图像分类的 PyTorch 实现 (CIFAR10)
图像分类是最基本的问题之一,对于人类大脑来说可能是微不足道的,但对于计算机来说却似乎是不可能完成的任务。但是只要有正确的技巧,这是很容易做到的!
本文的目的是简要介绍如何在 PyTorch 的帮助下开始任何图像分类任务。我采用了一个相当简单的线性层次结构,因此关注的是广泛的想法,而不是细节,比如卷积神经网络。
好了,让我们开始吧。
我假设你已经安装了 PyTorch,并可以正确调用gpu进行任务的执行。当然也可以在 Kaggle 或者 Google Colab 提供的免费计算机上运行这个程序。他们是相当容易安装,并且通过 import torch 命令便可以顺利进行导入。好了,让我们进入有趣的部分。
尝试多种不同的神经网络架构来解决问题的能力使得深度学习变得非常强大,尤其是相对于像线性回归、 Logit模型等浅层学习技术而言。在本教程中,我们将首先试验一个线性网络,然后尝试一个卷积设置。
数据集: CIFAR10。CIFAR-10数据集由10个类别的60000张32x32彩色图像组成,每个类别有6000张图像。有50000张训练图片和10000张测试图片。
该数据集被分为五个训练批次和一个测试批次,每个批次有10000张图像。这个测试批处理包含从每个类中随机选择的1000张图像。训练批次包含随机顺序的剩余图像,但某些训练批次可能包含来自一个类的图像多于另一个类的图像。在他们之间,训练批次包含来自每个类别中的5000张图像。
导入所需的库:
import torch
import torchvision
import numpy as np
import matplotlib.pyplot as plt
import torch.nn as nn
import torch.nn.functional as F
from torchvision.datasets import CIFAR10
from torchvision.transforms import ToTensor
from torchvision.utils import make_grid
from torch.utils.data.dataloader import DataLoader
from torch.utils.data import random_split
%matplotlib inline
现在让我们来看看我们一直在讨论的数据集:
dataset = CIFAR10(root='data/', download=True, transform=ToTensor())
test_dataset = CIFAR10(root='data/', train=False, transform=ToTensor())
Downloading https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz to data/cifar-10-python.tar.gz
HBox(children=(FloatProgress(value=1.0, bar_style='info', max=1.0), HTML(value='')))Extracting data/cifar-10-python.tar.gz to data/
让我们首先了解一下我们刚刚下载的这个数据集。首先我们来看看我们在这里处理了多少图像:
dataset_size = len(dataset)
dataset_size
50000数据集中测试集有多少?
test_dataset_size = len(test_dataset)
test_dataset_size
10000现在让我们看一下数据集中存在的类别。这些是现在图像的类型,或者给图像的标签。
classes = dataset.classes
classes
['airplane',
'automobile',
'bird',
'cat',
'deer',
'dog',
'frog',
'horse',
'ship',
'truck']理解数据集中的每个实例是如何表示的,对于理解如何在后面的代码中操作张量也是非常重要的。
img, label = dataset[0]
img_shape = img.shape
img_shape
torch.Size([3, 32, 32])Matplotlib 希望通道是图像张量的最后一个维度(而在 PyTorch 中它们是第一个维度) ,因此我们将使用.permute方法把通道移动到图像的最后一个维度。让我们打印图像的标签。
img, label = dataset[0]
plt.imshow(img.permute((1, 2, 0)))
print('Label (numeric):', label)
print('Label (textual):', classes[label])
Label (numeric): 6 Label (textual): frog

为训练准备数据
我们将使用一个包含5000张图像(数据集的10%)的验证集。为了确保每次获得相同的验证集,我们将 PyTorch 的随机数生成器的种子设置为43。
torch.manual_seed(43)
val_size = 5000
train_size = len(dataset) - val_size
让我们使用 random _ split 方法来创建训练集和验证集。每次运行此函数时,每个函数中的数据都是随机分布的。
train_ds, val_ds = random_split(dataset, [train_size, val_size])
len(train_ds), len(val_ds)
(45000, 5000)我们将batch size设置为128。
batch_size=128
现在,我们可以使用 DataLoader 按照上面定义的大小批量从数据集加载数据。这些参数是不言自明的。
train_loader = DataLoader(train_ds, batch_size, shuffle=True, num_workers=4, pin_memory=True)
val_loader = DataLoader(val_ds, batch_size*2, num_workers=4, pin_memory=True)
test_loader = DataLoader(test_dataset, batch_size*2, num_workers=4, pin_memory=True)
现在我们可以将数据可视化:
for images, _ in train_loader:
print('images.shape:', images.shape)
plt.figure(figsize=(16,8))
plt.axis('off')
plt.imshow(make_grid(images, nrow=16).permute((1, 2, 0)))
break
images.shape: torch.Size([128, 3, 32, 32])

很明显,当我们想要用肉眼识别图像的内容时,32x32像素的分辨率并不是最好的,这让我们明白了手头任务的难度。
现在我们可以创建一个基本模型类:
这个类将包含除了模型架构以外的所有内容,即它不会包含 __init__ 和 __forward__ 方法。稍后我们将扩展这个类来尝试不同的体系结构。事实上,你可以扩展这个模型来解决任何图像分类问题。
def accuracy(outputs, labels):
_, preds = torch.max(outputs, dim=1)
return torch.tensor(torch.sum(preds == labels).item() / len(preds))
class ImageClassificationBase(nn.Module):
def training_step(self, batch):
images, labels = batch
out = self(images) # Generate predictions
loss = F.cross_entropy(out, labels) # Calculate loss
return loss
def validation_step(self, batch):
images, labels = batch
out = self(images) # Generate predictions
loss = F.cross_entropy(out, labels) # Calculate loss
acc = accuracy(out, labels) # Calculate accuracy
return {'val_loss': loss.detach(), 'val_acc': acc}
def validation_epoch_end(self, outputs):
batch_losses = [x['val_loss'] for x in outputs]
epoch_loss = torch.stack(batch_losses).mean() # Combine losses
batch_accs = [x['val_acc'] for x in outputs]
epoch_acc = torch.stack(batch_accs).mean() # Combine accuracies
return {'val_loss': epoch_loss.item(), 'val_acc': epoch_acc.item()}
def epoch_end(self, epoch, result):
print("Epoch [{}], val_loss: {:.4f}, val_acc: {:.4f}".format(epoch, result['val_loss'], result['val_acc']))
我们在上面已经做了4个函数,我们将在后面的代码中使用它们。前两个函数分别帮助我们计算模型在每个阶段、训练期间和在验证数据集上测试期间的损失。我们用 cross_entropy 来衡量损失。它也常被称为 log loss。它度量了输出为0到1之间的概率值的分类模型的性能。Cross-entropy loss 随着预测的概率偏离实际标记而增加。其他损耗测量方法有 L1 loss、平滑 L1 loss等,但在分类方面,交叉熵损失效果最好。
现在你可能会有这样一个问题:.detach() 可以做什么?那么,当我们使用 loss.backwards() 计算和设置自动梯度下降,正如我们将在后面的代码中使用.fit()函数一样,最终的损失张量包含到该点之前的整个计算图的引用。我们分批计算损失,因此在每个点上,前面的变量不再有用,因此只占用内存,如果这个 detach 没有完成,内存最终会用完。
最后一个函数只是用来打印每次迭代的损失和准确性。
现在我们定义另外两个函数:
def evaluate(model, val_loader):
outputs = [model.validation_step(batch) for batch in val_loader]
return model.validation_epoch_end(outputs)
def fit(epochs, lr, model, train_loader, val_loader, opt_func=torch.optim.SGD):
history = []
optimizer = opt_func(model.parameters(), lr)
for epoch in range(epochs):
# Training Phase
for batch in train_loader:
loss = model.training_step(batch)
loss.backward()
optimizer.step()
optimizer.zero_grad()
# Validation phase
result = evaluate(model, val_loader)
model.epoch_end(epoch, result)
history.append(result)
return history
evaluate 调用每个批处理的 validation _step ()并返回输出。
fit 在这里是很重要的功能。它是执行训练的功能。模型经过训练后,就可以用来做预测。在这个函数中使用的优化是随机梯度下降。它比普通的神经网络/梯度下降法下降法性能更好,因为在处理这样的简单神经网络时,优化技术是必不可少的。如上所述,我们可以看到这里正在执行 loss.backward() 函数调用。这就是学习重量发生的地方。这将一直持续到我们指定的时期的数量,并且权重将根据我们指定的学习速度而改变。这发生在内部的 for 循环中。然后对验证数据集进行相同的处理。我们在一个叫做 history 的变量中记录这种学习。
转移到 GPU
这段代码完全可以在 CPU 上运行,但是如果你有一个 GPU,那么这就是你闪耀的时刻。就并行计算的速度而言,GPU 比 CPU 有优势,并且在深度学习问题中非常有用。
torch.cuda.is_available()
Truedef get_default_device():
"""Pick GPU if available, else CPU"""
if torch.cuda.is_available():
return torch.device('cuda')
else:
return torch.device('cpu')
device = get_default_device()
device
device(type='cuda')现在我们将所有张量移动到 GPU:
def to_device(data, device):
"""Move tensor(s) to chosen device"""
if isinstance(data, (list,tuple)):
return [to_device(x, device) for x in data]
return data.to(device, non_blocking=True)
class DeviceDataLoader():
"""Wrap a dataloader to move data to a device"""
def __init__(self, dl, device):
self.dl = dl
self.device = device
def __iter__(self):
"""Yield a batch of data after moving it to device"""
for b in self.dl:
yield to_device(b, self.device)
def __len__(self):
"""Number of batches"""
return len(self.dl)
在讨论这个问题的同时,让我们也定义一些辅助函数,以便在回顾 epoch 时直观地表示我们的损失和预测的准确性。
def plot_losses(history):
losses = [x['val_loss'] for x in history]
plt.plot(losses, '-x')
plt.xlabel('epoch')
plt.ylabel('loss')
plt.title('Loss vs. No. of epochs')
def plot_accuracies(history):
accuracies = [x['val_acc'] for x in history]
plt.plot(accuracies, '-x')
plt.xlabel('epoch')
plt.ylabel('accuracy')
plt.title('Accuracy vs. No. of epochs')
将数据移动到设备:
train_loader = DeviceDataLoader(train_loader, device)
val_loader = DeviceDataLoader(val_loader, device)
test_loader = DeviceDataLoader(test_loader, device)
训练模型
所以我们做了一个模型。但它现在知道什么了吗?没有。我们需要它来学习。让我们来训练它。
还记得我们一开始检查的每个图像的尺寸吗?让我们在一个变量中定义它。还记得有10个输出类吗?这就是我们网络的输出规模。
input_size = 3*32*32
output_size = 10
这是我们模型的架构。这里我们继续使用线性层。没有偏差的线性层能够学习输出和输入之间的平均相关率,例如,如果 x 和 y 正相关 = > w 将为正,如果 x 和 y 负相关 = > w 将为负。如果 x 和 y 是完全独立的 = > w 大约是0。
class CIFAR10Model(ImageClassificationBase):
def __init__(self):
super().__init__()
self.linear1 = nn.Linear(input_size,256)
self.linear2 = nn.Linear(256,128)
self.linear3 = nn.Linear(128,64)
self.linear4 = nn.Linear(64,output_size)
def forward(self, xb):
# Flatten images into vectors
out = xb.view(xb.size(0), -1)
# Apply layers & activation functions
out = self.linear1(out)
out = F.leaky_relu(out)
out = self.linear2(out)
out = F.leaky_relu(out)
out = self.linear3(out)
out = F.leaky_relu(out)
out = self.linear4(out)
# out = F.leaky_relu(out)
# out = self.linear5(out)
# out = F.leaky_relu(out)
# out = self.linear6(out)
# out = F.leaky_relu(out)
return out
# def __init__(self):
# super().__init__()
# self.linear1 = nn.Linear(input_size,3)
# self.conv1 = nn.Conv2d(3, 6, 5)
# self.pool = nn.MaxPool2d(2, 2)
# self.conv2 = nn.Conv2d(6, 16, 5)
# self.fc1 = nn.Linear(16 * 5 * 5, 120)
# self.fc2 = nn.Linear(120, 84)
# self.fc3 = nn.Linear(84, output_size)
# def forward(self, x):
# x = self.pool(F.relu(self.conv1(x)))
# x = self.pool(F.relu(self.conv2(x)))
# x = x.view(-1, 16 * 5 * 5)
# x = F.relu(self.fc1(x))
# x = F.relu(self.fc2(x))
# x = self.fc3(x)
# return x
这里我们有一个基本的神经网络,它有3个隐藏层,大小分别为256、128和64个神经元。在尝试了各种体系结构之后,我已经用这个模型获得了最大的准确性,但是几乎可以肯定有一个更好的组合,它可能会给你比我更好的准确性。尝试并尝试最适合你的方法。
请记住,我们在这里使用的是线性层,而不是卷积层,卷积层可能执行得更好,或者像 ResNet 这样的预先训练的模型,目的是保持本文初学者友好。我将在后面的文章中肯定地介绍卷积层!
将模型移动到设备上:
model = to_device(CIFAR10Model(), device)
在训练模型之前,最好用初始权重集检查验证损失和准确性。
history = [evaluate(model, val_loader)]
history
[{'val_loss': 2.304405927658081, 'val_acc': 0.09933363646268845}]这个模型是基于最初的随机权重进行预测的,没有任何学习意识,因此准确性很差(9%)。
现在我们使用前面定义的 fit ()函数来训练模型。
history += fit(10, 0.1, model, train_loader, val_loader)
Epoch [0], val_loss: 1.9315, val_acc: 0.2963 Epoch [1], val_loss: 1.7949, val_acc: 0.3543 Epoch [2], val_loss: 1.8200, val_acc: 0.3437 Epoch [3], val_loss: 1.7746, val_acc: 0.3671 Epoch [4], val_loss: 1.6859, val_acc: 0.3958 Epoch [5], val_loss: 1.6579, val_acc: 0.4094 Epoch [6], val_loss: 1.5974, val_acc: 0.4346 Epoch [7], val_loss: 1.5938, val_acc: 0.4330 Epoch [8], val_loss: 1.5969, val_acc: 0.4377 Epoch [9], val_loss: 1.5265, val_acc: 0.4569
这里,10是 epoch 的数量,0.1是这些 epoch 的学习率。我们可以看到精度在逐渐提高。
history += fit(10, 0.01, model, train_loader, val_loader)
Epoch [0], val_loss: 1.4420, val_acc: 0.4900 Epoch [1], val_loss: 1.4420, val_acc: 0.4865 Epoch [2], val_loss: 1.4318, val_acc: 0.4911 Epoch [3], val_loss: 1.4351, val_acc: 0.4953 Epoch [4], val_loss: 1.4271, val_acc: 0.4902 Epoch [5], val_loss: 1.4245, val_acc: 0.4882 Epoch [6], val_loss: 1.4233, val_acc: 0.4911 Epoch [7], val_loss: 1.4212, val_acc: 0.4896 Epoch [8], val_loss: 1.4177, val_acc: 0.4950 Epoch [9], val_loss: 1.4127, val_acc: 0.4933
history += fit(10, 0.001, model, train_loader, val_loader)
Epoch [0], val_loss: 1.4060, val_acc: 0.4974 Epoch [1], val_loss: 1.4057, val_acc: 0.4978 Epoch [2], val_loss: 1.4065, val_acc: 0.4980 Epoch [3], val_loss: 1.4056, val_acc: 0.4966 Epoch [4], val_loss: 1.4058, val_acc: 0.4982 Epoch [5], val_loss: 1.4045, val_acc: 0.5007 Epoch [6], val_loss: 1.4048, val_acc: 0.4966 Epoch [7], val_loss: 1.4044, val_acc: 0.4978 Epoch [8], val_loss: 1.4036, val_acc: 0.4985 Epoch [9], val_loss: 1.4031, val_acc: 0.4985
history += fit(10, 0.001, model, train_loader, val_loader)
Epoch [0], val_loss: 1.4060, val_acc: 0.4974 Epoch [1], val_loss: 1.4057, val_acc: 0.4978 Epoch [2], val_loss: 1.4065, val_acc: 0.4980 Epoch [3], val_loss: 1.4056, val_acc: 0.4966 Epoch [4], val_loss: 1.4058, val_acc: 0.4982 Epoch [5], val_loss: 1.4045, val_acc: 0.5007 Epoch [6], val_loss: 1.4048, val_acc: 0.4966 Epoch [7], val_loss: 1.4044, val_acc: 0.4978 Epoch [8], val_loss: 1.4036, val_acc: 0.4985 Epoch [9], val_loss: 1.4031, val_acc: 0.4985
history += fit(20, 0.0001, model, train_loader, val_loader)
Epoch [0], val_loss: 1.4030, val_acc: 0.4976 Epoch [1], val_loss: 1.4031, val_acc: 0.4983 Epoch [2], val_loss: 1.4030, val_acc: 0.4991 Epoch [3], val_loss: 1.4029, val_acc: 0.4999 Epoch [4], val_loss: 1.4030, val_acc: 0.4987 Epoch [5], val_loss: 1.4030, val_acc: 0.4999 Epoch [6], val_loss: 1.4030, val_acc: 0.4995 Epoch [7], val_loss: 1.4028, val_acc: 0.5001 Epoch [8], val_loss: 1.4029, val_acc: 0.4995 Epoch [9], val_loss: 1.4028, val_acc: 0.5001 Epoch [10], val_loss: 1.4028, val_acc: 0.4995 Epoch [11], val_loss: 1.4028, val_acc: 0.4989 Epoch [12], val_loss: 1.4027, val_acc: 0.5003 Epoch [13], val_loss: 1.4026, val_acc: 0.4997 Epoch [14], val_loss: 1.4026, val_acc: 0.5003 Epoch [15], val_loss: 1.4026, val_acc: 0.4988 Epoch [16], val_loss: 1.4026, val_acc: 0.5003 Epoch [17], val_loss: 1.4025, val_acc: 0.5003 Epoch [18], val_loss: 1.4025, val_acc: 0.5005 Epoch [19], val_loss: 1.4025, val_acc: 0.5005
通过上面定义的图形函数,我们可以看到随着训练的继续,模型的准确性是如何提高的。
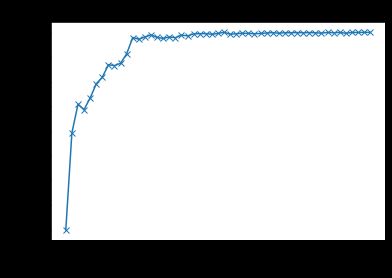
评估模型的最终性能:
evaluate(model, test_loader)
{'val_loss': 1.3559236526489258, 'val_acc': 0.517871081829071}我的模型只用了这么少的 epoch 和线性层就达到了51% 的精确度。
· END ·
HAPPY LIFE
