数字语音处理期中报告——音频信号分析与合成(MATLAB线性预测LPC)
目录
- 一级目录
-
- 二级目录
-
- 三级目录
- 一.实验要求
-
- 第一题:线性预测和确定共振峰
- 第二题:交叉合成
- 二.实验步骤
-
- 题目一
- 题目二
- 三.实验原理
- 四.实验结果
-
- 题目一:
- 题目二:
- 五.实验分析
一级目录
二级目录
三级目录
一.实验要求
第一题:线性预测和确定共振峰
第二题:交叉合成
其他:请提交不超过 8 页的完整报告。必要时使用伪代码,方程式和数字进行解释。
二.实验步骤
题目一
(a)找到一个安静的房间,用 16 kHz / 16 位/单声道录制自己的英语元音“ / a /,/ɛ/,/ i /,/ɔ/,/ u /”发音,中,尽可能稳定,清晰地发音。
(b)屏蔽信号并为每帧进行 LP 分析。
参考:检查函数 A = lpc(frame,order),该函数返回 A 中的线性预测系数的列表。
(c)在 1/ A(z)的幅度谱中找到峰值,这是声道滤波器的脉冲响应的 z 变换。
参考:使用 H = freqz(1,A,N,fs),然后在 abs(H)中找到局部最大值。
(d)绘制每个元音的第一和第二共振峰(f1、f2)的频率。
(e)请你的一位朋友也重复上面的过程,画出他(她)的 f1-f2 分布图。讨论与你的图是否一致?如果不一致,有哪些特征不同?
(f)基于此方法,每个元音在特征空间(f1-f2)中的聚类效果如何? 利用这种方法自动识别元音是否可行?
题目二
(a)你们每个人都以接听电话的方式记录自己的声音,说“喂”。
(b)对您所说的“喂”进行 LP 分析。分别存储 LP 系数以及得到的估计误差信号 e [n]。
(c)用你的 e [n]和你同伴的进行交叉合成。
(d)应用必要的信号处理技巧,使结果听起来尽可能自然。请注意,你的话语可能与你同伴的话语长度不同,请解决类似的问题。
(e)如果你对声音的自然性感到满意,请讨论结果听起来更像你的声音还是你同伴的声音。
三.实验原理
语音序列为缓变的随机序列,可近似用信号模型化方法分析。
信号模型化的思想建立的语音信号的产生模型。
将辐射、声道、声门激励的谱效应简化为时变数字滤波器,其稳态系统函数为:
H ( z ) = X ( z ) U ( z ) = G 1 − ∑ i = 1 p a i z − i H(z)=\frac{X(z)}{U(z)}=\frac{G}{1-\sum_{i=1}^{p}{a_iz^{-i}}} H(z)=U(z)X(z)=1−∑i=1paiz−iG
语音信号x(n)被模型化为一个过程序列。浊音激励为准周期冲激序列,清音激励为白噪声序列。H(z)称为合成滤波器。模型参数:浊/清音判决、基音周期、增益常数G、数字滤波器参数a1,a2,…,ap。
基本问题是从语音信号序列确定一组LPC系数。预测系数的估计须在一短段(帧)语音信号的范围内进行。
四.实验结果
题目一:
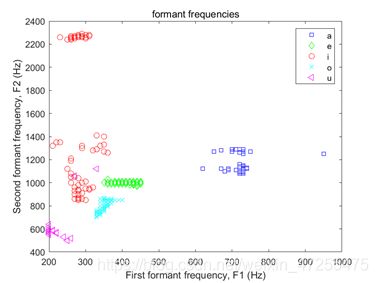
对信号进行LPC分析后,我的每个元音的第一第二共振峰的频率分布。
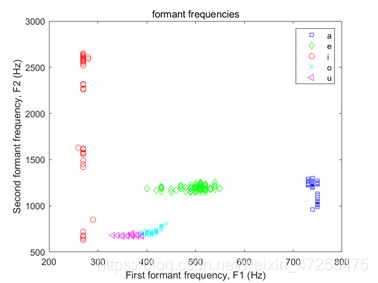
我同伴的每个元音的第一和第二共振峰(f1、f2)的频率分布。
题目二:
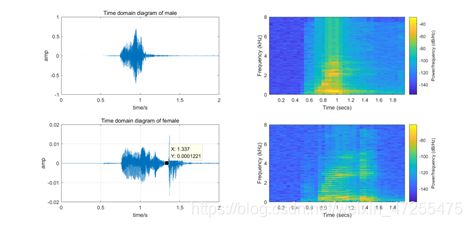
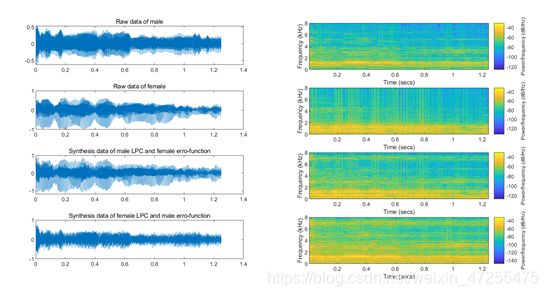
首先通过时域图像和频谱特征对音频信息进行预处理,包括语音信息的截取、归一化,上图为预处理前男声女生时域和音谱图,下图为与处理后图像。
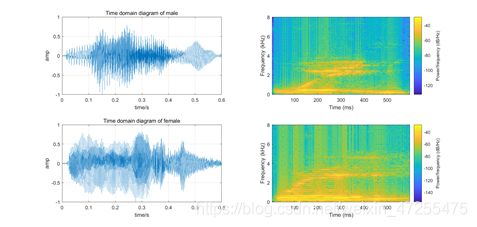
对男女声分别进行LPC分析得到对应的LP系数和相应的误差函数,对其进行交叉合成,得到合成的音频信号。通过辨识后判断声音更像误差函数提供者。进一步的,为了使结果更有说服力,通过修改代码,将合成前后的音频机器音谱图绘制出来,(此处合成的是男女声的“/ a /”)如下:
五.实验分析
由第一题图可知我的元音/ a /,/ɛ/,/ɔ/,/ u /比/ i /聚类效果较好很多,我的同伴图像中/ɛ/,/ i /,/ɔ/,/ u /比/ a /聚类效果要好。
由第二题导出的音频以及相应的时域和音谱图可知交叉合成的声音更像误差函数提供者的声音,并且相同的元音音节即使是对于不同的人都有着较为接近的共振峰,即意味着有着相似的LP系数。
为了更加清晰地看到分类效果,使用MATLAB自带的classification learner APP对第一组数据进行分类。分别使用分析树、SVM和KNN的方法进行分类训练,性能对比如下:

对于本数据,使用SVM方法精度较高,下图为其散点图和混淆矩阵。
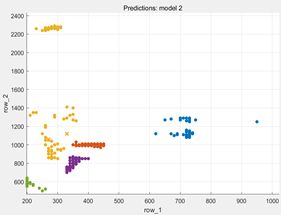
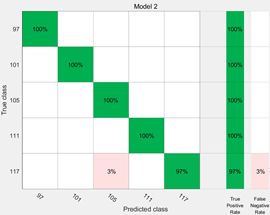
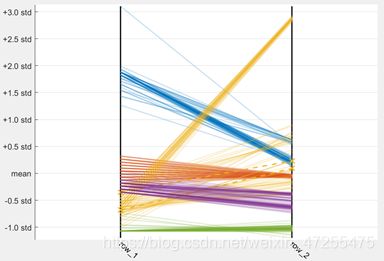
散点图某一音节对应区域的散点被认为是相应音节,并且使用以下平行坐标图可以更加清晰地看到第一和第二共振峰的各自的分布特点。
 代码见以下链接(想要可以私聊哦): https://download.csdn.net/download/weixin_47255475/13115539.
代码见以下链接(想要可以私聊哦): https://download.csdn.net/download/weixin_47255475/13115539.