Centos8安装英伟达显卡驱动并通过docker部署深度学习环境
20201107 -
每个人的机器和实际需要的环境都不一样,本文只是提供了在自己实验室centos8上的部署过程,部署过程中,没有什么问题。请谨慎参考本篇文章,以免浪费宝贵时间。
0. 引言
之前的时候,在实验室的深度学习服务器上安装深度学习的环境,部署的文章在《Docker部署容器使用GPU并搭建jupyter环境》,这次选择完全重装。
本次重装,操作系统选取centos8,物理机上还是原来的三块Tesla p100,显卡驱动升级为450,暂时没有必要使用更高版本。本次同样采用docker的部署形式,仅仅需要在底层宿主机安装显卡驱动,而实际深度学习的环境在容器中即可,相对来说比较方便,后续也仅仅升级显卡驱动即可。而且,使用docker部署的形式,就是为了能够让实验室每个组都能实现隔离,防止其他组的占用GPU;而且虽然通过虚拟环境能够在宿主机上实现隔离。
本篇文章已经成功部署了docker的深度学习环境,通过nvidia-docker2实现显卡的隔离,下面来具体展开。
注:本文是在centos8的系统下进行显卡驱动的安装,并没有在本机上进行cuda和cudnn的安装,而是在docker中部署环境,请注意,同时在安装过程中,一定要考虑版本安装是否正确。
1. 环境说明
1.1 硬件环境
这台机器插了三块特斯拉显卡,在安装成功之后,通过命令nvidia-smi可以查看。
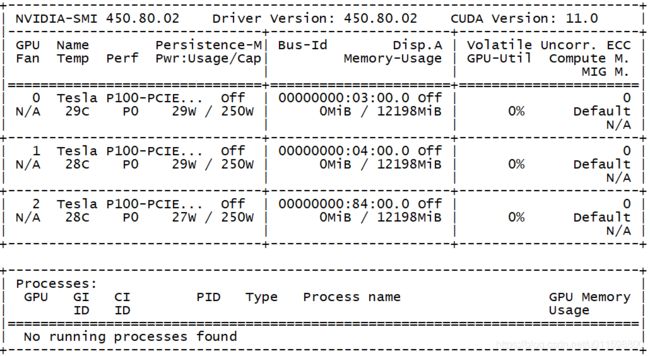
1.2 软件环境
宿主机操作系统选择centos8,选择centos8的原因是后续可能再次升级使用一些新特性,但是不免会带来一些跟centos7不一样的地方,不过慢慢查找原因即可。
这里centos8使用了8.2的镜像,内核版本:
4.18.0-193.28.1.el8
2. 部署过程
2.1 宿主机的一些准备工作
为了保证后续的部署工作更顺利,主要是保证网速,先调整一些简单的内容。
2.1.1 更换国内yum源
- 下载地址
http://mirrors.aliyun.com/repo/Centos-8.repo,具体替换文件的方法请自行搜索。 - 执行命令
yum clean all,yum makecache,实其生效
2.1.2 查看当前驱动
lshw -C display
该命令输出中,查看conigureation可以看到driver=nouveau,那么需要将该驱动禁用,不然无法安装nvidia驱动。
2.1.3 禁用nouveau
参考文章[1],执行以下命令
grub2-editenv - set "$(grub2-editenv - list | grep kernelopts) nouveau.modeset=0"
并重启。文章[12]中在通过禁用后,重建了文件系统,这样可能更安全,本次部署中直接使用了文章[1]的步骤,这里可能导致系统无法启动,请谨慎使用。
2.1.3 下载驱动
打开英伟达下载驱动的地址,按照自己的显卡型号选择。
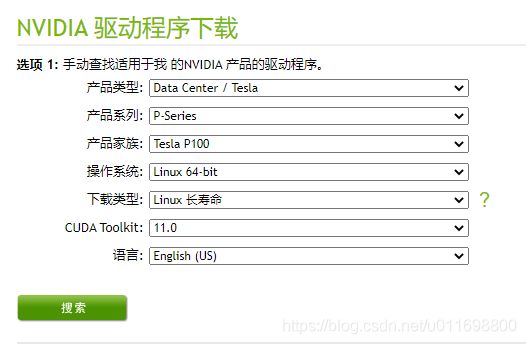
这里直接选择最新的CUDA11.0,但是实际上,后续镜像中并没有使用这么高级的版本,这里只是为了选择高版本的显卡驱动。cuda和cudnn都是向后兼容的。根据自己的需要进行选择,点击搜索后,出现下载页面。
下载完成即可进行安装;执行以下命令,
chmod +x NVIDIA-Linux-x86_64-450.80.02.run
./NVIDIA-Linux-x86_64-450.80.02.run
在安装过程中,如果出现以下界面:
![]()
只需到日志文件中查看,根据提示解决问题即可,这里出现错误是因为缺少elfutils-libelf-devel库,通过命令安装即可。yum install elfutils-libelf-devel,如果没有安装内核文件,安装即可。在是否选择32位库时这里没有选择;安装完成之后,通过命令nvidia-smi可以查看显卡信息。为了确认安装正确,请重启机器,确保重启之后依然可以使用命令nvidia-smi产看显卡信息。
此时已经正确安装了显卡驱动,后面就是部署docker环境
2.2 部署docker
在之前的文章《Docker部署容器使用GPU并搭建jupyter环境》中,提到了直接将宿主机的显卡带进去的方式,但是并不好使,这里还是按照nvidia-docker2的形式来进行部署。
2.2.1 安装docker
参考文章[2],执行命令如下:
yum install -y yum-utils device-mapper-persistent-data lvm2
yum-config-manager --add-repo https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
yum install docker-ce
但是报错:
Problem: package docker-ce-3:19.03.13-3.el7.x86_64 requires containerd.io >= 1.2.2-3, but none of the providers can be installed
在地址下载containerd.io-1.3.7-3.1.el8.x86_64.rpm,该文件依赖于container-selinux,执行以下命令:
yum install container-selinux
rpm -ivh containerd.io-1.3.7-3.1.el8.x86_64.rpm即可
yum install docker-ce
此时docker安装成功,版本位19.03.
2.2.2 安装nvidia-docker
执行命令:
curl -s -L https://nvidia.github.io/nvidia-docker/centos7/x86_64/nvidia-docker.repo | sudo tee /etc/yum.repos.d/nvidia-docker.repo
检查相关版本:
yum search --showduplicates nvidia-docker
选择版本2.5.0
yum install nvidia-docker2-2.5.0-1.noarch
注意此时安装了nvidia-docker之后,会覆盖原来的docker的配置,记得把原来的docker镜像源修改回来,可以参考文章[4].
2.2.3 测试nvidia-docker
执行命令
docker run --rm --gpus all nvidia/cuda:9.0-cudnn7-runtime-centos7 nvidia-smi
可以显示显卡信息,此时安装完成。当然也可以选择其他版本的cuda和cudnn。前面已经提到,通过docker部署的方式,只需要在宿主机安装显卡驱动,并不需要安装cuda等,只需要使用相应的镜像即可,镜像版本可以在dockerhub上搜索。只要版本能够兼容即可,具体版本信息可以在文章[3]中查询,如下图所示:

2.3 制作镜像
关于docker的命令使用请自行搜索相关文章,包括如何制作镜像,如何让服务持续运行等。
2.3.1 DNS解析失败
因为本次的宿主机系统是centos8,docker的镜像启动之后,并不能解析DNS,在查找了相关网页[5]之后,可以使用以下命令:
firewall-cmd --permanent --zone=trusted --add-interface=docker0
firewall-cmd --reload
如果出现了错误No module named 'six'),参考文章[6][7],执行以下命令:
cp /usr/local/lib/python3.6/site-packages/six.py /usr/lib/python3.6/site-packages/
这种方法可以解决这个错误,本质上是python的库安装过程中出现的一些问题;解决上述问题之后,镜像就可以解析dns了。
2.3.2 直接使用tensorflow官方镜像
参考文章[8],在文章最后的支持GPU的部分,使用镜像tensorflow/tensorflow:latest-gpu,启动镜像时的命令如下:
docker run --gpus all -it --rm tensorflow/tensorflow:latest-gpu
同时官方还提供了一个带有jupyter的镜像tensorflow/tensorflow:latest-gpu-jupyter,使用时注意启用GPU即可。
进入之后,通过python的命令可以查看是否支持gpu.
import tensorflow as tf
tf.test.is_gpu_available()
返回True,或者tf.config.experimental.list_physical_devices('GPU'),列出可用的GPU。
2.3.3 自己制作镜像 - cuda和cudnn版本问题
使用官方的镜像比较方便,当时还是希望能够自己制作镜像,这样使用起来更灵活。
一开始是为了测试镜像,所以直接进入镜像中逐步执行命令来查看。
docker run -it --rm --gpus all nvidia/cuda:11.0-cudnn8-runtime-centos7 bash
因为docker源使用的是阿里的,所以镜像中的yum源也是阿里的,速度很快,不用修改yum源,然后按照以下命令来安装tensorflow。
yum install python3
pip3 install --upgrade pip3 -i https://pypi.douban.com/simple/
pip3 install tensorflow -i https://pypi.douban.com/simple/
在选择镜像的cuda和cudnn的版本的时候,最开始直接选择了cuda11.0和cudnn8:11.0-cudnn8-runtime-centos7,然后安装了tensorflow 2.3.1,单总是提示没有可用GPU,具体报错如下:
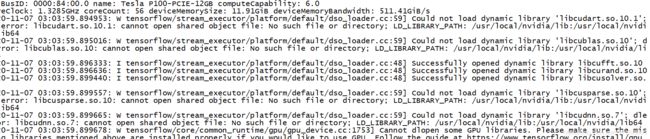
可以看到在这个报错信息是说,找不到cuda的库libcudart.so.10.1,也就是说,这里库的版本还是不匹配。在tensorflow的官网[9]中,提供了各种版本的信息。
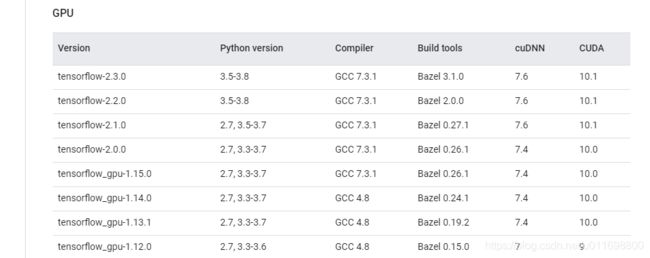
一开始我以为这里是tensorflow最低要求,但是从实际情况上来看,并不是。可能如果要使用最新版的cuda和cudnn可能需要自己通过源码来构建tensorflow了,但是这里还是选择低版本,比较方便。
在文章撰写过程中,pip3默认安装的tensorflow版本是2.3.1,那么按照依赖,选择docekr的镜像为nvidia/cuda:10.1-cudnn7-runtime-centos7
2.3.4 制作tensorflow和keras镜像
因为因为这里是为了给实验室各个小组分配镜像,因为每个人的需求可能都不一样,这里索性将镜像当作虚拟机来使用,直接将ssh端口开放给他们,然后让他们自己选择来安装,其实最好的方法,就是分配一个jupyter,但是这样就不太方便。这里还是自己在nvidia的原版镜像上,直接安装python3、tensorflow和keras。
dockerfile如下:
FROM nvidia/cuda:10.1-cudnn7-runtime-centos7
MAINTAINER VChao
run yum -y install python3 && \
pip3 install --upgrade pip -i https://pypi.douban.com/simple/ && \
ln -snf /usr/share/zoneinfo/$TZ /etc/localtime && \
echo $TZ > /etc/timezone && \
pip3 install tensorflow keras scikit-learn -i https://pypi.douban.com/simple/
run yum install -y openssh-server && echo 'root:root' | chpasswd && \
ssh-keygen -t rsa -f /etc/ssh/ssh_host_rsa_key -N '' && \
ssh-keygen -t dsa -f /etc/ssh/ssh_host_dsa_key -N '' && \
ssh-keygen -t ecdsa -f /etc/ssh/ssh_host_ecdsa_key -N '' && \
ssh-keygen -t ed25519 -f /etc/ssh/ssh_host_ed25519_key -N '' && \
echo "RSAAuthentication yes" >> /etc/ssh/sshd_config && \
echo "PubkeyAuthentication yes" >> /etc/ssh/sshd_config && \
mkdir /root/work_dir
CMD ["/usr/sbin/sshd","-D"]
其中开启SSH部分参考文章[10]。制作镜像的命令是,在dockerfile的当前路径下执行下列命令:
docker build . -t my_dl:0.1
版本信息可以自己写。
2.4 启动镜像
在前面的内容中,已经说明了启动镜像的方式,这里再具体说明一下;正常情况下,直接执行命令即可:
docker run -it -d --rm --gpus all my_dl:0.1
my_dl:0.1是前面制作的镜像名字;但是可能涉及多个显卡,对于我们实验室的3个小组来说,每个小组一个显卡,那么需要在启动镜像的时候就传递参数进去。
docker run -it -d --rm --runtime=nvidia -e NVIDIA_VISIBLE_DEVICES=1,2 my_dl:0.1
通过传递进去GPU编号,让每个容器只能使用个别显卡或全部显卡。
3 总结
本篇文章介绍了在一台刚安装的centos8系统,在安装显卡驱动之后,通过docker的方式部署深度学习黄静,实现容器内使用keras环境。如果部署过程中出现错误,请考虑是否版本匹配的问题,一般来说,选择适合自己机器版本的库都不会出现什么问题。
参考
[1]how-to-install-the-nvidia-drivers-on-centos-8
[2]linux安装docker
[3]cudnn版本信息
[4]Docker 配置国内阿里云镜像源
[5]Docker containers cannot resolve DNS
[6]firewall-cmd (ModuleNotFoundError: No module named ‘six’)
[7]firewalld修复 ModuleNotFoundError: No module named ‘six’
[8]tensorflow docker
[9]tensorflow版本
[10]docker 通过 Dockerfile 安装centos7 镜像,并完成ssh连接
[11]GPU管理
[12]centos 8 英伟达NVIDIA驱动安装