Opencv 仿射变换原理代码解析
- 仿射变换原理
仿射变换是线性变换,有一张图可以很好地展示放射变换的效果

其实仿射变换是透视变换的一种特例,但是透视变换的自由度更高,3*3的矩阵表示,透视变换的自由度是8,而放射变换可以用2*3的矩阵表示,【A B】 A是2*2的旋转部分+缩放因子S,而B是平移部分+缩放因子,是一个5个自由度的参数矩阵。
典型的放射变换包括平移,缩放和旋转。
其中Opencv中的旋转由于是绕某个图像坐标进行旋转,因此整个旋转的流程可以理解为平移—》旋转—》平移

最后可以得到旋转变换矩阵

而对于特定的放射矩阵W,opencv的求逆矩阵方法是分块矩阵求逆矩阵,注意不能想当然得将平移部分参数取反,因为平移因子是经过一些列的旋转操作后的参数,除非矩阵只有平移部分。
记录下分块矩阵求逆矩阵公式,摘自知乎帖子




知乎对仿射变换的解释,带交互动画的:https://www.zhihu.com/question/20666664
- Opencv源码
实现仿射变换和实现其他resize的插值函数是类似的,需要求出目标图像像素在原图像中的位置,获得对应点的像素值。插值的方式有多种,一般常见的有最近邻插值,双线性插值(Bilinear)https://www.cnblogs.com/yssongest/p/5303151.html,三次样条曲线(Cubic Spline)。
源码中一下部分用于求输入仿射矩阵的逆矩阵
if( !(flags & WARP_INVERSE_MAP) )
{
double D = M[0]*M[4] - M[1]*M[3];
D = D != 0 ? 1./D : 0;
double A11 = M[4]*D, A22=M[0]*D;
M[0] = A11; M[1] *= -D;
M[3] *= -D; M[4] = A22;
double b1 = -M[0]*M[2] - M[1]*M[5];
double b2 = -M[3]*M[2] - M[4]*M[5];
M[2] = b1; M[5] = b2;
}先对2*2矩阵求逆矩阵,然后对1*2的块求逆。
执行仿射变换的代码:
void cv::warpAffine( InputArray _src, OutputArray _dst,
InputArray _M0, Size dsize,
int flags, int borderType, const Scalar& borderValue )
{
.....
//计算X分量的数值
for( x = 0; x < dst.cols; x++ )
{
adelta[x] = saturate_cast(M[0]*x*AB_SCALE);
bdelta[x] = saturate_cast(M[3]*x*AB_SCALE);
}
Range range(0, dst.rows);
WarpAffineInvoker invoker(src, dst, interpolation, borderType,
borderValue, adelta, bdelta, M);
parallel_for_(range, invoker, dst.total()/(double)(1<<16));
.....
}
class WarpAffineInvoker :
public ParallelLoopBody
{
public:
WarpAffineInvoker(const Mat &_src, Mat &_dst, int _interpolation, int _borderType,
const Scalar &_borderValue, int *_adelta, int *_bdelta, double *_M) :
ParallelLoopBody(), src(_src), dst(_dst), interpolation(_interpolation),
borderType(_borderType), borderValue(_borderValue), adelta(_adelta), bdelta(_bdelta),
M(_M)
{
}
virtual void operator() (const Range& range) const
{
const int BLOCK_SZ = 64;
//XY 是映射坐标矩阵,但是是分Block进行计算,分块意义在于SSE进行访问加速
//A 是remap函数使用到的参数,和插值有关系,没有进一步深入
short XY[BLOCK_SZ*BLOCK_SZ*2], A[BLOCK_SZ*BLOCK_SZ];
const int AB_BITS = MAX(10, (int)INTER_BITS);
//AB_BITS 为10,放大1024倍
const int AB_SCALE = 1 << AB_BITS;
//round_delta 计算结果为16...
int round_delta = interpolation == INTER_NEAREST ? AB_SCALE/2 : AB_SCALE/INTER_TAB_SIZE/2, x, y, x1, y1;
#if CV_SSE2
bool useSSE2 = checkHardwareSupport(CV_CPU_SSE2);
#endif
#if CV_SSE4_1
bool useSSE4_1 = checkHardwareSupport(CV_CPU_SSE4_1);
#endif
//获得图像单个Block不越界的访问区域
int bh0 = std::min(BLOCK_SZ/2, dst.rows);
int bw0 = std::min(BLOCK_SZ*BLOCK_SZ/bh0, dst.cols);
bh0 = std::min(BLOCK_SZ*BLOCK_SZ/bw0, dst.rows);
//全图高度访问(rows),
for( y = range.start; y < range.end; y += bh0 )
{
//先访问cols(x),x += bw0每次增加1个Block的宽度
for( x = 0; x < dst.cols; x += bw0 )
{
int bw = std::min( bw0, dst.cols - x);
int bh = std::min( bh0, range.end - y);
//单个Block的映射坐标矩阵
Mat _XY(bh, bw, CV_16SC2, XY), matA;
//目标图像的某一个Block
Mat dpart(dst, Rect(x, y, bw, bh));
//再访问rows(y1)
for( y1 = 0; y1 < bh; y1++ )
{
//xy 是映射坐标矩阵的指针
short* xy = XY + y1*bw*2;
//计算包含y部分的分量
int X0 = saturate_cast((M[1]*(y + y1) + M[2])*AB_SCALE) + round_delta;
int Y0 = saturate_cast((M[4]*(y + y1) + M[5])*AB_SCALE) + round_delta;
if( interpolation == INTER_NEAREST )
{
x1 = 0;
#if CV_NEON
int32x4_t v_X0 = vdupq_n_s32(X0), v_Y0 = vdupq_n_s32(Y0);
for( ; x1 <= bw - 8; x1 += 8 )
{
int16x8x2_t v_dst;
v_dst.val[0] = vcombine_s16(vqmovn_s32(vshrq_n_s32(vaddq_s32(v_X0, vld1q_s32(adelta + x + x1)), AB_BITS)),
vqmovn_s32(vshrq_n_s32(vaddq_s32(v_X0, vld1q_s32(adelta + x + x1 + 4)), AB_BITS)));
v_dst.val[1] = vcombine_s16(vqmovn_s32(vshrq_n_s32(vaddq_s32(v_Y0, vld1q_s32(bdelta + x + x1)), AB_BITS)),
vqmovn_s32(vshrq_n_s32(vaddq_s32(v_Y0, vld1q_s32(bdelta + x + x1 + 4)), AB_BITS)));
vst2q_s16(xy + (x1 << 1), v_dst);
}
#elif CV_SSE4_1
if (useSSE4_1)
{
__m128i v_X0 = _mm_set1_epi32(X0);
__m128i v_Y0 = _mm_set1_epi32(Y0);
for ( ; x1 <= bw - 16; x1 += 16)
{
__m128i v_x0 = _mm_packs_epi32(_mm_srai_epi32(_mm_add_epi32(v_X0, _mm_loadu_si128((__m128i const *)(adelta + x + x1))), AB_BITS),
_mm_srai_epi32(_mm_add_epi32(v_X0, _mm_loadu_si128((__m128i const *)(adelta + x + x1 + 4))), AB_BITS));
__m128i v_x1 = _mm_packs_epi32(_mm_srai_epi32(_mm_add_epi32(v_X0, _mm_loadu_si128((__m128i const *)(adelta + x + x1 + 8))), AB_BITS),
_mm_srai_epi32(_mm_add_epi32(v_X0, _mm_loadu_si128((__m128i const *)(adelta + x + x1 + 12))), AB_BITS));
__m128i v_y0 = _mm_packs_epi32(_mm_srai_epi32(_mm_add_epi32(v_Y0, _mm_loadu_si128((__m128i const *)(bdelta + x + x1))), AB_BITS),
_mm_srai_epi32(_mm_add_epi32(v_Y0, _mm_loadu_si128((__m128i const *)(bdelta + x + x1 + 4))), AB_BITS));
__m128i v_y1 = _mm_packs_epi32(_mm_srai_epi32(_mm_add_epi32(v_Y0, _mm_loadu_si128((__m128i const *)(bdelta + x + x1 + 8))), AB_BITS),
_mm_srai_epi32(_mm_add_epi32(v_Y0, _mm_loadu_si128((__m128i const *)(bdelta + x + x1 + 12))), AB_BITS));
_mm_interleave_epi16(v_x0, v_x1, v_y0, v_y1);
_mm_storeu_si128((__m128i *)(xy + x1 * 2), v_x0);
_mm_storeu_si128((__m128i *)(xy + x1 * 2 + 8), v_x1);
_mm_storeu_si128((__m128i *)(xy + x1 * 2 + 16), v_y0);
_mm_storeu_si128((__m128i *)(xy + x1 * 2 + 24), v_y1);
}
}
#endif
for( ; x1 < bw; x1++ )
{
int X = (X0 + adelta[x+x1]) >> AB_BITS;
int Y = (Y0 + bdelta[x+x1]) >> AB_BITS;
xy[x1*2] = saturate_cast(X);
xy[x1*2+1] = saturate_cast(Y);
}
}
else
{
short* alpha = A + y1*bw;
x1 = 0;
#if CV_SSE2
if( useSSE2 )
{
__m128i fxy_mask = _mm_set1_epi32(INTER_TAB_SIZE - 1);
//XX 计算的是M1*dy+M2
//YY 计算的是M4*dy+M5
__m128i XX = _mm_set1_epi32(X0), YY = _mm_set1_epi32(Y0);
for( ; x1 <= bw - 8; x1 += 8 )
{
__m128i tx0, tx1, ty0, ty1;
//分别取4个整数进行X和Y(映射坐标)的计算,一共8个
tx0 = _mm_add_epi32(_mm_loadu_si128((const __m128i*)(adelta + x + x1)), XX);
ty0 = _mm_add_epi32(_mm_loadu_si128((const __m128i*)(bdelta + x + x1)), YY);
tx1 = _mm_add_epi32(_mm_loadu_si128((const __m128i*)(adelta + x + x1 + 4)), XX);
ty1 = _mm_add_epi32(_mm_loadu_si128((const __m128i*)(bdelta + x + x1 + 4)), YY);
//右移5位
tx0 = _mm_srai_epi32(tx0, AB_BITS - INTER_BITS);
ty0 = _mm_srai_epi32(ty0, AB_BITS - INTER_BITS);
tx1 = _mm_srai_epi32(tx1, AB_BITS - INTER_BITS);
ty1 = _mm_srai_epi32(ty1, AB_BITS - INTER_BITS);
//fx_和fy_是remap的参数
__m128i fx_ = _mm_packs_epi32(_mm_and_si128(tx0, fxy_mask),
_mm_and_si128(tx1, fxy_mask));
__m128i fy_ = _mm_packs_epi32(_mm_and_si128(ty0, fxy_mask),
_mm_and_si128(ty1, fxy_mask));
//_mm_packs_epi32函数是将32bit有符号整数合成为16bit有符号整数
tx0 = _mm_packs_epi32(_mm_srai_epi32(tx0, INTER_BITS),
_mm_srai_epi32(tx1, INTER_BITS));
ty0 = _mm_packs_epi32(_mm_srai_epi32(ty0, INTER_BITS),
_mm_srai_epi32(ty1, INTER_BITS));
fx_ = _mm_adds_epi16(fx_, _mm_slli_epi16(fy_, INTER_BITS));
//_mm_unpacklo_epi16函数是将16bit有符号整数交错地进行放置,以16bit为步长分开
//_mm_storeu_si128相当于memcpy
_mm_storeu_si128((__m128i*)(xy + x1*2), _mm_unpacklo_epi16(tx0, ty0));
_mm_storeu_si128((__m128i*)(xy + x1*2 + 8), _mm_unpackhi_epi16(tx0, ty0));
_mm_storeu_si128((__m128i*)(alpha + x1), fx_);
}
}
#elif CV_NEON
int32x4_t v__X0 = vdupq_n_s32(X0), v__Y0 = vdupq_n_s32(Y0), v_mask = vdupq_n_s32(INTER_TAB_SIZE - 1);
for( ; x1 <= bw - 8; x1 += 8 )
{
int32x4_t v_X0 = vshrq_n_s32(vaddq_s32(v__X0, vld1q_s32(adelta + x + x1)), AB_BITS - INTER_BITS);
int32x4_t v_Y0 = vshrq_n_s32(vaddq_s32(v__Y0, vld1q_s32(bdelta + x + x1)), AB_BITS - INTER_BITS);
int32x4_t v_X1 = vshrq_n_s32(vaddq_s32(v__X0, vld1q_s32(adelta + x + x1 + 4)), AB_BITS - INTER_BITS);
int32x4_t v_Y1 = vshrq_n_s32(vaddq_s32(v__Y0, vld1q_s32(bdelta + x + x1 + 4)), AB_BITS - INTER_BITS);
int16x8x2_t v_xy;
v_xy.val[0] = vcombine_s16(vqmovn_s32(vshrq_n_s32(v_X0, INTER_BITS)), vqmovn_s32(vshrq_n_s32(v_X1, INTER_BITS)));
v_xy.val[1] = vcombine_s16(vqmovn_s32(vshrq_n_s32(v_Y0, INTER_BITS)), vqmovn_s32(vshrq_n_s32(v_Y1, INTER_BITS)));
vst2q_s16(xy + (x1 << 1), v_xy);
int16x4_t v_alpha0 = vmovn_s32(vaddq_s32(vshlq_n_s32(vandq_s32(v_Y0, v_mask), INTER_BITS),
vandq_s32(v_X0, v_mask)));
int16x4_t v_alpha1 = vmovn_s32(vaddq_s32(vshlq_n_s32(vandq_s32(v_Y1, v_mask), INTER_BITS),
vandq_s32(v_X1, v_mask)));
vst1q_s16(alpha + x1, vcombine_s16(v_alpha0, v_alpha1));
}
#endif
//SSE不能访问的部分用常规方式遍历
for( ; x1 < bw; x1++ )
{
int X = (X0 + adelta[x+x1]) >> (AB_BITS - INTER_BITS);
int Y = (Y0 + bdelta[x+x1]) >> (AB_BITS - INTER_BITS);
xy[x1*2] = saturate_cast(X >> INTER_BITS);
xy[x1*2+1] = saturate_cast(Y >> INTER_BITS);
alpha[x1] = (short)((Y & (INTER_TAB_SIZE-1))*INTER_TAB_SIZE +
(X & (INTER_TAB_SIZE-1)));
}
}
}
//对单个Block进行重映射计算
if( interpolation == INTER_NEAREST )
remap( src, dpart, _XY, Mat(), interpolation, borderType, borderValue );
else
{
Mat _matA(bh, bw, CV_16U, A);
remap( src, dpart, _XY, _matA, interpolation, borderType, borderValue );
}
}
}
}
private:
Mat src;
Mat dst;
int interpolation, borderType;
Scalar borderValue;
int *adelta, *bdelta;
double *M;
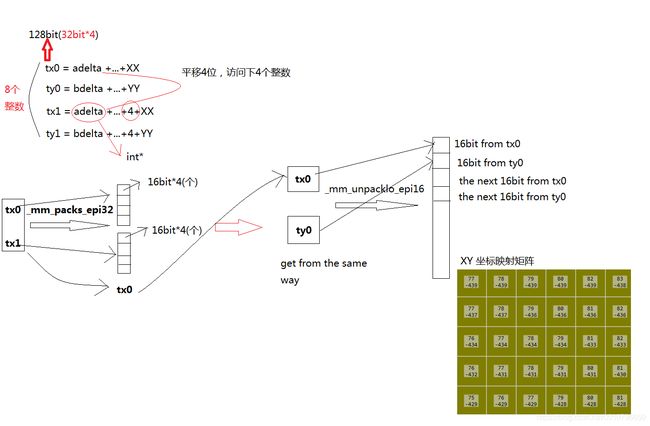
}; 当中涉及到SSE计算的原理图。
- 图像旋转和平移
以图像中某一个点为原点旋转,可以通过opencv cv::getRotationMatrix2D(Center, angle, 1);函数获得仿射变换需要的旋转矩阵,注意是2*3的矩阵;添加平移矩阵的就比较简单,构造一个3*3的平移矩阵和旋转矩阵相乘,在进行仿射变换就OK了,因为仿射变换内部就是通过求解输入矩阵的逆矩阵,得到映射矩阵,从而知道dst的图像各个像素点在原图像中的坐标。