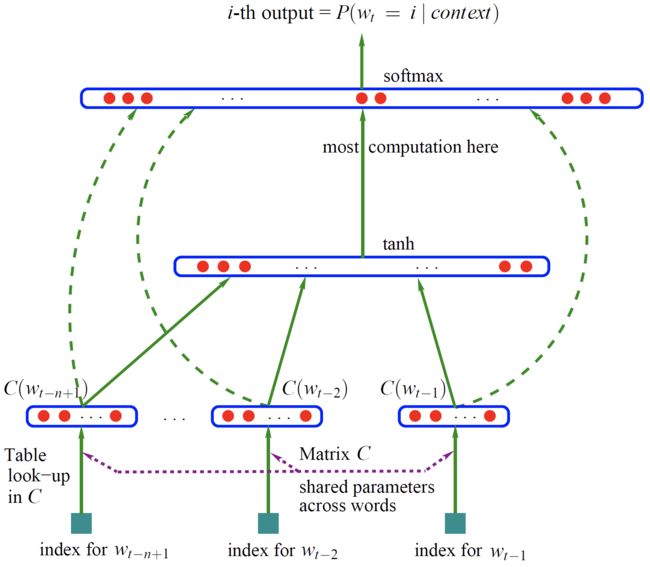
以一句英文为例:The cat is walking in the bedroom。如果我们需要这句话中,所有上下文为数量为4的连续词汇片段,那么就有 The cat is walking、cat is walking in、is walking in the 以及 walking in the bedroom 这样4个片段。从语言模型角度上来讲,每个连续词汇片段的最后一个单词是什么,是受前面三个词汇制约。因此,这就形成了一个根据前面三个单词,预测最后一个单词的监督学习系统。
如果用神经网络框架来描述,上图就代表一个监督模型的神经网络,当上下文数量为n的时候,这里的模型就是用前n-1个词语,也就是w(t-1) … w(t-n+1),来预测第t个词语w(t)。在神经网络中,用于计算的都是这些词的向量表示,如C(w(t-1)) 就是词语 w(t-1) 的向量表示。
这里C(w(t-1))其实就是词向量,但不是最终的词向量,最终结果还需要多轮迭代计算。其实这些词向量就是神经网络里的参数,生成词向量的过程就是一个参数更新的过程。
注意:对于初学者来说这里有个坑,考虑一个问题:词向量不是我们最终得到的吗?那我们如何得到最初输入的每个词对应的词向量C(w(t-1))、C(w(t-2))、、、C(w(t-n+1))?以下是我查阅资料后自己的理解:
在上图中存在一个系数矩阵C(是一个NM的矩阵),其中N是词典的长度,M是词向量的维度。最底层的输入其实是词语的one-hot形式,one-hot也可以看成 1N的矩阵 ,与这个系数矩阵C(NM, M是word2vec词向量维数)相乘之后就可以得到1M的向量,这个向量就是这个词对应的词向量了。
从本质上来看,词语w转化为词向量C(w),就是根据词 w 的one-hot 形式,通过矩阵相乘,从系数矩阵C中取出一行。
还需注意:这个系数矩阵C,就是神经网络的参数,最初是随机的,随着训练的进行不断被更新。
这部分先讲到这里的,接下讲的就是系数矩阵如何更新的,关于神经网络的介绍暂时不打算写下去了。推荐:http://licstar.net/archives/328#s21
Word2vec 训练介绍
这部分还是一样,尽量想避开那些底层原理、不想多扯。
Word2Vec 实际上是两种不同思想实现的:CBOW(Continuous Bag of Words) 和 Skip-gram。
CBOW的目标是根据上下文来预测当前词语的概率,且上下文所有的词对当前词出现概率的影响的权重是一样的,因此叫continuous bag-of-words模型。如在袋子中取词,取出数量足够的词就可以了,至于取出的先后顺序是无关紧要的。
Skip-gram刚好相反:根据当前词语来预测上下文的概率。
这两种方法都利用人工神经网络作为它们的分类算法。起初每个单词都是一个随机 N 维向量。经过训练之后,该算法利用 CBOW 或者 Skip-gram 的方法获得了每个单词的最优向量。训练过程如下图所示:
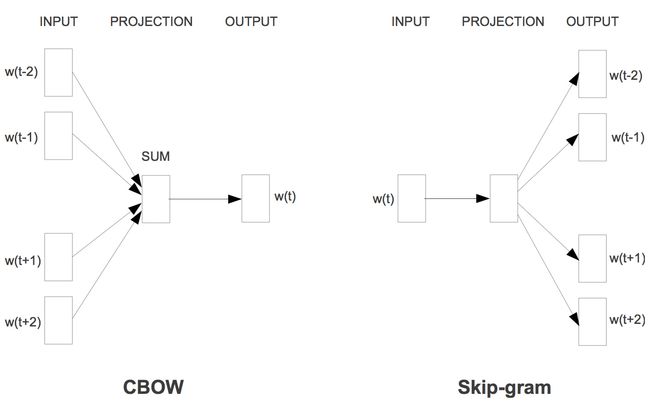
对于CBOW 和 Skip-gram 的基本思想讲到这里就结束了。按照学习word2vec一般套路,接下来就是实现CBOW 和 Skip-gram 这两种思想的方法了— Hierarchical Softmax 和 negative sampling。
关于Hierarchical Softmax 和 negative sampling 的介绍,非常推荐《Word2vec 中的数学原理详解》,其中在第4章节和第5章节有详细论述,因为这里不想copy的。此外还推荐其他资料:
《Deep learning 实战之word2vec》
文本深度表示模型——word2vec&doc2vec词向量模型
Python Gensim 使用介绍
本章节是word2vec代码实践,用的是Python的Gensim工具包。貌似还有其他工具包,不过我没有使用过。
Gensim的word2vec的输入是句子的序列,每个句子是一个单词列表。且本文用 20newsgroups 语料来训练word2vec模型。不多说了,直接上代码!
训练模型
# coding:utf-8
from sklearn.datasets import fetch_20newsgroups
from gensim.models import word2vec
from bs4 import BeautifulSoup
import re
import nltk
import time
start = time.time()
news = fetch_20newsgroups(subset='all')
X, y = news.data, news.target
def news_to_sentences(news):
news_text = BeautifulSoup(news).get_text()
tokenizer = nltk.data.load('tokenizers/punkt/english.pickle')
raw_sentences = tokenizer.tokenize(news_text)
sentences = []
for sent in raw_sentences:
sentences.append(re.sub('[^a-zA-Z]', ' ', sent.lower().strip()).split())
return sentences
# 句子词语列表化
sentences = []
for x in X:
sentences.extend(news_to_sentences(x))
# 设置词语向量维度
num_featrues = 300
# 保证被考虑词语的最低频度
min_word_count = 20
# 设置并行化训练使用CPU计算核心数量
num_workers = 2
# 设置词语上下午窗口大小
context = 5
downsampling = 1e-3
model = word2vec.Word2Vec(sentences, workers=num_workers, size=num_featrues, min_count=min_word_count, window=context, sample=downsampling)
model.init_sims(replace=True)
# 输入一个路径,保存训练好的模型,其中./data/model目录事先要存在
model.save("./data/model/word2vec_gensim")
# model.wv.save_word2vec_format("data/model/word2vec_org","data/model/vocabulary",binary=False)
常用参数说明

加载模型
from gensim.models import word2vec
加载模型
from gensim.models import word2vec
# 加载模型
model = word2vec.Word2Vec.load("./data/model/word2vec_gensim")
加载模型后使用另外句子来进一步训练模型。(这里不演示)
# model.train(more_sentences)
寻找指定词语最相似的词语
print model.most_similar('morning', topn=1)
输出:[(u’afternoon’, 0.8059341907501221)]
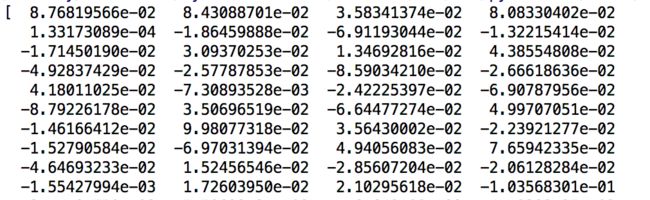
得到指定词的词向量
print model['morning’]
输出如下,一共300维,截取其中部分数据:
词向量加减
print model.most_similar(positive=['man', 'son'], negative=['woman'], topn=4)
输出:
[(u’lord’, 0.7308236360549927), (u’father’, 0.6855698227882385), (u’spirit’, 0.6771275997161865), (u’grace’, 0.6561732292175293)]
貌似没有像google官方示例一样,得到很好的结果。
计算两个词语相似度
print model.similarity('woman', 'man’)
输出:0.756960729577
通过输出我们发现,借助word2vec技术,在不使用词典的情况下依然可以通过上下文信息找到词语之间的相似性。
计算两个句子相似度
list1 = ['the', 'cat', 'is', 'walking', 'in', 'the', 'bedroom']
list2 = ['the', 'dog', 'was', 'running', 'across', 'the', 'kitchen']
print model.n_similarity(list1, list2)
输出:0.811719864179
相同的两篇文本输入,和上篇blog的方式进行对比。发现word2vec对于计算文章间语义相似度,有非常好的效果。
参考
除了文中已经给出的参考外,还包括以下参考资料:
- 知乎问答:word2vec是如何得到词向量的?
- 知乎问答:word2vec有什么应用?
- 知乎专栏:秒懂词向量Word2vec的本质 (对各种资源总结挺好的,搜藏下,以后再看)
- Gensim 官网用户手册
- 《Python 机器学习及实践》
主要来源于:宇毅