自监督论文阅读笔记 Self-EMD: Self-Supervised Object Detection without ImageNet
提出了一种新的自我监督表示学习方法 Self-EMD,用于目标检测。Self-EMD直接在 COCO 等未标记的非标志性图像数据集上进行训练,而不是像 ImageNet 这样常用的标志性目标图像数据集。Self-EMD将卷积特征图作为图像嵌入来 保留空间结构,并采用EMD来计算两个嵌入之间的相似性。受益于 更多未标记数据 的优点。
自监督学习流程的潜在先验 是同一图像的不同视图/裁剪对应于同一对象。因此 最大化他们的一致性 可以学习有用的特征。这个关键的先验实际上高度 依赖于预训练数据集的 潜在偏差:ImageNet 是一个以对象为中心的数据集,可确保潜在先验。
· ImageNet :由于图像被预先裁剪为以对象为中心,因此同一图像的不同裁剪来自同一对象。
· COCO: 每张图像都包含多个对象,不同的裁剪可能对应不同的对象。这种不一致的噪音可能会 损害自我监督学习方法的有效性。
从 实例级分类任务 中学习到的独特表示可能不适合对象检测。由于它应用全局池化层来生成向量嵌入,它可能会 破坏图像空间结构 并 丢失局部信息,而 检测器需要对空间定位敏感。
本文没有使用全局池化,而是 将卷积特征图作为图像嵌入,保留局部和空间信息。
离散的EMD:理想度量应该在没有对应监督的情况下 选取局部块之间的最佳匹配,并 最小化来自不相关区域的噪声。EMD 是用于计算 结构表示之间距离 的度量。
由于标记检测数据的开销远高于分类,因此对大规模标记数据的依赖仍然限制了现代目标检测器的应用。
对比学习依靠噪声对比估计来比较实例。
· MoCo [10, 4] 通过存储来自动量编码器而不是经过训练的网络的表示来改进对比方法的训练;
· SimCLR [3] 表明,如果批次足够大,可以用同一批次的元素完全替换内存库;
· BYOL [9] 和 SwAV [2] 避免比较每对图像,尤其是对于负对图像。 BYOL 通过吸引来自同一实例的不同特征直接引导表示,而SwAV将图像特征映射到一组可训练的原型向量。
实例级分类的成功实际上 依赖于 ImageNet 的潜在偏差:每张图像都以对象为中心,以确保同一图像的不同视图和裁剪对应于同一对象。如果我们考虑到 收集和清理数据 的额外工作 ,那么自我监督的“预训练”步骤实际上仍然不是免费 的。
在本文中,我们精心设计了 Self-EMD 的组件,首次成功 地将 EMD 应用于自监督学习。
跨视图框架依赖于 ImageNet 中以目标为中心的偏差,以确保不同的视图对应于同一个目标。
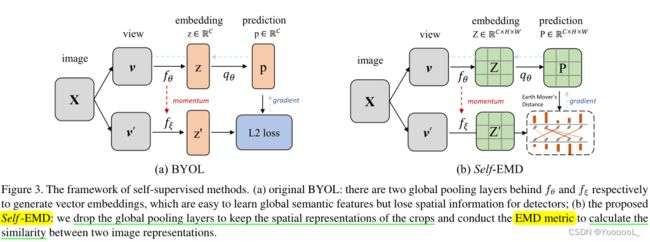
BYOL 的跨视图框架假设两个不同的视图来自同一个对象,但这种偏差仅在以对象为中心的图像上得到保证。在对未标记的 多对象图像 进行训练时,来自多对象的噪声可能会阻碍学习过程,导致检测微调任务的性能较差。此外,BYOL 和其他自监督学习方法采用 全局池化层 来生成向量嵌入,这 破坏了空间结构和局部信息。
本文 用卷积层替换 MLP 头 以保留空间特征图。使用EMD自动找到对应的映射,然后计算距离。
监督学习方法和目标检测之间的另一个差距是关于尺度不变性,因为 目标检测不仅涉及分类,还涉及定位,其中不同尺度的目标的威胁尤为明显。尺度不变性已在通用监督检测器中得到广泛探索,而在自监督学习中基本保持不变。事实上,像 BYOL 这样的自监督方法通过不同视图之间的随机尺度变换,在某种程度上隐含地学习了尺度不变的表示。
监督目标检测中一种常见的实际训练技巧是 多尺度训练,其中将输入图像调整为多尺度并分别修改注释。然而,在自监督任务中,我们 没有标签来适应训练的一致性。
Spatial Pyramid Cropping 空间金字塔裁剪 SPC for EMD :该操作使得局部特征的比较可以跨越两种不同crops的不同尺度,增强 学习到的局部表示中的 尺度信息。
网络架构:在两个编码器中使用标准的 ResNet-50 作为我们的基础骨干网。去掉全局池化层,用1×1卷积层代替MLP head中的线性层。为了计算 Eq 13中的边际权重,我们仍然将 原始 MLP 头部 作为 并行分支 来生成向量特征。
杂乱的噪声确实是自监督训练的一个问题。
单阶段检测器 RetinaNet 的改进最为显着。一个可能的原因是,对于单级检测器,局部特征表示更为重要,因为预测直接来自主干的卷积特征图。换句话说,由于 EMD 策略在预训练过程中保留了空间结构和局部信息,因此学习的表示更适合密集预测。
EMD 的工作机制 高度依赖 于卷积特征图 具有 信息语义意义 的前提条件。尽管在有监督的训练下自然会满足这样的条件,但在训练没有标签的网络时却很重要。还强调了在将 EMD 度量应用于自监督学习时marginal weights 边际权重的重要性。
但这种一致的增益表明了 尺度不变性在目标检测中的重要性。
在 COCO 上进行预训练时,我们提出的方法在更大程度上优于其他自监督方法。潜在的原因是,对于 SimCLR 和 MoCov2,它们在对比学习方式中 需要额外的负样本 ,这可能会加剧对以目标为中心的偏差的依赖。
与监督检测预训练相比,所有自监督方法都存在显着差距。这一结果表明,目前的自监督方法的好处是有限的。设计一个更好的自监督训练框架仍然是目标检测预训练的一个悬而未决的问题。
Self-EMD可以有效地 建立两个crop之间的语义对应 ,crop 1中的背景或crop 2 中的不相关区域被分配了较小的权重,从而 减轻了 训练期间的 杂乱噪声。
Conclusion:Self-EMD 将卷积特征图作为图像嵌入,然后使用离散的 Emd 来测量空间相似性。即使没有 ImageNet 数据集,Self-EMD 也能取得领先的结果。这使我们能够在未来利用更多未标记的数据。