【11月机器学习】回归
要点:线性模型与非线性模型,模型优化的三个角度
需要进一步理解的地方
简单定义
找到一个这样的函数:输入一些自变量得到一个因变量,其中因变量的数据类型都是数值。
应用
- PM2.5浓度预测(输入:历史PM2.5信息、气象资料;输出:未来某个时间点的PM2.5)
- 股票预测(输入:股票涨跌资料、公司并购信息;输出:明天的点数)
- 无人驾驶(输入:无人车感知信息;输出:驾驶操作)
- 商品推荐(输入:使用者信息,购买商品信息;输出:购买某一个商品的概率)
线性回归模型搭建
※线性模型&非线性模型
(94条消息) 线性模型和非线性模型的区别_O zil的博客-CSDN博客_线性模型和非线性模型 https://blog.csdn.net/weixin_42693876/article/details/117554892
https://blog.csdn.net/weixin_42693876/article/details/117554892

Step 1 建立模型
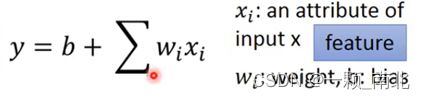
Step 2 模型评估
评估方式:将真实值和预测值带入某个损失函数,估计模型预测误差。
Step 3 梯度下降,更新模型
梯度下降算法用于可微分的函数
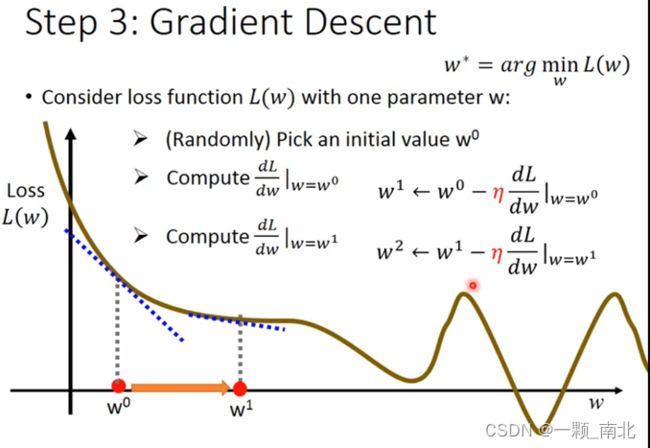
在线性回归中“局部最小值”即为“全局最小值”
回归模型优化
从模型角度(Step1)出发
※分类别训练模型
这个是李宏毅老师给出的宝可梦例子一种优化方法。该种方法适用的情形是:自变量中存在非数值数据类型的变量,不同类别的宝可梦进化后的CP值有差异。比如预测男女身高,性别这一自变量就是一种非数值的数据类型。

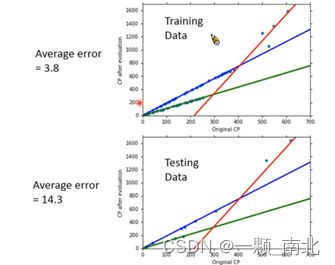
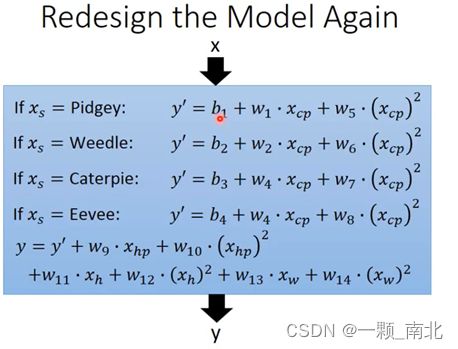
补充样本特征值
正所谓“打了个信息差”,了解到的信息越多越有利。但过度添加信息也带来冗余,如何筛选有效的特征值,又是另一个研究方向。个人用的比较多的是逐步回归和随机森林的特征重要性排序。
从损失函数角度(Step 2)出发
根据问题选择合适的损失函数
(94条消息) 损失函数(loss function)_iiiLISA的博客-CSDN博客_损失函数https://blog.csdn.net/EmilyHoward/article/details/118367495
常用的损失函数
| 名称 | 公式 | |
| 基于距离度量的损失函数 |
||
| 均方误差损失函数 |  |
评价信号质量、回归模型中的经验损失或性能评价 |
| L2损失函数 |  |
回归问题、模式识别、图像处理中最常使用的损失函数 |
| L1损失函数/曼哈顿距离 |  |
对离群点鲁棒性高;在残差为0处不可导;更新梯度始终相同,在较小损失值下梯度也很大,不利于模型收敛,一般的解决办法是在优化算法中使用变化的学习率,在损失接近最小值时降低学习率。 |
| Smooth L1损失函数 |  |
由Girshick R在Fast R-CNN中提出的,主要用在目标检测中防止梯度爆炸 |
| Huber损失函数 |  |
综合两种损失函数,得到连续导数,且对离群点鲁棒性高;但是,它不仅引入了额外的参数,这也增加了训练和调试的工作量。 |
| 基于概率分布度量的损失函数 | 将样本间的相似性转化为随机事件出现的可能性,即通过度量样本的真实分布与它估计的分布之间的距离,判断两者的相似度,一般用于涉及概率分布或预测类别出现的概率的应用问题中,在分类问题中尤为常用。 | |
| KL散度函数/相对熵 |  |
非对称度量方法,常用于度量两个概率分布之间的距离。两个随机分布的相似度越高KL散度越小。比较文本标签或图像的相似性。 |
| 交叉熵 |   |
评估当前训练得到的概率分布与真实分布的差异情况;在正负样本不均衡分类问题中常用;卷积神经网络中最常使用的分类损失函数,它可以有效避免梯度消散。在二分类情况下也叫做对数损失函数。 |
| Softmax |  |
类间距离的优化效果非常好,但类内距离的优化效果比较差,用于多分类和图像标注问题;softmax损失函数学习到的特征不具有足够的区分性,因此它常与对比损失或中心损失组合使用,以增强区分能力;逻辑回归模型在多分类任务上的一种延伸,常作为CNN模型的损失函数;softmax损失函数输出每个类别的预测概率,进一步输入交叉熵损失函数计算。 |
| Focal Loss |  |
解决难易样本不均衡的问题;易分样本虽然损失很低,但是数量太多,对模型的效果提升贡献很小,模型应该重点关注那些难分样本,因此需要把置信度高的损失再降低一些。 |
通常情况下,损失函数的选取应从以下方面考虑:
(1) 选择最能表达数据的主要特征来构建基于距离或基于概率分布度量的特征空间。
(2)选择合理的特征归一化方法,使特征向量转换后仍能保持原来数据的核心内容。
(3)选取合理的损失函数,在实验的基础上,依据损失不断调整模型的参数,使其尽可能实现类别区分。
(4)合理组合不同的损失函数,发挥每个损失函数的优点,使它们能更好地度量样本间的相似性。
(5)将数据的主要特征嵌入损失函数,提升基于特定任务的模型预测精确度。
正则化(Regularization)
正则化的目的是尽可能减小参数值,使得函数更加平滑,模型鲁棒性更强。通常用 施以权重。
施以权重。

从正则化上,往往会考虑的大小以及正则化的方式。
机器学习必知必会:正则化 - 知乎 (zhihu.com)https://zhuanlan.zhihu.com/p/67931198
从梯度下降角度(Step 3)出发
※不同的参数使用不同的学习率
4-回归-演示_哔哩哔哩_bilibilihttps://www.bilibili.com/video/BV1Ht411g7Ef?p=4&vd_source=03ffa2e0d5a752f100d1b1c03f0bc3b1
昨天和今天的主要收获在模型优化上,从建立模型的三个步骤对模型进行优化。
2022/11/16 21:23
一文了解回归模型10个重要知识点回归分析为许多机器学习算法提供了坚实的基础。在这篇文章中,我们将总结 10 个重要的回归问题和5个重要的回归问题的评价指标。 https://mp.weixin.qq.com/s/RItqExC9m1mO9_dO3ZQr1A关于更本质的回归问题↑
https://mp.weixin.qq.com/s/RItqExC9m1mO9_dO3ZQr1A关于更本质的回归问题↑