学习笔记之——vs2015+opencv2.4.13实现SIFT、SURF、ORB
此博文为本人写的第一篇博文,写博文的主要目的呢有两个:第一就是对自己做过的工作进行总结;第二就是希望跟志同道合的人相互学习交流~
本篇博文主要是我自学SIFT、SURF、ORB三种算法(三种特征描述子)过程的笔记以及运行的代码。博文主要是对于三种算法的 归纳以及加入我自己的一些思考与理解。当然里面还有一些出现的问题不知道怎么解决的,也放到博文里面(希望有大神可以在评论不吝赐教),后续也会继续更新,请广大读者批评指正谢谢。
在opencv3中,这三个算子都转移到一个名为xfeature2d的第三方库中,而在opencv2中这三个算子在nonfree库中,为此我还特意把opencv3.2改为opencv2.4.9和2.4.13。
关于在vs下配置opencv可参考https://blog.csdn.net/poem_qianmo/article/details/19809337。个人感觉这个教程比较好,注意版本号不一样修改对应的lib就好了。
一.SIFT
Scale Invariant Feature Transform(SIFT) 尺度不变特征变换。SIFT特征用于描述图像这种的局部特征。是一种关键点(或者叫做特征点)的检测和描述的算法。SIFT算法应用于图像特征点的提取,首先建立图像的尺度空间表示,接着在尺度空间中搜索图像的极值点,通过这些极值点(也称关键点,特征点。包含三个主要信息:位置、尺度、方向),从而建立特征描述向量。通过特征描述向量来做图像识别与检测方面的问题。
SIFT由David Lowe提出,且已经申请了专利保护。
SIFT的算法流程图如下图所示:

SIFT具有以下特点:
(1)SIFT特征具有旋转、尺度、平移、视角及亮度的不变性。
(2)SIFT特征对参数调整鲁棒性好,在进行特征描述时,根据场景需要可调整适宜的特征点数量,以便进行特征分析。
局部不变性包括尺度不变性与旋转不变性。尺度不变性描述的是物体视觉上的远近与目标的认知分析无关。而旋转不变性描述的是物体发生旋转操作与目标的认知分析无关,它强调目标特征的多角度信息特征
尺度不变性
SIFT的尺度不变性是指:若不同的尺度下都有相同的关键点,那么在不同的尺度的输入图像下都可以检测出关键点来进行匹配。
尺度不变性:人不管物体离得远还是近,都能够对其进行辨认。
将物体的不同尺度下的图像都提供给机器,让机器能够对物体在不同的尺度下有一个统一的认知。在建立统一认知的过程中,要考虑的就是在图像不同的尺度下都存在的特征点。这一过程在实际中,通过图像金字塔,将不同分辨率的信息都存储下来。
图像的尺度空间表达就是图像在所有尺度下的描述。
SIFT算法的步骤
本人主要是参考以下四篇博客来学习SIFT特征,下面的步骤是结合自己的理解来写的。
https://blog.csdn.net/abcjennifer/article/details/7639681#comments
https://blog.csdn.net/h2008066215019910120/article/details/17229439
https://blog.csdn.net/Kevin_cc98/article/details/78528619
https://blog.csdn.net/zddblog/article/details/7521424
1.构建尺度空间
(首先在图像的预处理中包括了对图像作灰度变换以及归一化处理,归一化处理是为了应对光照强度变化的鲁棒性)。
尺度空间理论的基本思想是:在图像信息处理模型中引入一个被视为尺度的参数,通过连续变化尺度参数获得多尺度下的尺度空间表示序列,对这些序列进行尺度空间主轮廓的提取,并以该主轮廓作为一种特征向量,实现边缘、角点检测和不同分辨率上的特征提取等。而在SIFT中尺度空间理论的目的是模拟图像数据的多尺度特征。(尺度空间的构建说白了就是通过图像金字塔对原图像进行降采样获得)
Laplacion(拉普拉斯)算子在边缘检测中得到了广泛的应用。 由于拉斯算子通过对图像进行微分操作实现边缘检测,所以对离散点和噪声比较敏感,于是,先对图像进行高斯卷积滤波降噪处理,再采用拉斯算子进行边缘检测,就可以提高算子对噪声和离散点的鲁棒性。这就是LOG算子(高斯尺度规范化或叫高斯拉普拉斯(Laplacion of Gaussian))的由来。(具体的推导与描述可以参见:https://blog.csdn.net/Kevin_cc98/article/details/78528619)
对于二维图像的尺度空间L(x,y,σ)可以定义为(LOG算子)(直观理解,一个图像的尺度空间就是通过下式来描述):

其中,I(x,y)为原图像,xy为空间坐标;G(x,y,σ)为尺度因子为σ的高斯卷积核函数。高斯卷积核是唯一可以产生多尺度空间的核,且是唯一线性核。而尺度因子描述的是图像的平滑程度,小尺度对应于图像中的细节部分(高分辨率),大尺度对应于图像的轮廓部分(低分辨率)。

(关于高斯滤波之类的,这里有比较好的描述https://blog.csdn.net/zddblog/article/details/7521424)
尺度空间模型在实现的时候,使用高斯金字塔表示。高斯金字塔的构建分为两部分:
①对图像做不同程度的降噪(对于每个octave里的不同图片做高斯滤波)
②对图像做隔点采样(就是降采样获得不同的octave)

通过对原始图像的降采样可以获得图像金字塔,而为了让尺度体现其连续性,高斯金字塔在传统图像金字塔简单的降采样的基础上加上了高斯滤波。对高斯金字塔中的每层(每个octave)的第一张图使用不同参数做高斯模糊处理,使得金字塔的每层(每个octave)都含有多张高斯模糊图像(也叫层interval)。
为了保证尺度不变(scale-invariant),对于一幅图像I,通过图像金字塔建立其在不同尺度(scale)的图像(就是每一层octave),每层octave都有对应的特征点,也即是在每个尺度下都有对应的特征点。第一个octave为原图像的大小,后面的每一个octave都为上一个octave降采样的结果,为上一个octave的1/4(长宽分别减半)。
通过隔点采样获得尺度空间,而在隔点采样之前,会通过高斯低通滤波器(抗混叠)进行滤波处理。而在SIFT中,采用的高斯核其方差是可以变化的,每次采样前(到下一层octave前),都通过不同的方程对图像进行一系列的高斯卷积处理,这一系列的滤波构成图像金字塔中每一层octave中的一系列图。
那么层中方差和层与层之间方差有什么关系呢。层中方差满足σ, k*σ, k*k*σ的关系,层间方差σ, 1*σ, 2*σ,比如第一层是σ, k*σ, k*k*σ,第二层就为2*σ,2* k*σ, 2*k*k*σ。但是这一处理还没结束,上面处理得到是高斯尺度空间,只有把层中的每两楼还要进行相减才能得到最后的DOG尺度空间(后面有说到DOG,高斯差分尺度空间,它是为了有效的在尺度空间检测到稳定的关键点)。

图像金字塔是一系列以金字塔形状排列的、分辨率逐步降低的图像集合。(上一层图像是下一层图像宽度和长度的一半)。通过采用图像金字塔,将不同分辨率的信息存储下来进而实现尺度不变。
在Lowe的论文中,建议在建立尺度空间前先对原始图像长宽扩展一倍。由于在检测极值点前对原始图像的高斯平滑会导致图像丢失高频信息,所以通过图像金字塔的向上采样技术可以将原始图像长宽扩展一倍,使得原始图像信息可以得到保留,增加特征点数量。
图像金字塔的说明
关于图像金字塔可以参考博文(https://blog.csdn.net/poem_qianmo/article/details/26157633)本人学习opencv主要也是跟着浅墨的博客以及他的书籍来学的,在此对他表示十分的感谢。
但是这里要强调一点,我一开始对于图像金字塔存在一个误区,就是觉得一张图,按照传统的分为好多层塔,上一层塔是对其下一层塔的降采样获得,但在SIFT的图像金字塔应该是这样的:在图像金字塔中分为很多层,每一层叫做一个octave(中文直译“八度音阶”),每一个octave中又有几张尺度不同的图片,在sift算法中,同一个octave层中的图片尺寸(即大小)相同,但是尺度(即模糊程度)不同,而不同的octave层中的图片尺寸大小也不相同,因为它是由上一层图片降采样得到的。
注意区分关键字:尺寸指大小,而尺度指模糊程度
由图片的size决定是几层塔(几个octave),每个octave里面有几张(层)图(一般是3~5张)。0塔的第0张图是原始图像(或者你double)后的图像,往上每一层图是对其下一层进行laplacian变换。塔间(octave间)的图片只是降采样关系。例如:1塔的第0层可以由0塔的第3层降采样得到。而0塔的第三层是第二层进行拉斯变换得到的。
(注意这两段的“层”“张”“塔”“octave”之间混用的关系)。
由于在实验中发现,尺度归一化的高斯拉普拉斯函数的极大值和极小值相对于其他特征提取函数(角点等等)能够产生最稳定的图像特征。然后发现,高斯差分函数与尺度归一化的高斯拉普拉斯函数非常近似。在计算图像特征中的关键点时,对于连续的图像,为了有效的在尺度空间检测到稳定的关键点,提出了高斯差分尺度空间(DOG scale-space)(一说是LOG可以很好地找到关键点,但是运算量过大,可以通过DOG图像的极大极小值来近似计算)

使用高斯金字塔每层(每个octave)中相邻上下两层图像相减,得到高斯差分图像,然后进行极值检测。

2.提取特征点
SITD特征点包含尺度以及方向。特征点是由DOG空间的局部极值点组成的。特征点的检测分为疑似关键点的检测以及去除伪关键点。
特征点的初步检测是通过同一组内(同一个octave内)各DOG相邻两层图像之间比较完成的。为了寻找尺度空间的极值点,每一个采样点要和它所有的相邻点比较,看其是否比它的图像域和尺度域的相邻点大或者小。如图所示,中间的检测点和它同尺度的8个相邻点和上下相邻尺度对应的9×2个点共26个点比较,以确保在尺度空间和二维图像空间都检测到极值点。 一个点如果在DOG尺度空间本层以及上下两层的26个领域中是最大或最小值时,就认为该点是图像在该尺度下的一个特征点。

同一组中的相邻尺度(由于k的取值关系,肯定是上下层)之间进行寻找,如图所示(S=3时):

在极值比较的过程中,每一组(octave)首末两张图是无法进行比较的,为了满足尺度变换的连续性。在每一层(octave)的 顶层继续用高斯模糊生成了3幅图像。所以,在DOG金字塔每组需S+2层图像,而DOG金字塔由高斯金字塔相邻两层相减得到,则高斯金字塔每组需S+3层图像,实际计算时S在3到5之间。当S=3时:

去除不好的特征点。由于初步初步获得的疑似关键点在大部分的场景中并不能直接进行特征描述,高斯差分算子对边缘及噪声相对敏感,会产生伪边缘信息和伪极值响应信息。不符合要求的点主要有两种:对比度低的特征点和不稳定的边缘响应点。两者的本质就是DOG局部曲率非常不对称。
在以下博文都有详细介绍,我个人觉得,只需要知道它有这一步,以及这一步大概怎么做的,为什么要这样做就好了,所以此处不详细列出原理(大概也是我看不懂的原因吧哈哈哈哈),有兴趣的读者可以详细阅读以下链接:
https://blog.csdn.net/abcjennifer/article/details/7639681#comments
https://blog.csdn.net/zddblog/article/details/7521424
特征点的方向。通过尺度空间获得了尺度不变性特征的提取,还要实现旋转不变性,需要对特征点的方向重新分配。利用关键点邻域像素的梯度方向分布特性为每个关键点指定方向参数,使算子具备旋转不变性。

上式为(x,y)处梯度的模以及方向。其中尺度L所用的尺度为每个关键点各自所在的尺度。
由梯度方向直方图确定主梯度方向。梯度方向的范围为0~360度,对其邻域内的梯度方向进行统计。在梯度方向上将整个圆周360度平均分为36份,每份10度。在以关键点为中心的邻域窗口内进行采样,并用直方图统计邻域像素的梯度方向。在Lowe的论文中还提到了要使用高斯函数对直方图进行平滑,减少突变的影响。直方图的峰值则代表了该关键点处邻域梯度的主方向,即作为该关键点的方向。(直方图中的峰值就是主方向,其他的达到最大值80%的方向可作为辅助方向)。至此,每个图像的关键点有三个信息:位置,所处尺度,方向,由此可以确定一个SIFT特征区域。

(对于同一梯度值的多个峰值的关键点位置,在相同位置和尺度将会有多个关键点被创建但方向不同。仅有15%的关键点被赋予多个方向,但可以明显的提高关键点匹配的稳定性。实际编程实现中,就是把该关键点复制成多份关键点,并将方向值分别赋给这些复制后的关键点,并且,离散的梯度方向直方图要进行插值拟合处理,来求得更精确的方向角度值)
特征向量的生成。上面只是获得了特征点,还要加一步生成特征向量(见后面程序)。关键点描述子的生成是指把图像中所描述的关键点性质特征生成向量的过程。与此同时,采用位置,尺度和方向的描述不足以实现两幅图的匹配,同时为进一步实现旋转不变以及关照等的影响,实际中还采用了128维的向量对特征点进行描述,在匹配的时候就仅比较两幅图的128维向量就可以了。
(1)首先将坐标轴旋转为关键点的方向,以确保旋转不变性。

(2)生成128维特征描述子
以关键点为中心选取8*8的窗口,如上左图所示。上左图的中央为当前关键点的位置,每个小格代表关键点邻域所在尺度空间的一个像素,利用公式求得每个像素的梯度幅值与梯度方向,箭头方向代表该像素的梯度方向,箭头长度代表梯度模值,然后用高斯窗口对其进行加权运算。
上左图中蓝色的圈代表高斯加权的范围(越靠近关键点的像素梯度方向信息贡献越大)。然后在每4×4的小块上计算8个方向的梯度方向直方图,绘制每个梯度方向的累加值,即可形成一个种子点,如上右图所示。一个关键点由2×2共4个种子点组成,每个种子点有8个方向向量信息(所以有2*2*8=32维)。这种邻域方向性信息联合的思想增强了算法抗噪声的能力,同时对于含有定位误差的特征匹配也提供了较好的容错性。
将上图的区域扩展到16*16(如下图所示,就可以获得所需要的128维向量)。在每个4*4的1/16象限中,通过加权梯度值加到直方图8个方向区间中的一个,计算出一个梯度方向直方图。这样就可以对每个feature形成一个4*4*8=128维的描述子,每一维都可以表示4*4个格子中一个的scale/orientation。

个人理解:以特征点为中心在附近选16*16的像素。16*16的像素阵列中,每4*4小块做8个方向的梯度方向直方图,然后就获得一个4*4的区间,每个区间里面有8个统计的方向。所以为4*4*8=128维特征。
(3)将这个128维的向量归一化之后,就进一步去除了光照的影响。
关键点描述子的生成步骤

放两张图来显示特征点与特征向量的区别:第一张是图像的关键点的特征,采用的是一个个圆来描述,直径代表尺寸,一条半径是方向,圆中心是位置。第二张是上图特征的128个描述子,取16*16方格,计算梯度,统计,从图中看出各个尺度的方格大小是不一样的。
(博文https://blog.csdn.net/h2008066215019910120/article/details/17229439的这两张图很好的描述了特点与特征向量的区别)


3.根据特征向量(描述子)进行匹配
opencv中,特征向量的匹配分为FlannBasedMatcher和BruteForceMatcher两种匹配器(后文会描述到,这里就先不介绍,不然一下知识点太多容易混乱)。反正就是你获得两张图片的特征向量后,你要对它进行匹配咯(数学推导我也没有看hhh)
程序
先给出测试的图片:


代码如下:
-
#include -
#include -
#include -
using namespace std; -
using namespace cv; -
//计算图像的SIFT特征及匹配 -
int main() -
{ -
Mat srcImage1 = imread("hand1.jpg", 1); -
Mat srcImage2 = imread("hand2.jpg", 1); -
//CV_Assert用于判断输入数据的合法性,当该函数为false时,返回一个错误信息 -
CV_Assert(srcImage1.data != NULL && srcImage2.data != NULL); -
//转换为灰度图并做归一化 -
Mat grayMat1, grayMat2; -
cvtColor(srcImage1, grayMat1, CV_BGR2GRAY); -
normalize(grayMat1, grayMat1, 0, 255, NORM_MINMAX); -
cvtColor(srcImage2, grayMat2, CV_BGR2GRAY); -
normalize(grayMat2, grayMat2, 0, 255, NORM_MINMAX); -
//定义SIFT描述子 -
SiftFeatureDetector detector; -
//这个对象顾名思义就是SIFT特征的探测器,用它来探测图片中SIFT点的特征,存到一个KeyPoint类型的vector中。 -
/*keypoint只是保存了opencv的sift库检测到的特征点的一些基本信息,但sift所提取出来的特征向量其实不是在这个里面,特征向量通过SiftDescriptorExtractor 提取, -
结果放在一个Mat的数据结构中。这个数据结构才真正保存了该特征点所对应的特征向量。*/ -
//得到keypoint只是达到了关键点的位置,方向等信息,并无该特征点的特征向量,要想提取得到特征向量就还要进行SiftDescriptorExtractor 的工作。 -
SiftDescriptorExtractor extractor; -
//建立了SiftDescriptorExtractor 对象后,通过该对象,对之前SIFT产生的特征点进行遍历,找到该特征点所对应的128维特征向量。 -
//SiftDescriptorExtractor对应于SIFT算法中特征向量提取的工作,通过他对关键点周围邻域内的像素分块进行梯度运算,得到128维的特征向量。 -
//特征点的检测,并放入keypoint类型的vector中 -
vector< KeyPoint> keypoints1; -
detector.detect(grayMat1, keypoints1); -
vector< KeyPoint> keypoints2; -
detector.detect(grayMat2, keypoints2); -
//计算特征点描述子 -
Mat descriptors1; -
extractor.compute(grayMat1, keypoints1, descriptors1); -
Mat descriptors2; -
extractor.compute(grayMat2, keypoints2, descriptors2); -
//特征点匹配 -
//两幅图片的特征向量被提取出来后,我们就可以使用BruteForceMatcher对象对两幅图片的descriptor进行匹配,得到匹配的结果到matches中 -
vectormatches; -
BruteForceMatcher< L2> matcher; -
matcher.match(descriptors1, descriptors2, matches); -
//二分排序 -
int N = 80; -
nth_element(matches.begin(), matches.begin() + N - 1, matches.end()); -
//方法是,nth位置的元素放置的值就是把所有元素排序后在nth位置的值.把所有不大于nth的值放到nth的前面,把所有不小于nth的值放到nth后面. -
matches.erase(matches.begin() + N, matches.end());//去除特征点不匹配情况。erase(pos,n); 删除从pos开始的n个字符。 -
//绘制检测结果 -
Mat resultMat; -
drawMatches(srcImage1, keypoints1, srcImage2, keypoints2, matches, resultMat); -
imshow("jieguo", resultMat); -
waitKey( ); -
return 0; -
}
程序是可以正常运行的,出来的结果如下:

但是一旦按下“ESC”或者“0”时,就会出现以下错误:

如果只是按“shift+F5”是不会报错的。
至今这个问题还没有找到答案。。。。重新建立工程配置了opencv2.4.9也会出现同样的问题。要是有大佬知道怎么解决请写在评论处
(个人感觉应该是调用sift过程中出现的问题,因为我曾经把上面的sift主体部分改装成函数封装,一运行就直接在函数结束的地方终端,不能返回图像。。。。。)
下面再给出另外一个SITF特征点检测的程序:
测试图片如下

-
#include "opencv2/core/core.hpp" -
#include "highgui.h" -
#include "opencv2/imgproc/imgproc.hpp" -
#include "opencv2/features2d/features2d.hpp" -
#include "opencv2/nonfree/nonfree.hpp" -
using namespace cv; -
using namespace std; -
//运用sift类 -
int main() -
{ -
Mat img = imread("666666.jpg", 1); -
SIFT sift(200);//设置了200个特征点 -
vectorkey_points;//存放特征点,存放检测出来的特征点 -
Mat descriptors, mascara;// descriptors为描述符,mascara为掩码矩阵 -
sift(img, mascara, key_points, descriptors);//执行sift运算 -
Mat output_img; //输出图像矩阵 -
//在输出图像上绘制特征点 -
drawKeypoints(img, //输入图像 -
key_points, //特征点矢量 -
output_img, //输出图像 -
Scalar::all(-1), //绘制特征点的颜色,为随机 -
//以特征点为中心画圆,圆的半径表示特征点的大小,直线表示特征点的方向 -
DrawMatchesFlags::DRAW_RICH_KEYPOINTS); -
imshow("sift tu", output_img); -
waitKey(0); -
return 0; -
}
结果如下:

其实本质上跟上面的程序是一样的。只是这个程序比较简易,就粘贴出来。
补充说明一下KeyPoint类,该类是一个为特征点检测而生的数据结构,用于表示特征点。
二.SURF
先给出几篇参考的博文:
https://blog.csdn.net/ssw_1990/article/details/72789873
https://blog.csdn.net/tostq/article/details/49472709
SURF英文全称为Speeded Up Robust Features,直接翻译就是“加速版的具有鲁棒性的特征”。是由Herbert Bay等人在2006年提出的。是一种类似于SIFT的特征点检测及描述的算法,是SIFT的加速版。SIFT算法的最大缺点是如果不借助硬件或专门的图像处理器很难达到实时。而SURF算法的实现原理借鉴了SIFT中DOG简化近似的思想,采用海森矩阵(Hessian matrix)行列式近似值图像。
SURF通过Hessian矩阵的行列式来确定兴趣点的位置,在根据兴趣点邻域的Haar小波响应来确定描述子。
SURF算法的步骤
1.通过Hessian矩阵构建高斯图像金字塔尺度空间
构建Hessian矩阵
首先同SIFT方法一样,SURF也必须考虑如何确定兴趣点位置,不过SIFT采用是DOG来代替LOG算子,找到其在尺度和图像内局部极值视为特征点,而SURF方法是基于Hessian矩阵的,而它通过积分图像极大地减少运算时间,并称之为FAST-Hessian。下面来介绍一下Hessian矩阵:它是一个自变量为向量的实值函数的二阶偏导数组成的方块矩阵。设图像像素函数为f(x,y),则图像中某个像素点的Hessian矩阵为:

对于图像中的每个像素点都可以求出一个Hessian矩阵。Hessian矩阵的判别式为:

判别式的值是H矩阵的特征值。Hessian矩阵描述函数的局部曲率(SIFT去除伪关键点也用到了Hessian矩阵)。当像素点的Hessian矩阵是正定矩阵,则该点是一个局部极小值;当像素点的Hessian矩阵是负定矩阵,则该点是一个局部极大值点;当像素点的Hessian矩阵是不定矩阵,在该像素点不是极值点。故此,可以利用判定结果的符号将所有点分类,根据判别式取值正负,来判别该点是或不是极值点。
由于SURF特征点需要具备尺度不变性(或者说尺度无关性),故此在构造Hessian矩阵前先对图像进行高斯滤波(高斯卷积核是唯一可以产生多尺度空间的核,且是唯一线性核)


通过Hessian矩阵的行列式值来判断特征点。由于求Hessian矩阵时要先进行高斯平滑,然后求二阶导数,这一过程在离散的像素点中是用模板卷积形成的。故此在SURF中用盒函数来近似这一个高斯二阶梯度模板。使用盒子滤波运算进行简化,使得简化后的模板只是几个矩形区域组成,矩形区域内填充同一值。在简化模板中白色区域的值为正数,黑色区域的值为负数,灰度区域的值为0,如下所示:


这部分看得不是很懂,就直接粘贴出来了。反正记住SURF算法使用矩形盒型滤波器来近似模拟高斯函数的二阶偏导数。使用矩阵盒滤波器可以加快计算速度,利用矩形盒滤波器与图像卷积后设定权重系数,进而来计算det(H)值,当其值为负数时,表明矩阵的两个特征值异号,该点判定为非极值点;当其值为正数时,表明矩阵两个特征值同时为正或负,该点可能是局部极值点。
构建尺度空间
通过上面的步骤,构建了一幅近似于Hessian的行列式图(类似于SIFT中的DOG图)。SURF特征描述为实现图像尺度的不变性,同样也采用图像金字塔模型,但是与SIFT不同的是,SURF的金字塔图像始终保持源图像尺寸,而尺度变换则是通过改变矩形盒滤波器大小及高斯函数尺度来实现。
尺度空间通常通过高速金字塔来实施。一般的方法是通过不同的高斯函数,对图像进行平滑滤波,然后重采样图像以获得更高一层的金字塔图像。而SURF方法通过盒函数和积分图像,因此不需要进行采样操作,直接应用不同大小的滤波器就可以了。下图说明了这一情况,左图是sift算法,其是图像大小减少,而模板不变(这里只是指每组间,组内层之间还是要变的)。而SURF算法(右图)刚好相反,其是图像大小不变,而模板大小扩大。

在SURF中,图片的大小是一直不变的,不同octave层的待检测图片是改变高斯模糊尺寸大小得到的。算法允许尺度空间多层图像同时被处理,不需要二次抽样,从而提高了算法的性能。SURF通过使原始图像保持不变而只改变了滤波器大小,节省了降采样的过程,使得其处理速度得到提升。SURF通过采用不断增大盒子滤波模板尺寸的间接方法。通过不同尺寸盒子滤波模板与积分图像求取Hessian矩阵行列式的响应图像。
2.利用非极大值抑制初步确定特征点
通过不同尺寸盒子滤波模板与积分图像求取Hessian矩阵行列式的响应图像,类似于SIFT使用3×3×3邻域非最大值抑制,即每个像素点与其三维邻域中的26个点进行大小比较获得初步不同尺度的特征点。
3.精确定位极值点
与SIFT类似,采用三维线性插值法得到亚像素级的特征点,同时也去掉小于一定阈值的点。
4.选取特征点的主方向
为了保证特征矢量具有旋转不变性,需要对每一个特征点分配一个主方向。
这一步与sift也大有不同。Sift选取特征点主方向是采用在特征点领域内统计其梯度直方图,取直方图bin值最大的以及超过最大bin值80%的那些方向做为特征点的主方向。
而在surf中,不统计其梯度直方图,而是统计特征点领域内的harr小波特征。即在特征点的领域(比如说,半径为6s的圆内,s为该点所在的尺度)内,统计60度扇形内所有点的水平haar小波特征和垂直haar小波特征总和,haar小波的尺寸变长为4s,这样一个扇形得到了一个值。然后60度扇形以一定间隔进行旋转,最后将最大值那个扇形的方向作为该特征点的主方向。该过程的示意图如下:

5.构造SURF特征点描述算子
同sift算法一样,SURF也是通过建立兴趣点附近区域内的信息来作为描述子的,不过sift是利用邻域点的方向,而SURF则是利用Haar小波响应。
SURF首先在兴趣点附近建立一个20s大小的方形区域,为了获得旋转不变性,同sift算法一样,我们需要将其先旋转到主方向,然后再将方形区域划分成16个(4*4)子域。对每个子域(其大小为5s*5s)我们计算25(5*5)个空间归一化的采样点的Haar小波响应dx和dy。
之后我们将每个子区域(共4*4)的dx,dy相加,因此每个区域都有一个描述子(如下式),为了增加鲁棒性,我们可以给描述子再添加高斯权重(尺度为3.3s,以兴趣点为中心)


所以最后在所有的16个子区域内的四位描述子结合,将得到该兴趣点的64位描述子

由于小波响应对于光流变化偏差是不变的,所以描述子具有了光流不变性,而对比性不变可以通过将描述子归一化为单位向量得到。
另外也建立128位的SURF描述子,其将原来小波的结果再细分,比如dx的和将根据dy的符号,分成了两类,所以此时每个子区域内都有8个分量,SURF-128有非常好效果,如下图所示。

在surf中,也是在特征点周围取一个正方形框,框的边长为20s(s是所检测到该特征点所在的尺度)。该框带方向,方向当然就是第4步检测出来的主方向了。然后把该框分为16个子区域,每个子区域统计25个像素的水平方向和垂直方向的haar小波特征,这里的水平和垂直方向都是相对主方向而言的。该haar小波特征为水平方向值之和,水平方向绝对值之和,垂直方向之和,垂直方向绝对值之和。该过程的示意图如下所示:
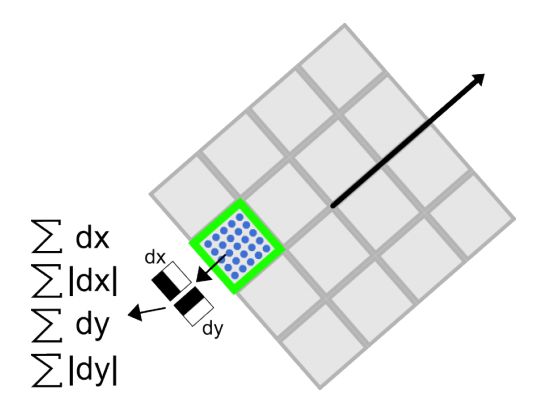
这样每个小区域就有4个值,所以每个特征点就是16*4=64维的向量,相比sift而言,少了一半,这在特征匹配过程中会大大加快匹配速度。
代码演示:
opencv中SURF部分设计到三个类:SURF、SurfFeatureDetector、SurfDescriptorExtractor
根据features2d.hpp头文件中的两句定义:
-
typedef SURF SurfFeatureDetector; -
typedef SURF SurfDescriptorExtractor;
其中,typedef声明是为现有类型创建一个新的名字,类型别名,即SURF类有了两个新名字SurfFeatureDetector以及SurfDescriptorExtractor。也就是说,SurfFeatureDetector类和SurfDescriptorExtractor类,其实就是SURF类,他们三者等价。下图给出了SURF相关类之间的关系:

SURF特征检测及匹配代码:(参考《OPENCV图像处理编程实例》一书,并结合自己的理解作出的注释)
(建议看程序的时候结合着上文SIFT来看。)
-
#include -
#include -
#include -
#include -
using namespace std; -
using namespace cv; -
void SurfFeature(const Mat & srcImage1, const Mat & srcImage2, float Para) -
{ -
//CV_Assert()用于判断输入数据的合法性,当该函数为false时,返回一个错误信息 -
CV_Assert(srcImage1.data != NULL && srcImage2.data != NULL); -
//转换为灰度图 -
Mat grayImage1, grayImage2; -
cvtColor(srcImage1, grayImage1, CV_RGB2GRAY); -
cvtColor(srcImage2, grayImage2, CV_RGB2GRAY); -
//初始化SURF特征描述子(与SiftFeatureDetector和SiftDescriptorExtractor形成对比) -
SurfFeatureDetector surfDector(Para);//Para为surf算法的参数。Hessian阈值特征点检测算子 -
SurfDescriptorExtractor surfExtractor; -
//分为:特征检测器(Feature Detector),描述子提取器(Descriptor Extractor)和描述子匹配器(Descriptor Matcher) -
//关键点的声明 -
vectorkeyPoints1, keyPoints2; -
//特征点的检测,并放入keypoint类型的vector中。计算SURF特征关键点 -
surfDector.detect(grayImage1, keyPoints1); -
surfDector.detect(grayImage2, keyPoints2); -
//对于关键点的一些说明: -
//用特征检测器SurfFeatureDetector获取关键点的位置,方向等信息。获得特征点的基本信息。再用描述子提取器来获取特征向量 -
//keyPoint向量用于保存特征信息,每个元素包含的内容有以下: -
/*size1:特征点的总个数 -
pt: 特征点的坐标 -
size2:特征点的大小 -
angle:特征点的角度 -
response:特征点的响应强度,代表该点的稳健程度,可以在Surf特征探测器的含参构造函数中设置响应强度的最低阈值,如: SurfFeatureDetector surfDetector(800); -
octave:特征点所在的金字塔的哪一组 -
class_id:特征点的分类*/ -
//特征描述矩阵的声明 -
Mat descriptorMat1, descriptorMat2; -
//计算SURF特征描述矩阵 -
surfExtractor.compute(grayImage1, keyPoints1, descriptorMat1); -
surfExtractor.compute(grayImage2, keyPoints2, descriptorMat2); -
//对于特征描述矩阵的一些说明: -
//通过compute方法,输入为灰度图像、关键点,输出为特征描述子矩阵。 -
//得到keypoint只是达到了关键点的位置,方向等信息,并无该特征点的特征向量,要想提取得到特征向量就还要进行SurfDescriptorExtractor(描述子提取器)的工作 -
//进行特征点的匹配 -
if (keyPoints1.size() > 0 && keyPoints2.size() > 0) -
{ -
//计算特征匹配点 -
FlannBasedMatcher matcher;//声明一个FLANN匹配器,用匹配器对两幅图的特征描述矩阵进行匹配。 -
//得到的匹配结果放于matches中,matches为特征点匹配向量 -
vectormatches; -
//说明: -
/*描述子匹配器进行特征点匹配后生产一个DMatch类型的向量matches -
matches数据结构包含的内容有: -
size:配对成功的特征点对数 -
queryIdx:当前“匹配点”在查询图像的特征在KeyPoints1向量中的索引号,可以据此找到匹配点在查询图像中的位置 -
trainIdx:当前“匹配点”在训练(模板)图像的特征在KeyPoints2向量中的索引号,可以据此找到匹配点在训练图像中的位置 -
imgIdx:当前匹配点对应训练图像(如果有若干个)的索引,如果只有一个训练图像跟查询图像配对,即两两配对,则imgIdx = 0 -
distance:连个特征点之间的欧氏距离,越小表明匹配度越高 -
*/ -
matcher.match(descriptorMat1, descriptorMat2, matches); -
//绘制特征点匹配结果 -
Mat resultMat; -
drawMatches(srcImage1, keyPoints1, srcImage2, keyPoints2, matches, resultMat); -
imshow("jieguotu", resultMat); -
waitKey(0); -
} -
} -
int main() -
{ -
Mat src1 = imread("hand1.jpg", 1); -
Mat src2 = imread("hand2.jpg", 1); -
SurfFeature(src1,src2,1000); -
return 0; -
}
运行结果如下:

那么同样存在的问题:按shift+F5退出是正常,如果按ESC或者0就出现如图所示的错误:

与此同时,如果将waitKey(0)语句的位置换到return0前面,也会报错如下:

点击若干次继续然后再点中断的结果如下:

如果有大佬知道怎么解决这一问题,请在评论处赐教~谢谢!!!
注释:个人认为做工程与做理论的区别就是:理论可能你需要很深入的证明与推导,工程只需要你会用一些函数就可以。完全的小白也可以实现SURF特征检测及匹配,但是建议还是对每个函数的具体物理意义理解一下,这样才不至于完全纸上谈兵。
关于SURF的实现细节可参考博文:https://blog.csdn.net/b10090411/article/details/53406068。
关于匹配器
此处,在SURF中特征点匹配使用了FlannBasedMatcher;而在上面的SIFT中使用了BruteForceMatcher。Brute Force匹配和FLANN匹配是opencv二维特征点匹配常见的两种办法(具体看参见https://blog.csdn.net/haizimin/article/details/49838911)。BruteForceMatcher中文名是“暴力匹配”,其会尝试所有可能的匹配,从而使得它总能够找到最佳匹配。而FlannBasedMatcher中的FLANN是指Fast Library forApproximate Nearest Neighbors(近似最近邻的快速库),它是一种近似法,算法更快但是找到的是最近邻近似匹配,所以当我们需要找到一个相对好的匹配但是不需要最佳匹配的时候往往使用FlannBasedMatcher。
三.ORB
主要参考博客:
https://blog.csdn.net/zouzoupaopao229/article/details/52625678
https://blog.csdn.net/guoyunfei20/article/details/78792770
ORB(Oriented FAST and Rotated BRIEF)是一种快速特征点提取和描述的算法。这个算法是由Ethan Rublee, Vincent Rabaud, Kurt Konolige以及Gary R.Bradski在2011年一篇名为《ORB:An Efficient Alternative to SIFT or SURF》的文章中提出。ORB算法分为两部分,分别是特征点提取和特征点描述。特征提取是由FAST(Features from Accelerated Segment Test)算法发展来的,特征点描述是根据BRIEF(Binary Robust IndependentElementary Features)特征描述算法改进的。ORB特征是将FAST特征点的检测方法与BRIEF特征描述子结合起来,并在它们原来的基础上做了改进与优化。据说,ORB算法的速度是sift的100倍,是surf的10倍。可用于实时性特征检测。
ORB算法主要分为以下两个步骤:特征点提取和特征点描述。特征点提取是根据FAST算法改进的,而特征点描述是根据BRIEF特征描述算法改进的。
1.FAST特征点的检测
FAST算法的介绍
对于FAST特征点检测主要参考博客
https://blog.csdn.net/laobai1015/article/details/51208911
https://blog.csdn.net/u010682375/article/details/72824097
FAST(Features fromaccelerated segment test)是一种角点检测方法,它可以用于特征点的提取。FAST算法是公认的最快的特征点提取方法。FAST算法提取的特征点非常接近角点类型。FAST角点检测算法最初是由Edward Rosten和Tom Drummond提出,该算法最突出的优点是它的计算效率。FAST关键点检测是对兴趣点所在圆周上的16个像素点进行判断,若判断后的当前中心像素为暗或亮,将决定其是否为角点。该算法的基本原理是使用圆周长为16个像素点(半径为3的Bresenham圆)来判定其圆心像素P是否为角点。在圆周上按顺时针方向从1到16的顺序对圆周像素点进行编号。如果在圆周上有N个连续的像素的亮度都比圆心像素的亮度Ip加上阈值t还要亮,或者比圆心像素的亮度减去阈值还要暗,则圆心像素被称为角点。

一般N为12。在一幅图像中,非角点往往是占多数,而且非角点检测要比角点检测容易得多,因此首先剔除掉非角点将大大提高角点检测速度。由于N为12,所以编号为1,5,9,13的这4个圆周像素点中应该至少有三个像素点满足角点条件,圆心才有可能是角点。因此首先检查1和9像素点,如果I1和I9在[Ip –t, Ip + t]之间,则圆心肯定不是角点,否则再检查5和13像素点。如果这4个像素中至少有三个像素满足亮度高于Ip+t或低于Ip –t,则进一步检查圆周上其余像素点。以上方法可能导致密集的角点,因此在OpenCV中使用了非极大值抑制来增强其鲁棒性。
故此FAST角点检测方法的具体步骤可以归纳为:
1、在圆周上的部分像素点上,进行非角点的检测;
2、如果初步判断是角点,则在圆周上的全部像素点上进行角点检测;
3、对角点进行非极大值抑制,得到角点输出。
另外一种FAST的步骤归纳如下:
根据2006年 Edward_Rosten 和 Tom_Drummond 提出的FAST算法可以归纳如下几步:
1.在图像中选取一个像素点 p,来判断它是不是关键点。 Ip 等于像素点 p的灰度值。
2.选择适当的阈值 t。
3.如下图所示在像素点 p 的周围选择 16 个像素点进行测试。

4.如果在这 16 个像素点中存在 n 个连续像素点的灰度值都高于 Ip + t,或者低于 Ip − t,那么像素点 p 就被认为是一个角点。如上图中的虚线所示,n 选取的值为 12。
5.为了获得更快的效果,还采用了而外的加速办法。首先对候选点的周围每个 90 度的点: 1, 9, 5, 13 进行测试(先测试 1 和 19, 如果它们符合阈值要求再测试 5 和 13)。如果 p 是角点,那么这四个点中至少有 3 个要符合阈值要求。如果不是的话肯定不是角点,就放弃。对通过这步测试的点再继续进行测试(是否有 12 的点符合阈值要求)。这个检测器的效率很高,但是它有如下几条缺点:
- • 当 n<12 时它不会丢弃很多候选点 (获得的候选点比较多)。
- • 像素的选取不是最优的,因为它的效果取决与要解决的问题和角点的分布情况。
- • 高速测试的结果被抛弃
- • 检测到的很多特征点都是连在一起的。
前三个问题都可以通过机器学习来解决,最后一个问题可以使用非最大值抑制的方法解决。
(详细请参考博文:https://blog.csdn.net/u010682375/article/details/72824097)
给出一段FAST角点检测的代码:
-
#include -
#include -
#include -
#include -
#include -
using namespace std; -
using namespace cv; -
int main() -
{ -
Mat src = imread("666666.jpg", 1); -
imshow("测试图",src); -
//创建放置关键点的vector -
vectorkeyPoints; -
//创建FAST对象,并将阈值设定为55 -
FastFeatureDetector fast(55); -
//获取特征点 -
fast.detect(src, keyPoints); -
//在原图上画出特征点 -
drawKeypoints(src, keyPoints, src, Scalar(0, 0, 255), DrawMatchesFlags::DRAW_OVER_OUTIMG); -
imshow("FAST feature", src); -
waitKey(0); -
return 0; -
}
结果图如下:

ORB中的FAST算法
ORB中的特征提取是由FAST算法改进得来的。称为oFAST(FAST Keypoint Orientation)。也就是在使用FAST提取出特征点后,给其定义一个特征点的方向,以此来实现特征点的旋转不变性。
oFAST算法步骤如下:
步骤一:粗提取(其实就相当于前面介绍的FAST特征提取算法,没经过机器学习与非最大值抑制的方法的)。该步能够提取大量的特征点,但是有很大一部分的特征点的质量不高。
步骤二:机器学习的方法筛选最优特征点。简单来说就是使用ID3算法训练一个决策树,将特征点圆周上的16个像素输入决策树中,以此来筛选出最优的FAST特征点。(https://blog.csdn.net/u010682375/article/details/72824097)
步骤三:非极大值抑制去除局部较密集特征点。使用非极大值抑制算法去除临近位置多个特征点的问题。为每一个特征点计算出其响应大小。计算方式是特征点P和其周围16个特征点偏差的绝对值和。在比较临近的特征点中,保留响应值较大的特征点,删除其余的特征点。
步骤四:特征点的尺度不变性。建立金字塔,来实现特征点的多尺度不变性。设置一个比例因子scale Factor(opencv默认为1.2)和金字塔的层数nlevels(pencv默认为8)。将原图像按比例因子缩小成nlevels幅图像。缩放后的图像为:I’= I/scaleFactork(k=1,2,…, nlevels)。nlevels幅不同比例的图像提取特征点总和作为这幅图像的oFAST特征点。
步骤五:特征点的旋转不变性。ORB算法提出使用矩(moment)法来确定FAST特征点的方向。也就是说通过矩来计算特征点以r为半径范围内的质心,特征点坐标到质心形成一个向量作为该特征点的方向。矩定义如下:

其中,I(x,y)为图像灰度表达式。该矩的质心位置为:
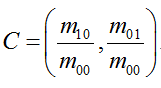
假设角点坐标为O,则向量的角度即为该特征点的主方向。计算公式如下:

2.BRIEF特征描述子
BRIEF特征描述子的介绍
主要参考博客:
https://blog.csdn.net/luoshixian099/article/details/48338273
https://blog.csdn.net/hujingshuang/article/details/46910259
BRIEF(Binary Robust Independent Elementary Features)在2010年被提出。BRIEF是对已检测到的特征点进行描述,它是一种二进制编码的描述子,摈弃了利用区域灰度直方图描述特征点的传统方法,大大的加快了特征描述符建立的速度,同时也极大的降低了特征匹配的时间,是一种非常快速,很有潜力的算法。
BRIEF描述子原理简要为三个步骤,长度为N的二进制码串作为描述子(占用内存N/8):
1.以特征点P为中心,取一个S×S大小的Patch邻域;
2.在这个邻域内随机取N对点,然后对这2×N点分别做高斯平滑(采用高斯平滑图像,降低噪声的影响,使描述子更加稳定)。定义τ测试,比较N对像素点的灰度值的大小;

3.最后把步骤2得到的N个二进制码串组成一个N维向量,形成一个二进制编码,这个编码就是对特征点的描述,即特征描述子。(一般N=256)

看了这套理论描述看不懂。。。。直接看代码吧,其实就是一句,作为特征描述子
下面给出代码:
由于本人做计算机视觉是以应用为主,而不是理论为主(相信对于一部分人也一样),那以应用为主最快的入手方法就是看代码,而不是公式推导
下面代码是基于SURF特征检测与BRIEF特征描述
-
#include -
#include -
#include -
#include -
#include -
#include -
using namespace std; -
using namespace cv; -
int main() -
{ -
//读入图片 -
Mat srcImage1 = imread("hand1.jpg", 1); -
Mat srcImage2 = imread("hand2.jpg", 1); -
//转换为灰度图 -
Mat grayImage1, grayImage2; -
cvtColor(srcImage1, grayImage1, CV_RGB2GRAY); -
cvtColor(srcImage2, grayImage2, CV_RGB2GRAY); -
//定义特征点检测器(注意SurfFeatureDetector和SurfDescriptorExtractor是等价的) -
SurfFeatureDetector detector(400); -
//声明存放关键点的容器 -
vectorkeyPoints1, keyPoints2; -
//特征点检测 -
detector.detect(grayImage1, keyPoints1); -
detector.detect(grayImage2, keyPoints2); -
//定义特征提取器,采用了BRIEF特征描述子 -
BriefDescriptorExtractor extractor(64);// //参数表示字节数,采用长度为64×8=512的向量表示 -
//注意bytes参数表示的是描述子占用的字节数不是描述子长度,如默认采用32字节对应描述子长度为32×8=256; -
//声明存放特征向量的特征描述矩阵 -
Mat descriptorMat1, descriptorMat2; -
//计算SURF特征描述矩阵(计算特征向量) -
extractor.compute(grayImage1, keyPoints1, descriptorMat1); -
extractor.compute(grayImage2, keyPoints2, descriptorMat2); -
//用匹配器进行匹配。之前介绍过FLANN匹配器和暴力匹配器(BruteForceMatcher) -
BFMatcher matcher(NORM_HAMMING); //汉明距离匹配特征点 -
//定义特征点匹配向量 -
vectormatches; -
matcher.match(descriptorMat1, descriptorMat2, matches); -
//画图 -
Mat image; -
drawMatches(srcImage1, keyPoints1, srcImage2, keyPoints2, matches, image); -
imshow("BRIEF特征描述子出来的匹配结果", image); -
定义特征提取器,采用了SURF的特征描述子 -
//SurfDescriptorExtractor extractor1;// //参数表示字节数,采用长度为64×8=512的向量表示 -
声明存放特征向量的特征描述矩阵 -
//Mat descriptorMat1_1, descriptorMat2_1; -
计算SURF特征描述矩阵(计算特征向量) -
//extractor1.compute(grayImage1, keyPoints1, descriptorMat1_1); -
//extractor1.compute(grayImage2, keyPoints2, descriptorMat2_1); -
用匹配器进行匹配。之前介绍过FLANN匹配器和暴力匹配器(BruteForceMatcher) -
//BFMatcher matcher1; //汉明距离匹配特征点 -
// -
定义特征点匹配向量 -
//vectormatches1; -
//matcher1.match(descriptorMat1_1, descriptorMat2_1, matches1); -
画图 -
//Mat image1; -
//drawMatches(srcImage1, keyPoints1, srcImage2, keyPoints2, matches1, image1); -
//imshow("采用了SURF的特征描述子出来的匹配结果", image1); -
waitKey(0); -
return 0; -
}
结果如下图所示:


BRIEF算法的优点:计算速度快。缺点:1、对噪声敏感(因为二进制编码是通过比较具体像素值来判定的);2、不具备尺度不变性和旋转不变性。
ORB中的BRIEF算法(又称为rBRIEF)
rBRIEF特征描述是在BRIEF特征描述的基础上加入旋转因子改进的。
博文:https://blog.csdn.net/zouzoupaopao229/article/details/52625678描述得比较清晰,下面直接粘贴出来
BRIEF算法计算出来的是一个二进制串的特征描述符。它是在一个特征点的邻域内,选择n对像素点pi、qi(i=1,2,…,n)。然后比较每个点对的灰度值的大小。如果I(pi)>I(qi)则生成二进制串中的1,否则为0。所有的点对都进行比较,则生成长度为n的二进制串。一般n取128、256或512,opencv默认为256。另外,值得注意的是为了增加特征描述符的抗噪性,算法首先需要对图像进行高斯平滑处理。在ORB算法中,在这个地方进行了改进,在使用高斯函数进行平滑后,又用了其他操作,使其更加的具有抗噪性。具体方法下面将会描述。
关于在特征点SxS的区域内选取点对的方法,BRIEF论文(附件2)中测试了5种方法:
1)在图像块内平均采样;
2)p和q都符合(0,S2/25)的高斯分布;
3)p符合(0,S2/25)的高斯分布,而q符合(0,S2/100)的高斯分布;
4)在空间量化极坐标下的离散位置随机采样;
5)把p固定为(0,0),q在周围平均采样。
五种采样方法的示意图如下:

论文指出,第二种方法可以取得较好的匹配结果。在旋转不是非常厉害的图像里,用BRIEF生成的描述子的匹配质量非常高,作者测试的大多数情况中都超越了SURF。但在旋转大于30°后,BRIEF的匹配率快速降到0左右。BRIEF的耗时非常短,在相同情形下计算512个特征点的描述子时,SURF耗时335ms,BRIEF仅8.18ms;匹配SURF描述子需28.3ms,BRIEF仅需2.19ms。在要求不太高的情形下,BRIEF描述子更容易做到实时。
rBRIEF(Rotation-AwareBrief)
(1)steered BRIEF(旋转不变性改进)
在使用oFast算法计算出的特征点中包括了特征点的方向角度。假设原始的BRIEF算法在特征点SxS(一般S取31)邻域内选取n对点集。

经过旋转角度θ旋转,得到新的点对

在新的点集位置上比较点对的大小形成二进制串的描述符。这里需要注意的是,在使用oFast算法是在不同的尺度上提取的特征点。因此,在使用BRIEF特征描述时,要将图像转换到相应的尺度图像上,然后在尺度图像上的特征点处取SxS邻域,然后选择点对并旋转,得到二进制串描述符。
(2)rBRIEF-改进特征点描述子的相关性
使用steeredBRIEF方法得到的特征描述子具有旋转不变性,但是却在另外一个性质上不如原始的BRIEF算法。是什么性质呢,是描述符的可区分性,或者说是相关性。这个性质对特征匹配的好坏影响非常大。描述子是特征点性质的描述。描述子表达了特征点不同于其他特征点的区别。我们计算的描述子要尽量的表达特征点的独特性。如果不同特征点的描述子的可区分性比较差,匹配时不容易找到对应的匹配点,引起误匹配。ORB论文中,作者用不同的方法对100k个特征点计算二进制描述符,对这些描述符进行统计,如下表所示:

图2 特征描述子的均值分布.X轴代表距离均值0.5的距离,y轴是相应均值下的特征点数量统计
我们先不看rBRIEF的分布。对BRIEF和steeredBRIEF两种算法的比较可知,BRIEF算法落在0上的特征点数较多,因此BRIEF算法计算的描述符的均值在0.5左右,每个描述符的方差较大,可区分性较强。而steeredBRIEF失去了这个特性。至于为什么均值在0.5左右,方差较大,可区分性较强的原因,这里大概分析一下。这里的描述子是二进制串,里面的数值不是0就是1,如果二进制串的均值在0.5左右的话,那么这个串有大约相同数目的0和1,那么方差就较大了。用统计的观点来分析二进制串的区分性,如果两个二进制串的均值都比0.5大很多,那么说明这两个二进制串中都有较多的1时,在这两个串的相同位置同时出现1的概率就会很高。那么这两个特征点的描述子就有很大的相似性。这就增大了描述符之间的相关性,减小之案件的可区分性。
下面我们介绍解决上面这个问题的方法:rBRIEF。
原始的BRIEF算法有5中去点对的方法,原文作者使用了方法2。为了解决描述子的可区分性和相关性的问题,ORB论文中没有使用5种方法中的任意一种,而是使用统计学习的方法来重新选择点对集合。
首先建立300k个特征点测试集。对于测试集中的每个点,考虑其31x31邻域。这里不同于原始BRIEF算法的地方是,这里在对图像进行高斯平滑之后,使用邻域中的某个点的5x5邻域灰度平均值来代替某个点对的值,进而比较点对的大小。这样特征值更加具备抗噪性。另外可以使用积分图像加快求取5x5邻域灰度平均值的速度。
从上面可知,在31x31的邻域内共有(31-5+1)x(31-5+1)=729个这样的子窗口,那么取点对的方法共有M=265356种,我们就要在这M种方法中选取256种取法,选择的原则是这256种取法之间的相关性最小。怎么选取呢?
1)在300k特征点的每个31x31邻域内按M种方法取点对,比较点对大小,形成一个300kxM的二进制矩阵Q。矩阵的每一列代表300k个点按某种取法得到的二进制数。
2)对Q矩阵的每一列求取平均值,按照平均值到0.5的距离大小重新对Q矩阵的列向量排序,形成矩阵T。
3)将T的第一列向量放到R中。
4)取T的下一列向量和R中的所有列向量计算相关性,如果相关系数小于设定的阈值,则将T中的该列向量移至R中。
5)按照4)的方式不断进行操作,直到R中的向量数量为256。
通过这种方法就选取了这256种取点对的方法。这就是rBRIEF算法。
ORB算法最大的特点就是计算速度快 。这得益于使用FAST检测特征点,FAST的检测速度正如它的名字一样是出了名的快。再者 是就是使用了BRIEF算法计算描述子,该描述子特有的2进制串的表现形式不仅节约了存储空间,而且大大缩短了匹配的时间。
ORB代码
测试图跟上面的SIFT与SURF一样。建议对照着SIFT与SURF来看ORB的程序。在OpenCV中,ORB类继承自Feature2D类(在opencv3.20也可以实现,但用法不一样,可参考博客:https://blog.csdn.net/bingoplus/article/details/60133565 ),另外有两个类:OrbFeatureDetector和OrbDescriptorExtractor,与ORB类是等价的。
-
#include -
#include -
#include -
#include -
using namespace cv; -
using namespace std; -
//计算图像ORB特征及匹配 -
void ORB_feature_and_compare(const Mat & src1, const Mat & src2) -
{ -
//转换为灰度图 -
Mat grayImage1, grayImage2; -
cvtColor(src1, grayImage1, CV_RGB2GRAY); -
cvtColor(src2, grayImage2, CV_RGB2GRAY); -
//特征检测 -
OrbFeatureDetector detector;//特征检测器,检测出来的特征放于KeyPoint中 -
//关键点检测存放容器的声明 -
vectorkeyPoints1, keyPoints2; -
//特征点的检测,并放于keypoint中 -
detector.detect(grayImage1, keyPoints1); -
detector.detect(grayImage2, keyPoints2); -
//特征提取 -
OrbDescriptorExtractor extractor;//特征提取器,描述子,将上面获得的关键点转换为特征向量,存放于特征描述矩阵中 -
//特征描述矩阵的声明 -
Mat descriptorMat1, descriptorMat2; -
//计算特征向量并存放于特征描述矩阵中 -
extractor.compute(grayImage1, keyPoints1, descriptorMat1); -
extractor.compute(grayImage2, keyPoints2, descriptorMat2); -
//特征匹配 -
BFMatcher matcher;//声明一个匹配器,采用暴力匹配。匹配的结果放于DMatch中,里面的则为特征点匹配向量 -
//声明一个特征点的匹配向量,存放匹配结果 -
vectormatches; -
matcher.match(descriptorMat1, descriptorMat2, matches); -
//绘制特征点匹配结果 -
Mat resultMat; -
drawMatches(src1, keyPoints1, src2, keyPoints2, matches, resultMat); -
imshow("jieguotu", resultMat); -
waitKey(0); -
} -
int main() -
{ -
Mat src1 = imread("hand1.jpg", 1); -
Mat src2 = imread("hand2.jpg", 1); -
ORB_feature_and_compare(src1, src2); -
return 0; -
}
结果如图所示:

匹配的效果不是特别的好~~~至于原因我也没有去深究,如果读者有什么想法,可以在评论一下赐教(会不会是匹配的速度快,对应准确率就没那么高呢?)
总结:三种算法其实非常相似,在opencv中表现只是特征提取的函数以及特征描述的函数不一样而已。
三种算法用于识别两张图的目标是否相同,总结基本流程总结如下:
1、分别找出这两张图中的特征点。通过特征检测器进行特征检测,检测的结果放于KeyPoint类型的vector中。
2、描述这些特征点的属性。特征的描述也叫特征的提取,就是第一步获得的仅仅是一系列特征点,第二步就要生成特征向量,用特征提取器获得描述子,并放于特征描述矩阵中。
3、比较这两张图片的特征点的属性,如果有足够多的特征点具有相同的属性,那么可以认为这两张图片中的目标是相同的。通过匹配器进行特征匹配(匹配器分为FLANN和暴力匹配),匹配结果放于DMatch类型的vector中。
至此,本人学习SIFT、SURF和ORB三种特征算子的旅途就告一段落了,希望本博客能给有需要的人带来帮助,同时也欢迎广大读者批评赐教。感觉本人对于这三种算子的理解目前还是处于纸上谈兵的状态,希望能与大家多交流,后续我也会自己做一些项目,有新的心得体会会及时更新这篇博客。同时这篇博客理论部分很多都是参考其他博客与书籍,适当的地方都给出了引用,本博客无商业用途,仅仅作为本人的学习笔记~谢谢。
Reference:(除了在上面分别指出的博客链接外,本博文还参考了以下资料)
《OpenCV图像处理编程实例》
《Opencv3编程入门》