语音识别系列︱paddlehub的开源语音识别模型测试(二)
上一篇:
语音识别系列︱用python进行音频解析(一)
这一篇开始主要是开源模型的测试,百度paddle有两个模块,paddlehub / paddlespeech都有语音识别模型,这边会拆分两篇来说。
整体感觉,准确度不佳,而且语音识别这块的使用文档写的缺胳膊少腿的;
使用者需要留心各类安装问题。
文章目录
- 1 paddlehub的安装
- 2 几款模型
- 3 三款语音识别模型实验
-
- 3.1 deepspeech2_aishell - 0.065
- 3.2 u2_conformer_wenetspeech - 0.087
- 3.3 u2_conformer_aishell - 0.055
- 4 文本-标点恢复
- 5 语音识别 + 标点恢复 案例
1 paddlehub的安装
先把paddlepaddle安装好了
!pip install --upgrade paddlepaddle -i https://mirror.baidu.com/pypi/simple
!pip install --upgrade paddlehub -i https://mirror.baidu.com/pypi/simple
!pip install pytest-runner -i https://mirror.baidu.com/pypi/simple
!pip install paddlespeech -i https://mirror.baidu.com/pypi/simple
接下来可就麻烦一些,要下载的很多,一些依赖:
apt-get install -y libsndfile1 swig g++ gcc
其中在paddlehub教程中是libsndfile,但是目前已经找不到这个依赖了;然后有些linux没装gcc/g++
安装swig_decoder:
git clone https://github.com/PaddlePaddle/DeepSpeech.git && cd DeepSpeech && git reset --hard b53171694e7b87abe7ea96870b2f4d8e0e2b1485 && cd deepspeech/decoders/ctcdecoder/swig && sh setup.sh
如果不安装成功,会报错:
ImportError: No module named swig_decoders
2 几款模型
语音识别的模型paddlehub有以下几个:模型
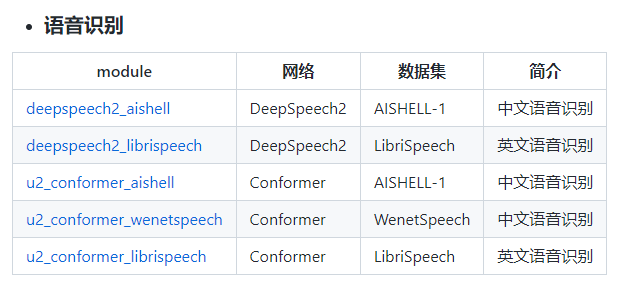
中文的有三个,安装完之后,可以下载:
hub install deepspeech2_aishell
hub install u2_conformer_wenetspeech
hub install u2_conformer_aishell
模型三个链接:
- u2_conformer_aishell
- deepspeech2_aishell
- u2_conformer_wenetspeech
3 三款语音识别模型实验
跑实验的时候如果会出现报错:
ImportError: libGL.so.1: cannot open shared object file: No such file or directory
需要安装:
pip install opencv-python-headless -i https://mirror.baidu.com/pypi/simple
如果还一直报错,那就卸载了,然后再重新装。
这几款模型音频采样率16000,如果不是,那就需要更改音频采样率:
语音识别系列︱用python进行音频解析(一)
3.1 deepspeech2_aishell - 0.065

DeepSpeech2是百度于2015年提出的适用于英文和中文的end-to-end语音识别模型。deepspeech2_aishell使用了DeepSpeech2离线模型的结构,模型主要由2层卷积网络和3层GRU组成,并在中文普通话开源语音数据集AISHELL-1进行了预训练,该模型在其测试集上的CER指标是0.065。
import paddlehub as hub
# 采样率为16k,格式为wav的中文语音音频
wav_file = '/PATH/TO/AUDIO'
model = hub.Module(
name='deepspeech2_aishell',
version='1.0.0')
text = model.speech_recognize(wav_file)
print(text)
3.2 u2_conformer_wenetspeech - 0.087
模型信息:
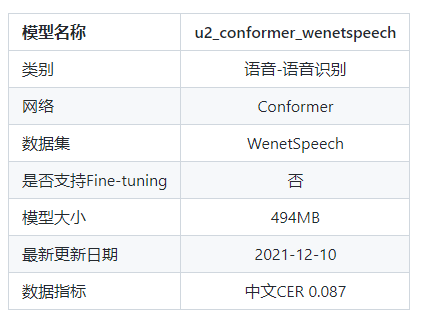
U2 Conformer模型是一种适用于英文和中文的end-to-end语音识别模型。u2_conformer_wenetspeech采用了conformer的encoder和transformer的decoder的模型结构,并且使用了ctc-prefix beam search的方式进行一遍打分,再利用attention decoder进行二次打分的方式进行解码来得到最终结果。
import paddlehub as hub
# 采样率为16k,格式为wav的中文语音音频
wav_file = '/PATH/TO/AUDIO'
model = hub.Module(
name='u2_conformer_wenetspeech',
version='1.0.0')
text = model.speech_recognize(wav_file)
print(text)
3.3 u2_conformer_aishell - 0.055
模型信息:

U2 Conformer模型是一种适用于英文和中文的end-to-end语音识别模型。u2_conformer_aishell采用了conformer的encoder和transformer的decoder的模型结构,并且使用了ctc-prefix beam search的方式进行一遍打分,再利用attention decoder进行二次打分的方式进行解码来得到最终结果。
u2_conformer_aishell在中文普通话开源语音数据集AISHELL-1进行了预训练,该模型在其测试集上的CER指标是0.055257。
import paddlehub as hub
# 采样率为16k,格式为wav的中文语音音频
wav_file = '/PATH/TO/AUDIO'
model = hub.Module(
name='u2_conformer_aishell',
version='1.0.0')
text = model.speech_recognize(wav_file)
print(text)
参考:https://github.com/PaddlePaddle/PaddleHub/tree/develop/modules/audio/asr/u2_conformer_aishell
4 文本-标点恢复
模型信息,文档:

Ernie是百度提出的基于知识增强的持续学习语义理解模型,该模型将大数据预训练与多源丰富知识相结合,通过持续学习技术,不断吸收海量文本数据中词汇、结构、语义等方面的知识,实现模型效果不断进化。
"悟道"文本数据集 采用20多种规则从100TB原始网页数据中清洗得出最终数据集,注重隐私数据信息的去除,源头上避免GPT-3存在的隐私泄露风险;包含教育、科技等50+个行业数据标签,可以支持多领域预训练模型的训练。
数据总量:3TB
数据格式:json
开源数量:200GB
数据集下载:https://resource.wudaoai.cn/
日期:2021年12月23日
auto_punc采用了Ernie1.0预训练模型,在WuDaoCorpora 2.0的200G开源文本数据集上进行了标点恢复任务的训练,模型可直接用于预测,对输入的对中文文本自动添加7种标点符号:逗号(,)、句号(。)、感叹号(!)、问号(?)、顿号(、)、冒号(:)和分号(;)。
安装:
hub install auto_punc
预测代码:
import paddlehub as hub
model = hub.Module(
name='auto_punc',
version='1.0.0')
texts = [
'今天的天气真好啊你下午有空吗我想约你一起去逛街',
'我最喜欢的诗句是先天下之忧而忧后天下之乐而乐',
]
punc_texts = model.add_puncs(texts)
print(punc_texts)
# ['我最喜欢的诗句是:先天下之忧而忧,后天下之乐而乐。', '今天的天气真好啊!你下午有空吗?我想约你一起去逛街。']
5 语音识别 + 标点恢复 案例
这里简单写一个官方的:
import paddlehub as hub
# 语音识别
# 采样率为16k,格式为wav的中文语音音频
wav_file = '/PATH/TO/AUDIO'
model = hub.Module(
name='deepspeech2_aishell',
version='1.0.0')
text = model.speech_recognize(wav_file)
print(text)
# 标点恢复
model = hub.Module(
name='auto_punc',
version='1.0.0')
punc_texts = model.add_puncs([text])
print(punc_texts)
# ['我最喜欢的诗句是:先天下之忧而忧,后天下之乐而乐。', '今天的天气真好啊!你下午有空吗?我想约你一起去逛街。']