NLP 论文领读|中文拼写纠错:怎样改善模型对 multi-typo 的纠正效果?
欢迎关注「NLP 论文领读」专栏!快乐研究,当然从研读 paper 开始。关注公众号「澜舟科技」了解更多!
本期分享者:甘子发
澜舟科技算法实习生 ,郑州大学自然语言处理实验室(ZZUNLP)二年级硕士生。目前正在进行文本纠错方向的研究 E-mail: [email protected]
写在前面
自然语言文本中经常会出现一些拼写错误(typo),在中文文本里即所谓的错别字,中文拼写纠错(Chinese Spelling Correction,CSC) 可以对中文文本中的 typo 进行检测和纠正。拼写纠错在诸多 NLP 任务和应用中都有重要作用,如 OCR、语音识别和搜索引擎等。在 NLP 任务和日常工作生活场景中,中文文本中的 typo 主要是拼音和字形相似导致的,示例如表 1 所示。

表 1
一般 CSC 系统的输入和输出序列长度相同,所以现在 CSC 系统主要采用基于 BERT 的非自回归生成模型,这些模型依据输入序列中的所有字符来平行生成每个位置的字符,而随着 BERT 等预训练模型的成功,CSC 模型的性能也有了极大的提升。
虽然 BERT 模型很强大,但其在解决 CSC 任务时也会遇到一些问题。
首先,基于 BERT 的 CSC 模型根据 typo 本身及其上下文对该处 typo 进行检测和纠正,但当一个句子中有多处拼写错误(multi-typo)时,则句子中每个字符的上下文都至少包含一处 typo,这导致其信息中含有噪声,从而影响模型的效果。论文统计了中文拼写纠错任务 SIGHAN13、14、15 的测试集中的 multi-typo 数据,如表 2 所示,并且把这些数据抽出做成测试集,测试模型对 multi-typo 文本的纠错能力,结果如表 3 所示(character-level),结果证实了上述结论。
其次,BERT 是掩码语言模型,其从大规模语料中学习怎样根据上下文恢复被遮掩的 token,但对于一个被遮掩的位置可能有多个有效的字符,这时候 BERT 模型则会倾向于恢复成最常见的那一个,而在 CSC 任务中,则表现为模型可能会把一个有效的表述改成另外一种更常见的表述,比如将“这并非是说……”改成“这并不是说……”。
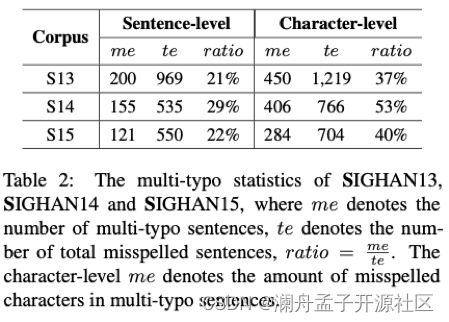
表 2
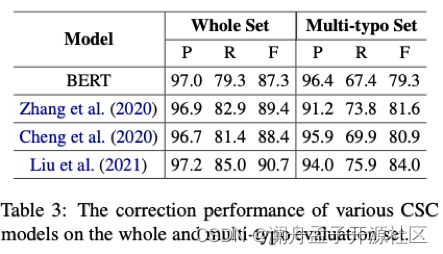
表 3
针对上述的两个问题,来自腾讯 AI 平台部门和北京大学的研究人员提出了一种名为 CRASpell 的解决方法,让我们一起来看看吧。
论文标题
CRASpell: A Contextual Typo Robust Approach to Improve Chinese Spelling Correction
论文作者
Shulin Liu, Shengkang Song, Tianchi Yue, Tao Yang, Huihui Cai, Tinghao Yu, Shengli Sun
作者单位
Tencent AI Platform Department, China
Peking University, China
论文链接
https://aclanthology.org/2022.findings-acl.237/
项目代码
https://github.com/liushulinle/CRASpell
CRASpell 介绍
该论文将 multi-typo 降低模型性能的问题称作 Contextual Typo Disturbance,将模型对文本不必要的纠正称为 Overcorrection,并针对这两个问题提出了 CRASpell 模型,其结构如图 1 所示:

图 1
由图 1 我们可以看到,CRASpell 主要分为两部分,左边为 Correction Module,右边为 Noise Modeling Module。
1. Correction Module
Correction Module 中,Transformer Encoder 加 Generative Block 就是一个基本的 CSC 模型,Generative Block 计算并输出一个 generative distribution,其过程可以描述为:
P g = softmax ( W g h i + b g ) \mathbf{P}_{\mathrm{g}}=\operatorname{softmax}\left(\mathbf{W}_{\mathbf{g}} \mathbf{h}_{\mathrm{i}}+\mathbf{b}_{\mathrm{g}}\right) Pg=softmax(Wghi+bg) (1)
论文中使用 copy mechanism [1-2] 来解决 Overcorrection 的问题,其对于输入序列中的每一个 token,都有一个 one-shot 向量的 copy distribution,其形式可以描述为:
p c [ k ] = { 0 k ≠ i d x ( x i ) 1 k = i d x ( x i ) \mathbf{p}_{\mathbf{c}}[k]=\left\{\begin{array}{ll} 0 & k \neq i d x\left(x_{i}\right) \\ 1 & k=i d x\left(x_{i}\right) \end{array}\right. pc[k]={01k=idx(xi)k=idx(xi) (2)
Copy Block 则是用来输出一个 copy probability,计算过程如下:
h c = W c h f l n ( h i ) + b c h h e ′ = f i n ( f a r c ( h e ) ) ω = Sigmoid ( W c h c ′ ) \begin{array}{l} \mathbf{h}_{\mathrm{c}}=\mathbf{W}_{\mathbf{c h}} f_{l n}\left(\mathbf{h}_{\mathrm{i}}\right)+\mathbf{b}_{\mathrm{ch}} \\ \mathbf{h}_{\mathrm{e}}^{\prime}=f_{i n}\left(f_{\mathrm{arc}}\left(\mathbf{h}_{\mathrm{e}}\right)\right) \\ \omega=\operatorname{Sigmoid}\left(\mathbf{W}_{\mathrm{c}} \mathbf{h}_{\mathrm{c}}^{\prime}\right) \end{array} hc=Wchfln(hi)+bchhe′=fin(farc(he))ω=Sigmoid(Wchc′) (3)
然后以 copy probability 为权重,将 copy distribution 和 generative distribution 相加作为最后输出,这样相当于给输入的 token 额外加上了一个偏重,让模型更加倾向于保留原来的 token:
p = ω × p c + ( 1 − ω ) × p g \mathbf{p}=\omega \times \mathbf{p}_{\mathbf{c}}+(1-\omega) \times \mathbf{p}_{\mathbf{g}} p=ω×pc+(1−ω)×pg (4)
2. Noise Modeling Module
针对 Contextual Typo Disturbance 问题,CRASpell 提出了 Noise Modeling Module,其思想是训练模型在原始上下文和有噪声的上下文中输出相似的概率分布。
Noise Modeling Module 的结构也是 Transformer Encoder 加 Generative Block,不同的是其前面还有一个 Noisy Block,其通过替换的方式在 typo 的上下文中插入噪声,而噪声上下文的质量又受到两个因素的影响:
a. 插入噪声的位置
作者根据表 3 的实验结果,决定在 typo 周围 d t d_{t} dt 个字符内选择, d t = 5 d_{t}=5 dt=5 时如图 2 所示,如果句子中没有错误或者选择的位置正好是一处 typo,则不插入噪声。

图 2
b. 应该替换成什么字符
论文中使用公开的混淆集(confusion set)[3],将选择位置上的字符替换成其相似字符,这也是 CSC 任务中制作伪数据的常用方法,不同类型字符的替换比例为:70%近音字、15%近形字以及 15%随机选择的字符。
原始输入经过 Noisy Block 插入噪声后得到新的输入,经过 Noise Modeling Module 后的输出为 p g ~ \widetilde{\mathbf{p}_{\mathrm{g}}} pg , 最后将其与 Correction Module 中的 generative distribution 共同计算 KL 散度损失:
L K L = 1 2 ( D K L ( p g ∥ p g ~ ) + D K L ( p g ~ ∥ p g ) ) \mathcal{L}_{K L}=\frac{1}{2}\left(\mathcal{D}_{K L}\left(\mathbf{p}_{\mathbf{g}} \| \widetilde{\mathbf{p}_{\mathbf{g}}}\right)+\mathcal{D}_{K L}\left(\widetilde{\mathbf{p}_{\mathbf{g}}} \| \mathbf{p}_{\mathbf{g}}\right)\right) LKL=21(DKL(pg∥pg )+DKL(pg ∥pg)) (5)
在 Correction Module 中,给定训练样本 (X, Y),对于式 (4) 中的 ,其每个位置的 token 的 loss 为:
L c i = − log p ( Y i ∣ X ) \mathcal{L}_{c}^{i}=-\log \mathbf{p}\left(\mathbf{Y}_{\mathbf{i}} \mid \mathbf{X}\right) Lci=−logp(Yi∣X) (6)
结合式 (5) 和式 (6),得到整个模型训练的损失函数为:
L i = ( 1 − α i ) L c i + α i L K L i \mathcal{L}^{i}=\left(1-\alpha_{i}\right) \mathcal{L}_{c}^{i}+\alpha_{i} \mathcal{L}_{K L}^{i} Li=(1−αi)Lci+αiLKLi (7)
α i = { α , X ~ i = X i 0 , otherwise \alpha_{i}=\left\{\begin{array}{c} \alpha, \quad \widetilde{\mathbf{X}}_{i}=\mathbf{X}_{i} \\ 0, \text { otherwise } \end{array}\right. αi={α,X i=Xi0, otherwise (8)
这里我们可以看到,Noise Modeling Module 只在训练时被用到,而插入噪声的位置没有计算在 loss 内,这样做是为了不改变训练过程中数据里 typo 的数量,让插入的噪声只起到改变上下文信息的作用。
实验设置和结果
数据集方面,论文中的训练集包括 10K 人工标注的 SIGHAN 数据 [3-5],加上 271K 的自动生成的数据 [6],测试集使用的是 SIGHAN15 的测试集,另外作者还抽取了 SIGHAN15 测试集中所有的 multi-typo 数据以及相同数量的 negative(不含 typo)数据,组成了 multi-typo 测试集,如表 4 所示。指标采用了 character-level 的 precision、recall 和 F1 分数,即预测对一个 typo 标签算一个正确的预测结果,这样更能体现论文提出的方法对 multi-typo 的提升效果。

表 4
基线模型:
-
SoftMask:提出 soft-masking 策略提升 BERT 的错误检测性能;
-
SpellGCN:将 GCN 与 BERT 结合对字符间的关系进行建模;
-
Tail2Tail:基于 BERT 的模型,但把解码器换成了 CRF;
-
cBERT:论文作者发表于 2021 年的工作,用 CSC 数据进行预训练的 BERT,论文提出的 CRASpell 模型也用 cBERT 进行初始化;
-
PLOME:与 cBERT 相同,但另外融合了从拼音和笔画获取的发音和字形特征;
-
cBERTCopy:将 copy mechanism 应用在 cBERT 上;
-
cBERTNoise:将 Noise Modeling Module 应用在 cBERT 上;
-
cBERTRdrop:基于 cBERT 实现的 Rdrop 方法 [7]。
1. Main Results

表 5
我们可以从表 5 中看到,Noise Modeling Module 和 copy mechanism 都能提升模型性能,使用了 Noise Modeling Module 的 cBERTNoise 和 CRASpell 在 multi-typo 测试集上均取得了优于其他方法的结果(Correction-level 的 Precision 高于 Detection-level,是因为其分母是在 ground-truth 范围内的预测标签的数量,而不是所有预测标签的数量),而另外还使用了 copy mechanism 的 CRASpell 则在两个测试集都取得了最好结果。作者也从 SIGHAN14 的测试集中筛选出了一个 multi-typo 测试集,结果如表 6 所示。

表6
2. Effects of Different Replaced Positions
论文中对比了 Noisy Block 在输入句子中选择插入噪声位置的两种方式:
-
在整个句子中随机选择
-
在 typo 附近选择
结果如表 7 所示,作者还在测试集的数据中插入噪声,测试噪声与 typo 的距离对结果的影响,结果如图 3 所示,两组实验的结果都表明距离 typo 较近的噪声对模型的性能影响较大。

表 7
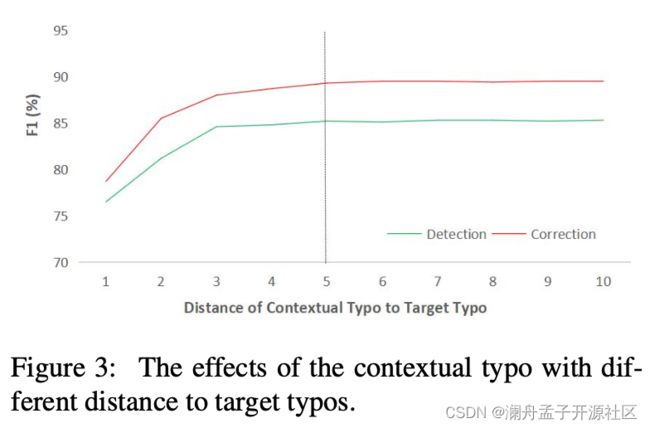
图 3
3. Effects of Different Replaced Characters & the Copy Block
表 8 展示了插入噪声的两种方法:随机从词典中选取和从 confusion set 中选取的结果,可以看出 confusion set 的效果更好,因为从 confusion set 中选取的近音、近形字更接近实际场景下的 typo。Copy Block 被用来减少 BERT 模型对有效字符的修改,从表 9 可以看出其对 BERT 模型性能的提升,cBERT 因为在 CSC 数据上预训练过,所以 Copy Block 对其提升幅度较小。

表 8
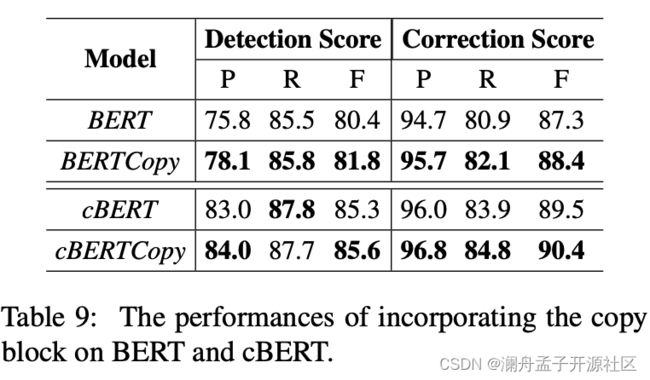
表 9
4. Comparison of Different Methods for Multi-typo Texts
作者为了展示 Noise Modeling Module 对模型的提升,另外实现了两种基于 cBERT 的方法:
- MultiRound:用 cBERT 对输入进行多轮预测,直至不再修改;
- NoiseTrain:用 Noise Block 生成的数据训练 cBERT,插入噪声的位置也参与 loss 计算。
结果如表 10 所示,可以看出 NoiseTrain 提升效果最差,作者猜测是因为插入的噪声使训练数据中 typo 数量增加,且质量偏低,从而导致模型在 single-typo 和 zero-typo 的数据上的效果变差,而 Noise Modeling Module 中插入的噪声只作为上下文,不参与 loss 计算,作者认为这是导致结果差别巨大的关键所在。

表 10
总结
针对之前 CSC 模型的两个限制:Contextual Typo Disturbance 和 Overcorrection,这篇论文提出了一种新的拼写纠错模型。针对第一个问题,论文提出了 Noise Modeling Module,在训练过程中生成含噪声的上下文,该方法有效地提升了模型在 multi-typo 文本上的纠错效果。针对 Overcorrection 问题,论文将 Copy Block 与 CSC 模型结合,训练模型在原字符有效的情况下尽量不进行修改。最终,该方法也是在 SIGHAN15 任务上取得了新的 SOTA。
参考文献
[1] Gu J, Lu Z, Li H, et al. Incorporating Copying Mechanism in Sequence-to-Sequence Learning[C]//Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2016: 1631-1640.
[2] Zeng X, Zeng D, He S, et al. Extracting relational facts by an end-to-end neural model with copy mechanism[C]//Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2018: 506-514.
[3] Wu S H, Liu C L, Lee L H. Chinese Spelling Check Evaluation at SIGHAN Bake-off 2013[C]//SIGHAN@ IJCNLP. 2013: 35-42.
[4] Yu L C, Lee L H, Tseng Y H, et al. Overview of SIGHAN 2014 bake-off for Chinese spelling check[C]//Proceedings of The Third CIPS-SIGHAN Joint Conference on Chinese Language Processing. 2014: 126-132.
[5] Tseng Y H, Lee L H, Chang L P, et al. Introduction to SIGHAN 2015 bake-off for Chinese spelling check[C]//Proceedings of the Eighth SIGHAN Workshop on Chinese Language Processing. 2015: 32-37.
[6] Wang D, Song Y, Li J, et al. A hybrid approach to automatic corpus generation for Chinese spelling check[C]//Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. 2018: 2517-2527.
[7] Wu L, Li J, Wang Y, et al. R-drop: regularized dropout for neural networks[J]. Advances in Neural Information Processing Systems, 2021, 34.