【论文笔记】A Survey on Vision Transformer
目录
Abstract
Personal understanding
2 FORMULATION OF TRANSFORMER
3 REVISITING TRANSFORMERS FOR NLP
4 VISION TRANSFORMER
4.1 Backbone for Representation Learning
4.1.1 Pure Transformer
4.1.2 Transformer with Convolution
4.1.3 Self-supervised Representation Learning
4.1.4 Discussions
4.2 High/Mid-level Vision
4.2.1 Generic Object Detection
4.2.2 Segmentation
4.2.3 Pose Estimation
4.2.4 OtherTasks
4.2.5 Discussions
4.3 Low-level Vision
4.3.1 Image Generation
4.4 Video Processing
4.4.1 High-level Video Processing
4.4.2 Low-level Video Processing
4.4.3 Discussions
4.5 Multi-Modal Tasks
4.6 Efficient Transformer
4.6.1 Pruning and Decomposition
4.6.2 Knowledge Distillation
4.6.3 Quantization
4.6.4 Compact Architecture Design
5 SELF-ATTENTION FOR COMPUTER VISION
Image Classification
Semantic Segmentation
Object Detection
Other Vision Tasks

论文标题:A Survey on Vision Transformer
论文地址:A Survey on Vision Transformer | IEEE Journals & Magazine | IEEE Xplore
发表时间:2021年8月
Abstract
Transformer 最早应用于自然语言处理领域,是一种主要基于自注意力机制的深度神经网络。由于其强大的表示能力,研究人员正在寻找将Transformer应用于计算机视觉任务的方法。在各种视觉基准测试中,基于Transformers的模型的性能类似于或优于其他类型的网络,例如卷积和循环网络。鉴于其高性能和对视觉特定感应偏置的需求较少,Transformer 越来越受到计算机视觉社区的关注
在本文中,我们通过将它们分类到不同的任务并分析它们的优缺点来回顾这些Vision Transformer模型。我们探索的主要类别包括主干网络、高/中级视觉、低级视觉和视频处理。我们还包括有效的Transformer方法,用于将变压器推入基于实际设备的应用程序中。此外,我们还简要介绍了计算机视觉中的自注意力机制,因为它是 Transformer 的基础组件。在本文的最后,我们讨论了相关挑战,并为Vision Transformer提供了几个进一步的研究方向
Personal understanding
由于基于 Transformer 的视觉模型数量迅速增加,跟上新进展的速度变得越来越困难。因此,迫切需要对现有工程进行调查,并对社区有益。
在本文中,着重于对Vision Transformers的最新进展进行全面概述,并讨论进一步改进的潜在方向。为了便于未来对不同主题的研究,我们将 Transformer 模型按应用场景分类,如表所示。
声明及约定:
声明一:本文并无某种框架的详细过程,仅是目前的流行的 Vision Transformer 的发展趋势、各个节点关键架构以及多种实际用途
约定一:有的给出的是架构,有的给出的是论文,因为原作者并无自命名框架,但是同学们都可以自行检索,csdn还是很强大的

第 2 节讨论了 Transformer 的制定和自注意力机制
第 3 节中,描述了 NLP 中的 Transformer 方法,因为研究经验可能对视觉任务有益
第 4 节是本文的主要部分,总结了主干、高/中级视觉、低级视觉和视频任务的视觉转换器模型,还简要描述了高效的 Transformer 方法
第 5 节中,回顾了 CV 的自注意力机制作为 Vision Transformer 模型的补充
最后一部分,给出结论并讨论几个研究方向和挑战。
下图展示了Vision Transformer的发展时间表——毫无疑问,未来还会有更多的里程碑

2 FORMULATION OF TRANSFORMER
Transformer 首次用于机器神经语言处理(NLP)领域的翻译任务。如图2所示,它由一个编码器模块和一个解码器模块以及几个相同架构的编码器/解码器组成。每个编码器和解码器都由一个自注意层和一个前馈神经网络组成,而每个解码器还包含一个编码器-解码器注意层

自注意力机制:机器翻译的自我注意模块通过估计所有位置的注意分数并根据分数收集相应的嵌入,计算序列中每个位置的响应。区别不同位置,所对应的权重。以此达到翻译不同位置时,使用不同的关注权重
分为单头、双头注意力


提示:Transformer的输入端,并非是one-hot编码或者word2vec,而是添加了位置信息的字符级编码
3 REVISITING TRANSFORMERS FOR NLP
NLP任务中一些具有代表性的模型,如下图
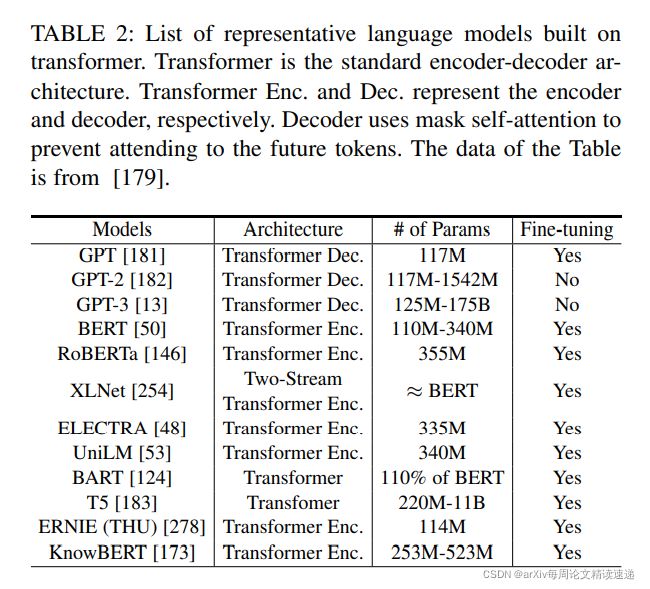
NLP中,神经网络发展历史按先后顺序,简单给大家列出来一下,有想要自己了解的,给大家一个索引:
NNLM(2001)---word2vec(2013)---Glove(2014)---Doc2vec(2014)---Fast Text(2016)---ELMo(2018)---GPT(2018)---Bert(2018)---TLM(2021)
4 VISION TRANSFORMER
它们应用卷积层来提取低级特征,然后将这些特征馈入Vision Transformer
对于Vision Transformer,它们使用标记器将像素分组为少量的视觉标记,每个标记代表图像中的语义概念。这些可视标记直接用于图像分类,Transformer用于对标记之间的关系建模

下图总结了,各种模型的结果
代表性 CNN 和 Vision Transformer 模型的 ImageNet 结果比较

4.1 Backbone for Representation Learning
4.1.1 Pure Transformer
Vision Transformer(ViT)架构如图
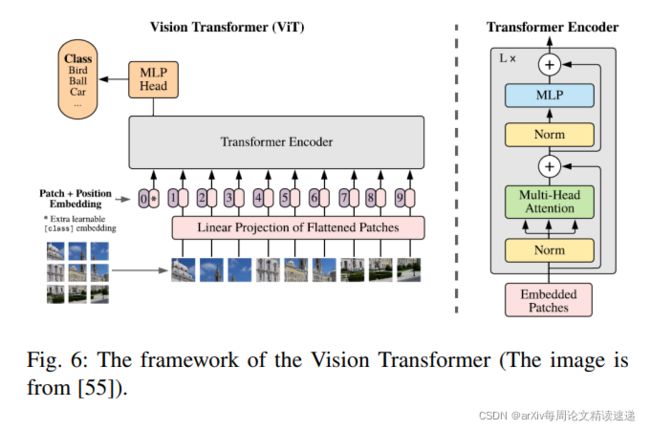
在大多数情况下,ViT是针对大型数据集进行预先训练的,然后针对较小的下游任务进行非本地调整
在 ImageNet 等中型数据集上训练时,ViT 产生了适中的结果,其精度比同等大小的 ResNet 低几个百分点。 由于 Transformer 缺乏 CNN 固有的一些归纳偏差——例如平移等效性和局部性——它们在数据量不足的情况下不能很好地泛化。然而,作者发现在大型数据集(1400 万到 3 亿张图像)上训练模型超过了归纳偏差。当以足够的规模进行预训练时,Transformer 在具有较少数据点的任务上取得了出色的结果。例如,当在 JFT-300M 数据集上进行预训练时,ViT 在多个图像识别基准上接近甚至超过了最先进的性能。 具体来说,它在 ImageNet 上达到了 88.36% 的准确率,在 CIFAR-10 上达到了 99.50%,在 CIFAR-100 上达到了 94.55%,在 19 个任务的 VTAB 套件上达到了 77.16%
ViT 的变体。 遵循 ViT 的范式,已经提出了一系列 ViT 变体来提高视觉任务的性能。 主要方法包括增强局部性、自我注意改进和架构设计
例如:TNT、Twins、CAT、RegionViT、DeepViT、KVT、XCiT等
4.1.2 Transformer with Convolution
尽管 Vision Transformer 已经成功地应用于各种视觉任务,因为它们能够捕获输入中的远程依赖关系,但 Transformer 和现有 CNN 之间的性能仍然存在差距。一个主要原因可能是缺乏提取本地信息的能力。除了上面提到的增强局部性的 ViT 变体之外,将 Transformer 与卷积相结合可能是将局部性引入传统 Transformer 的更直接的方法
通过将 ViT 的嵌入词干替换为标准卷积词干,改变了 ViT 的早期视觉处理,并发现这种变化使 ViT 能够更快地收敛,并且可以使用 Adam 或 SGD,而不会显着降低准确度
经典模型有:CPVT 、CvT、CeiT、LocalViT 、Cmt、LeViT、BoTNet等
4.1.3 Self-supervised Representation Learning
图像的生成式预训练方法已经存在了很长时间,而 iGPT 和 ViT 是将 Transformer 应用于视觉任务的两项开创性工作
iGPT 与 ViT-like 模型的区别主要在于 3 个方面
1)iGPT的输入是通过像素聚类得到的一系列调色板,而 ViT 将图像均匀地划分为多个局部块
2)iGPT的架构是 encoder-decoder 框架,而 ViT 只有transformer encoder
3)iGPT利用自回归自监督损失进行训练,而 ViT 通过监督图像分类任务进行训练
4.1.4 Discussions
视觉转换器的所有组件,包括多头自注意力、多层感知器、快捷连接、层归一化、位置编码和网络拓扑,在视觉识别中都起着关键作用
如上所述,已经提出了许多工作来提高 Vision Transformer 的有效性和效率
从下图中的结果可以看出,将 CNN 和 Transformer 结合使用可以获得更好的性能,表明它们通过局部连接和全局连接相互补充。 对骨干网络的进一步研究可以改善整个视觉社区。至于 Vision Transformer 的自监督表示学习,我们仍然需要努力追求大规模预训练在 NLP 领域的成功


4.2 High/Mid-level Vision
最近,人们越来越关注将变压器用于高/中级计算机视觉任务,例如对象检测 、车道检测、分割和姿势估计,我们将在本节中回顾这些方法
4.2.1 Generic Object Detection
如下图所示。与基于CNN的检测器相比,基于 Transformer 的方法在准确性和运行速度方面都表现出强大的性能。下表显示了前面在 COCO 2012 验证集上提到的不同基于 Transformer 的目标检测器的检测结果
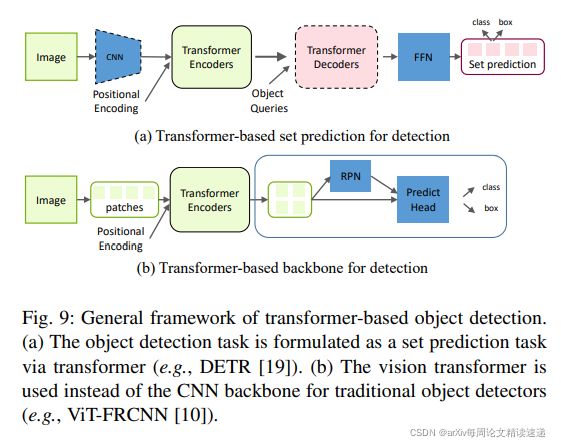

将CNN与Transformer结合在一起的经典模型有:DETR、Deformable DETR、TSP-FCOS、TSP-RCNN等
基于 Transformer 的目标检测的预训练模型:UP-DETR、YOLOS-S、YOLOS-B等
4.2.2 Segmentation
全景分割Transformer:DETR、Max-deeplab等
用于实例分割的Transformer:VisTR、ISTR等
语义分割Transformer:SETR等
用于医学图像分割的Transformer:Cell-DETR等
4.2.3 Pose Estimation
用于手部姿势估计的Transformer:Point-Net、Point-Net++、HOT-Net等
人体姿势估计Transformer:METRO、Tokenpose、Tfpose等
4.2.4 OtherTasks
还有很多不同的高/中级视觉任务已经探索了视觉转换器的使用以获得更好的性能
行人检测:PED等
车道检测:LSTR等
场景图:Graph R-CNN、Texema等
跟踪:TMT、TrTr、TransT等
再次鉴别:ReID、Re-ID等
点云学习:Pct等
4.2.5 Discussions
如前几节所述,Transformer 在包括检测、分割和姿态估计在内的几个高级任务中表现出强大的性能。 在将 Transformer 用于高级任务之前需要解决的关键问题涉及输入嵌入、位置编码和预测损失。 一些方法提出从不同的角度改进自我注意模块,例如可变形注意、自适应聚类和点变换器
尽管如此,探索将Transformer用于高级视觉任务仍处于初步阶段,因此进一步的研究可能会证明是有益的
例如,是否需要在 Transformer 之前使用 CNN 和 PointNet 等特征提取模块以获得更好的性能? 如何像 BERT 和 GPT-3 在 NLP 领域那样使用大规模预训练数据集来充分利用Vision Transformer? 是否可以预训练单个 Transformer 模型并针对不同的下游任务进行微调,只需要几个 epoch 的微调? 如何通过结合特定任务的先验知识来设计更强大的架构?
之前的几项工作已经对上述主题进行了初步讨论,我们希望进行更多的研究工作,以探索更强大的变压器以实现高层次的视觉
4.3 Low-level Vision
很少有工作将Transformer应用于低级视觉领域,例如图像超分辨率和生成。 这些任务通常将图像作为输出(例如,高分辨率或去噪图像),这比输出为标签或框的分类、分割和检测等高级视觉任务更具挑战性
4.3.1 Image Generation
Image Transformer 由两部分组成:用于提取图像表示的编码器和用于生成像素的解码器
由于 Transformer 模型很难直接生成高分辨率图像,因此提出了Taming Transformer。 如下图所示,Taming Transformer 由两部分组成:VQGAN 和 Transformer。VQGAN 是 VQVAE的变体,它使用鉴别器,感知损失来提高视觉质量。通过 VQGAN,图像可以用一系列上下文丰富的离散向量来表示,因此这些向量可以很容易地被 Transformer 模型通过自回归的方式预测。Transformer 模型可以学习用于生成高分辨率图像的远程交互。因此,所提出的 Taming Transformer 在各种图像合成任务上都取得了最先进的结果

除了图像生成,DALL·E提出了用于文本到图像生成的转换器模型,它根据给定的标题合成图像。 整个框架由两个阶段组成。在第一阶段,使用离散 VAE 来学习视觉码本。在第二阶段,文本由 BPE-encode 解码,对应的图像由第一阶段学习的 dVAE 解码。 然后使用自回归转换器来学习编码文本和图像之间的先验。在推理过程中,图像的标记由转换器预测并由学习解码器解码。引入了 CLIP 模型来对生成的样本进行排序。文本到图像生成任务的实验证明了所提出模型的强大能力。 请注意,我们的调查主要关注纯视觉任务,我们不包括下图中的通用框架

4.4 Video Processing
Transformer 在基于序列的任务,尤其是 NLP 任务上的表现出奇的好。 在计算机视觉(特别是视频任务)中,空间和时间维度信息受到青睐,从而导致 Transformer 在许多视频任务中的应用,例如帧合成、动作识别和视频检索
4.4.1 High-level Video Processing
视频动作识别:actortransformer等
视频检索:TCT、SMCA等
视频目标检测:MEGA、PMPNet等
多任务学习:Video multitask transformer network
4.4.2 Low-level Video Processing
帧/视频合成:ConvTransformer等
视频修复:STTN等
4.4.3 Discussions
与图像相比,视频具有额外的维度来编码时间信息。利用空间和时间信息有助于更好地理解视频。 由于 Transformer 的关系建模能力,通过同时挖掘空间和时间信息,视频处理任务得到了改进。 然而,由于视频数据的高度复杂性和大量冗余,如何高效、准确地建模空间和时间关系仍然是一个悬而未决的问题
4.5 Multi-Modal Tasks
由于 Transformer 在基于文本的 NLP 任务中取得的成功,许多研究都热衷于利用其处理多模态任务(例如,视频-文本、图像-文本和音频-文本)的潜力
经典模型有:VideoBERT、VisualBERT、VL-BERT、SpeechBERT、CLIP、Cogview、UniT等
CLIP架构如图:

4.6 Efficient Transformer
尽管 Transformer 模型在各种任务中取得了成功,但它们对内存和计算资源的高要求阻碍了它们在手机等资源有限的设备上的实现
在本节中,我们回顾了为有效实施而进行的压缩和加速Transformer模型的研究。 这包括包括网络修剪、低秩分解、知识蒸馏、网络量化和紧凑架构设计
下表列出了一些用于压缩基于 Transformer 的模型的代表性工作

4.6.1 Pruning and Decomposition
网络瘦身相关论文:
M. Zhu, K. Han, Y. Tang, and Y. Wang. Visual transformer pruning. arXiv preprint arXiv:2104.08500, 2021.
P. Michel, O. Levy, and G. Neubig. Are sixteen heads really better than one? In NeurIPS, pages 14014–14024, 2019.
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin. Attention is all you need. NeurIPS, 30:5998–6008, 2017.
S. Prasanna, A. Rogers, and A. Rumshisky. When bert plays the lottery, all tickets are winning. arXiv preprint arXiv:2005.00561, 2020.
Z. Liu, J. Li, Z. Shen, G. Huang, S. Yan, and C. Zhang. Learning efficient convolutional networks through network slimming. In ICCV, pages 2736–2744, 2017.等
4.6.2 Knowledge Distillation
知识蒸馏旨在通过从大型教师网络转移知识来训练学生网络。与教师网络相比,学生网络的架构通常更薄更浅,更容易部署在资源有限的资源上。神经网络的输出和中间特征也可用于将有效信息从教师传递给学生
相关论文:
G. Hinton, O. Vinyals, and J. Dean. Distilling the knowledge in a neural network. arXiv preprint arXiv:1503.02531, 2015.
J. Ba and R. Caruana. Do deep nets really need to be deep? NeurIPS, 27:2654–2662, 2014.
C. Bucilua, R. Caruana, and A. Niculescu-Mizil. Model compression. ˇ In Proceedings of the 12th ACM SIGKDD international conference on Knowledge discovery and data mining, pages 535–541, 2006.
J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding. In NAACLHLT (1), 2019.
S. Mukherjee and A. H. Awadallah. Xtremedistil: Multi-stage distillation for massive multilingual models. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 2221– 2234, 2020.
4.6.3 Quantization
量化旨在减少表示网络权重或中间特征所需的位数。对通用神经网络的量化方法进行了详细讨论,并实现了与原始网络相当的性能。最近,人们对如何专门量化变压器模型的兴趣越来越大
相关论文:
V. Vanhoucke, A. Senior, and M. Z. Mao. Improving the speed of neural networks on cpus. In Deep Learning and Unsupervised Feature Learning Workshop, NIPS 2011, 2011.
Z. Yang, Y. Wang, K. Han, C. Xu, C. Xu, D. Tao, and C. Xu. Searching for low-bit weights in quantized neural networks. In NeurIPS, 2020.
E. Park and S. Yoo. Profit: A novel training method for sub-4-bit mobilenet models. In ECCV, pages 430–446. Springer, 2020.
J. Fromm, M. Cowan, M. Philipose, L. Ceze, and S. Patel. Riptide: Fast end-to-end binarized neural networks. Proceedings of Machine Learning and Systems, 2:379–389, 2020.
Y. Bai, Y.-X. Wang, and E. Liberty. Proxquant: Quantized neural networks via proximal operators. arXiv preprint arXiv:1810.00861, 2018.
4.6.4 Compact Architecture Design
除了将预定义的 Transformer 模型压缩成更小的模型之外,一些工作还试图直接设计紧凑的模型
相关论文:
Convbert: Improving bert with span-based dynamic convolution 其架构如下图

Z. Wu, Z. Liu, J. Lin, Y. Lin, and S. Han. Lite transformer with longshort range attention. arXiv preprint arXiv:2004.11886, 2020.
D. R. So, C. Liang, and Q. V. Le. The evolved transformer. arXiv preprint arXiv:1901.11117, 2019.
Y. Guo, Y. Zheng, M. Tan, Q. Chen, J. Chen, P. Zhao, and J. Huang. Nat: Neural architecture transformer for accurate and compact architectures. In NeurIPS, pages 737–748, 2019.
Z. Geng, M.-H. Guo, H. Chen, X. Li, K. Wei, and Z. Lin. Is attention better than matrix decomposition? In ICLR, 2020.
上述方法在试图识别变压器模型中的冗余时采用了不同的方法,见下图

剪枝和分解方法通常需要具有冗余的预定义模型。具体来说,剪枝侧重于减少Transformer模型中组件(例如,层、头)的数量,而分解表示具有多个小矩阵的原始矩阵。紧凑型模型也可以直接手动(需要足够的专业知识)或自动(例如通过NAS)设计。为了在资源有限的设备上高效部署,可以通过量化方法进一步用低位来表示所获得的紧凑模型
5 SELF-ATTENTION FOR COMPUTER VISION
前面几节回顾了使用Transformer架构来完成视觉任务的方法。由此可以得出结论,自我注意力机制在Transformer中起着关键作用。自注意模块也可以被认为是CNN架构的一个构建块,它对大的接受域具有低尺度的特性。这个构建块被广泛用于网络之上,以捕获远程交互,并增强视觉任务的高级语义特征
在本节中,我们将深入研究基于计算机视觉挑战性任务的模型。这些任务包括语义分割、实例分割、目标检测、关键点检测和深度估计。本文简要总结了现有的计算机视觉应用
Image Classification
可训练的分类注意包括两个主要流:关于图像区域使用的硬注意和生成非刚性特征图的软注意
经典架构有:AG-CNN、SENet等
Semantic Segmentation
经典架构有:PSANet、OCNet、DANet、CFNet等
Object Detection
经典架构有:GCNet、SENet等
Other Vision Tasks
相关论文:
Y. Chang, Z. Huang, and Q. Shen. The same size dilated attention network for keypoint detection. In International Conference on Artificial Neural Networks, pages 471–483, 2019.
Y. Chen, H. Zhao, Z. Hu, and J. Peng. Attention-based context aggregation network for monocular depth estimation. International Journal of Machine Learning and Cybernetics, pages 1583–1596, 2021.等
写在最后:
大家可以酌情精读自己相关领域的论文,还是很有帮助的