机器学习从入门到再入门之关于SVM的再理解
先说一些废话。很早之前就想开一个类似于技术博客的登西啦,奈何觉得自己没有技术值得记录,再加上时常泛滥的拖延症,迟迟没有正儿八经搞一个博客。最近觉得写博客或许能帮助自己梳理知识,记录自己学习的轨迹;再加上是一个间歇性狂热的AI追捧者,所以还是决定开一个博客,记录一下自己近期学习的知识、AI技术或者其他一些感兴趣的登西。很有可能是不定时更新,但我会努力督促自己及时更新的。(大喊:皮紧起来!支棱起来!)氮素,作为一只小菜鸟,肯定有很多不足和错误,也希望大家温和地给我指出来,我会认真听取大家建议滴~~~
下面就开始啦~~~
机器学习里的支持向量机是面试常考问题,之前参加面试也被问倒!!!过好几次,虽然本科学过,但学得不够深入,基础不够扎实,所以现在研一又继续选了这门课。前几天正好结合老师上课讲的内容和其他大佬们总结的内容对自己之前不明白的几个地方梳理了一下(主要是偏个人理解,关于公式的推导我这里就不涉及了),所以小菜鱼的第一篇博客就诞生啦。
一、发展背景
1963年,提出了原始的SVM;
1992年,引入核函数解决了非线性分类问题;
1995年,提出了软间隔最大化解决了噪声问题(误分类问题);
2001年,提出了SVC方式完成非监督学习;
2005年,提出并对比多种多分类的SVM方法。
二、思想
在保证分类正确的同时,让离超平面最近的点(这些点也就是支持向量)到超平面的间隔最大。其实也就是说,使超平面和支持向量之间的间隔最大,这样能最好地保证分类准确性。
三、与感知机模型的比较
我们都知道感知机是一种年岁已高(没有说它不好的意思)的二分类线性分类模型了,是神经网络和支持向量机的基础。它的思想是尝试找到一个能将数据集分开的超平面。一个需要注意的地方,它的损失函数只针对误分类点!!!它的优化目标是使得误分类点离超平面的距离最小,而支持向量的优化目标是使支持向量与超平面的距离最大。(这个“最大”、“最小”的概念要细细理解一下,其实也不难理解的)
四、SVM的优化目标
本科学svm的时候,看过许多对svm的优化目标的不同解释,很懵,但由于期末不涉及,所以懵着懵着就结束了这门课,结课之后没有深究,因此到本科毕业都继续懵。懵的原因主要是,它的目标函数一会儿涉及到“![]() ”,一会儿又是“
”,一会儿又是“ ”这样的形式。最近不懵了,其实他们在解释过程中“默默地”引入了经验风险和结构风险这两个先验知识。
”这样的形式。最近不懵了,其实他们在解释过程中“默默地”引入了经验风险和结构风险这两个先验知识。
1、经验风险:经验风险是对训练集中的所有样本点损失函数的平均最小化。只考虑经验风险的话,会出现过拟合的现象,比如神经网络。
而支持向量机中用到的损失函数便是“ ![]() ”这样的形式,其中
”这样的形式,其中![]() 就叫合页损失函数,当样本点
就叫合页损失函数,当样本点 被正确分类且
被正确分类且![]() 时,损失为0。
时,损失为0。
如果想知道模型 对训练样本中所有的样本的预测能力,只需所有的样本点都求一次损失然后进行累加,即:
对训练样本中所有的样本的预测能力,只需所有的样本点都求一次损失然后进行累加,即: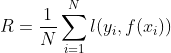 ,其中
,其中![]() 是合页损失函数,
是合页损失函数, 便是经验风险。经验风险越小说明模型对训练集的拟合程度越好。所谓的经验风险最小化便是让这个式子最小化。
便是经验风险。经验风险越小说明模型对训练集的拟合程度越好。所谓的经验风险最小化便是让这个式子最小化。
2、结构风险:在经验风险函数后面加一个正则化项(惩罚项)便是结构风险了(因为我们需要在训练误差和模型复杂度之间寻求平衡,防止过拟合,减小泛化误差,所以引入了正则化项),这时候优化目标就变为:![L=min\sum_{i}^{N}\left [ 1-y_{i}(wx_{i}+b)) \right ]_{+}+\lambda \left \| W \right \|^{2}](http://img.e-com-net.com/image/info8/1130018597814a9787101826ef519dd1.gif) 。
。
这个结构风险和svm原始优化目标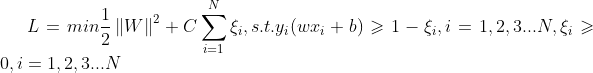 是等价的。
是等价的。
(该证明可参考李航的统计学习方法P131)
【补充:查了一下资料得知,统计学习理论中表明,学习机器的实际风险是由训练样本的经验风险和置信范围两部分组成。而之前说过SVM的思想是求解能够正确划分训练数据集并且几何间隔最大的分离超平面,原因是分类超平面可以满足经验风险最小,最大间隔满足置信范围最小,这样才能取得较小的实际风险,从而实现结构风险最优,折衷考虑了经验风险和置信范围,具有较好的推广能力。所以,支持向量机是采用结构风险最小化准则设计的分类器。】
(关于经验风险、结构风险、置信区间之间的关系,可移步(12条消息) 机器学习之路(七)支持向量机_asd2479745295的博客-CSDN博客)
五、为什么叫支持向量机
我们知道引入拉格朗日乘子后 的计算表达式为
的计算表达式为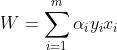 ,由KKT条件可知,
,由KKT条件可知,![]() 时,
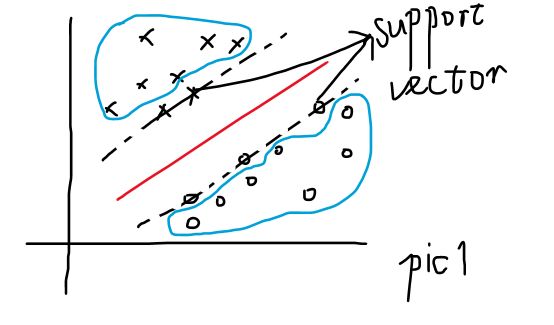
时,![]() ,所以对于那些正确分类的样本(即下图pic1中蓝色圈内的样本点,他们位于支持向量的上下两侧),他们对于的权值贡献
,所以对于那些正确分类的样本(即下图pic1中蓝色圈内的样本点,他们位于支持向量的上下两侧),他们对于的权值贡献 为0,也就是说非支持向量样本不影响的值,因此的值只和支持向量有关。支持向量机由此得名。
为0,也就是说非支持向量样本不影响的值,因此的值只和支持向量有关。支持向量机由此得名。
六、核函数
1、作用:核函数的作用大家都耳熟能详,就是将样本"映射"到高维空间(这个映射并不是真的映射,下面第二点会讲),使得在低维特征空间不可分的样本在这个高维的特征空间线性可分。
2、原理:那么,它的原理是什么呢?可以看到在支持向量机优化函数和预测函数中都有“![]() ”这样的形式,代表的是两个向量内积。如果用
”这样的形式,代表的是两个向量内积。如果用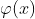 表示从低维映射到高维空间的映射,则
表示从低维映射到高维空间的映射,则 经映射后可表示为
经映射后可表示为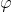
![]() ,于是代入优化函数和预测函数公式便为
,于是代入优化函数和预测函数公式便为![]() ,但是如果在高维空间再进行这样的内积计算就太复杂了,因此核函数就诞生了。定义核函数
,但是如果在高维空间再进行这样的内积计算就太复杂了,因此核函数就诞生了。定义核函数![]() ,其含义是和
,其含义是和 在特征空间的内积等于他们原始样本空间中通过
在特征空间的内积等于他们原始样本空间中通过![]() 函数计算的结果。也就是说,其实核函数是用来计算映射到高维空间之后的内积的一种简便方法。所以才说核函数是在低维上计算,但分类效果表现在高维。
函数计算的结果。也就是说,其实核函数是用来计算映射到高维空间之后的内积的一种简便方法。所以才说核函数是在低维上计算,但分类效果表现在高维。
我之前一直以为核函数是将特征映射到高维空间的映射函数,到这里才知道它的本质实际上是一种可以直接在低维空间对高维空间中的向量做内积的简便运算方式。
关于我对支持向量机的部分理解就到这儿啦,至于其他概念,比如函数间隔、几何间隔、对偶问题、以及为什么这些公式里这么多数字1······在西瓜书上都有详细的解释,我就不赘述啦。所以整体看来,这篇文章没啥技术含量,主要还是偏理解性的内容多一些~
十分欢迎建议和意见!!!!!
不接受恶意抬杠,杠就是你对!
下个文章见~~~
------------------------2022.1.9更新------------------------
七、半监督支持向量机
1、半监督学习:让学习器自动利用未标记样本进行自我学习,提升学习性能。可以理解为在有监督的SVM分类算法中加入无标记样本来实现半监督分类。
2、算法思想:迭代的寻找优化目标
其中![]() 对应有标记样本,
对应有标记样本,![]() 对应未标记样本的近似解,
对应未标记样本的近似解,![]() 、
、![]() 是平衡标记数据和未标记数据对结果影响的参数。(为让有标记样本在求解超平面时占比更大因为预测的伪标记很大程度上与真实值有偏差,在初始化的时候。
是平衡标记数据和未标记数据对结果影响的参数。(为让有标记样本在求解超平面时占比更大因为预测的伪标记很大程度上与真实值有偏差,在初始化的时候。![]() 应设置比
应设置比![]() 小的值。
小的值。
3、算法步骤:利用有标记样本学习一个“母版”SVM——使用该母版预测未标记数据,预测结果作为伪标记——代入L中求解超平面和松弛向量——找出两个标记指派为异类(标签相乘为负数)且很可能错误的未标记样本(松弛变量之和大于2),交换他们的标记——重新基于优化目标L求解分隔平面和松弛向量——逐渐增大![]() ,直到
,直到![]() ,停止算法。
,停止算法。
4、一些改进:由于要对每一对未标记样本进行调整,产生的计算量非常大。因此也有一些针对该问题优化的研究。