python实现K近邻算法
k近邻算法是机器学习中一种基础的分类与回归算法,通过输入新实例的特征向量,计算与新实例距离最为接近的k个训练集样本,之后在k个训练集样本中通过一定的选举策略确定出新实例的类别或者数值,从而达到分类或者回归的目的。
在知道了k近邻算法的大体思路后,便可以总结出k近邻算法的三要素。
1 k值的选取
对于k近邻算法而言,新实例受到样本点的影响取决于k值的大小,当k值很小时,决策新实例的样本点的个数就会很少,新实例受到距离较近的样本点的影响就越大,而当新实例附近的样本点刚好是噪音,那么就会导致新实例的预测值出错、模型过拟合。当k值过大时,决策新实例的样本点的个数就会越多,模型复杂度就会越简单,而此时距离新实例较远的样本点也会影响到新实例的预测,从而导致预测值的出错。因此在k值的选取上应对不同的k值采取交叉验证的方式计算出各个k值的正确率从而选取正确率最大的那一个k值。
2 样本点与实例之间如何度量
在确定好距离实例最近的k个样本点的个数之后,接下来就是要寻找距离最近的k个样本,而衡量最近的k个样本的依据就是样本点到实例之间的距离。对于每一个样本点而言其可能具有多个特征向量,并且每个特征向量可能拥有不同的定义域,因此对于数值型的特征向量而言在计算距离时需要先对特征向量做归一化操作,从而使每一维度的特征向量对距离的影响相同。对于非数值型的特征向量,如图片类型,可先对图片做灰度处理,从而转化成为数值类型数据。
在计算距离时通常采用欧氏距离,对于样本点![]() 的特征向量可表示为
的特征向量可表示为![]() ,那么样本点
,那么样本点 相对于样本点
相对于样本点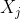 的距离可表示为如下公式。当p=2时此距离为欧氏距离。
的距离可表示为如下公式。当p=2时此距离为欧氏距离。

3 选举策略
在确定好k个距离实例点最近的样本点后,接下来就需要通过这些样本点确定实例点的类别或者数值。对于分类问题,可采用多数表决法,即实例点的类别和k个样本点中数最多的样本类别一致。对于回归问题,实例点的数值可采取样本点的均值。
4 kd树
对于数据量小的分类问题而言,在寻找距离实例点最近的k个样本点时,可采取逐个计算距离。但是对于数据量大的分类问题而言,逐个计算样本点与实例点的距离显然时间复杂度会很大,为了减小时间复杂度,因此引入kd树。
kd树实际就是一个多维的平衡二叉树,其每一个节点代表了一个k维的样本点,对于每一个深度为i的非叶节点,可将样本集在第i维上分为小于该非叶节点和大与该非叶节点的两部分,其中第i维称作切分轴,该非叶节点称作切分点。
因此构建kd树时首先需要根据此时kd树的深度确定切分轴i,然后在样本集的第i维上取中位数的样本点作为切分点(为了保证左右子树的高度之差小于等于1),将样本集划分为两部分,之后重复此操作,直至划分到叶节点。
我们用大根堆存放k个近邻样本点,当kd树中的样本个数大于k时,首先判断队中样本是否大于等于k个,若不是则将该样本点插入大根堆中,若是则需比较当前样本点与大根堆的堆顶样本点的大小,若大于堆顶样本则不属于K个近邻样本,若小于堆顶样本,则将大根堆中的样本做替换操作。
#kd树类
class KDTree(object):
def __init__(self,X,y = None):
"""
kd树的构造函数,即初始化
:param X:输入特征集,n_samples * n_features
:param y: 输入标签集 1 * n_samples
"""
self.root = None
self.y_valid = False if y is None else True
self.creat(X,y)
def creat(self,X,y = None):
"""
构建KD树
:param X:特征输入集
:param y:输入标签集
:return: KDnode
"""
def create_(X,axis,parent = None):
"""
递归生成KD树
:param X: 合并标签后输入集
:param axis: 分割轴
:param parent: 父节点
:return: KDnode
"""
n_samples = np.shape(X)[0] # 样本点的个数
if n_samples == 0:
return None
mid = n_samples >> 1 # 右移操作,切分点的下标
partition_sort(X,mid,key = lambda x:x[axis]) # 在第axis维上的排序函数,
if self.y_valid: # 标签存在
# KDnode为样本点(特征集,标签,切分轴,父节点)
kd_node = KDNode(X[mid][:-1],X[mid][-1],axis = axis,parent = parent) # #
else: # 对于无标签样本
kd_node = KDNode(X[mid],axis = axis,parent = parent)
next_axis = (axis + 1) % k_dimenssions #递归下一层的切分轴
kd_node.left = create_(X[:mid],next_axis,kd_node) #递归左子树
kd_node.right = create_(X[mid + 1:],next_axis,kd_node) # 递归右子树
return kd_node # 返回样本点
print("build KD-tree")
k_dimenssions = np.shape(X)[1] # kd树深度 = 样本点特征向量维数
if y is not None:
X = np.hstack((np.array(X),np.array([y]).T)).tolist() # 将样本点的特征向量与标签进行拼接
self.root = create_(X,0) # 从根节点构造kd树
def search_knn(self,point,k,dist = None):
"""
在kd树中搜索k个最近邻样本
:param point: 实例点
:param k: 最近邻样本个数
:param dist: 度量方式
:return:
"""
def search_knn_(kd_node):
"""
搜索k近邻样本
:param kd_node:KDNode
:return:
"""
if kd_node is None:
return
data = kd_node.data
distance = p_dist(data) # 样本点与实例之间的距离
if len(heap) < k: # 大根堆中样本点个数小于k时
# 向大根堆中插入元素
max_heappush(heap,(kd_node,distance))
elif distance < heap[0][1]: # 大根堆中样本点个数大于k时,且该实例的距离小于大根堆中堆顶样本
# 替换大根堆中较大的样本点
max_heapreplace(heap,(kd_node,distance))
axis = kd_node.axis
# 当前样本点与输入实例所形成的超球体包含堆顶样本点或者 堆中样本点的个数小于k
if abs(point[axis] - data[axis]) < heap[0][1] or len(heap) < k:
# 搜索左孩子样本点
search_knn_(kd_node.left)
# 搜索有孩子样本点
search_knn_(kd_node.right)
# 当实例axis维上的数值小于kd树当前节点中样本点axis维上的数值时
elif point[axis] < data[axis]:
# 在该节点的左子树上搜索
search_knn_(kd_node.left)
else:
# 在该节点的右子树上搜索
search_knn_(kd_node.right)
if self.root is None:
raise Exception("kd-tree must not be null")
if k < 1:
raise ValueError("k must be greater than 0")
# 距离的度量方式
if dist is None:
p_dist = lambda x:norm(np.array(x) - np.array(point))
else:
p_dist = lambda x:dist(x,point)
# 用大根堆存放距离实例最近的k个样本点
heap = []
# 从根节点开始搜索k个样本点
search_knn_(self.root)
# 升序排放返回大根堆中k个样本点
return sorted(heap,key = lambda x:x[1])
5 验证程序正确性
if __name__ == '__main__':
"模型测试"
N =100000 # 样本数量
X = [[np.random.random() * 100 for _ in range(3)] for _ in range(N)] # N * 3 样本集
kd_tree = KDTree(X) # 构造kd树
for x in X[:10]: # 测试10个实例的最近样本点
# res1中存放的是kd_tree中距离x最近的20个预测样本点的距离
res1 = ([list(node[0].data) for node in kd_tree.search_knn(x,20)])
# 计算kd_tree中所有样本点与实例x的距离distances
distances = norm(np.array(X) - np.array(x),axis = 1)
# res2中存放的是distances中前20个数值最小的距离
res2 = ([list(X[i]) for _,i in sorted(zip(distances,range(N)))[:20]])
# 如果 res1 == res2,表示预测结果与真实计算结果一致
if all(x in res2 for x in res1):
print('correct ^_^ ^_^')
else:
print('error >_< >_<')
print('\n')6 实验结果
