近端策略优化算法(PPO):RL最经典的博弈对抗算法之一「AI核心算法」
关注:决策智能与机器学习,深耕AI脱水干货

作者:Abhishek Suran
转载请联系作者
提要:PPO强化学习算法解析及其TensorFlow 2.x实现过程(含代码)
在本文中,我们将尝试理解Open-AI的强化学习算法:近端策略优化算法PPO(
Proximal Policy Optimization)。在一些基本理论之后,我们将使用TensorFlow 2.x实现PPO。
为什么PPO ?
因为PPO可以方便地克服以下两个问题。
策略更新不稳定:在许多策略梯度方法中,由于步长较大,策略更新不稳定,导致错误的策略更新,当这个新的错误策略被用于学习时,会导致更糟糕的策略。如果步骤很小,那么就会导致学习的缓慢。
数据效率低:很多学习方法都是借鉴现有经验,在梯度更新后丢弃经验。这使得学习过程变慢,因为神经网络需要大量的数据来学习。
PPO的核心理念
在早期的Policy梯度法中,目标函数类似于
![]()
但现在我们不用现行Policy的日志,而是用现行Policy与旧Policy的比率.

我们也将裁剪比例,并将两者的最小值,即b/w裁剪和未裁剪。
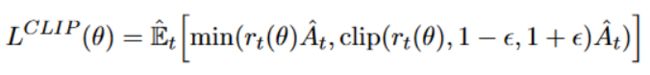
此压缩目标将限制大型策略更新,如下所示。
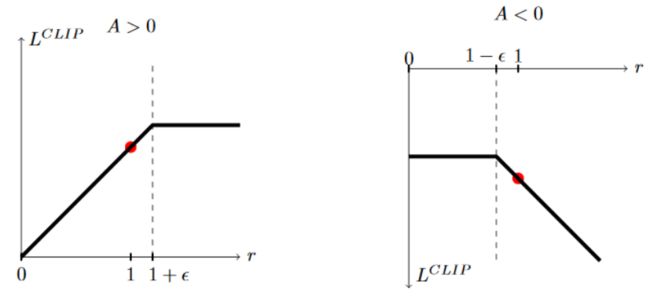
因此,最后的目标包括3个部分,
第一个是Lclip,
第二个是我们的批评者网的MSE,即预测的状态值和目标的平方损失。
第三部分是熵来鼓励探索。
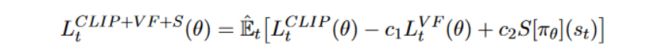
算法的步骤
游戏n步,存储状态,动作概率,奖励,完成变量。
基于上述经验,应用广义优势估计方法。我们将在编码部分看到这一点。
通过计算各自的损失,训练神经网络在某些时期的运行。
对完成训练的模型测试“m”轮。
如果测试片段的平均奖励大于你设定的目标奖励,那么就停止,否则就从第一步开始重复。
代码
神经网络:
在导入所需的库并初始化我们的环境之后,我们定义了神经网络,并且类似于actor评论家文章中的神经网络。
Actor-network将当前状态作为每个动作的输入和输出概率。
批评家网络输出一个状态的值。
class critic(tf.keras.Model):
def __init__(self):
super().__init__()
self.d1 = tf.keras.layers.Dense(128,activation='relu')
self.v = tf.keras.layers.Dense(1, activation = None)
def call(self, input_data):
x = self.d1(input_data)
v = self.v(x)
return v
class actor(tf.keras.Model):
def __init__(self):
super().__init__()
self.d1 = tf.keras.layers.Dense(128,activation='relu')
self.a = tf.keras.layers.Dense(2,activation='softmax')
def call(self, input_data):
x = self.d1(input_data)
a = self.a(x)
return a
行动选择:
我们定义代理类并初始化优化器和学习率。
我们还定义了一个clip_pram变量,它将用于actor丢失函数。
对于动作选择,我们将使用TensorFlow概率库,它将概率作为输入并将其转换为分布。
然后,我们使用分布来进行动作选择。
class agent():
def __init__(self):
self.a_opt = tf.keras.optimizers.Adam(learning_rate=7e-3)
self.c_opt = tf.keras.optimizers.Adam(learning_rate=7e-3)
self.actor = actor()
self.critic = critic()
self.clip_pram = 0.2
def act(self,state):
prob = self.actor(np.array([state]))
prob = prob.numpy()
dist = tfp.distributions.Categorical(probs=prob, dtype=tf.float32)
action = dist.sample()
return int(action.numpy()[0])
测试模型的知识:
这个功能将用来测试我们的代理的知识,并返回一集的总报酬。
def test_reward(env):
total_reward = 0
state = env.reset()
done = False
while not done:
action = np.argmax(agentoo7.actor(np.array([state])).numpy())
next_state, reward, done, _ = env.step(action)
state = next_state
total_reward += reward
return total_reward
训练循环:
我们将循环“步骤”时间,即我们将收集“步骤”时间的经验。
下一个循环是代理与环境交互的次数,我们将体验存储在不同的列表中。
在上述循环结束后,我们计算状态的值并加到最后一个状态的值,在广义优势估计方法中进行计算。
然后用广义优势估计方法对所有列表进行处理,得到收益、优势。
接下来,我们对网络进行10轮训练。
经过培训,我们将对agent进行5集的测试环境测试。
如果测试片段的平均奖励大于你设定的目标奖励,那么就停止,否则就从第一步开始重复。
tf.random.set_seed(336699)
agentoo7 = agent()
steps = 50
ep_reward = []
total_avgr = []
target = False
best_reward = 0
avg_rewards_list = []
for s in range(steps):
if target == True:
break
done = False
state = env.reset()
all_aloss = []
all_closs = []
rewards = []
states = []
actions = []
probs = []
dones = []
values = []
print("new episod")
for e in range(128):
action = agentoo7.act(state)
value = agentoo7.critic(np.array([state])).numpy()
next_state, reward, done, _ = env.step(action)
dones.append(1-done)
rewards.append(reward)
states.append(state)
#actions.append(tf.one_hot(action, 2, dtype=tf.int32).numpy().tolist())
actions.append(action)
prob = agentoo7.actor(np.array([state]))
probs.append(prob[0])
values.append(value[0][0])
state = next_state
if done:
env.reset()
value = agentoo7.critic(np.array([state])).numpy()
values.append(value[0][0])
np.reshape(probs, (len(probs),2))
probs = np.stack(probs, axis=0)
states, actions,returns, adv = preprocess1(states, actions, rewards, dones, values, 1)
for epocs in range(10):
al,cl = agentoo7.learn(states, actions, adv, probs, returns)
# print(f"al{al}")
# print(f"cl{cl}")
avg_reward = np.mean([test_reward(env) for _ in range(5)])
print(f"total test reward is {avg_reward}")
avg_rewards_list.append(avg_reward)
if avg_reward > best_reward:
print('best reward=' + str(avg_reward))
agentoo7.actor.save('model_actor_{}_{}'.format(s, avg_reward), save_format="tf")
agentoo7.critic.save('model_critic_{}_{}'.format(s, avg_reward), save_format="tf")
best_reward = avg_reward
if best_reward == 200:
target = True
env.reset()
env.close()
估计广义优势:
我们定义了一个预处理函数,它实现了GAE方法来计算返回值和优势。
初始化变量“g”为零,lambda为0.95。
我们通过反转奖励列表来循环奖励。
计算delta为(当前操作的奖励+下一个状态的gamma *值* done变量,对于终端状态为零-当前状态的值)。
计算变量“g”为(+ gamma * lambda * done变量* g)。
计算return为(g +当前状态值)。
反向返回列表,就像我们反向计算一样。
优势被计算为(返回值)。这里我们使用值[:-1]。毕竟,我们的值列表比所有其他列表大一个,因为为了计算目的,我们将状态的值加到了最后一个状态的旁边。
def preprocess1(states, actions, rewards, done, values, gamma):
g = 0
lmbda = 0.95
returns = []
for i in reversed(range(len(rewards))):
delta = rewards[i] + gamma * values[i + 1] * done[i] - values[i]
g = delta + gamma * lmbda * dones[i] * g
returns.append(g + values[i])
returns.reverse()
adv = np.array(returns, dtype=np.float32) - values[:-1]
adv = (adv - np.mean(adv)) / (np.std(adv) + 1e-10)
states = np.array(states, dtype=np.float32)
actions = np.array(actions, dtype=np.int32)
returns = np.array(returns, dtype=np.float32)
return states, actions, returns, adv
学习功能:
学习函数接受(在与环境交互期间存储或计算的状态、动作、优势、概率、返回值的数组)作为输入。
我们计算当前的概率和损失。批评家的损失是MSE。
这个函数使用渐变点击来执行渐变更新。
def learn(self, states, actions, adv , old_probs, discnt_rewards):
discnt_rewards = tf.reshape(discnt_rewards, (len(discnt_rewards),))
adv = tf.reshape(adv, (len(adv),))
old_p = old_probs
old_p = tf.reshape(old_p, (len(old_p),2))
with tf.GradientTape() as tape1, tf.GradientTape() as tape2:
p = self.actor(states, training=True)
v = self.critic(states,training=True)
v = tf.reshape(v, (len(v),))
td = tf.math.subtract(discnt_rewards, v)
c_loss = 0.5 * kls.mean_squared_error(discnt_rewards, v)
a_loss = self.actor_loss(p, actions, adv, old_probs, c_loss)
grads1 = tape1.gradient(a_loss, self.actor.trainable_variables)
grads2 = tape2.gradient(c_loss, self.critic.trainable_variables)
self.a_opt.apply_gradients(zip(grads1, self.actor.trainable_variables))
self.c_opt.apply_gradients(zip(grads2, self.critic.trainable_variables))
return a_loss, c_loss
演员损失:
Actor损失将当前概率、动作、优势、旧概率和批评家损失作为输入。
首先,我们计算熵和均值。
然后,我们循环遍历概率、优势和旧概率,并计算比率、剪切比率,并将它们追加到列表中。
然后,我们计算损失。注意这里的损失是负的因为我们想要进行梯度上升而不是梯度下降。
def actor_loss(self, probs, actions, adv, old_probs, closs):
probability = probs
entropy = tf.reduce_mean(tf.math.negative(tf.math.multiply(probability,tf.math.log(probability))))
#print(probability)
#print(entropy)
sur1 = []
sur2 = []
for pb, t, op in zip(probability, adv, old_probs):
t = tf.constant(t)
op = tf.constant(op)
#print(f"t{t}")
#ratio = tf.math.exp(tf.math.log(pb + 1e-10) - tf.math.log(op + 1e-10))
ratio = tf.math.divide(pb,op)
#print(f"ratio{ratio}")
s1 = tf.math.multiply(ratio,t)
#print(f"s1{s1}")
s2 = tf.math.multiply(tf.clip_by_value(ratio, 1.0 - self.clip_pram, 1.0 + self.clip_pram),t)
#print(f"s2{s2}")
sur1.append(s1)
sur2.append(s2)
sr1 = tf.stack(sur1)
sr2 = tf.stack(sur2)
#closs = tf.reduce_mean(tf.math.square(td))
loss = tf.math.negative(tf.reduce_mean(tf.math.minimum(sr1, sr2)) - closs + 0.001 * entropy)
#print(loss)
return loss
这就是编码。现在让我们看看你的代理不学习的原因和一些提示。
执行时需要注意的事项
在编写RL时,需要记住以下几点。
神经元的数量,隐藏层,学习速率对学习有巨大的影响。
张量和数组的形状应该是正确的。很多时候,实现是正确的,代码可以工作,但是代理没有学到任何东西,仅仅因为张量的形状是不正确的,并且当对那些张量进行操作时给出了错误的结果
相关资料
您可以在这里找到本文的完整代码:https://arxiv.org/abs/1707.06347
PPO相关经典论文下载,请在公众号回复:20201203
PPO视频讲解,B站视频(英文字幕)https://www.bilibili.com/video/BV1NW411U7ML?from=search&seid=1258895800860502283
历史精华好文
专辑1:AI工程落地
专辑2:AI核心算法
专辑3:AI优质资源
交流合作
请加微信号:yan_kylin_phenix,注明姓名+单位+从业方向+地点,非诚勿扰。
