【多目标跟踪论文阅读笔记——JDE(Towards Real-Time Multi-Object Tracking)】
[阅读心得] 多目标跟踪经典论文——JDE
- 写在前面
-
- 1. 摘要
- 2. Introduction
- 3. Joint Learning of Detection and Embedding(JDE)
-
- 3.1 Problem Settings
- 3.2 Architecture Overview
- 3.3 Learning to Detect
- 3.4 Learning Appearance Embeddings
- 3.5 Automatic Loss Balancing
- 3.6 Online Association
- 4. 实验及其结果
-
- 4.1 与SDE模式的算法进行比较
- 4.2 与SOTA算法比较
- 5 结论与分析
-
- 5.1 结论
- 5.2 分析
【论文】https://arxiv.org/pdf/1909.12605.pdf
【代码】https://github.com/Zhongdao/Towards-Realtime-MOT
写在前面
Towards Real-Time Multi-Object Tracking是2019年清华大学发表的多目标跟踪论文,其创新性地将目标检测环节和外观特征信息提取环节两部分融合设计为一个网络,从而极大地提升了多目标跟踪算法的推理速度,达到了接近实时地帧数(near real-time),也为后序MOT的发展(如FairMOT)提供参考。但是笔者认为可能仍然没有完全解决Detection和REID两任务之间的矛盾。
1. 摘要
目前的多目标跟踪(MOT)算法主要遵从“检测后跟踪”的范式。顾名思义,其包含两个阶段:
1)检测模型获得目标的位置信息。
2)外观特征向量提取模型获得向量并用于数据关联。
分别执行这两个阶段会导致严重的效率问题,整个运行时间基本等于两阶段分别执行时间之和。而目前提升MOT实时性的工作主要集中于数据关联阶段,因为现在所说的“real-time MOT”通常指的是“real-time association step”,而并非真实的整个MOT算法的实时性
该论文提出了一种将“目标检测”与“特征向量提取”任务依赖一个共享模型学习的MOT网络设计方式:
1)将特征向量(embedding)提取网络放入单阶段目标检测模型中,从而能够通过一个网络输出这两个任务所需的结果。
2)提出了一种新的,简单且快速的数据关联方法,适用于上述联合网络。
最终经过实验验证,提出的MOT算法速度大幅提升、精度和分离式(SDE)的MOT算法中的SOTA基本持平。
2. Introduction
如今,多目标跟踪算法(MOT)范式主要有三种:
- 分离式:SDE模式,先用Detection网络获得BBox,再将bbox输入REID网络提取特征
- 两阶段式:two-stage模式,先用RPN网络找到目标对应特征图,再将特征图输入REID网络提取特征
上述两种方法本质上都是“两阶段”,只不过主要区别在于输入进REID网络的是图像(re-sampled pixels)还是特征图(re-sampled features) - 联合式:JDE模型,本文新提出,将检测任务和REID任务融合到一个网络中去,即Joint learns the Detectors and Embedding model。
三种范式的结构图如下:
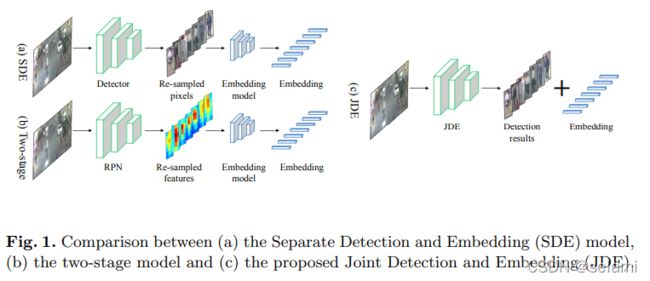
3. Joint Learning of Detection and Embedding(JDE)
3.1 Problem Settings
希望建立一个Joint learning模型,满足如下要求:
- 精准地检测出目标位置
- 提取出的特征向量满足:连续帧之间,同ID的的目标相似度高、不同ID的目标相似度低。其中,相似度可以用欧氏距离或余弦距离来衡量。
Technically, if the two objectives are both satisfied, even a simple association strategy, e.g., the Hungarian algorithm, would produce good tracking results.
最后,如论文作者所说,如果设计的JDE网络能够满足上述两个要求,那么不需要设计复杂的association规则就能够较好地实现跟踪。
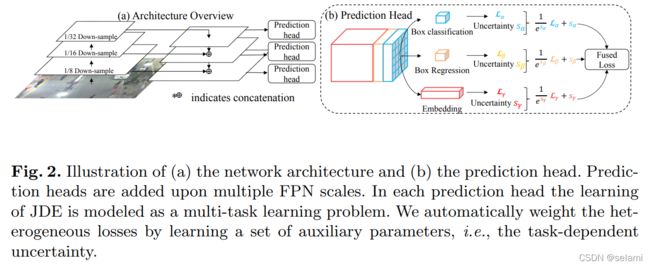
3.2 Architecture Overview
特征提取网络采用Darknet53,后面接特征金字塔结构FPN,输出结果为分别对原图下采样1/8. 1/16. 1/32倍。输出维度为 ( 6 A + D ) ∗ H ∗ W (6A+D) *H*W (6A+D)∗H∗W,其中, A A A表示预设的anchor数, D D D表示外观特征向量的维数。其output主要由三部分构成:
1 ) the box classification results of size 2 A ∗ H ∗ W 2A*H*W 2A∗H∗W
2 ) the box regression coefficients of size 4 A ∗ H ∗ W 4A*H*W 4A∗H∗W
3 ) the dense embedding map of size D ∗ H ∗ W D*H*W D∗H∗W
3.3 Learning to Detect
检测部分的设计主要包括anchor设定、正负例判定、损失函数设计三部分。
- anchors相关设置
anchors数目设置为12个,即每个通道分配3个anchor,anchor的ratio设置为常用值1:3,尺寸根据training dataset重新聚类。 - 正负例判定
I O U > 0.5 IOU > 0.5 IOU>0.5, 则判定为前景
I O U < 0.4 IOU < 0.4 IOU<0.4, 则判定为背景
Our preliminary experiment indicates that these thresholds effectively suppress false alarms, which usually happens under heavy occlusions.
- 损失函数
检测环节的损失函数主要由两部分构成,前景/背景分类(foreground/background classification) 和 位置回归(bounding box regression)。
1)前景/背景分类: L α \mathcal L_\alpha Lα, Cross-Entrophy Loss
2)目标位置回归: L β \mathcal L_\beta Lβ, Smooth-L1 Loss
3.4 Learning Appearance Embeddings
- 损失函数
主要设计了损失函数部分,讨论了Triplet loss, Triplet loss with upper bound 以及 CE loss之间的优劣,最终选择该部分的损失函数为: L γ \mathcal L_\gamma Lγ, Cross-Entrophy Loss
3.5 Automatic Loss Balancing
根据上述各个部分的设计可知,该网络存在3个不同尺度的输出通道、且每个通道输出包括3个任务的信息(foreground/background, bbox regression, appearance embedding)。因此,目前存在一个多任务、多尺度之间相互平衡的问题。按照基本的加权思想可以表示为:
L t o t a l = ∑ i M ∑ j = α , β , γ w j i L j i \mathcal L_{total} = \sum_{i}^M \sum_{j=\alpha,\beta,\gamma} w_j^i L_j^i Ltotal=i∑Mj=α,β,γ∑wjiLji
其中, M M M表示多尺度通道数(number of prediction heads),本网络中为3。 w w w为加权。
那么如何设计这9个权重参数呢?论文主要阐述了2种方法
- 调参:但是搜索空间太大了,很难调出性能很好的参数
- 一种自动学习策略:an automatic learning scheme by using the concept of the task-independent uncertainty.其公式为:
L t o t a l = ∑ i M ∑ j = α , β , γ 1 2 ( 1 e j s i + s j i ) \mathcal L_{total} = \sum_{i}^M \sum_{j=\alpha,\beta,\gamma} \frac{1}{2} (\frac{1}{e_j^{s^i}} + s_j^i) Ltotal=i∑Mj=α,β,γ∑21(ejsi1+sji)
其中 s j i s_j^i sji是一个可学习的参数,与上式中 w j i w_j^i wji的意义类似,表示不同损失函数的权重。
3.6 Online Association
正如3.1中所说,论文作者认为,只要网络的两大部分输出结果足够好,使用简单的Association方法就能获得好的效果。但是本论文仍然提出了一种关联机制,并和SORT中的对应机制进行比较,取得了更好的效果。提出的关联机制主要步骤如下:
- 初始化一个轨迹池(tracklet pool),一个轨迹(tracklet)由其外观向量 e i e_i ei和运动状态 m i = ( x , y , γ , h , x , ˙ y , ˙ γ , ˙ h ) ˙ m_i = (x,y,\gamma,h,x\dot, y\dot, \gamma\dot, h\dot ) mi=(x,y,γ,h,x,˙y,˙γ,˙h)˙
- 对新的一帧,计算这一帧的各个目标和轨迹池中各条轨迹的两两之间的成本矩阵,包括
1)动态成本矩阵 A m A_m Am (motion affinity matrix):马氏距离计算
2)外形特征成本矩阵 A e A_e Ae (appearance affinity matrix):余弦距离计算
将两部分成本矩阵加权相加:
C = λ A e + ( 1 − λ ) A m C = \lambda A_e + (1-\lambda) A_m C=λAe+(1−λ)Am
计算得到最终的成本矩阵,使用匈牙利算法进行匹配,将该帧的目标关联到轨迹池中的轨迹上去。 - 根据第二步,匹配上的轨迹需要更新其 e i , m i e_i, m_i ei,mi:
1) m i m_i mi通过卡尔曼滤波更新
2) e i e_i ei通过滑动平均方法更新: e i t = α e i t − 1 + ( 1 − α ) f i t e_i^t = \alpha e_i^{t-1} + (1-\alpha) f_i^t eit=αeit−1+(1−α)fit ,其中 α = 0.9 \alpha=0.9 α=0.9, f i t f_i^t fit表示该帧目标的外观特征向量 - 如果一个新目标出现超过2帧,则新建一条轨迹到轨迹池。
- 如果一个轨迹超过30帧没更新,则终止这条轨迹
4. 实验及其结果
4.1 与SDE模式的算法进行比较
按照SDE模型的流程,将不同的Detection网络和REID网络进行组合,并将其精度(MOTA、IDF-1)和速度(FPS)与本文提出的JDE算法进行对比,结果如图所示:
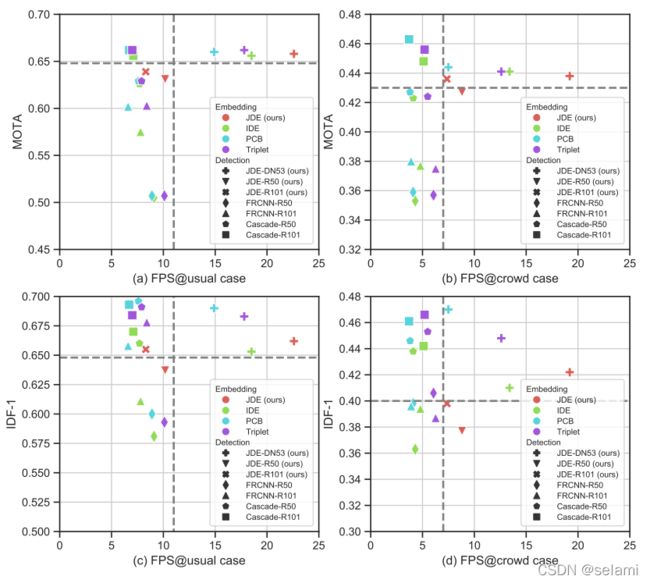
如图,按照作者的说法,可以获得主要三条结论:
1)JDE的速度明显快于其他MOT算法,且精度也基本能够和其他SDE算法持平
2)JDE不需要额外的REID模型获得embeding,也能获得足够好的精度表现
3)JDE在目标密度(density)增大很多的情况下,其推理速度基本不会收到影响,这明显优于其他所有SDE模式的网络组合
4.2 与SOTA算法比较
此外,作者还将JDE算法与当时MOT领域的SOTA算法进行了比较,结果如图所示:
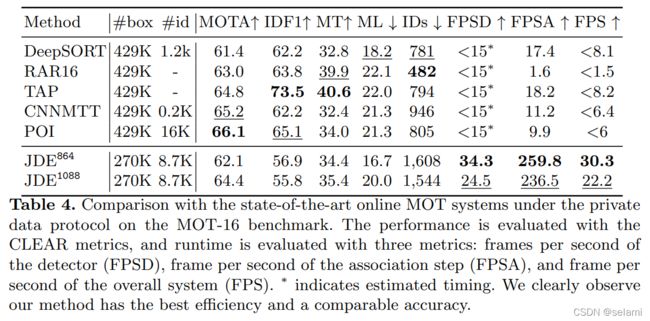
通过分析该图标,作者得到如下结论:
1) 速度上,JDE比SOTA基本上要快2-3倍,如果选取分辨率稍低的视频流,速度甚至可以达到30.3FPS
2) 精度上,JDE比SOTA(POI)低2.6%,仍有明显的差距
3) JDE的ID switch明显多余目前方法,一开始论文作者认为是这种joint learning的网络本身弱于seperate learning网络导致的,后面单独为JDE使用的REID模型,但是点数依然涨不上去。最终,作者认为这是由于在大量密集行人场景下,目标严重相互遮挡导致的,IDs主要发生在轨迹的中途。后续需要改进(存疑)
5 结论与分析
5.1 结论
- 提出了JDE,一种将detection和appearance feature共享于同一模型的范式
- JDE算法极大的减少了推理时间,接近实时性效果,精度尚可
- 提出一种新的关联机制
5.2 分析
- 目前JDE范式的主要优势在于速度够快但是精度还是不够好,达不到SOTA
- 精度低的主要原因是detection效果不好,后续fairmot发现anchor机制在这种任务中效果不好,推荐使用anchor-free机制的detection模型
- detection和reid两个任务共享一个网络,是否本质上存在冲突?detection更看重高维信息而reid更看重低位信息?用一个网络学习是否一定会导致性能减弱?multi-task问题?
- backbone用的还是Darknet53,近年来detection领域提出了很多新模块提点明显,可否考虑使用?对REID是否会起反作用?