DolphinScheduler3.1简介、部署、功能介绍以及架构设计
1.DolphinScheduler简介
1-1.关于DolphinScheduler
Apache DolphinScheduler 是一个分布式易扩展的可视化DAG工作流任务调度开源系统。适用于企业级场景,提供了一个可视化操作任务、工作流和全生命周期数据处理过程的解决方案。
Apache DolphinScheduler 旨在解决复杂的大数据任务依赖关系,并为应用程序提供数据和各种 OPS 编排中的关系。 解决数据研发ETL依赖错综复杂,无法监控任务健康状态的问题。 DolphinScheduler 以 DAG(Directed Acyclic Graph,DAG)流式方式组装任务,可以及时监控任务的执行状态,支持重试、指定节点恢复失败、暂停、恢复、终止任务等操作。
1-2.DolphinScheduler特性
- 简单易用
- 可视化DAG:用户友好的通过拖拽定义工作流、运行控制工具
- 模块化操作:模块化有助于轻松定制和维护
- 使用场景丰富
- 支持多种任务类型:支持shell、MR、Spark、SQL等10多种任务类型,支持跨语言,易于扩展
- 丰富的工作流操作:工作流支持定时、暂停、恢复和停止,便于维护和控制全局和本地参数
- 高可用
- 高可用性:去中心化射击,确保稳定性。原生HA任务列表支持,提供过载容错能力。DolphinScheduler能提供高度稳健的环境
- 高扩展
- 高扩展性:支持多租户和在线资源管理。支持每天10万个数据任务的稳定运行
1-3.DolphinScheduler环境配置建议
1-3-1.Linux操作系统版本要求
| 操作系统 | 版本 |
|---|---|
| Red Hat Enterprise Linux | 7.0 及以上 |
| CentOS | 7.0 及以上 |
| Oracle Enterprise Linux | 7.0 及以上 |
| Ubuntu LTS | 16.04 及以上 |
注意: 以上 Linux 操作系统可运行在物理服务器以及 VMware、KVM、XEN 主流虚拟化环境上
1-3-2.服务器配置建议
DolphinScheduler 支持运行在 Intel x86-64 架构的 64 位通用硬件服务器平台。对生产环境的服务器硬件配置有以下建议:
对于生产环境配置要求建议:
| CPU | 内存 | 硬盘类型 | 网络 | 实例数量 |
|---|---|---|---|---|
| 4核+ | 8 GB+ | SAS | 千兆网卡 | 3 |
注意:
- 以上建议配置为部署 DolphinScheduler 的最低配置,生产环境强烈推荐使用更高的配置
- 硬盘大小配置建议 50GB+ ,系统盘和数据盘分开
1-3-3.网络要求
DolphinScheduler正常运行提供如下的网络端口配置:
| 组件 | 默认端口 | 说明 |
|---|---|---|
| MasterServer | 5678 | 非通信端口,只需本机端口不冲突即可 |
| WorkerServer | 1234 | 非通信端口,只需本机端口不冲突即可 |
| ApiApplicationServer | 12345 | 提供后端通信端口 |
注意:
- MasterServer 和 WorkerServer 不需要开启网络间通信,只需本机端口不冲突即可
- 管理员可根据实际环境中 DolphinScheduler 组件部署方案,在网络侧和主机侧开放相关端口
1-3-4.客户端Web浏览器要求
DolphinScheduler 推荐 Chrome浏览器 以及使用 Chromium 内核的较新版本浏览器访问前端可视化操作界面
1-4.DolphinScheduler常用术语解释
1-4-1.术语解释
- DAG
- 全称 Directed Acyclic Graph,简称 DAG。工作流中的 Task 任务以有向无环图的形式组装起来,从入度为零的节点进行拓扑遍历,直到无后继节点为止

-
流程定义
- 通过拖拽任务节点并建立任务节点的关联所形成的可视化DAG
-
流程实例
- 流程实例是流程定义的实例化,可以通过手动启动或定时调度生成。每运行一次流程定义,产生一个流程实例
-
任务实例
- 任务实例是流程定义中任务节点的实例化,标识着某个具体的任务
-
任务类型
- 目前支持有 SHELL、SQL、SUB_PROCESS(子流程)、PROCEDURE、MR、SPARK、PYTHON、DEPENDENT(依赖),同时计划支持动态插件扩展,注意:其中 SUB_PROCESS类型的任务需要关联另外一个流程定义,被关联的流程定义是可以单独启动执行
-
调度方式
- 系统支持基于 cron 表达式的定时调度和手动调度。命令类型支持:启动工作流、从当前节点开始执行、恢复被容错的工作流、恢复暂停流程、从失败节点开始执行、补数、定时、重跑、暂停、停止、恢复等待线程。 其中 恢复被容错的工作流 和 恢复等待线程 两种命令类型是由调度内部控制使用,外部无法调用
-
定时调度
- 系统采用 quartz 分布式调度器,并同时支持cron表达式可视化的生成
-
依赖
- 系统不单单支持 DAG 简单的前驱和后继节点之间的依赖,同时还提供任务依赖节点,支持流程间的自定义任务依赖
-
优先级
- 支持流程实例和任务实例的优先级,如果流程实例和任务实例的优先级不设置,则默认是先进先出
-
邮件告警
- 支持 SQL任务 查询结果邮件发送,流程实例运行结果邮件告警及容错告警通知
-
失败策略
- 对于并行运行的任务,如果有任务失败,提供两种失败策略处理方式,继续是指不管并行运行任务的状态,直到流程失败结束。结束是指一旦发现失败任务,则同时Kill掉正在运行的并行任务,流程失败结束
-
补数
- 补历史数据,支持区间并行和串行两种补数方式,其日期选择方式包括日期范围和日期枚举两种
1-4-2.模块介绍
- dolphinscheduler-master master模块,提供工作流管理和编排服务。
- dolphinscheduler-worker worker模块,提供任务执行管理服务。
- dolphinscheduler-alert 告警模块,提供 AlertServer 服务。
- dolphinscheduler-api web应用模块,提供 ApiServer 服务。
- dolphinscheduler-common 通用的常量枚举、工具类、数据结构或者基类
- dolphinscheduler-dao 提供数据库访问等操作。
- dolphinscheduler-remote 基于 netty 的客户端、服务端
- dolphinscheduler-service service模块,包含Quartz、Zookeeper、日志客户端访问服务,便于server模块和api模块调用
- dolphinscheduler-ui 前端模块
| 服务 | 说明 |
|---|---|
| MasterServer | 主要负责 DAG的切分和任务状态的监控 |
| WorkerServer/LoggerServer | 主要负责任务的提交、执行和任务状态的更新。LoggerServer 用于 Rest Api 通过 RPC 查看日志 |
| ApiServer | 提供 Rest Api 服务,供 UI 进行调用 |
| AlertServer | 提供告警服务 |
| UI | 前端页面展示 |
2.dolphinscheduler3.1.1集群部署(Cluster)
本次部署相关安装包以及依赖组件安装文件均汇总在网盘:
链接:https://pan.baidu.com/s/1RLZr2BJRhWl7zFVD98j1mg?pwd=7y8o
提取码:7y8o
- mysql目录
- 用于MySQL应用部署,如果已经有了MySQL5.7环境可以不用下载
- apache-dolphinscheduler-3.1.1-bin.tar.gz
- 用于部署dolphinscheduler-3.1.1版本安装包
- apache-zookeeper-3.5.7-bin.tar.gz
- 用于部署zookeeper服务
- jdk-8u171-linux-x64.tar.gz
- 用于部署java1.8环境,如果不是新服务器,一般都已经有java1.8环境
- mysql-connector-java-8.0.20.jar
- 用于应用与MySQL之间的连接jdbc协议
2-1.环境准备
2-1-1.机器准备
| 服务器IP | 主机名 | CPU/内存/磁盘 | 操作系统 |
|---|---|---|---|
| 172.28.54.210 | dolphinscheduler01 | 4c/8g/100g | CentOS 7.4 |
| 172.28.54.211 | dolphinscheduler02 | 4c/8g/100g | CentOS 7.4 |
| 172.28.54.212 | dolphinscheduler03 | 4c/8g/100g | CentOS 7.4 |
2-1-2.规划主机名
# 设置3台机器主机名
172.28.54.210 # hostnamectl set-hostname dolphinscheduler01
172.28.54.211 # hostnamectl set-hostname dolphinscheduler02
172.28.54.212 # hostnamectl set-hostname dolphinscheduler03
2-1-3.环境优化【所有机器】
- 关闭SELINUX与防火墙
[root@dolphinscheduler01 ~]# vim /etc/selinux/config
SELINUX=disabled
- 关闭防火墙
# 本次关闭
[root@dolphinscheduler01 ~]# systemctl stop firewalld.service
# 开机不自启动
[root@dolphinscheduler01 ~]# systemctl disable firewalld.service
- 配置资源限制参数
[root@dolphinscheduler01 ~]# vim /etc/security/limits.conf
# End of file
* soft nofile 524288
* hard nofile 524288
* soft nproc 131072
* hard nproc 131072
- 配置hosts解析
[root@dolphinscheduler01 ~]# vim /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
# dolphinscheduler_cluster
172.28.54.210 dolphinscheduler01
172.28.54.211 dolphinscheduler02
172.28.54.212 dolphinscheduler03
2-1-4.安装java1.8环境【所有机器】
JDK:下载JDK (1.8+),安装并配置 JAVA_HOME 环境变量,并将其下的 bin 目录追加到 PATH 环境变量中。如果环境中已存在,可以跳过这步
# 网盘下载安装包 jdk-8u171-linux-x64.tar.gz
#链接:https://pan.baidu.com/s/1RLZr2BJRhWl7zFVD98j1mg?pwd=7y8o
#提取码:7y8o
# 上传至服务器
# 解压jdk安装包
[root@dolphinscheduler01 ~]# tar -xf jdk-8u171-linux-x64.tar.gz -C /usr/local/
# 配置环境变量
[root@dolphinscheduler01 ~]# vim /etc/profile
# JAVA_HOME
export JAVA_HOME=/usr/local/jdk1.8.0_171
export PATH=$PATH:$JAVA_HOME/bin
# 引用环境变量
[root@dolphinscheduler01 ~]# source /etc/profile
# 验证jdk安装环境是否正常
[root@dolphinscheduler01 ~]# java -version
java version "1.8.0_171"
Java(TM) SE Runtime Environment (build 1.8.0_171-b11)
Java HotSpot(TM) 64-Bit Server VM (build 25.171-b11, mixed mode)
# 分发至dolphinscheduler02、dolphinscheduler03
[root@dolphinscheduler01 ~]# scp -r /usr/local/jdk1.8.0_171 dolphinscheduler02:/usr/local/
[root@dolphinscheduler01 ~]# scp -r /usr/local/jdk1.8.0_171 dolphinscheduler03:/usr/local/
# 分别在dolphinscheduler02、dolphinscheduler03上配置、引用环境变量并验证,方法同dolphinscheduler01
2-1-5.数据库部署
数据库:PostgreSQL (8.2.15+) 或者 MySQL (5.7+),两者任选其一即可,如 MySQL 则需要 JDBC Driver 8.0.16 +
如果已经有MySQL实例,可以跳过这步
建议MySQL部署在相对稳定的机器上
大多数用户都可以yum安装或者生产环境有专门的MySQL实例,如是纯离线环境又没有现成的,可以在网盘中下载MySQL安装rpm包,按照顺序安装即可
# 如果有MySQL残留文件则remove卸载
[root@dolphinscheduler01 mysql]# yum remove mysql-libs -y
[root@dolphinscheduler01 mysql]# rpm -ivh 01_mysql-community-common-5.7.29-1.el7.x86_64.rpm
[root@dolphinscheduler01 mysql]# rpm -ivh 02_mysql-community-libs-5.7.29-1.el7.x86_64.rpm
[root@dolphinscheduler01 mysql]# rpm -ivh 03_mysql-community-libs-compat-5.7.29-1.el7.x86_64.rpm
[root@dolphinscheduler01 mysql]# rpm -ivh 04_mysql-community-client-5.7.29-1.el7.x86_64.rpm
[root@dolphinscheduler01 mysql]# rpm -ivh 05_mysql-community-server-5.7.29-1.el7.x86_64.rpm
[root@dolphinscheduler01 mysql]# systemctl start mysqld
# 安装完毕后初始密码在 cat /var/log/mysqld.log | grep password
[root@dolphinscheduler01 mysql]# mysql -uroot -pwQIhYE7v2l6Jg6Y6
# 将root初始密码设置为方便易用的密码
mysql> SET PASSWORD=PASSWORD('123456');
Query OK, 0 rows affected (0.00 sec)
# 退出mysql
mysql> exit;
Bye
2-1-6.ZooKeeper安装部署【所有机器】
注册中心:ZooKeeper (3.4.6+)
# 网盘下载安装包 apache-zookeeper-3.5.7-bin.tar.gz
# 或者自行官方网站下载:
# [root@dolphinscheduler01 ~]# wget http://archive.apache.org/dist/zookeeper/zookeeper-3.5.7/apache-zookeeper-3.5.7-bin.tar.gz
# 解压安装、分发安装包
[root@dolphinscheduler01 ~]# tar -xf apache-zookeeper-3.5.7-bin.tar.gz -C /usr/local/
[root@dolphinscheduler01 ~]# scp -r /usr/local/apache-zookeeper-3.5.7-bin dolphinscheduler02:/usr/local/
[root@dolphinscheduler01 ~]# scp -r /usr/local/apache-zookeeper-3.5.7-bin dolphinscheduler03:/usr/local/
# 配置服务器编号
# 配置服务器编号-01
[root@dolphinscheduler01 ~]# cd /usr/local/apache-zookeeper-3.5.7-bin/
[root@dolphinscheduler01 apache-zookeeper-3.5.7-bin]# mkdir -p tmp/zookeeper
[root@dolphinscheduler01 apache-zookeeper-3.5.7-bin]# cd tmp/zookeeper
[root@dolphinscheduler01 zookeeper]# echo 1 > myid
# 配置服务器编号-02
[root@dolphinscheduler02 ~]# cd /usr/local/apache-zookeeper-3.5.7-bin/
[root@dolphinscheduler02 apache-zookeeper-3.5.7-bin]# mkdir -p tmp/zookeeper
[root@dolphinscheduler02 apache-zookeeper-3.5.7-bin]# cd tmp/zookeeper
[root@dolphinscheduler02 zookeeper]# echo 2 > myid
# 配置服务器编号-03
[root@dolphinscheduler03 ~]# cd /usr/local/apache-zookeeper-3.5.7-bin/
[root@dolphinscheduler03 apache-zookeeper-3.5.7-bin]# mkdir -p tmp/zookeeper
[root@dolphinscheduler03 apache-zookeeper-3.5.7-bin]# cd tmp/zookeeper
[root@dolphinscheduler03 zookeeper]# echo 3 > myid
# 配置zoo.cfg
[root@dolphinscheduler01 zkData]# cd /usr/local/apache-zookeeper-3.5.7-bin/conf/
[root@dolphinscheduler01 conf]# mv zoo_sample.cfg zoo.cfg
[root@dolphinscheduler01 conf]# vim zoo.cfg
tickTime=2000
initLimit=10
syncLimit=5
# dataDir 中的值改成 dataDir=./tmp/zookeeper,不然启动dolphinscheduler服务会报错
dataDir=./tmp/zookeeper
clientPort=2181
server.1=dolphinscheduler01:2888:3888
server.2=dolphinscheduler02:2888:3888
server.3=dolphinscheduler03:2888:3888
# 分发配置zoo.cfg
[root@dolphinscheduler01 conf]# scp zoo.cfg dolphinscheduler02:/usr/local/apache-zookeeper-3.5.7-bin/conf/
[root@dolphinscheduler01 conf]# scp zoo.cfg dolphinscheduler03:/usr/local/apache-zookeeper-3.5.7-bin/conf/
# 配置环境变量【3台机器都要操作】
[root@dolphinscheduler01 conf]# vim /etc/profile
# ZK_home
export ZOOKEEPER_HOME=/usr/local/apache-zookeeper-3.5.7-bin
export PATH=$PATH:$ZOOKEEPER_HOME/bin
[root@dolphinscheduler01 conf]# source /etc/profile
【注意】:
- server.1 / server.2 / server.3 中的 1 2 3 对应的就是zkData目录中myid中的值
- server后面的dolphinscheduler01 / dolphinscheduler02 / dolphinscheduler03 没采用IP地址是因为配置了/etc/hosts的解析
配置cluster信息解读:
server.A=B:C:D [ server.1=dolphinscheduler01:2888:3888 ( A=1 , B=dolphinscheduler01 , C=2888, D=3888)
A 是一个数字,表示这个是第几号服务器;
集群模式下配置一个文件myid,这个文件在配置的data目录下,这个文件里面数值就是A的值,Zookeeper启动时读取此文件,拿到里面的数据与zoo.cfg里面的配置信息比较从而判断到底是哪个server。
B 是这个服务器的地址;
C 是这个服务器Follower与集群中的Leader服务器交换信息的端口;
D 是万一集群中的Leader服务器挂了,需要一个端口来重新进行选举,选出一个新的Leader,而这个端口就是用来执行选举时服务器相互通信的端口。
# 启动zk服务
[root@dolphinscheduler01 ~]# zkServer.sh start
[root@dolphinscheduler02 ~]# zkServer.sh start
[root@dolphinscheduler03 ~]# zkServer.sh start
# 查看集群状态
# 01
[root@dolphinscheduler01 ~]# zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /usr/local/apache-zookeeper-3.5.7-bin/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost.
Mode: follower
# 02
[root@dolphinscheduler02 ~]# zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /usr/local/apache-zookeeper-3.5.7-bin/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost.
Mode: leader
# 03
[root@dolphinscheduler03 ~]# zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /usr/local/apache-zookeeper-3.5.7-bin/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost.
Mode: follower
2-2.安装部署dolphinscheduler
2-2-1.解压安装包
# 解压安装包
[root@dolphinscheduler01 ~]# tar -xf apache-dolphinscheduler-3.1.1-bin.tar.gz -C /usr/local/
2-2-2配置部署用户以及权限【所有机器】
创建部署用户,并且一定要配置 sudo 免密。以创建 dolphinscheduler 用户为例
每台服务器均需要执行
# 创建用户需使用 root 登录
[root@dolphinscheduler01 ~]# useradd dolphinscheduler
# 添加密码
[root@dolphinscheduler01 ~]# echo "dolphinscheduler" | passwd --stdin dolphinscheduler
# 配置 sudo 免密
[root@dolphinscheduler01 ~]# sed -i '$adolphinscheduler ALL=(ALL) NOPASSWD: NOPASSWD: ALL' /etc/sudoers
[root@dolphinscheduler01 ~]# sed -i 's/Defaults requirett/#Defaults requirett/g' /etc/sudoers
# 修改目录权限,使得部署用户对二进制包解压后的 apache-dolphinscheduler目录有操作权限
[root@dolphinscheduler01 ~]# chown -R dolphinscheduler:dolphinscheduler /usr/local/apache-dolphinscheduler-3.1.1-bin/
2-2-3.配置机器SSH免密登陆【所有机器】
由于安装的时候需要向不同机器发送资源,所以要求各台机器间能实现SSH免密登陆。配置免密登陆的步骤如下
# 3台机器操作方式相同,02,03自行操作
[root@dolphinscheduler01 ~]# su - dolphinscheduler
[dolphinscheduler@dolphinscheduler01 ~]$ ssh-keygen -t rsa
[dolphinscheduler@dolphinscheduler01 ~]$ ssh-copy-id dolphinscheduler01
[dolphinscheduler@dolphinscheduler01 ~]$ ssh-copy-id dolphinscheduler02
[dolphinscheduler@dolphinscheduler01 ~]$ ssh-copy-id dolphinscheduler03
2-2-4.修改dolphinscheduler相关配置文件
- 修改 install_env.sh 文件
文件 install_env.sh 描述了哪些机器将被安装 DolphinScheduler 以及每台机器对应安装哪些服务。您可以在路径
bin/env/install_env.sh中找到此文件,可通过以下方式更改env变量,export=,配置详情如下
[dolphinscheduler@dolphinscheduler01 ~]$ vim /usr/local/apache-dolphinscheduler-3.1.1-bin/bin/env/install_env.sh
ips="dolphinscheduler01,dolphinscheduler02,dolphinscheduler03"
sshPort="22"
masters="dolphinscheduler01,dolphinscheduler02,dolphinscheduler03"
workers="dolphinscheduler01:default,dolphinscheduler02:default,dolphinscheduler03:default"
alertServer="dolphinscheduler01"
apiServers="dolphinscheduler01"
installPath="/opt/dolphinscheduler"
deployUser="dolphinscheduler"
zkRoot=${zkRoot:-"/dolphinscheduler"}
- 修改 dolphinscheduler_env.sh 文件
[dolphinscheduler@dolphinscheduler01 ~]$ vim /usr/local/apache-dolphinscheduler-3.1.1-bin/bin/env/dolphinscheduler_env.sh
export JAVA_HOME="/usr/local/jdk1.8.0_171"
export DATABASE="mysql"
export SPRING_PROFILES_ACTIVE=${DATABASE}
export SPRING_DATASOURCE_URL="jdbc:mysql://dolphinscheduler01:3306/dolphinscheduler?useUnicode=true&characterEncoding=UTF-8&useSSL=false&allowPublicKeyRetrieval=true"
export SPRING_DATASOURCE_USERNAME="dolphinscheduler"
export SPRING_DATASOURCE_PASSWORD="dolphinscheduler"
export SPRING_CACHE_TYPE="none"
export SPRING_JACKSON_TIME_ZONE="Asia/Shanghai"
export MASTER_FETCH_COMMAND_NUM="10"
export REGISTRY_TYPE="zookeeper"
export REGISTRY_ZOOKEEPER_CONNECT_STRING="dolphinscheduler01:2181,dolphinscheduler02:2181,dolphinscheduler03:2181"
注意:
JAVA_HOME根据自己实际情况配置修改正确路径
最后的配置,这里没有列出来的,暂时可以不配置
2-2-5.初始化数据库
DolphinScheduler 元数据存储在关系型数据库中,目前支持 PostgreSQL 和 MySQL
如果使用 MySQL 需要手动下载 mysql-connector-java 驱动 (8.0.16+) 并移动到 DolphinScheduler 的每个模块的 libs 目录下,其中包括 api-server/libs 和 alert-server/libs 和 master-server/libs 和 worker-server/libs和tools/libs
依赖包已经在分享的云盘中
[dolphinscheduler@dolphinscheduler01 ~]$ cp mysql-connector-java-8.0.20.jar /usr/local/apache-dolphinscheduler-3.1.1-bin/api-server/libs/
[dolphinscheduler@dolphinscheduler01 ~]$ cp mysql-connector-java-8.0.20.jar /usr/local/apache-dolphinscheduler-3.1.1-bin/alert-server/libs/
[dolphinscheduler@dolphinscheduler01 ~]$ cp mysql-connector-java-8.0.20.jar /usr/local/apache-dolphinscheduler-3.1.1-bin/master-server/libs/
[dolphinscheduler@dolphinscheduler01 ~]$ cp mysql-connector-java-8.0.20.jar /usr/local/apache-dolphinscheduler-3.1.1-bin/worker-server/libs/
[dolphinscheduler@dolphinscheduler01 ~]$ cp mysql-connector-java-8.0.20.jar /usr/local/apache-dolphinscheduler-3.1.1-bin/tools/libs/
# 这里的配置增加项都和/usr/local/apache-dolphinscheduler-3.1.1-bin/bin/env/dolphinscheduler_env.sh中配置匹配上
[dolphinscheduler@dolphinscheduler01 ~]# mysql -uroot -p
# 新建dolphinscheduler库
mysql> CREATE DATABASE dolphinscheduler DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_general_ci;
mysql> CREATE USER 'dolphinscheduler'@'%' IDENTIFIED BY 'dolphinscheduler';
mysql> GRANT ALL PRIVILEGES ON dolphinscheduler.* TO 'dolphinscheduler'@'%';
mysql> CREATE USER 'dolphinscheduler'@'localhost' IDENTIFIED BY 'dolphinscheduler';
mysql> GRANT ALL PRIVILEGES ON dolphinscheduler.* TO 'dolphinscheduler'@'localhost';
mysql> FLUSH PRIVILEGES;
mysql> quit;
Bye
完成上述步骤后,已经为 DolphinScheduler 创建一个新数据库dolphinscheduler,现在可以通过快速的 Shell 脚本来初始化数据库,用来建应用使用的各类table表
[dolphinscheduler@dolphinscheduler01 ~]$ cd /usr/local/apache-dolphinscheduler-3.1.1-bin/
[dolphinscheduler@dolphinscheduler01 apache-dolphinscheduler-3.1.1-bin]$ bash tools/bin/upgrade-schema.sh
如果MySQL连接异常,这一步则会执行失败,如果报错可以查看MySQL的相关配置和操作
也可以到MySQL的dolphinscheduler库下去查看是否创建表成功:
[dolphinscheduler@dolphinscheduler01 ~]$ mysql -udolphinscheduler -pdolphinscheduler mysql> use dolphinscheduler; mysql> show tables like '%version%'; +----------------------------------------+ | Tables_in_dolphinscheduler (%version%) | +----------------------------------------+ | t_ds_version | +----------------------------------------+ 1 row in set (0.00 sec) mysql> select * from t_ds_version; +----+---------+ | id | version | +----+---------+ | 1 | 3.1.1 | +----+---------+ 1 row in set (0.00 sec)
2-2-6.安装部署dolphinscheduler
install.sh安装启动dolphinscheduler
[dolphinscheduler@dolphinscheduler01 apache-dolphinscheduler-3.1.1-bin]$ bash ./bin/install.sh
注意:只有第一次是使用bash ./bin/install.sh,成功部署完毕后,以后都是用bash ./bin/stop-all.sh和bash ./bin/start-all.sh
install.sh可以理解成会把/usr/local/apache-dolphinscheduler-3.1.1-bin/目录下修改的文件分发到各个机器,然后逐个去启动
查看服务角色分布情况:
[dolphinscheduler@dolphinscheduler01 ~]$ for i in dolphinscheduler01 dolphinscheduler02 dolphinscheduler03;do echo "=== $i ===" && ssh $i "/usr/local/jdk1.8.0_171/bin/jps";done
=== dolphinscheduler01 ===
31120 AlertServer
31041 MasterServer
31157 ApiApplicationServer
31081 WorkerServer
=== dolphinscheduler02 ===
25048 MasterServer
25085 WorkerServer
=== dolphinscheduler03 ===
25008 WorkerServer
24971 MasterServer
后续通过URL访问连接则对应的是dolphinscheduler01服务器的ApiApplicationServer服务,对应端口是12345
2-2.7.登录访问DolphinScheduler
浏览器访问地址 http://localhost:12345/dolphinscheduler/ui 即可登录系统UI。
默认的用户名和密码是 :admin / dolphinscheduler123
Apache DolphinScheduler 首页可让您查看用户所有项目的任务状态统计、工作流状态统计和项目统计。 这是观察整个系统状态以及深入各个进程以检查任务和任务日志的每个状态的最佳方式
2-2-8.DolphinScheduler集群启动停止服务
# 一键停止集群所有服务
bash ./bin/stop-all.sh
# 一键开启集群所有服务
bash ./bin/start-all.sh
# 启停 Master
bash ./bin/dolphinscheduler-daemon.sh stop master-server
bash ./bin/dolphinscheduler-daemon.sh start master-server
# 启停 Worker
bash ./bin/dolphinscheduler-daemon.sh start worker-server
bash ./bin/dolphinscheduler-daemon.sh stop worker-server
# 启停 Api
bash ./bin/dolphinscheduler-daemon.sh start api-server
bash ./bin/dolphinscheduler-daemon.sh stop api-server
# 启停 Alert
bash ./bin/dolphinscheduler-daemon.sh start alert-server
bash ./bin/dolphinscheduler-daemon.sh stop alert-server
3.DolphinScheduler功能介绍
3-1.项目管理
3-1-1.项目列表
点击"项目管理"进入项目管理页面,点击“创建项目”按钮,输入项目名称,项目描述,点击“提交”,创建新的项目。
项目创建完成后,点击项目名称即可进入到指定项目的首页

- 任务状态统计
- 在指定时间范围内,统计任务实例中状态为提交成功、正在运行、准备暂停、暂停、准备停止、停止、失败、成功、需要容错、kill、等待线程的个数
- 流程状态统计
- 在指定时间范围内,统计工作流实例中状态为提交成功、正在运行、准备暂停、暂停、准备停止、停止、失败、成功、需要容错、kill、等待线程的个数
3-1-2.工作流定义
3-1-2-1.创建工作流
- 创建工作流定义
- 左侧任务栏:工作流->工作流定义,点击进入工作流定义页面,点击“创建工作流”按钮,进入工作流DAG编辑页面
- 工具栏中拖拽一个任务类型SHELL到画板中,新增一个Shell任务
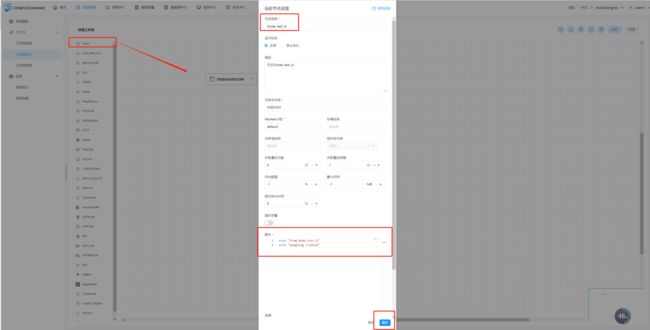
添加 Shell 任务的参数设置:
- 填写“节点名称”,“描述”,“脚本”字段;
- 节点名称 - Node节点名称
- 描述 - 可以详细描述一下当前Node节点是做什么、什么功能
- 脚本 - 当前节点实现的shell命令代码
- “运行标志”勾选“正常”,若勾选“禁止执行”,运行工作流不会执行该任务;
- 选择“任务优先级”:当 worker 线程数不足时,级别高的任务在执行队列中会优先执行,相同优先级的任务按照先进先出的顺序执行;
- 超时告警(非必选):勾选超时告警、超时失败,填写“超时时长”,当任务执行时间超过超时时长,会发送告警邮件并且任务超时失败;
- 资源(非必选):资源文件是资源中心->文件管理页面创建或上传的文件,如文件名为 test.sh,脚本中调用资源命令为 sh test.sh。注意调用需要使用资源的全路径;
- 自定义参数(非必填);
- 点击"确认添加"按钮,保存任务设置。
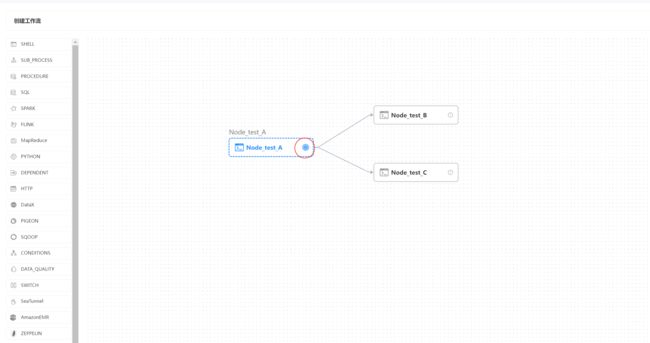
按照Node_test_A方式再创建Node_test_B和Node_test_C,这时候画板中的A、B、C 三个节点都是相互独立的,并没有关联
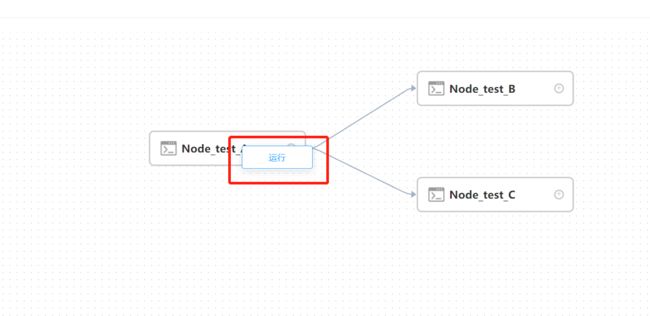
- 配置任务之间的依赖关系
- 点击任务节点的右侧加号连接任务;如下图所示,任务Node_test_B和任务Node_test_C 并行执行,当任务 Node_A 执行完,任务 Node_B、Node_C 会同时执行
-
实时任务的依赖关系
- 若DAG中包含了实时任务的组件,则实时任务的关联关系显示为虚线,在执行工作流实例的时候会跳过实时任务的执行
-
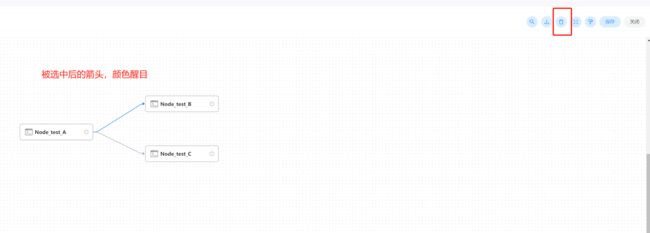
删除依赖关系
- 鼠标左键点击需要删除的"箭头"图标,选中连接线,点击右上角"删除"图标,删除任务间的依赖关系。
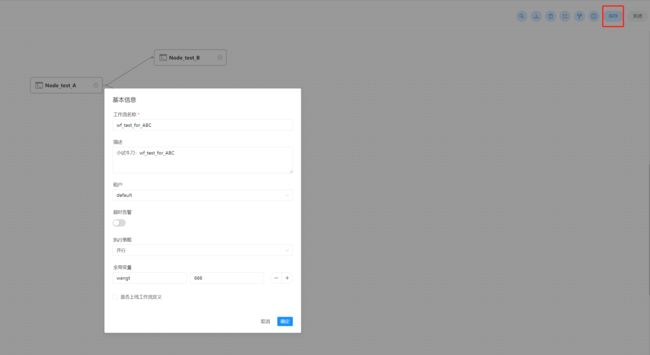
- 保存工作流定义
- 点击”保存“按钮,弹出"设置DAG图名称"弹框,如下图所示,输入工作流定义名称,工作流定义描述,设置全局参数(选填,参考全局参数),点击"添加"按钮,工作流定义创建成功
执行策略:
- 并行:如果对于同一个工作流定义,同时有多个工作流实例,则并行执行工作流实例
- 串行等待:如果对于同一个工作流定义,同时有多个工作流实例,则并行执行工作流实例
- 串行抛弃:如果对于同一个工作流定义,同时有多个工作流实例,则抛弃后生成的工作流实例并杀掉正在跑的实例
- 串行优先:如果对于同一个工作流定义,同时有多个工作流实例,则按照优先级串行执行工作流实例
3-1-2-2.工作流定义操作功能
点击项目管理->工作流->工作流定义,进入工作流定义页面,如下图所示:

工作流定义列表的操作功能如下:
-
编辑:只能编辑"下线"的工作流定义。工作流DAG编辑同创建工作流定义
-
上线: 工作流状态为"下线"时,上线工作流,只有"上线"状态的工作流能运行,但不能编辑。
-
下线: 工作流状态为"上线"时,下线工作流,下线状态的工作流可以编辑,但不能运行。
-
运行: 只有上线的工作流能运行。运行操作步骤见运行工作流
-
定时: 只有上线的工作流能设置定时,系统自动定时调度工作流运行。创建定时后的状态为"下线",需在定时管理页面上线定时才生效。定时操作步骤见工作流定时
-
定时管理: 定时管理页面可编辑、上线/下线、删除定时。
-
删除: 删除工作流定义。在同一个项目中,只能删除自己创建的工作流定义,其他用户的工作流定义不能进行删除,如果需要删除请联系创建用户或者管理员。
-
下载: 下载工作流定义到本地。
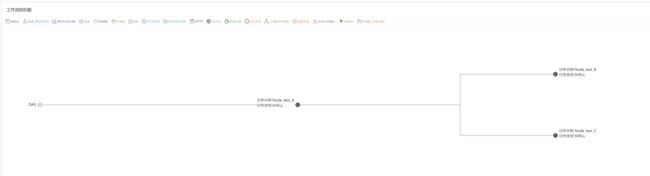
-
工作流树形图: 以树形结构展示任务节点的类型及任务状态
3-1-2-3.运行工作流
-
点击项目管理->工作流->工作流定义,进入工作流定义页面,如下图所示,点击"上线"按钮,上线工作流。
-
点击”运行“按钮,弹出启动参数设置弹框,如下图所示,设置启动参数,点击弹框中的"运行"按钮,工作流开始运行,工作流实例页面生成一条工作流实例
工作流运行参数说明:
- 失败策略:当某一个任务节点执行失败时,其他并行的任务节点需要执行的策略。
- ”继续“表示:某一任务失败后,其他任务节点正常执行;
- ”结束“表示:终止所有正在执行的任务,并终止整个流程。
- 通知策略:当流程结束,根据流程状态发送流程执行信息通知邮件,包含任何状态都不发,成功发,失败发,成功或失败都发。
- 流程优先级:流程运行的优先级,当 master 线程数不足时,级别高的流程在执行队列中会优先执行,相同优先级的流程按照先进先出的顺序执行,分五个等级:
- 最高(HIGHEST)
- 高(HIGH)
- 中(MEDIUM)
- 低(LOW)
- 最低(LOWEST)
- Worker 分组:该流程只能在指定的 worker 机器组里执行。默认是 Default,可以在任一 worker 上执行。
- 通知组:选择通知策略||超时报警||发生容错时,会发送流程信息或邮件到通知组里的所有成员。
- 启动参数: 在启动新的流程实例时,设置或覆盖全局参数的值。
- 补数:指运行指定日期范围内的工作流定义,根据补数策略生成对应的工作流实例,补数策略包括串行补数、并行补数 2 种模式
- 日期可以通过页面选择或者手动输入,日期范围是左关右关区间(startDate <= N <= endDate)
- 串行补数:指定时间范围内,从开始日期至结束日期依次执行补数,依次生成多条流程实例;点击运行工作流,选择串行补数模式:例如从7月 9号到7月10号依次执行,依次在流程实例页面生成两条流程实例
- 并行补数: 指定时间范围内,同时进行多天的补数,同时生成多条流程实例。手动输入日期:手动输入以逗号分割日期格式为
yyyy-MM-dd HH:mm:ss的日期。点击运行工作流,选择并行补数模式:例如同时执行7月9号到7月10号的工作流定义,同时在流程实例页面生成两条流程实例(执行策略为串行时流程实例按照策略执行) - 并行度:是指在并行补数的模式下,最多并行执行的实例数。
- 依赖模式:是否触发下游依赖节点依赖到当前工作流的工作流实例的补数(要求当前补数的工作流实例的定时状态为已上线,只会触发下游直接依赖到当前工作流的补数)
- 日期选择:
- 通过页面选择日期
- 手动输入
- 补数与定时配置的关系:
- 未配置定时或已配置定时并定时状态下线:根据所选的时间范围结合定时默认配置(每天0点)进行补数
- 已配置定时并定时状态上线:根据所选的时间范围结合定时配置进行补数,比如该工作流调度日期为7月7号到7月10号,配置了定时(每日凌晨5点运行)
运行任务需要新加一个租户:
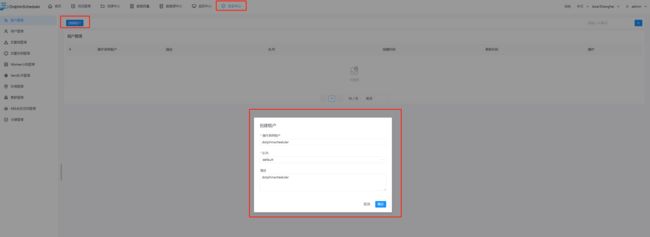
安全中心后面展开介绍,这里先跑通流程

点击确定后,则工作流会开始运行
3-1-2-4.单独运行工作流中的任务
- 右键选中任务,点击"启动"按钮(只有已上线的任务才能点击运行)
- 弹出启动参数设置弹框,参数说明同运行工作流
3-1-2-5.工作流定时
创建定时:点击项目管理->工作流->工作流定义,进入工作流定义页面,上线工作流,点击"定时"按钮,弹出定时参数设置弹框
-
选择起止时间。在起止时间范围内,定时运行工作流;不在起止时间范围内,不再产生定时工作流实例
-
在定义完时间后可以点击运行时间,查看验证后续执行的时间清单
-
失败策略、通知策略、流程优先级、Worker 分组、通知组、收件人、抄送人同工作流运行参数
-
定时上线:点击"定时管理"按钮,进入定时管理页面,点击"上线"按钮,定时状态变为"上线"
3-1-2-6.导出工作流
点击操作中的导出,可以导出一个json文件到本地

workflow_1668875701525.json
3-1-2-6.删除工作流
点击操作上的删除按钮,点击确定即可
3-1-2-7.导出工作流
点击项目管理->工作流->工作流定义,进入工作流定义页面,点击"导入工作流"按钮,导入本地工作流文件,工作流定义列表显示导入的工作流,状态为下线。
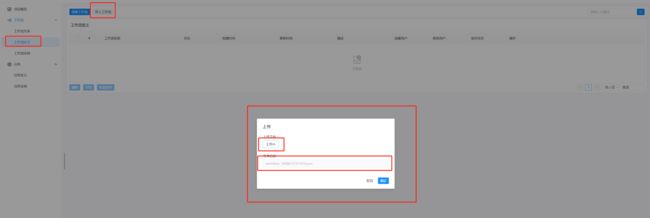
3-1-3.工作流实例
将导入的工作流wf_test_for_ABC_import_20221120004014956点击运行,工作流中的单个任务点击运行,产生一些运行实例
3-1-3-1.查看工作流实例
点击项目管理->工作流->工作流实例,进入工作流实例页面

点击工作流名称,进入DAG查看页面,查看任务执行状态
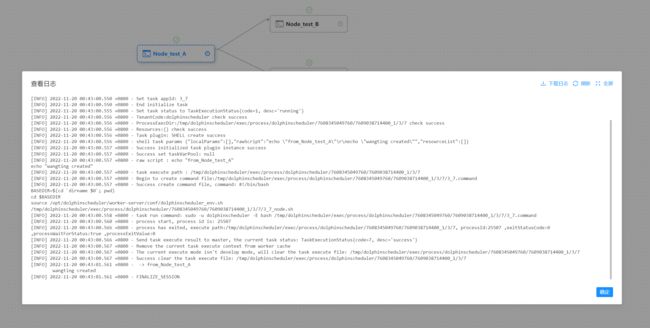
3-1-3-2.查看任务日志
- 进入工作流实例页面,点击工作流名称,进入DAG查看页面,双击其中一个任务节点
- 点击"查看日志",弹出日志弹框,如下图所示,任务实例页面也可查看任务日志
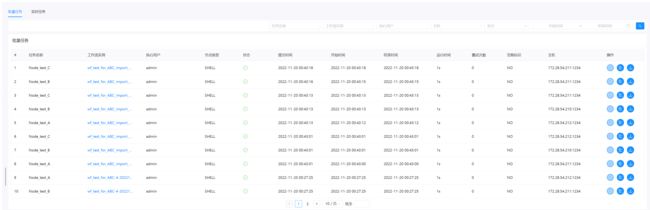
3-1-3-3.查看任务历史记录
- 点击项目管理->工作流->工作流实例,进入工作流实例页面,点击工作流名称,进入工作流 DAG 页面;
- 双击任务节点,点击"查看历史",跳转到任务实例页面,并展示该工作流实例运行的任务实例列表
3-1-3-4.查看运行参数
- 点击项目管理->工作流->工作流实例,进入工作流实例页面,点击工作流名称,进入工作流 DAG 页面
- 点击左上角图标,,查看工作流实例的启动参数和查看变量

3-1-3-5.工作流实例操作功能
点击项目管理->工作流->工作流实例,进入工作流实例页面,在操作中有各类常用常用按钮
- 编辑: 只能编辑 成功/失败/停止 状态的流程。点击"编辑"按钮或工作流实例名称进入 DAG 编辑页面,编辑后点击"保存"按钮,弹出保存 DAG 弹框,修改流程定义信息,在弹框中勾选"是否更新工作流定义",保存后则将实例修改的信息更新到工作流定义;若不勾选,则不更新工作流定义
- 重跑: 重新执行已经终止的流程
- 恢复失败: 针对失败的流程,可以执行恢复失败操作,从失败的节点开始执行。
- 停止: 对正在运行的流程进行停止操作,后台会先 kill worker 进程,再执行 kill -9 操作
- 暂停: 对正在运行的流程进行暂停操作,系统状态变为等待执行,会等待正在执行的任务结束,暂停下一个要执行的任务。
- 恢复暂停: 对暂停的流程恢复,直接从暂停的节点开始运行
- 删除: 删除工作流实例及工作流实例下的任务实例
- 甘特图: Gantt 图纵轴是某个工作流实例下的任务实例的拓扑排序,横轴是任务实例的运行时间
3-1-4.任务实例
- 批量任务实例
点击项目管理->工作流->任务实例,进入任务实例页面,如下图所示,点击工作流实例名称,可跳转到工作流实例DAG图查看任务状态

查看日志:点击操作列中的“查看日志”按钮,可以查看任务执行的日志情况
3-1-5.任务定义
使用 Apache DolphinScheduler 3.0.0 此前版本,用户如果想要操作任务,需要先找到对应的工作流,并在工作流中定位到任务的位置之后才能编辑。然而,当工作流数量变多或单个工作流有较多的任务时,找到对应任务的过程将会变得非常痛苦,这不是 Apache DolphinScheduler 所追求的 easy to use 理念。所以,我们在 3.0.0 中增加了任务定义页面,让用户可以通过任务名称快速定位到任务,并对任务进行操作,轻松实现批量任务变更。
- 批量任务定义
批量任务定义允许用户在基于任务级别而不是在工作流中操作修改任务。再此之前,我们已经有了工作流级别的任务编辑器,可以在工作流定义 单击特定的工作流,然后编辑任务的定义,并不是这里可以一次性创建很多新任务的意思。
在该视图中,可以通过单击 操作 列中的相关按钮来进行创建、查询、更新、删除任务定义。可以通过通配符进行全部任务查询,当只记得任务名称但忘记它属于哪个工作流时是非常有用的。也支持通过任务名称结合使用 任务类型 或 工作流程名称进行查询

3-2.任务类型
dolphinscheduler有非常丰富的任务类型插件,几乎可以覆盖全部的数据处理任务的场景,这里简单介绍一下任务的描述,具体每个任务类型的使用是一个漫长的学习过程和经验积累。
-
Shell
- Shell 任务类型,用于创建 Shell 类型的任务并执行一系列的 Shell 脚本。worker 执行该任务的时候,会生成一个临时 shell 脚本,并使用与租户同名的 linux 用户执行这个脚本
-
sub_process
- 子流程节点,就是把外部的某个工作流定义当做一个节点去执
-
Dependent
- Dependent 节点,就是依赖检查节点。比如 A 流程依赖昨天的 B 流程执行成功,依赖节点会去检查 B 流程在昨天是否有执行成功的实例
-
stored-procedure
- 存储过程节点
- 根据选择的数据源,执行存储过程
- 前提:在该数据库里面创建存储过程
- 存储过程节点
-
SQL
- SQL任务类型,用于连接数据库并执行相应SQL
-
Spark
- Spark 任务类型用于执行 Spark 应用
-
MapReduce
- MapReduce(MR) 任务类型,用于执行 MapReduce 程序。对于 MapReduce 节点,worker 会通过使用 Hadoop 命令 hadoop jar 的方式提交任务
-
Python
- Python 任务类型,用于创建 Python 类型的任务并执行一系列的 Python 脚本。worker 执行该任务的时候,会生成一个临时python脚本, 并使用与租户同名的 linux 用户执行这个脚本
-
Flink
- Flink 任务类型,用于执行 Flink 程序
-
HTTP
- 该节点用于执行 http 类型的任务,例如常见的 POST、GET 等请求类型,此外还支持 http 请求校验等功能
-
DataX
- DataX 任务类型,用于执行 DataX 程序。对于 DataX 节点,worker 会通过执行
${DATAX_HOME}/bin/datax.py来解析传入的 json 文件
- DataX 任务类型,用于执行 DataX 程序。对于 DataX 节点,worker 会通过执行
-
Pigeon
- Pigeon任务类型是通过调用远程websocket服务,实现远程任务的触发,状态、日志的获取,是 DolphinScheduler 通用远程 websocket 服务调用任务
-
Conditions
- Conditions 是一个条件节点,根据上游任务运行状态,判断应该运行哪个下游任务。截止目前 Conditions 支持多个上游任务,但只支持两个下游任务。当上游任务数超过一个时,可以通过且以及或操作符实现复杂上游依赖
-
Switch
- Switch 是一个条件判断节点,依据全局变量的值和用户所编写的表达式判断结果执行对应分支。 注意使用 javax.script.ScriptEngine.eval 执行表达式
-
SeaTunnel
- SeaTunnel 任务类型,用于创建并执行 SeaTunnel 类型任务。worker 执行该任务的时候,会通过 start-seatunnel-spark.sh 或 start-seatunnel-flink.sh 命令解析 config 文件。
-
Amazon EMR
- Amazon EMR 任务类型,用于在AWS上操作EMR集群并执行计算任务。 后台使用 aws-java-sdk 将JSON参数转换为任务对象,提交到AWS
-
Zeppelin
- Zeppelin任务类型,用于创建并执行Zeppelin类型任务。worker 执行该任务的时候,会通过Zeppelin Cient API触发Zeppelin Notebook Paragraph
-
Jupyter
- Jupyter任务类型,用于创建并执行Jupyter类型任务。worker 执行该任务的时候,会通过papermill执行jupyter note
-
Hive Cli
- 使用Hive Cli任务插件创建Hive Cli类型的任务执行SQL脚本语句或者SQL任务文件。 执行任务的worker会通过hive -e命令执行hive SQL脚本语句或者通过hive -f命令执行资源中心中的hive SQL文件
-
kubernetes
- kubernetes任务类型,用于在kubernetes上执行一个短时和批处理的任务。worker最终会通过使用kubernetes client提交任务
-
MLflow
- MLflow 是一个MLops领域一个优秀的开源项目, 用于管理机器学习的生命周期,包括实验、可再现性、部署和中心模型注册
- MLflow 组件用于执行 MLflow 任务,目前包含Mlflow Projects,和MLflow Models
-
OpenMLDB
- OpenMLDB 是一个优秀的开源机器学习数据库,提供生产级数据及特征开发全栈解决方案
- OpenMLDB任务组件可以连接OpenMLDB集群执行任务
-
DVC
- DVC 组件用于在DS上使用DVC的数据版本管理功能,帮助用户简易地进行数据的版本管理
-
Dinky
- Dinky任务类型,用于创建并执行Dinky类型任务以支撑一站式的开发、调试、运维 FlinkSQL、Flink Jar、SQL。worker 执行该任务的时候,会通过Dinky API触发Dinky 的作业
-
ChunJun
- ChunJun 任务类型,用于执行 ChunJun 程序。对于 ChunJun 节点,worker 会通过执行 ${CHUNJUN_HOME}/bin/start-chunjun 来解析传入的 json 文件
-
Pytorch
- Pytorch 是一个的主流Python机器学习库
- 为了用户能够在DolphinScheduler中更方便的运行Pytorch项目,实现了Pytorch任务组件。主要提供便捷的python环境管理以及支持运行python项目
针对每一个任务类型,可以在官方项目文档中找到对应的任务插件的详细介绍使用
3-3.参数
3-3-1.内置参数
3-3-1-1.基础内置参数
| 变量名 | 声明方式 | 含义 |
|---|---|---|
| system.biz.date | ${system.biz.date} | 日常调度实例定时的定时时间前一天,格式为 yyyyMMdd |
| system.biz.curdate | ${system.biz.curdate} | 日常调度实例定时的定时时间,格式为 yyyyMMdd |
| system.datetime | ${system.datetime} | 日常调度实例定时的定时时间,格式为 yyyyMMddHHmmss |
3-3-1-2.衍生内置参数
- 支持代码中自定义变量名,声明方式:${变量名}。可以是引用 “系统参数”
- 定义这种基准变量为 [ . . . ] 格 式 的 , [...] 格式的, [...]格式的,[yyyyMMddHHmmss] 是可以任意分解组合的,比如:$[yyyyMMdd], $[HHmmss], $[yyyy-MM-dd] 等
- 也可以通过以下两种方式定义:
- 使用add_months()函数,该函数用于加减月份, 第一个入口参数为[yyyyMMdd],表示返回时间的格式 第二个入口参数为月份偏移量,表示加减多少个月
- 后 N 年:$[add_months(yyyyMMdd,12*N)]
- 前 N 年:$[add_months(yyyyMMdd,-12*N)]
- 后 N 月:$[add_months(yyyyMMdd,N)]
- 前 N 月:$[add_months(yyyyMMdd,-N)]
- 直接加减数字 在自定义格式后直接“+/-”数字
- 后 N 周:$[yyyyMMdd+N]
- 前 N 周:$[yyyyMMdd-7N]
- 后 N 天:$[yyyyMMdd+N]
- 前 N 天:$[yyyyMMdd-N]
- 后 N 小时:$[HHmmss+N/24]
- 前 N 小时:$[HHmmss-N/24]
- 后 N 分钟:$[HHmmss+N/24/60]
- 前 N 分钟:$[HHmmss-N/24/60]
- 使用add_months()函数,该函数用于加减月份, 第一个入口参数为[yyyyMMdd],表示返回时间的格式 第二个入口参数为月份偏移量,表示加减多少个月
3-3-2.全局参数
-
作用域
- 全局参数是指针对整个工作流的所有任务节点都有效的参数,在工作流定义页面配置
-
使用方式
- 具体的使用方式可结合实际的生产情况而定,这里演示为使用 Shell 任务打印出前一天的日期
-
创建shell任务
- 创建一个 Shell 任务,并在脚本内容中输入 echo ${dt}。此时 dt 则为我们需要声明的全局参数
在某个工作流下创建任务时,需要将此工作流选为下线状态

- 点击保存工作流,并设置全局参数( 全局参数配置方式如下:在工作流定义页面,点击“设置全局”右边的加号,填写对应的变量名称和对应的值,保存即可 )

注意:
- 这里定义的 dt 参数可以被其它任一节点的局部参数引用
- 任务实例查看执行结果
- 进入任务实例页面,可以通过查看日志,验证任务的执行结果,判断参数是否有效

3-3-3.本地参数
- 作用域
- 在任务定义页面配置的参数,默认作用域仅限该任务,如果配置了参数传递则可将该参数作用到下游任务中
- 使用方式
- 本地参数配置方式如下:在任务定义页面,点击“自定义参数”右边的加号,填写对应的变量名称和对应的值,保存即可
- 如果要在任务中使用配置参数并在下游任务中使用它们,使用setValue
通过自定义参数使用
创建一个新任务Node_test_E

参数说明:
- dt:参数名
- IN:IN 表示局部参数仅能在当前节点使用,OUT 表示局部参数可以向下游传递
- DATE:数据类型,日期
- $[yyyy-MM-dd]:自定义格式的衍生内置参数
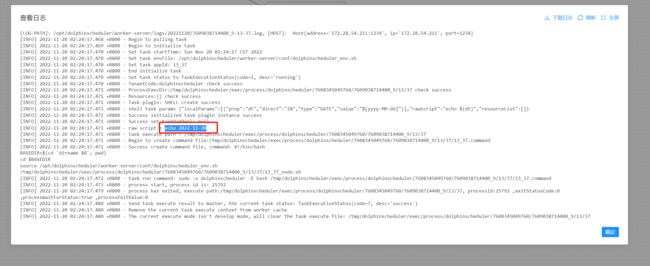
可以看到在工作流中定义的dt为前一天的变量并未影响到子任务中的定义,优先使用的为任务定义中的变量
通过 setValue export 本地参数
如果你想简单 export 参数然后在下游任务中使用它们,你可以在你的任务中使用 setValue,你可以将参数统一在一个任务中管理。在 Shell 任务中使用语法 echo ‘${setValue(wow=20230123)}’(不要忘记单引号) 并添加新的 OUT 自定义参数来 export 它
创建任务Node_test_F

创建任务Node_test_G

在工作流中将F任务和G任务形成上下游关系

此时运行任务,验证G任务是否可以打印出echo '${wow}',取到F任务中定义的变量

3-3-4.参数传递
DolphinScheduler 提供参数间相互引用的能力,包括:本地参数引用全局参数、上下游参数传递。因为有引用的存在,就涉及当参数名相同时,参数的优先级问题
- 本地任务引用全局参数
- 本地任务引用全局参数的前提是,你已经定义了全局参数,使用方式和本地参数中的使用方式类似,但是参数的值需要配置成全局参数中的 key
- 上游任务传递给下游任务
- DolphinScheduler 允许在任务间进行参数传递,目前传递方向仅支持上游单向传递给下游。目前支持这个特性的任务类型有:
- Shell
- SQL
- Procedure
- 当定义上游节点时,如果有需要将该节点的结果传递给有依赖关系的下游节点,需要在【当前节点设置】的【自定义参数】设置一个方向是 OUT 的变量。目前我们主要针对 SQL 和 SHELL 节点做了可以向下传递参数的功能
- DolphinScheduler 允许在任务间进行参数传递,目前传递方向仅支持上游单向传递给下游。目前支持这个特性的任务类型有:
注意:若节点之间没有依赖关系,则局部参数无法通过上游传递
3-3-5.参数优先级
DolphinScheduler 中所涉及的参数值的定义可能来自三种类型:
- 全局参数:在工作流保存页面定义时定义的变量
- 上游任务传递的参数:上游任务传递过来的参数
- 本地参数:节点的自有变量,用户在“自定义参数”定义的变量,并且用户可以在工作流定义时定义该部分变量的值
因为参数的值存在多个来源,当参数名相同时,就需要会存在参数优先级的问题。DolphinScheduler 参数的优先级从高到低为:
- 本地参数 > 上游任务传递的参数 > 全局参数( 就近原则 )
在上游任务传递的参数中,由于上游可能存在多个任务向下游传递参数,当上游传递的参数名称相同时:
-
下游节点会优先使用值为非空的参数
-
如果存在多个值为非空的参数,则按照上游任务的完成时间排序,选择完成时间最早的上游任务对应的参数
3-4.数据源中心
数据源中心接入支持:
- MySQL
- PostgreSQL
- HIVE
- Spark
- Amazon Athena
这里简单拿MySQL做一下介绍,其它数据源基本参照官方文档配置即可
MySQL
- 数据源:选择 MYSQL
- 数据源名称:输入数据源的名称
- 描述:输入数据源的描述
- IP 主机名:输入连接 MySQL 的 IP
- 端口:输入连接 MySQL 的端口
- 用户名:设置连接 MySQL 的用户名
- 密码:设置连接 MySQL 的密码
- 数据库名:输入连接 MySQL 的数据库名称
- Jdbc 连接参数:用于 MySQL 连接的参数设置,以 JSON 形式填写

MariaDB [(none)]> use wow;
Database changed
MariaDB [wow]> show tables;
+---------------+
| Tables_in_wow |
+---------------+
| wow_info |
+---------------+
1 row in set (0.000 sec)
MariaDB [wow]> select * from wow_info;
+----+------+-------------+
| id | role | pinyin |
+----+------+-------------+
| 1 | fs | fashi |
| 2 | ms | mushi |
| 3 | ss | shushi |
| 4 | dz | daozei |
| 5 | ws | wuseng |
| 6 | xd | xiaode |
| 7 | sq | shengqi |
| 8 | zs | zhanshi |
| 9 | dk | siwangqishi |
| 10 | dh | emolieshou |
+----+------+-------------+
添加一个SQL任务
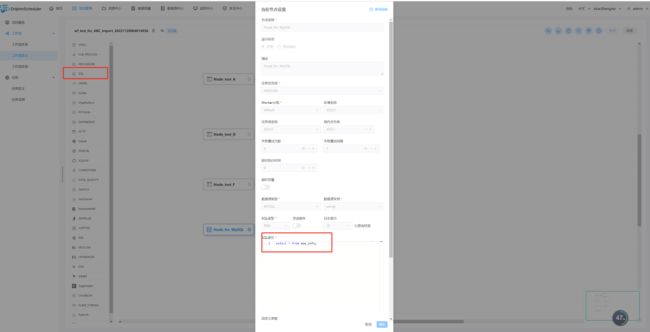
运行任务后,查看日志:

3-5.告警
告警通知支持方式:
- Telegram
- 钉钉告警
- 企业微信
- Webexteams
- 脚本告警
- Http告警
- 飞书告警
3-6.资源中心
资源中心通常用于上传文件、UDF 函数和任务组管理。 对于 standalone 环境,可以选择本地文件目录作为上传文件夹(此操作不需要Hadoop部署)。当然,你也可以 选择上传到 Hadoop 或者 MinIO 集群。 在这种情况下,您需要有 Hadoop(2.6+)或 MinION 等相关环境。
3-7.监控中心
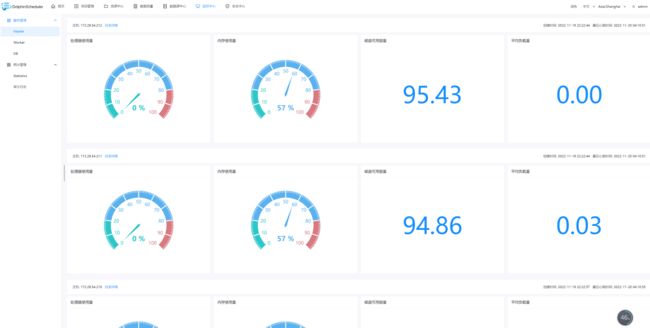
- 服务管理主要是对系统中的各个服务的健康状况和基本信息的监控和显示
- master信息
- worker信息
- Database信息
3-8.安全中心
安全中心只有管理员账户才有权限操作,分别有队列管理、租户管理、用户管理、告警组管理、worker分组管理、令牌管理等功能,在用户管理模块可以对资源、数据源、项目等授权
-
创建队列
- 队列是在执行 spark、mapreduce 等程序,需要用到“队列”参数时使用的
- 管理员进入安全中心 -> 队列管理页面,点击“创建队列”按钮,创建队列
-
添加租户
- 租户对应的是 Linux 的用户,用于 worker 提交作业所使用的用户。如果 linux 没有这个用户,则会导致任务运行失败。你可以通过修改 worker.properties 配置文件中参数 worker.tenant.auto.create=true 实现当 linux 用户不存在时自动创建该用户。worker.tenant.auto.create=true 参数会要求 worker 可以免密运行 sudo 命令
- 租户编码:租户编码是 Linux上 的用户,唯一,不能重复
- 管理员进入安全中心->租户管理页面,点击“创建租户”按钮,创建租户
-
创建普通用户
- 用户分为管理员用户和普通用户
- 管理员有授权和用户管理等权限,没有创建项目和工作流定义的操作的权限
- 普通用户可以创建项目和对工作流定义的创建,编辑,执行等操作
- 如果该用户切换了租户,则该用户所在租户下所有资源将复制到切换的新租户下
- 进入安全中心->用户管理页面,点击“创建用户”按钮,创建用户
- 用户分为管理员用户和普通用户
-
编辑用户信息
- 管理员进入安全中心->用户管理页面,点击"编辑"按钮,编辑用户信息
- 普通用户登录后,点击用户名下拉框中的用户信息,进入用户信息页面,点击"编辑"按钮,编辑用户信息
-
修改用户密码
- 管理员进入安全中心->用户管理页面,点击"编辑"按钮,编辑用户信息时,输入新密码修改用户密码
- 普通用户登录后,点击用户名下拉框中的用户信息,进入修改密码页面,输入密码并确认密码后点击"编辑"按钮,则修改密码成功
-
创建告警组
- 告警组是在启动时设置的参数,在流程结束以后会将流程的状态和其他信息以邮件形式发送给告警组
- 管理员进入安全中心->告警组管理页面,点击“创建告警组”按钮,创建告警组
-
令牌管理
-
由于后端接口有登录检查,令牌管理提供了一种可以通过调用接口的方式对系统进行各种操作
-
管理员进入安全中心->令牌管理页面,点击“创建令牌”按钮,选择失效时间与用户,点击"生成令牌"按钮,点击"提交"按钮,则选择用户的token创建成功
-
普通用户登录后,点击用户名下拉框中的用户信息,进入令牌管理页面,选择失效时间,点击"生成令牌"按钮,点击"提交"按钮,则该用户创建 token 成功
-
调用示例:
-
/** * test token */ public void doPOSTParam()throws Exception{ // create HttpClient CloseableHttpClient httpclient = HttpClients.createDefault(); // create http post request HttpPost httpPost = new HttpPost("http://127.0.0.1:12345/escheduler/projects/create"); httpPost.setHeader("token", "123"); // set parameters List<NameValuePair> parameters = new ArrayList<NameValuePair>(); parameters.add(new BasicNameValuePair("projectName", "qzw")); parameters.add(new BasicNameValuePair("desc", "qzw")); UrlEncodedFormEntity formEntity = new UrlEncodedFormEntity(parameters); httpPost.setEntity(formEntity); CloseableHttpResponse response = null; try { // execute response = httpclient.execute(httpPost); // response status code 200 if (response.getStatusLine().getStatusCode() == 200) { String content = EntityUtils.toString(response.getEntity(), "UTF-8"); System.out.println(content); } } finally { if (response != null) { response.close(); } httpclient.close(); } }
-
-
-
授予权限
- 授予权限包括项目权限,资源权限,数据源权限,UDF函数权限,k8s命名空间
- 管理员可以对普通用户进行非其创建的项目、资源、数据源、UDF函数、k8s命名空间。因为项目、资源、数据源、UDF函数、k8s命名空间授权方式都是一样的
- 对于用户自己创建的项目,该用户拥有所有的权限。则项目列表和已选项目列表中不会显示
- 管理员进入安全中心->用户管理页面,点击需授权用户的“授权”按钮
- 选择项目,进行项目授权
- 资源、数据源、UDF 函数授权同项目授权
-
Worker分组
每个 worker 节点都会归属于自己的 worker 分组,默认分组为 default。
在任务执行时,可以将任务分配给指定 worker 分组,最终由该组中的 worker 节点执行该任务-
新增 / 更新 worker 分组
-
打开要设置分组的 worker 节点上的 worker-server/conf/application.yaml 配置文件. 修改 worker 配置下的 groups 参数
-
groups 参数的值为 worker 节点对应的分组名称,默认为 default
-
如果该 worker 节点对应多个分组,则用连字符列出
-
worker: ...... groups: - default - group1 - group2 ......
-
-
也可以在运行中添加 worker 所属的 worker 分组而忽略 application.yaml 中的配置。修改步骤为 安全中心 -> worker分组管理 -> 点击 创建worker分组 -> 输入分组名称和worker地址 -> 点击确定
-
-
-
环境管理
-
在线配置 worker 运行环境,一个 worker 可以指定多个环境,每个环境等价于 dolphinscheduler_env.sh 文件.
-
默认环境为dolphinscheduler_env.sh文件
-
在任务执行时,可以将任务分配给指定 worker 分组,根据 worker 分组选择对应的环境,最终由该组中的 worker 节点执行环境后执行该任务
-
环境配置等价于dolphinscheduler_env.sh文件内配置
-
在工作流定义中创建任务节点选择 worker 分组和 worker 分组对应的环境,任务执行时 worker 会先执行环境在执行任务
-
注意: 当无法在任务定义或工作流运行对话框中使用你想要使用的环境时,请检查您已经选择worker,并且您要使用的环境已经关联到您选择的worker中
-
4.架构设计
4-1.元数据文档
-
用户 队列 数据源
- 一个租户下可以有多个用户;
- t_ds_user中的queue字段存储的是队列表中的queue_name信息,t_ds_tenant下存的是queue_id,在流程定义执行过程中,用户队列优先级最高,用户队列为空则采用租户队列;
- t_ds_datasource表中的user_id字段表示创建该数据源的用户,t_ds_relation_datasource_user中的user_id表示对数据源有权限的用户;
-
项目资源告警
- 一个用户可以有多个项目,用户项目授权通过
t_ds_relation_project_user表完成project_id和user_id的关系绑定; t_ds_projcet表中的user_id表示创建该项目的用户,t_ds_relation_project_user表中的user_id表示对项目有权限的用户;t_ds_resources表中的user_id表示创建该资源的用户,t_ds_relation_resources_user中的user_id表示对资源有权限的用户;t_ds_udfs表中的user_id表示创建该UDF的用户,t_ds_relation_udfs_user表中的user_id表示对UDF有权限的用户;
- 一个用户可以有多个项目,用户项目授权通过
-
项目 - 租户 - 工作流定义 - 定时
- 一个项目可以有多个工作流定义,每个工作流定义只属于一个项目;
- 个租户可以被多个工作流定义使用,每个工作流定义必须且只能选择一个租户;
- 一个工作流定义可以有一个或多个定时的配置;
-
工作流定义和执行
- 一个工作流定义对应多个任务定义,通过
t_ds_process_task_relation进行关联,关联的key是code + version,当任务的前置节点为空时,对应的pre_task_node和pre_task_version为0; - 一个工作流定义可以有多个工作流实例
t_ds_process_instance,一个工作流实例对应一个或多个任务实例t_ds_task_instance; t_ds_relation_process_instance表存放的数据用于处理流程定义中含有子流程的情况,parent_process_instance_id表示含有子流程的主流程实例id,process_instance_id表示子流程实例的id,parent_task_instance_id表示子流程节点的任务实例id,流程实例表和任务实例表分别对应t_ds_process_instance表和t_ds_task_instance表;
- 一个工作流定义对应多个任务定义,通过
4-2.架构设计
4-2-1.系统架构图
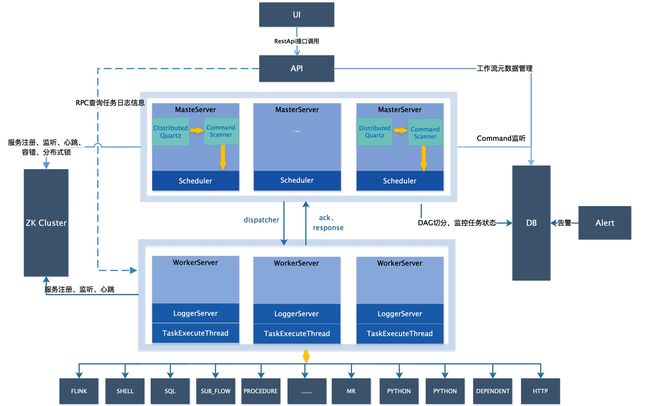
4-2-2.启动流程活动图
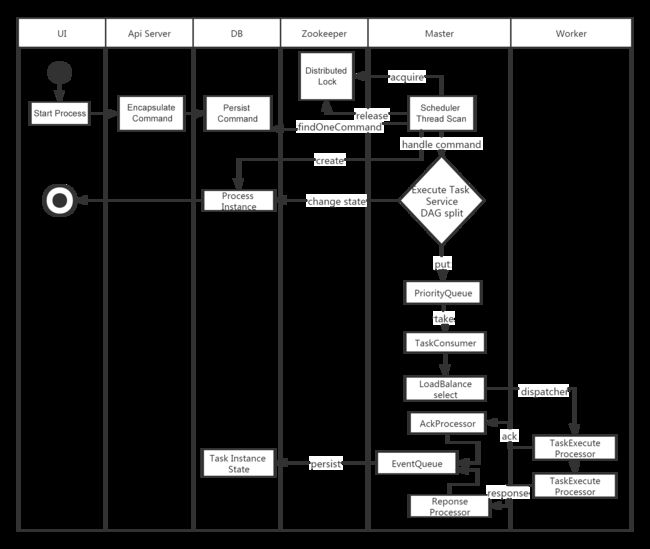
4-2-3.架构说明
- MasterServer
- MasterServer采用分布式无中心设计理念,MasterServer主要负责 DAG 任务切分、任务提交监控,并同时监听其它MasterServer和WorkerServer的健康状态。 MasterServer服务启动时向Zookeeper注册临时节点,通过监听Zookeeper临时节点变化来进行容错处理。 MasterServer基于netty提供监听服务。
- MasterServer服务主要包含:
- DistributedQuartz分布式调度组件,主要负责定时任务的启停操作,当quartz调起任务后,Master内部会有线程池具体负责处理任务的后续操作;
- MasterSchedulerService是一个扫描线程,定时扫描数据库中的
t_ds_command表,根据不同的命令类型进行不同的业务操作; - WorkflowExecuteRunnable主要是负责DAG任务切分、任务提交监控、各种不同事件类型的逻辑处理;
- TaskExecuteRunnable主要负责任务的处理和持久化,并生成任务事件提交到工作流的事件队列;
- EventExecuteService主要负责工作流实例的事件队列的轮询;
- StateWheelExecuteThread主要负责工作流和任务超时、任务重试、任务依赖的轮询,并生成对应的工作流或任务事件提交到工作流的事件队列;
- FailoverExecuteThread主要负责Master容错和Worker容错的相关逻辑;
- WorkerServer
- WorkerServer也采用分布式无中心设计理念,WorkerServer主要负责任务的执行和提供日志服务。 WorkerServer服务启动时向Zookeeper注册临时节点,并维持心跳。 WorkerServer基于netty提供监听服务
- WorkerServer服务主要包含:
- WorkerManagerThread主要负责任务队列的提交,不断从任务队列中领取任务,提交到线程池处理
- TaskExecuteThread主要负责任务执行的流程,根据不同的任务类型进行任务的实际处理
- RetryReportTaskStatusThread主要负责定时轮询向Master汇报任务的状态,直到Master回复状态的ack,避免任务状态丢失
- ZooKeeper
ZooKeeper服务,系统中的MasterServer和WorkerServer节点都通过ZooKeeper来进行集群管理和容错。另外系统还基于ZooKeeper进行事件监听和分布式锁。 我们也曾经基于Redis实现过队列,不过我们希望DolphinScheduler依赖到的组件尽量地少,所以最后还是去掉了Redis实现
- AlertServer
- 提供告警服务,通过告警插件的方式实现丰富的告警手段
- ApiServer
- API接口层,主要负责处理前端UI层的请求。该服务统一提供RESTful api向外部提供请求服务
- UI
- 系统的前端页面,提供系统的各种可视化操作界面
4-3.配置文件
DolphinScheduler目录结构:
├── LICENSE
│
├── NOTICE
│
├── licenses licenses存放目录
│
├── bin DolphinScheduler命令和环境变量配置存放目录
│ ├── dolphinscheduler-daemon.sh 启动/关闭DolphinScheduler服务脚本
│ ├── env 环境变量配置存放目录
│ │ ├── dolphinscheduler_env.sh 当使用`dolphinscheduler-daemon.sh`脚本起停服务时,运行此脚本加载环境变量配置文件 [如:JAVA_HOME,HADOOP_HOME, HIVE_HOME ...]
│ │ └── install_env.sh 当使用`install.sh` `start-all.sh` `stop-all.sh` `status-all.sh`脚本时,运行此脚本为DolphinScheduler安装加载环境变量配置
│ ├── install.sh 当使用`集群`模式或`伪集群`模式部署DolphinScheduler时,运行此脚本自动安装服务
│ ├── remove-zk-node.sh 清理zookeeper缓存文件脚本
│ ├── scp-hosts.sh 安装文件传输脚本
│ ├── start-all.sh 当使用`集群`模式或`伪集群`模式部署DolphinScheduler时,运行此脚本启动所有服务
│ ├── status-all.sh 当使用`集群`模式或`伪集群`模式部署DolphinScheduler时,运行此脚本获取所有服务状态
│ └── stop-all.sh 当使用`集群`模式或`伪集群`模式部署DolphinScheduler时,运行此脚本终止所有服务
│
├── alert-server DolphinScheduler alert-server命令、配置和依赖存放目录
│ ├── bin
│ │ └── start.sh DolphinScheduler alert-server启动脚本
│ ├── conf
│ │ ├── application.yaml alert-server配置文件
│ │ ├── bootstrap.yaml Spring Cloud 启动阶段配置文件, 通常不需要修改
│ │ ├── common.properties 公共服务(存储等信息)配置文件
│ │ ├── dolphinscheduler_env.sh alert-server环境变量配置加载脚本
│ │ └── logback-spring.xml alert-service日志配置文件
│ └── libs alert-server依赖jar包存放目录
│
├── api-server DolphinScheduler api-server命令、配置和依赖存放目录
│ ├── bin
│ │ └── start.sh DolphinScheduler api-server启动脚本
│ ├── conf
│ │ ├── application.yaml api-server配置文件
│ │ ├── bootstrap.yaml Spring Cloud 启动阶段配置文件, 通常不需要修改
│ │ ├── common.properties 公共服务(存储等信息)配置文件
│ │ ├── dolphinscheduler_env.sh api-server环境变量配置加载脚本
│ │ └── logback-spring.xml api-service日志配置文件
│ ├── libs api-server依赖jar包存放目录
│ └── ui api-server相关前端WEB资源存放目录
│
├── master-server DolphinScheduler master-server命令、配置和依赖存放目录
│ ├── bin
│ │ └── start.sh DolphinScheduler master-server启动脚本
│ ├── conf
│ │ ├── application.yaml master-server配置文件
│ │ ├── bootstrap.yaml Spring Cloud 启动阶段配置文件, 通常不需要修改
│ │ ├── common.properties 公共服务(存储等信息)配置文件
│ │ ├── dolphinscheduler_env.sh master-server环境变量配置加载脚本
│ │ └── logback-spring.xml master-service日志配置文件
│ └── libs master-server依赖jar包存放目录
│
├── standalone-server DolphinScheduler standalone-server命令、配置和依赖存放目录
│ ├── bin
│ │ └── start.sh DolphinScheduler standalone-server启动脚本
│ ├── conf
│ │ ├── application.yaml standalone-server配置文件
│ │ ├── bootstrap.yaml Spring Cloud 启动阶段配置文件, 通常不需要修改
│ │ ├── common.properties 公共服务(存储等信息)配置文件
│ │ ├── dolphinscheduler_env.sh standalone-server环境变量配置加载脚本
│ │ ├── logback-spring.xml standalone-service日志配置文件
│ │ └── sql DolphinScheduler元数据创建/升级sql文件
│ ├── libs standalone-server依赖jar包存放目录
│ └── ui standalone-server相关前端WEB资源存放目录
│
├── tools DolphinScheduler元数据工具命令、配置和依赖存放目录
│ ├── bin
│ │ └── upgrade-schema.sh DolphinScheduler元数据创建/升级脚本
│ ├── conf
│ │ ├── application.yaml 元数据工具配置文件
│ │ └── common.properties 公共服务(存储等信息)配置文件
│ ├── libs 元数据工具依赖jar包存放目录
│ └── sql DolphinScheduler元数据创建/升级sql文件
│
├── worker-server DolphinScheduler worker-server命令、配置和依赖存放目录
│ ├── bin
│ │ └── start.sh DolphinScheduler worker-server启动脚本
│ ├── conf
│ │ ├── application.yaml worker-server配置文件
│ │ ├── bootstrap.yaml Spring Cloud 启动阶段配置文件, 通常不需要修改
│ │ ├── common.properties 公共服务(存储等信息)配置文件
│ │ ├── dolphinscheduler_env.sh worker-server环境变量配置加载脚本
│ │ └── logback-spring.xml worker-service日志配置文件
│ └── libs worker-server依赖jar包存放目录
│
└── ui 前端WEB资源目录
Master Server相关配置:
位置:master-server/conf/application.yaml
| 参数 | 默认值 | 描述 |
|---|---|---|
| master.listen-port | 5678 | master监听端口 |
| master.fetch-command-num | 10 | master拉取command数量 |
| master.pre-exec-threads | 10 | master准备执行任务的数量,用于限制并行的command |
| master.exec-threads | 100 | master工作线程数量,用于限制并行的流程实例数量 |
| master.dispatch-task-number | 3 | master每个批次的派发任务数量 |
| master.host-selector | lower_weight | master host选择器,用于选择合适的worker执行任务,可选值: random, round_robin, lower_weight |
| master.heartbeat-interval | 10 | master心跳间隔,单位为秒 |
| master.task-commit-retry-times | 5 | 任务重试次数 |
| master.task-commit-interval | 1000 | 任务提交间隔,单位为毫秒 |
| master.state-wheel-interval | 5 | 轮询检查状态时间 |
| master.max-cpu-load-avg | -1 | master最大cpuload均值,只有高于系统cpuload均值时,master服务才能调度任务. 默认值为-1: cpu cores * 2 |
| master.reserved-memory | 0.3 | master预留内存,只有低于系统可用内存时,master服务才能调度任务,单位为G |
| master.failover-interval | 10 | failover间隔,单位为分钟 |
| master.kill-yarn-job-when-task-failover | true | 当任务实例failover时,是否kill掉yarn job |
| master.registry-disconnect-strategy.strategy | stop | 当Master与注册中心失联之后采取的策略, 默认值是: stop. 可选值包括: stop, waiting |
| master.registry-disconnect-strategy.max-waiting-time | 100s | 当Master与注册中心失联之后重连时间, 之后当strategy为waiting时,该值生效。 该值表示当Master与注册中心失联时会在给定时间之内进行重连, 在给定时间之内重连失败将会停止自己,在重连时,Master会丢弃目前正在执行的工作流,值为0表示会无限期等待 |
| master.master.worker-group-refresh-interval | 10s | 定期将workerGroup从数据库中同步到内存的时间间隔 |
Worker Server相关配置:
位置:worker-server/conf/application.yaml
| 参数 | 默认值 | 描述 |
|---|---|---|
| worker.listen-port | 1234 | worker监听端口 |
| worker.exec-threads | 100 | worker工作线程数量,用于限制并行的任务实例数量 |
| worker.heartbeat-interval | 10 | worker心跳间隔,单位为秒 |
| worker.host-weight | 100 | 派发任务时,worker主机的权重 |
| worker.tenant-auto-create | true | 租户对应于系统的用户,由worker提交作业.如果系统没有该用户,则在参数worker.tenant.auto.create为true后自动创建。 |
| worker.max-cpu-load-avg | -1 | worker最大cpuload均值,只有高于系统cpuload均值时,worker服务才能被派发任务. 默认值为-1: cpu cores * 2 |
| worker.reserved-memory | 0.3 | worker预留内存,只有低于系统可用内存时,worker服务才能被派发任务,单位为G |
| worker.alert-listen-host | localhost | alert监听host |
| worker.alert-listen-port | 50052 | alert监听端口 |
| worker.registry-disconnect-strategy.strategy | stop | 当Worker与注册中心失联之后采取的策略, 默认值是: stop. 可选值包括: stop, waiting |
| worker.registry-disconnect-strategy.max-waiting-time | 100s | 当Worker与注册中心失联之后重连时间, 之后当strategy为waiting时,该值生效。 该值表示当Worker与注册中心失联时会在给定时间之内进行重连, 在给定时间之内重连失败将会停止自己,在重连时,Worker会丢弃kill正在执行的任务。值为0表示会无限期等待 |
| worker.task-execute-threads-full-policy | REJECT | 如果是 REJECT, 当Worker中等待队列中的任务数达到exec-threads时, Worker将会拒绝接下来新接收的任务,Master将会重新分发该任务; 如果是 CONTINUE, Worker将会接收任务,放入等待队列中等待空闲线程去执行该任务 |
Alert Server相关配置
位置:alert-server/conf/application.yaml
| 参数 | 默认值 | 描述 |
|---|---|---|
| server.port | 50053 | Alert Server监听端口 |
| alert.port | 50052 | alert监听端口 |
4-4.负载均衡
负载均衡即通过路由算法(通常是集群环境),合理的分摊服务器压力,达到服务器性能的最大优化。
DolphinScheduler-Worker 负载均衡算法
DolphinScheduler-Master 分配任务至 worker,默认提供了三种算法:
加权随机(random)
平滑轮询(roundrobin)
线性负载(lowerweight)
默认配置为线性加权负载。
由于路由是在客户端做的,即 master 服务,因此你可以更改 master.properties 中的 master.host.selector 来配置你所想要的算法。
eg:master.host.selector=random(不区分大小写)
5.启动多ApiServer通过nginx代理实现连接高可用
当前访问dolphinscheduler为:
浏览器访问地址 http://ApiServerIp:12345/dolphinscheduler/ui 即可登录系统UI。
默认的用户名和密码是 :admin / dolphinscheduler123
为了避免ApiServer单点故障,虽然dolphinscheduler自身运行高可用,还在运作,但是没有了界面管理访问,影响也较大;所以启动多ApiServer通过nginx代理实现连接高可用,通过这个方案最终实现访问多入口,任务调度多master,加固整体稳定性
- 关闭dolphinscheduler集群
[dolphinscheduler@dolphinscheduler01 ~]$ cd /usr/local/apache-dolphinscheduler-3.1.1-bin/
[dolphinscheduler@dolphinscheduler01 apache-dolphinscheduler-3.1.1-bin]$ ./bin/stop-all.sh
- 修改install_env.sh配置
[dolphinscheduler@dolphinscheduler01 apache-dolphinscheduler-3.1.1-bin]$ vim /usr/local/apache-dolphinscheduler-3.1.1-bin/bin/env/install_env.sh
# 将apiServers配置项增加
apiServers="dolphinscheduler01,dolphinscheduler02,dolphinscheduler03"
- 使用install.sh重新安装启动dolphinscheduler
[dolphinscheduler@dolphinscheduler01 ~]$ cd /usr/local/apache-dolphinscheduler-3.1.1-bin/
[dolphinscheduler@dolphinscheduler01 apache-dolphinscheduler-3.1.1-bin]$ bash ./bin/install.sh
- 查看各组件服务
[dolphinscheduler@dolphinscheduler01 apache-dolphinscheduler-3.1.1-bin]$ for i in dolphinscheduler01 dolphinscheduler02 dolphinscheduler03;do echo "=== $i ===" && ssh $i "/usr/local/jdk1.8.0_171/bin/jps";done
=== dolphinscheduler01 ===
2884 AlertServer
2805 MasterServer
2921 ApiApplicationServer
2845 WorkerServer
=== dolphinscheduler02 ===
27908 MasterServer
27945 WorkerServer
27982 ApiApplicationServer
=== dolphinscheduler03 ===
27570 MasterServer
27607 WorkerServer
27646 ApiApplicationServer
此时已经部署完毕,验证访问:
当前访问dolphinscheduler为:
http://dolphinscheduler01:12345/dolphinscheduler/ui
http://dolphinscheduler02:12345/dolphinscheduler/ui
http://dolphinscheduler03:12345/dolphinscheduler/ui
默认的用户名和密码是 :admin / dolphinscheduler123
此时3个地址均可以访问

使用nginx负载均衡配置:
# upstream
upstream dolphinscheduler{
server 39.101.79.153:12345;
server 8.130.37.189:12345;
server 8.130.36.178:12345;
}
location /dolphinscheduler/ui {
proxy_http_version 1.1;
proxy_buffering off;
proxy_request_buffering off;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection "upgrade";
proxy_set_header Host $host;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_pass http://dolphinscheduler/dolphinscheduler/ui;
}
最后通过nginx代理的URL访问,此时ApiServer服务即使服务有一个异常,依然可以正常访问
