机器学习实验二 决策树
文章目录
-
- 一、算法原理
- 二、基本步骤
- 三、量化纯度
- 四、剪枝处理
- 五、连续值处理
- 六、代码实现
一、算法原理
1.决策树(Decision Tree)是一种简单但是广泛使用的分类器。通过训练数据构建决策树,可以高效的对未知的数据进行分类。
2.决策树需要监管学习,监管学习就是给出一堆样本,每个样本都有一组属性和一个分类结果,也就是分类结果已知,那么通过学习这些样本得到一个决策树,这个决策树能够对新的数据给出正确的分类。
3.决策树有两大优点:1)决策树模型可以读性好,具有描述性,有助于人工分析;2)效率高,决策树只需要一次构建,反复使用,每一次预测的最大计算次数不超过决策树的深度。

举个我们上课讲过的,关于女儿和妈妈讨论找对象的例子:在这个例子中,由男方的年龄、长相、收入、是否为公务员这四个条件决定女儿要不要和南方见面。比如说一个男生,他年龄小于30岁,长得不错,收入中等但他是公务员,那女儿就会和他见面。
二、基本步骤
决策树构建的基本步骤如下:
- 开始,所有记录看作一个节点
- 遍历每个变量的每一种分割方式,找到最好的分割点
- 分割成两个节点N1和N2
- 对N1和N2分别继续执行2-3步,直到每个节点足够“纯”为止
决策树的变量可以有两种:
1) 数字型(Numeric):变量类型是整数或浮点数,如前面例子中的“年龄”。用“>=”,“>”,“<”或“<=”作为分割条件(排序后,利用已有的分割情况,可以优化分割算法的时间复杂度)。
2) 名称型(Nominal):类似编程语言中的枚举类型,变量只能重有限的选项中选取,比如前面例子中的“是否为公务员”,只能是“是”或“不是”。使用“=”来分割。
那么问题来了,怎么评判一个分割点的好坏?这时候,我们需要设定一个阈值,使得分类后的错误率最小,也就是说使分类结果更“纯”,这个就是学习决策树的关键部分。接下来介绍一下量化纯度的方法~
三、量化纯度
经典的属性划分方法有3种,分别是:
–信息增益: ID 3
–增益率:C 4.5
–基尼指数:CART
1.对于ID3来说,信息熵是度量样本集合纯度最常用的一种指标,这里假设记录被分为n类,每一类的比例P(i)=第i类的数目/总数目,这里直接上个熵的公式:
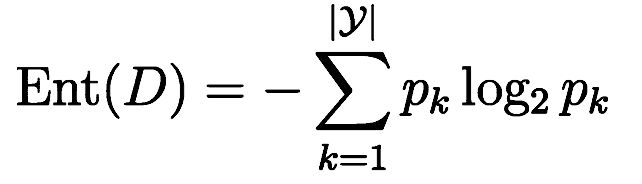
Entropy的值越小,则D的纯度越高;计算信息熵时约定:若p = 0,则p·log2p=0;Entropy的最小值为0,最大值为log2|y|。
接下来再给出信息增益的定义和公式:
 -其中,a是离散属性,它有V个可能的取值,用a划分,则会产生V个分支节点,其中第v个分支结点包含了D中所有在属性a上取值为av的样本,记为Dv。
-其中,a是离散属性,它有V个可能的取值,用a划分,则会产生V个分支节点,其中第v个分支结点包含了D中所有在属性a上取值为av的样本,记为Dv。
-一般而言,信息增益越大,则意味着使用属性a来进行划分所获得的“纯度提升”越大。
-但是!!!信息增益对可取值数目较多的属性有所偏好,这里我们在C4.5中引入增益率:
2.对于C4.5来说:

增益率准则对可取值数目较少的属性有所偏好,C4.5中,先从候选划分属性中找出信息增益高于平均水平的属性,再从中选取增益率最高的。
3.对于CART,我们引入基尼指数。
分类问题中,假设D有K个类,样本点属于第k类的概率为pk, 则概率分布的基尼值定义为:
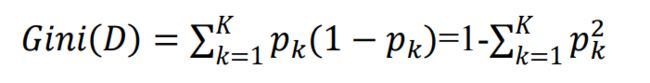
-反映了随机抽取两个样本,其类别标记不一致的概率。
给定数据集D,属性a的基尼指数定义为: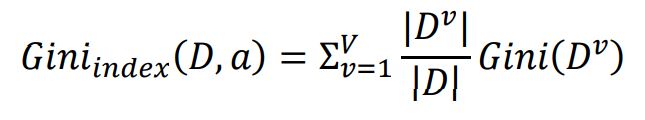
在候选属性集合A中,选择那个使得划分后基尼指数最小的属性作为最有划分属性。
四、剪枝处理
剪枝,是为了防止过拟合。有预剪枝和后剪枝两种方法。
通过预留一部分验证集来检验剪枝的效果。
1.预剪枝:通过提前停止树的构建而对树剪枝的方法。主要方法有:
(1.当决策树达到预设的高度时就停止决策树的生长。
(2.达到某个节点的实例具有相同的特征向量,即使这些实例不属于同一类,也可以停止决策树的生长。
(3.定义一个阈值,当达到某个节点的实例个数小于阈值时就可以停止决策树的生长。
(4.通过计算每次扩张对系统性能的增益,决定是否停止决策树的生长。若当前结点的划分不能带来决策树泛化性能提升,则停止划分并将当前结点记为叶结点,其类别标记为该节点对应训练样例数最多的类别。
优点:防止过拟合,大幅减少时间开销。
缺点:带来欠拟合风险(因为有些节点的划分虽然不能提高泛化性能,但是可以显著提高分类的性能)。
2.后剪枝:先生成决策树,再自底向上对非叶节点进行分析计算,如果该结点对应的子树替换为叶结点能带来决策树泛化性能提升,则将该子树替换为叶结点。
优点:欠拟合风险小,泛化性能往往优于预剪枝决策树。
缺点:因为是在决策树建立之后再自底向上判断是否剪枝,时间开销大。
五、连续值处理
采用二分法来使属性值离散化


与离散属性不同,若当前结点划分属性为连续属性,该属性还可作为其后代结点的划分属性。
六、代码实现
使用威斯康辛州诊断出来的乳腺癌病例统计作为本次实验的数据集,总共有569个样本
数据集部分截图如下:
导入所需要的库和数据集(我是把数据集下载成txt格式的)
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
from matplotlib.pyplot import figure
import sklearn
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn import tree
import graphviz
from sklearn import preprocessing
df = pd.read_csv('wdbc.txt',sep=',',names=[i for i in range(32)])
print(df)
df.describe()

把我们读入的数据集按列读入X,Y变量中,其中X是30个乳腺癌的特征,Y是乳腺癌是否为恶性(M)/良性(B)。我们利用train_test_split函数把读入的数据分成70%的训练集和30%的测试集。
然后利用DecisionTreeClassifier()函数初始化决策树,这里我们默认使用Gini系数,既CART算法。
df.isnull().any()
X = df.iloc[:,2:].values
Y = df.iloc[:,1].values
x_train,x_test,y_train,y_test = train_test_split(X,Y,train_size = 0.7,shuffle = True)
clf = DecisionTreeClassifier()
clf.fit(x_train, y_train)
clf.score(x_test, y_test)
这里可以看到返回的平均准确率(score()函数返回的)

因为我们刚刚也没设置什么循环次数和学习率之类的,直接就用DecisionTreeClassifier()这个方法的默认参数,接下来我们限制一下树的深度为5。
dt0_0 = 0.
dt0_1 = 0.
for i in range(1,21):
clf = DecisionTreeClassifier(criterion='gini', max_depth=5)
clf.fit(x_train, y_train)
a = clf.score(x_train, y_train)
b = clf.score(x_test, y_test)
dt0_0=dt0_0+a
dt0_1=dt0_1+b
pre_y=clf.predict(X)
recall=sklearn.metrics.recall_score(Y,pre_y,pos_label='M')
precision=sklearn.metrics.precision_score(Y,pre_y,pos_label='M')
print(dt0_0/(i)) #训练集的准确率
print(dt0_1/(i)) #测试集的准确率
print(DecisionTreeClassifier.get_depth(clf))
print(recall, precision)
结果如下:

这是用信息增益的方法做的决策树和结果
dt1_0 = 0.
dt1_1 = 0.
for j in range(1,21):
clf_1 = DecisionTreeClassifier(criterion='entropy', max_depth=5)
clf_1.fit(x_train,y_train)
c = clf_1.score(x_train, y_train)
d = clf_1.score(x_test, y_test)
dt1_0=dt1_0+c
dt1_1=dt1_1+d
print(dt1_0/j)
print(dt1_1/j)
pre_Y=clf_1.predict(X)
recall_1=sklearn.metrics.recall_score(Y,pre_Y,pos_label='M')
precision_1=sklearn.metrics.precision_score(Y,pre_Y,pos_label='M')
print(DecisionTreeClassifier.get_depth(clf_1))
print(recall_1, precision_1)

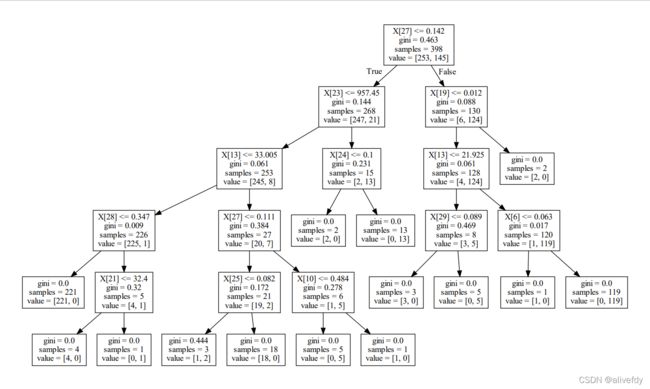
附上一张本次决策树的代码图(使用CART算法的)
dot_data = tree.export_graphviz(clf, out_file=None)
graph = graphviz.Source(dot_data)
graph.render("cancer_0")
https://www.cnblogs.com/bourneli/archive/2013/03/15/2961568.html
https://zhuanlan.zhihu.com/p/30059442
https://archive.ics.uci.edu/ml/datasets/Breast+Cancer+Wisconsin+%28Diagnostic%29