Robust Double-Encoder Network for RGB-D Panoptic Segmentation
Robust Double-Encoder Network for RGB-D Panoptic Segmentation
RGB-D全景分割的鲁棒双编码器网络
arXiv:2210.02834v1 [cs.CV] 6 Oct 2022
文章地址:https://arxiv.org/abs/2210.02834
代码地址:https://github.com/PRBonn/PS-res-excite
摘要
感知对于在现实环境中行动的机器人来说至关重要,因为自主系统需要看到并理解周围的世界,才能适当地行动。全景分割通过计算像素级语义标签和实例ID来提供对场景的解释。本文利用RGB-D数据对室内场景进行全景分割。我们提出了一种新的编码器-解码器神经网络,它通过两个编码器分别处理RGB和Depth。各个编码器的特征在不同的分辨率下逐步融合,这样RGB特征就可以使用互补的深度信息来增强。我们提出了一种新的融合方法,称为ResidualExcite,它根据特征图的重要性重新评估每个条目。使用我们的双编码器架构,我们可以很好地处理丢失的线索。特别是,同一个模型可以对RGB-D、仅RGB和仅深度输入数据进行训练和推断,而不需要训练专门的模型。我们在公开可用的数据集上评估了我们的方法,并表明我们的方法比其他通用的全景分割方法取得了更好的结果。
1导言
整体场景理解在许多机器人应用中都至关重要。识别物体和获得周围环境的语义解释的能力是真正自治系统的关键功能之一。语义场景感知和理解支持一些机器人任务,如映射[6][21],地点识别[10]和操作[36]。全景分割[22]将语义分割和实例分割统一起来,并将两者结合起来解决。它的目标是为图像的每个像素分配一个语义标签和一个实例ID。图像的内容通常分为两组:事物和东西。物类由可数的对象(如人、车、表)组成,而物类是没有单独实例的无定形空间区域(如天空、街道、地板)。
在本文中,我们使用RGB-D传感器进行目标的全景分割。这些数据在室内环境中尤其有趣,因为深度提供的几何信息可以帮助处理复杂的场景,如杂乱的场景和动态对象。此外,我们还解决了对缺失线索的鲁棒性问题,例如,当RGB或Depth图像缺失时。这是一个实际的问题,因为机器人可以同时配备RGBD和RGB相机,而且有时必须在糟糕的光照条件下运行,在这种条件下RGB数据不可靠。因此,处理RGB-D、RGB和深度数据的单一模型在实际应用中是有帮助的。我们研究了一个编码器-解码器架构如何提供引人注目的结果在室内场景的RGB和深度线索编码器。以前的工作显示了双编码器架构如何有效地处理RGB-D数据[29][37],但它们只针对语义分割。

本文的主要贡献是提出了一种基于双编码器结构的RGB-D全景分割新方法。我们提出了一种新的特征融合策略,称为ResidualExcite,以及一种双编码器结构,对缺失线索具有鲁棒性,允许同时使用RGB-D、RGB-only和Depth-only数据进行训练和推理,而不需要重新训练模型(见图1)。我们表明
(i)与其他最先进的融合模块相比,我们的融合机制表现更好,
(ii)我们的架构允许对RGBD、仅RGB和仅深度数据进行训练和推断,而不需要为每个模态建立专门的模型。
为了支持这些主张,我们报告了在ScanNet[4]和HyperSim[33]数据集上的大量实验。为了支持可再现性,本文中使用的代码和数据集分割将在https://github.com/PRBonn/PS-res-excite发布。
2.相关工作
随着深度学习的出现,我们见证了自主机器人提供场景解释能力的巨大进步。Kirillov等[23]将全景分割的任务定义为语义分割和实例分割的结合。这个任务的目标是为每个像素分配一个类标签,并附加分段对象实例。大多数针对图像全景分割的方法都采用自顶向下的方式处理,因为它们依赖于基于边界框的对象提议[16][22]。他们的目标是提取一些候选对象区域[12][18],然后独立地对它们进行评估。这些方法是有效的,但它们可能导致实例预测的重叠段。在这项工作中,我们遵循自底向上的方法[2][9],不依赖边界框,而是直接在像素级别上操作。
到目前为止提到的作品都是使用RGB图像。全景分割在激光雷达数据中也很常见,包括范围图像[26]和点云[11][32]。但在考虑RGB-D数据时,常见的只有语义分割[5][31]和实例分割[7][19],而全景分割目前受到的关注较少。细化RGB-D数据最常见的方法依赖于通过截断符号距离函数[19]或体素网格[14]的3D表示。很少有直接使用RGB-D图像的工作,它们大多只针对[3]的语义分割。在我们的方法中,我们直接在RGB-D帧上进行全景分割,而不是依靠中间表示。
双编码器结构是处理RGB-D帧的2D表示的最成功的方法。它们允许使用单独的编码器分别处理RGB和深度线索,并依赖于特征融合来组合编码器[30]的输出。Gupta等人[13]提出了一种替代直接利用RGB和深度的方法,即对深度进行预处理,对每个像素使用三个通道进行编码,描述水平视差、离地高度和像素表面法线与重力方向之间的角度。然而,所有这些工作的核心思想是,RGB和深度是分开处理的,融合只发生在网络的稍后点,在编码部分(后期融合)之后。然而,Hazirbas等人[15]表明,在不同特征分辨率下的特征融合可以提高性能(早期中期融合)。相反,我们建议在编码器的每一个下采样步骤使用多分辨率融合。
对于数据流的特征,可以采用不同的融合策略。总和[15]和串联[24]是最早的策略,它们有考虑所有特征而不根据它们的有效效用来权衡的局限性。最新努力的方向是挤压和激励模块[37]和门控融合[42],这是两种不同的通道注意机制,旨在增加对更相关的特征的关注。其他工作利用模态之间的相关性,基于信息量最大的特征[38][40]重新校准特征图。在我们的工作中,我们建立在上述的渠道-注意机制之上。我们提出了一种新的融合机制ResidualExcite,它的灵感来自于挤压激励和残差网络[17],目的是在更细粒度的尺度上衡量特征的重要性。
此外,我们利用双编码器结构,使单个模型能够对不同的模式(RGB-D、RGB-only、depth-only)进行训练和推断。过去曾研究过多模态模型,但大多是利用多个“专家模型”,其输出被融合在一个单一的预测中,如Blum等人[1]所做的工作。
3 RGB-D全景分割方法
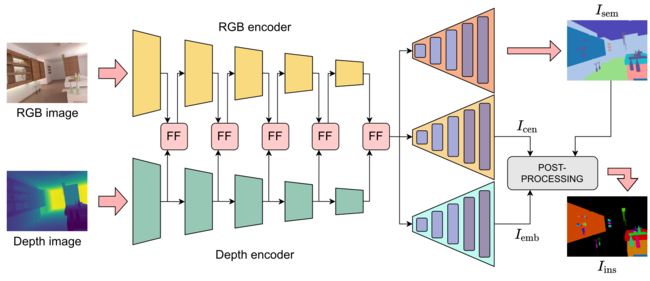
我们的全景分割网络是一个编码器-解码器架构,它运行在RGB- d图像上,并通过两种不同的编码器处理RGB和深度数据。编码器的特征被融合在不同的输出步长,并被发送到三个解码器,以恢复原始图像分辨率的骨干特征。第一个解码器的目标是语义分割。第二个解码器以概率热图的形式预测物体中心的位置。第三个解码器为图像的每个像素预测一个嵌入向量。最后,后处理模块聚合来自最后两个解码器的信息,以自底向上的方式获得实例分割。图2说明了我们提出的网络架构。接下来的部分将解释我们的方法的各个部分。
A. Encoders
我们的全景分割网络基于两个ResNet34编码器[17],分别以RGB图像 I r g b ∈ R 3 × H × W I_{rgb}∈R^{3×H×W} Irgb∈R3×H×W和深度图像 I d e p t h ∈ R 1 × H × W I_{depth}∈R^{1×H×W} Idepth∈R1×H×W作为输入。在这两种编码器中,基本的ResNet块被Non-Bottleneck-1D块[34]所取代,这允许比普通ResNet更轻量级的架构,因为所有3×3卷积都被3×1和1×3卷积序列所取代,中间有一个ReLU,同时提高分割性能[37]。我们将两个编码器在不同的输出步长下的特性融合到RGB编码器中。我们将在第III-B节提供关于融合策略的更多细节。最后一次融合后,得到的特征由自适应金字塔池化模块[43]处理,该模块具有增大网络接受场的作用。从RGB编码器中提取不同输出步长的特征,并通过跳过连接[35]的方式在解码器中使用它们。
B.特征融合
我们在编码器中以不同的输出步长进行特征融合。我们在每一个下采样步骤中融合来自两个编码器的特征,然后将它们发送到RGB编码器。深度编码器只处理深度特征,以避免用两个编码器处理相同的特征。

受Squeeze-and-Excitation模块[20]的启发,我们提出了一种融合特征的新方法。该模块产生一个信道描述符(压缩操作),并给每个信道分配调制权值,最后应用到特征映射(激励)上。我们的目标是获得全局调制权重,而不是通道权重,因为我们相信更细粒度的特征重称重对有效的分割结果至关重要。因此,我们删除了压缩操作,并添加了一个残差连接。这个模块称为ResidualExcite(参见图3),由
X r g b = X r g b + λ ( E ( X r g b ) X r g b + E ( X d e p t h ) X d e p t h ) , (1) X_{rgb} = X_{rgb}+λ(E(X_{rgb}) X_{rgb}+E(X_{depth}) X_{depth}),\tag{1} Xrgb=Xrgb+λ(E(Xrgb)Xrgb+E(Xdepth)Xdepth),(1)
X i ∈ R C d × H d × W d , i ∈ r g b , d e p t h X_i∈ R^{C_d×H_d×W_d},i∈ {rgb,depth} Xi∈RCd×Hd×Wd,i∈rgb,depth是来自各自分支的特征, E ( X i ) ∈ R C d × H d × W d E(X_i)∈ R^{C_d×H_d×W_d} E(Xi)∈RCd×Hd×Wd是激励模块,它是一个由1×1个卷积和一个 S S S形激活函数组成的序列, λ λ λ是一个(未训练的)参数,用于在残差连接上对激励模块进行加权,下标 d d d是指在发生融合的特定输出步幅处特征的维数。 R G B RGB RGB和深度特征都是单独激发的(意味着激发和元素相乘),然后求和,以便在另一个线索缺失的情况下可以分别使用它们。最后,残差连接再次添加 X r g b X_{rgb} Xrgb。
C .解码器
解码器由三个类似swiftnet的模块[28]组成,其中我们加入了Non-Bottleneck-1D模块,我们在第一个模块中将特征通道扩展到512,然后随着分辨率的增加减少。最后,两个基于最近邻卷积和深度卷积的上采样模块(比转置卷积[37]的计算成本更低)恢复原始分辨率。我们的模型由三种解码器组成,分别用于语义分割、中心预测和嵌入预测。
语义分割。语义分割译码器的输出深度等于语义类C的个数, I s e m ∈ R C × H × W I_{sem}∈R^{C×H×W} Isem∈RC×H×W,并具有softmax激活函数。用常用的交叉熵损失 L s e m L_{sem} Lsem训练,实现单热编码多标签分类。
中心预测。中心预测译码器的输出深度为 1 1 1, I c e n ∈ R 1 × H × W I_{cen}∈R^{1×H×W} Icen∈R1×H×W,并有一个sigmoid激活函数来预测作为中心的像素概率。它优化为二进制焦损耗[27]:
L c e n = { − α ( 1 − y ^ ) τ l o g ( y ^ ) , i f y = 1 , − ( 1 − α ) y ^ τ l o g ( 1 − y ^ ) , o t h e r w i s e , (2) L_{cen}=\left\{ \begin{matrix} −α (1 − \hat y)^τ log(\hat y) , if y = 1, \\ −(1 − α) \hat y^τ log(1 − \hat y) , otherwise,\tag{2} \end{matrix} \right. Lcen={−α(1−y^)τlog(y^),ify=1,−(1−α)y^τlog(1−y^),otherwise,(2)
其中 α α α和 τ τ τ是设计参数,在所有实验中分别固定为0.1和2
嵌入的预测。该网络的第三个解码器对图像中的每个像素预测 D e m b D_{emb} Demb维嵌入向量 I e m b ∈ R D e m b × H × W I_{emb}∈R^{D_{emb}×H×W} Iemb∈RDemb×H×W,并采用复合铰链损耗进行优化。第一个项 L a t t L_{att} Latt吸引属于同一实例的像素的嵌入向量,第二个项 L r e p L_{rep} Lrep排斥属于不同实例的像素的嵌入向量,第三个项 L r e g L_{reg} Lreg是一个正则化的项,避免了爆炸性的条目:
L e m b = β 1 L a t t + β 2 L r e p + β 3 L r e g , L a t t = 1 K ∑ k = 1 K 1 P k ∑ p = 1 P k [ ∣ ∣ e ^ k − e ^ p ∣ ∣ − δ a ] + L r e p = 1 K ( K − 1 ) ∑ k 1 = 1 K ∑ k 1 ≠ k 2 k 2 = 1 K − 1 [ δ r − ∣ ∣ e ^ k 1 − e ^ k 2 ∣ ∣ ] + , L r e p = 1 K ∑ k = 1 K ∣ ∣ e ^ k ∣ ∣ , \begin{align*} L_{emb}& = β_1 L_{att} + β_2 L_{rep} + β_3 L_{reg}, \tag{3}\\ L_{att} &= {1\over K} \sum^K_{k=1} {1\over P_k} \sum^{P_k}_{p=1}[||\hat e_k-\hat e_p||-δ_a]^+ \tag{4} \\ L_{rep} &= {1\over K(K − 1)} \sum ^K_{k_1=1} \sum ^{K−1}_{k1 \ne k2k_2=1 } [δ_r −|| \hat e_{k_1} − \hat e_{k_2}||]^+,\tag{5}\\ L_{rep}&={1\over K}\sum ^K_{k=1}||\hat e_k||,\tag{6} \end{align*} LembLattLrepLrep=β1Latt+β2Lrep+β3Lreg,=K1k=1∑KPk1p=1∑Pk[∣∣e^k−e^p∣∣−δa]+=K(K−1)1k1=1∑Kk1=k2k2=1∑K−1[δr−∣∣e^k1−e^k2∣∣]+,=K1k=1∑K∣∣e^k∣∣,(3)(4)(5)(6)
其中: e ^ i ∈ R D e m b \hat e_i∈R^{D_{emb}} e^i∈RDemb为解码器预测的无界对数, K为图像中的实例数, P k P_k Pk为特定实例的点数, [ ⋅ ] + [·]^+ [⋅]+对应 m a x ( 0 , ⋅ ) max(0,·) max(0,⋅), δ a δ_a δa和 δ r δ_r δr分别为吸引和排斥嵌入向量的阈值。为了加快计算速度,我们只在属于一个实例及其对应中心的像素之间计算 L a t t L_{att} Latt,而 L r e p L_{rep} Lrep只在不同实例的中心之间计算。类似地,我们只对中心的向量进行正则化。
我们优化了网络的全景损耗,它是前面定义的术语的加权和:
L p a n = w 1 L s e m + w 2 L c e n + w 3 L e m b . (7) L_{pan} = w_1 L_{sem} + w_2 L_{cen} + w_3 L_{emb}. \tag{7} Lpan=w1Lsem+w2Lcen+w3Lemb.(7)
D后处理
我们的后处理模块根据三个解码器的输出计算实例掩码。由于中心预测解码器通常在期望的中心周围输出污染,我们执行一个非最大抑制操作,以将每个污染减少到单个像素,由语义预测过滤以确保一致性。
特别地,中心首先通过语义预测 I s e m I_{sem} Isem进行过滤,避免中心属于没有实例的东西类。然后,有概率是一个低于阈值 δ c e n δ_{cen} δcen的中心的像素被丢弃。接下来,对于每个斑点,我们提取概率最大的像素为中心。A 污染 B被定义为属于相同语义类且具有相似嵌入向量的像素集合。将 Ω Ω Ω作为 I c e n I_{cen} Icen中被预测为中心的像素集,即 Ω = { p ∣ I c e n ( p ) ≥ δ c e n } Ω = \{p | I_{cen}(p)≥δ_{cen}\} Ω={p∣Icen(p)≥δcen},将污染定义为
B = { p i , p j ∈ Ω ∣ I s e m ( p i ) = c ∧ I s e m ( p j ) = c ∧ ∣ ∣ e ^ p i − e ^ p j ∣ ∣ < δ e m b , i ≠ j } , ( ) B = \{p_i, p_j ∈ Ω | I_{sem}(p_i) = c ∧ I_{sem}(p_j) = c∧ ||\hat e_{p_i }− \hat e_{p_j }||< δ_{emb}, i \ne j\}, \tag{} B={pi,pj∈Ω∣Isem(pi)=c∧Isem(pj)=c∧∣∣e^pi−e^pj∣∣<δemb,i=j},()
其中c是特定的语义类, δ e m b δ_{emb} δemb是聚合嵌入向量的阈值。
在中心提取之后,我们执行聚集聚类操作,根据嵌入空间和语义类中的距离将像素分组到中心。特别地,对于每个中心,我们计算其在嵌入空间中与同一语义类的所有像素的距离。与图像的所有像素之间的相似度矩阵相比,该操作的计算强度较小,并鼓励使用对象中心。最后,如果像素在嵌入空间中的距离低于某个阈值 θ θ θ,我们将其指定为中心。语义分割预测的使用加强了一致性,并避免了将属于同一对象中不同语义类的像素分组。
E、 对缺失输入的鲁棒性
由于我们使用两个单独的编码器处理RGB和深度,因此可以向网络提供部分信息,即没有RGB或深度,并冻结与丢失数据对应的部分。这也可以在训练时完成,使用切换机制,如果没有输入提供给一个分支,则冻结梯度。通过这种方式,冻结的编码器不会影响正向和反向传递,网络可以同时训练完整的RGB-D、仅RGB或仅深度图像。此外,网络能够在不需要重新训练的情况下根据不同的数据进行推断。特征与部分数据融合不是问题,因为剩余的线索仍然可以被激发(或挤压和激发)和处理。
我们使用丢弃数据(RGB或深度)的概率(等于 p d r o p p_{drop} pdrop)来训练完整模型。这意味着网络可以用完整的RGB-D数据训练或不训练。如果数据被丢弃,则没有输入被发送到相应的编码器,我们将其冻结。此外,我们使用自适应采样机制来选择需要丢弃的内容:特别是,如果一条线索被丢弃的次数多于另一条线索,那么它在下一次迭代中被丢弃的概率就会降低。这有助于拥有更平衡的投放机制,并缓解了总是投放相同模态的问题。
4. 实验评价
我们展示了我们的实验,以展示我们的方法的能力,并将其与文献中常见的其他融合方法进行了比较。此外,我们展示了用部分数据训练的模型的性能。
A、 实验设置
数据集和指标。我们在两个数据集上测试了我们的方法:ScanNet[4]和HyperSim[33]。ScanNet由组织在1513个场景中的2.5M真实世界图像组成。HyperSim是一个室内场景的照片级合成数据集,由461个场景中组织的77.4K图像组成。对于这两个数据集,我们不考虑将填充类(墙、地板)用于实例分割。
对于中心预测,我们预处理两个数据集的实例掩码,以提取对象掩码内的中心地面真相。我们认为这比计算相关边界框的中心更有效,该边界框可能位于对象遮罩和分割遮罩之外,例如在孤立的凹面对象的情况下。我们通过语义分割的所有类的全景质量(PQ)[22]和联合平均交集(mIoU)[8]来评估我们的方法。
训练详情和参数。在所有实验中,除非明确指定,否则我们使用初始学习率为0.004的单周期学习率策略[39]。我们执行随机缩放、裁剪和翻转数据增强,并使用AdamW[25]对200个周期进行优化。批量大小设置为32。此外,我们将 D e m b = 32 D_{emb}=32 Demb=32设置为嵌入尺寸 , δ a = 0.1 , δ r = 1 , δ e m b = 0.5 , δ c e n = 0.5 , θ = 0.5 , λ = 1.5 ,δ_a=0.1,δ_r=1,δ_{emb}=0.5,δ_{cen}=0.5,θ=0.5,λ=1.5 ,δa=0.1,δr=1,δemb=0.5,δcen=0.5,θ=0.5,λ=1.5。损失权重设置为 w 1 = 1 , w 2 = 0.1 , w 3 = 10 , β 1 = 1 、 β 2 = 1 , β 3 = 0.001 。 w_1=1,w_2=0.1,w_3=10,β_1=1、β_2=1,β_3=0.001。 w1=1,w2=0.1,w3=10,β1=1、β2=1,β3=0.001。
B、 RGB-D图像的全景分割
第一组实验评估了我们提出的方法的性能,并与文献中常见的其他架构进行了比较。我们的工作基于ESANet[37],这是一种用于图像RGB-D语义分割的双编码器网络。为了将其用作全景分割的基线,我们使用解码器扩展ESANet进行中心预测和嵌入预测。请注意,ESANet利用Squeeze-and-Excitation作为融合策略,但在论文中也报告了通过相加进行融合,简单地总结了来自两个编码器的特征,并将其投影到RGB编码器中。这里,我们使用两种变体。此外,我们使用另一个融合模块作为基线,CBAM[41],它沿着两个独立的维度(通道和空间)推断注意力图。此外,我们还与将RGB-D图像处理为四通道输入信号的单个编码器架构进行了比较。为此,我们调整了Panoptic DeepLab[2]来处理四个通道的图像,并为模型提供了一个4D张量,该张量是RGB和深度图像的级联。


| Method | Dataset | PQ | mIoU |
|---|---|---|---|
| RGB Panoptic DeepLab [2] | ScanNet | 30.11 | 43.12 |
| RGB-D Panoptic DeepLab | ScanNet | 31.43 | 45.45 |
| ESANet [37] with Addition | ScanNet | 35.65 | 51.78 |
| ESANet [37] with SE [20] | ScanNet | 37.09 | 54.01 |
| Ours with CBAM [41] | ScanNet | 39.11 | 58.11 |
| Ours with ResidualExcite | ScanNet | 40.87 | 58.98 |
| RGB Panoptic DeepLab [2] | HyperSim | 26.10 | 40.45 |
| RGB-D Panoptic DeepLab | HyperSim | 28.56 | 41.08 |
| ESANet [37] with Addition | HyperSim | 32.18 | 50.74 |
| ESANet [37] with SE [20] | HyperSim | 35.87 | 54.07 |
| Ours with CBAM [41] | HyperSim | 37.02 | 54.21 |
| Ours with ResidualExcite | HyperSim | 38.67 | 55.14 |
我们将我们的方法与此类方法进行了比较,因为我们专注于图像类数据,而不依赖于三维表示,如截断的符号距离场或点云。结果如表1所示,定性结果如图4和图5所示。与ESANet和我们的方法相比,我们对Panoptic DeepLab的重新实现表现出了较差的性能。我们还报告了Panoptic DeepLab(表中称为RGB Panopic DeepLab)的普通实现中的数字,该实现没有使用深度。有趣的是,RGB Panoptic DeepLab的性能接近RGB-D重新实现的性能,它只需处理四个通道而不是三个通道的输入。这表明,作为附加输入通道的处理深度不会增加太多信息,而通过第二编码器的单独处理对于这样的任务更有效。ResidualExcite模块有助于分割性能,并优于其他融合策略,如CBAM和挤压和激励(ESANet+实例分割)。相加融合显示出较差的性能,这是一个预期的结果,因为它处理所有特征,而不根据其有效性进行权衡。这个实验表明,我们更细粒度的加权机制(它对编码器特征的每个单个条目而不是每个通道都有影响)提高了下游任务的性能。
为了实证验证我们的架构设计,我们将其与ScanNet语义分割基准中的一些最新模型进行了比较[15][40]。我们使用我们的完整模型及其特定于任务的约简,其中用于中心和嵌入预测的解码器被切掉,以便仅进行语义分割。表II显示,即使我们的完整模型性能较弱,我们的任务特定模型也优于基线。请注意,基准测试中较高的一些方法依赖于多个帧作为输入,因此不能直接与我们的方法进行比较。
| Method | Dataset | mIoU |
|---|---|---|
| AdapNet++ [40] | ScanNet | 54.61 |
| FuseNet [15] | ScanNet | 56.65 |
| SSMA [40] | ScanNet | 66.13 |
| Ours (full model) | ScanNet | 58.98 |
| Ours (semantic) | ScanNet | 69.78 |
C、 对缺失输入的鲁棒性实验
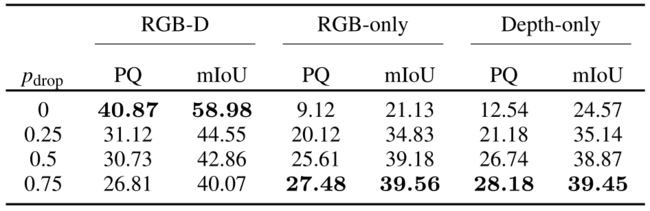
第二组实验支持了我们的观点,即我们的方法可以对部分数据进行训练和推断,从而使网络学会处理缺失的RGB或深度帧。我们测试了不同的pdrop值:0.25、0.5和0.75。这意味着网络将根据指定的概率丢弃RGB帧或深度帧。如果发生掉线,我们根据第IIIE节中提到的自适应采样机制选择掉线。该策略比随机抽样提供了更好的性能,因此本文未对此进行报道。表III显示了RGB-D、仅RGB和仅深度数据的推断性能。当对完整RGB-D帧进行推断时,所有模型产生的分割结果都不如不丢弃任何帧的模型(与上面讨论的模型相同)。然而,当对部分数据进行推理时,它的性能会大幅下降,因为网络从未用缺失的线索进行训练。此外,我们注意到,由于网络更多地使用丢失的线索进行训练,因此更频繁地丢弃帧会使模型更好地对部分数据进行推断。相反,当处理部分数据时,pdrop值低会导致性能不佳,因为网络主要是用RGB和深度这两者训练的。用pdrop=0.5训练的模型是在RGB-D、仅RGB和仅深度上获得满意结果的最佳折衷方案,即使没有达到RGB-D模型的性能。定性结果如图6所示。

第IV-C节中描述的所有实验都是以4个批次和0.001的初始学习率进行的。由于缺少输入,训练过程不太稳定,因此需要较小的学习率。我们使用ResidualExcite进行融合;实验仅在ScanNet上进行。
D、 消融研究
在最后一个实验部分,我们提供了烧蚀,以显示融合策略所提供的改进。我们仅在ScanNet数据集上执行所有消融。
首先,我们分析残差激励并研究残差连接的影响。如果没有它,激励模块(ExciteOnly)仍然提供对功能的入口重新称重。实验表明,这已经足以确保相对于其他基线的优异性能,但残差连接提供了进一步的改进,见表IV。此外,在我们的情况下,RGB编码器中的融合比深度编码器中的更有效。
| RGB | D | SE | E | RE | PQ | mIoU |
|---|---|---|---|---|---|---|
| 25.63 | 38.91 | |||||
| 28.89 | 41.01 | |||||
| 35.65 | 51.78 | |||||
| 37.09 | 54.01 | |||||
| 38.73 | 55.57 | |||||
| 38.80 | 56.67 | |||||
| 40.87 | 58.98 |
然后,我们展示了具有加法(RGB+D)、挤压和激励(SE)、仅激励(E)和残差激励(RE)的双编码器网络。我们使用X?以指示哪个分支处理融合特征。
在同一个表中,我们比较了使用单个编码器的全模型缩减的性能。我们在仅RGB和仅深度数据上测试全景分割。结果明显低于双编码器模型。有趣的是,深度只提供比RGB更好的结果。这可能是由于一些场景具有挑战性的闪电条件,并且一些对象在RGB图像中很难识别。这样的信息不会在深度图像中丢失。此外,这表明,当涉及到用于分割的对象识别时,几何线索可能比颜色信息更相关。
5. 结论
在本文中,我们提出了一种基于具有中间特征融合的双编码器结构的RGB-D图像全景分割新方法。我们的方法利用神经网络的内部结构,在使用相同的模型且不需要再训练的情况下,当线索丢失时,能够进行训练和推断。我们在不同的数据集上实施并评估了我们的方法,并与其他现有模型进行了比较,支持了本文中的所有主张。实验表明,我们对特征进行更精细的重新加权对于有效的分割结果至关重要。此外,与完整模型相比,使用部分数据训练的模型在RGB-D分割方面的性能较差,但在对部分数据进行推断时效果更好。
致谢
我们感谢Andres Milioto和Xieyuanli Chen的建设性反馈和有益讨论。
REFERENCES
[1] H. Blum, A. Gawel, R. Siegwart, and C. Lerma. Modular Sensor Fusion for Semantic Segmentation. In Proc. of the IEEE/RSJ Intl. Conf. on Intelligent Robots and Systems (IROS), 2018.
[2] B. Cheng, M.D. Collins, Y . Zhu, T. Liu, T.S. Huang, H. Adam, and L. Chen. Panoptic-DeepLab: A Simple, Strong, and Fast Baseline for Bottom-Up Panoptic Segmentation. In Proc. of the CVF/IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), 2020.
[3] C. Couprie, C. Farabet, L. Najman, and Y . LeCun. Indoor semantic segmentation using depth information. arXiv preprint:1301.3572,2013.
[4] A. Dai, A. Chang, M. Savva, M. Halber, T. Funkhouser, and M. Nießner. ScanNet: Richly-Annotated 3D Reconstructions of Indoor Scenes. In Proc. of the IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), 2017.
[5] A. Dai and M. Niessner. 3DMV: Joint 3D-Multi-View Prediction for 3D Semantic Scene Segmentation. In Proc. of the Europ. Conf. on Computer Vision (ECCV), 2018.
[6] R. Dubé, D. Dugas, E. Stumm, J. Nieto, R. Siegwart, and C. Lerma.SegMatch: Segment Based Place Recognition in 3D Point Clouds. In Proc. of the IEEE Intl. Conf. on Robotics & Automation (ICRA), 2017.
[7] F. Engelmann, M. Bokeloh, A. Fathi, B. Leibe, and M. Niessner. 3DMPA: Multi-Proposal Aggregation for 3D Semantic Instance Segmentation. In Proc. of the IEEE/CVF Conf. on Computer Vision and Pattern Recognition (CVPR), 2020.
[8] M. Everingham, L. V an Gool, C. Williams, J. Winn, and A. Zisserman.The Pascal Visual Object Classes (VOC) Challenge. Intl. Journal of Computer Vision (IJCV), 88(2):303–338, 2010.
[9] N. Gao, Y . Shan, Y . Wang, X. Zhao, Y . Y u, M. Yang, and K. Huang.SSAP: Single-Shot Instance Segmentation With Affinity Pyramid. In Proc. of the IEEE/CVF Intl. Conf. on Computer Vision (ICCV), 2019.
[10] S. Garg, N. Süderhauf, and M. Milford. Don’t look back: Robustifying place categorization for viewpoint and condition-invariant place recognition. In Proc. of the IEEE Intl. Conf. on Robotics & Automation (ICRA), 2018.
[11] S. Gasperini, M.N. Mahani, A. Marcos-Ramiro, N. Navab, and F. Tombari. Panoster: End-To-End Panoptic Segmentation of LiDAR Point Clouds. IEEE Robotics and Automation Letters (RA-L),6(2):3216–3223, 2021.
[12] R. Girshick, J. Donahue, T. Darrell, and J. Malik. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proc. of the IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), 2014.
[13] S. Gupta, R. Girshick, P . Arbeláez, and J. Malik. Learning rich features from RGB-D images for object detection and segmentation. In Proc. of the Europ. Conf. on Computer Vision (ECCV), 2014.
[14] L. Han, T. Zheng, L. Xu, and L. Fang. OccuSeg: Occupancy-Aware 3D Instance Segmentation. In Proc. of the CVF/IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), 2020.
[15] C. Hazirbas, L. Ma, C. Domokos, and D. Cremers. Fusenet: Incorporating depth into semantic segmentation via fusion-based cnn architecture. In Proc. of the Asian Conf. on Computer Vision (ACCV),2016.
[16] K. He, G. Gkioxari, P . Dollár, and R. Girshick. Mask R-CNN. In Proc. of the IEEE Intl. Conf. on Computer Vision (ICCV), 2017.
[17] K. He, X. Zhang, S. Ren, and J. Sun. Deep Residual Learning for Image Recognition. In Proc. of the IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), 2016.
[18] J. Hosang, R. Benenson, P . Dollár, and B. Schiele. What makes for effective detection proposals? IEEE Trans. on Pattern Analalysis and Machine Intelligence (TPAMI), 38(4):814–830, 2015.
[19] J. Hou, A. Dai, and M. Niessner. 3D-SIS: 3D Semantic Instance Segmentation of RGB-D Scans. In Proc. of the IEEE/CVF Conf. on Computer Vision and Pattern Recognition (CVPR), 2019.
[20] J. Hu, L. Shen, and G. Sun. Squeeze-and-Excitation Networks. In Proc. of the IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), 2018.
[21] R. Khanna, M. Möller, J. Pfeifer, F. Liebisch, A. Walter, and R. Siegwart. Beyond point clouds - 3d mapping and field parameter measurements using uavs. In Proc. of the IEEE Conf. on Emerging Technologies Factory Automation (ETF A), 2015.
[22] A. Kirillov, R. Girshick, K. He, and P . Dollar. Panoptic Feature Pyramid Networks. In Proc. of the IEEE/CVF Conf. on Computer Vision and Pattern Recognition (CVPR), 2019.
[23] A. Kirillov, K. He, R. Girshick, C. Rother, and P . Dollár. Panoptic Segmentation. In Proc. of the IEEE/CVF Conf. on Computer Vision and Pattern Recognition (CVPR), 2019.
[24] M. Loghmani, M. Planamente, B. Caputo, and M. Vincze. Recurrent Convolutional Fusion for RGB-D Object Recognition. IEEE Robotics and Automation Letters (RA-L), 4(3):2878–2885, 2019.
[25] I. Loshchilov and F. Hutter. Decoupled weight decay regularization.arXiv preprint:1711.05101, 2017.
[26] A. Milioto, J. Behley, C. McCool, and C. Stachniss. LiDAR Panoptic Segmentation for Autonomous Driving. In Proc. of the IEEE/RSJ Intl. Conf. on Intelligent Robots and Systems (IROS), 2020.
[27] A. Milioto, L. Mandtler, and C. Stachniss. Fast Instance and Semantic Segmentation Exploiting Local Connectivity, Metric Learning, and One-Shot Detection for Robotics. In Proc. of the IEEE Intl. Conf. on Robotics & Automation (ICRA), 2019.
[28] M. Orsic, I. Kreso, P . Bevandic, and S. Segvic. In defense of pretrained imagenet architectures for real-time semantic segmentation of road-driving images. In Proc. of the IEEE/CVF Conf. on Computer Vision and Pattern Recognition (CVPR), 2019.
[29] J. Park, Q. Zhou, and V . Koltun. Colored Point Cloud Registration Revisited. In Proc. of the IEEE Intl. Conf. on Computer Vision (ICCV),2017.
[30] S. Park, K. Hong, and S. Lee. RDFNet: RGB-D Multi-Level Residual Feature Fusion for Indoor Semantic Segmentation. In Proc. of the IEEE Intl. Conf. on Computer Vision (ICCV), 2017.
[31] X. Qi, R. Liao, J. Jia, S. Fidler, and R. Urtasun. 3D Graph Neural Networks for RGBD Semantic Segmentation. In Proc. of the IEEE/CVF Intl. Conf. on Computer Vision (ICCV), 2017.
[32] R. Razani, R. Cheng, E. Li, E. Taghavi, Y . Ren, and L. Bingbing.GP-S3Net: Graph-Based Panoptic Sparse Semantic Segmentation Network. In Proc. of the IEEE/CVF Intl. Conf. on Computer Vision (ICCV), 2021.
[33] M. Roberts, J. Ramapuram, A. Ranjan, A. Kumar, M.A. Bautista,N. Paczan, R. Webb, and J.M. Susskind. Hypersim: A Photorealistic Synthetic Dataset for Holistic Indoor Scene Understanding. In Proc. of the IEEE/CVF Intl. Conf. on Computer Vision (ICCV), 2021.
[34] E. Romera, J.M. Alvarez, L.M. Bergasa, and R. Arroyo. Erfnet: Efficient residual factorized convnet for real-time semantic segmentation.IEEE Trans. on Intelligent Transportation Systems (ITS), 19(1):263–272, 2018.
[35] O. Ronneberger, P . Fischer, and T. Brox. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Medical Image Computing and Computer-Assisted Intervention, volume 9351 of LNCS, pages 234–241. Springer, 2015.
[36] M. Schwarz, A. Milan, A. Periyasamy, and S. Behnke. Rgb-d object detection and semantic segmentation for autonomous manipulation in clutter. Intl. Journal of Robotics Research (IJRR), 37(4-5):437–451,2017.
[37] D. Seichter, M. Köhler, B. Lewandowski, T. Wengefeld, and H. Gross.Efficient RGB-D Semantic Segmentation for Indoor Scene Analysis.In Proc. of the IEEE Intl. Conf. on Robotics & Automation (ICRA),2021.
[38] K. Sirohi, R. Mohan, D. Büscher, W. Burgard, and A. V alada.EfficientLPS: Efficient LiDAR Panoptic Segmentation. IEEE Trans. on Robotics (TRO), 2021.
[39] L.N. Smith and N. Topin. Super-convergence: V ery fast training of neural networks using large learning rates. Artificial Intelligence and Machine Learning for Multi-Domain Operations Applications,11006:369–386, 2019.
[40] A. V alada, R. Mohan, and W. Burgard. Self-supervised model adaptation for multimodal semantic segmentation. Intl. Journal of Computer Vision (IJCV), 128(5):1239–1285, 2019.
[41] S. Woo, J. Park, J.Y . Lee, and I.S. Kweon. Cbam: Convolutional block attention module. In Proc. of the Europ. Conf. on Computer Vision (ECCV), 2018.
[42] J. Xu, R. Zhang, J. Dou, Y . Zhu, J. Sun, and S. Pu. RPVNet: A Deep and Efficient Range-Point-Voxel Fusion Network for LiDAR Point Cloud Segmentation. In Proc. of the IEEE/CVF Intl. Conf. on Computer Vision (ICCV), 2021.
[43] H. Zhao, J. Shi, X. Qi, X. Wang, and J. Jia. Pyramid Scene Parsing Network. In Proc. of the IEEE/CVF Conf. on Computer Vision and Pattern Recognition (CVPR), 2017.