机器学习中的时间序列预测模型
1.概述
在机器学习的各类方法中,有一类主要能用于时间序列预测的模型,包括但不限于自回归模型AR、滑动平均MA、融合AR与MA的ARIMA、隐马尔可夫模型HMM、卡尔曼滤波KF、循环神经网络RNN/LSTM等,本文对其做基本的阐述并说明其各自特点与应用场景。
2.时间序列模型
时间序列是按照一定的时间间隔排列的一组数据,其时间间隔可以是任意的时间单位,如小时、日、周、月等。比如,产品月均销售趋势、股市K线图走势、实时翻译的语音信号、机器人移动轨迹等这些数据形成了一定时间间隔且前后具有一定的延续性与关联性。 通过对这些时间序列的分析,从中发现和揭示现象发展变化的规律,然后将这些知识和信息用于预测。
比如销售量是上升还是下降,销售量是否与季节有关,是否可以根据现有的数据预测未来一年的销售额等。 对于时间序列的预测,由于很难确定它与其它变量之间的关系,这时我们就不能用回归去预测,而应使用时间序列方法进行预测。采用时间序列分析进行预测时需要一系列的模型,这种模型称为时间序列模型。以下对其分别进行阐述。时间序列对应的机器学习通常属于在线学习 online learning。
2.1 AR与MA相关模型
2.1.1 自回归模型(Auto-Regressive model)
自回归模型AR,是利用当前时刻之前若干时刻的随机变量的线性组合来描述以后某时刻随机变量的线性回归模型,自回归模型反映了序列数据当前值与前期  个数值之间(对应 阶自回归模型)的相关关系,也就是说当前值可表示为前 项数值的线性组合与白噪声序列的函数。其中白噪声可以看作随机序列,序列的均值为0。自回归模型反映了具有统计上显著的滞后自相关性。阶自回归模型的具体表达式如下
个数值之间(对应 阶自回归模型)的相关关系,也就是说当前值可表示为前 项数值的线性组合与白噪声序列的函数。其中白噪声可以看作随机序列,序列的均值为0。自回归模型反映了具有统计上显著的滞后自相关性。阶自回归模型的具体表达式如下
![]()
对于1 阶自相关性,上述模型简化为AR(1),具体如下
![]()
其中 ![]() 是独立同分布的白噪音序列,其均值为0、方差为
是独立同分布的白噪音序列,其均值为0、方差为 ![]() 。
。![]() 这部分取决于过去的观测,
这部分取决于过去的观测,![]() 是过去无法预测的部分。该模型的形式与简单线性回归模型相同,当
是过去无法预测的部分。该模型的形式与简单线性回归模型相同,当 被其对数波动率取代时,这个简单模型可广泛应用于随机波动率建模。
被其对数波动率取代时,这个简单模型可广泛应用于随机波动率建模。
2.1.2 滑动平均(Moving Average)
所谓滑动平均MA就是以一定的窗口为单位,在指定的窗口内将数据取平均,可以是简单平均也可以是加权平均。
对于简单滑动平均
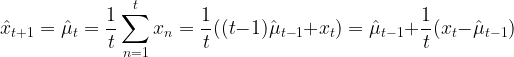
从中可以看出,一个新的估计值等于旧的估计值加上一个修正项,通常修正项的添加可适用于在线学习(online learning)的不断修正。
对于加权的滑动平均(q 阶滑动平均的通用表达式)

MA(q)模型总是平稳的,因为它是有限的白噪声过程的线性组合,只考虑滞后的前  项,相应的系数
项,相应的系数![]() 都是常数,其它项的影响系数都为0。其中 是待预测值,白噪声
都是常数,其它项的影响系数都为0。其中 是待预测值,白噪声 ![]() ,视为独立同分布的正态时间序列。
,视为独立同分布的正态时间序列。
MA模型具有可逆性(Invertibility),可逆性提供了一个简单的方法来获得冲击值(噪声序列)。零均值MA(1)模型可改写为
![]()
直观上可知, 随系数阶次的增加其影响应更小(时序距离更远),当阶次趋于无穷时相应的影响应趋于0。因此为保证MA(1)具有可逆性,通常要求 ![]() 。
。
2.1.3 指数滑动平均(Expotential Moving Average)
指数滑动平均的表达式如下
![]()
待预测值 ![]() ,对应
,对应 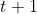 时刻,其中,
时刻,其中,![]() 。一个数据点在时间
。一个数据点在时间  步之后的影响权重为
步之后的影响权重为 ![]() 。因此随时间的推移,距离当前时刻越远的时间点的贡献呈指数下降。
。因此随时间的推移,距离当前时刻越远的时间点的贡献呈指数下降。
根据指数级数的求和
![]()
因此得到

因为 ![]() ,当
,当  时,
时, ![]() , 也就是说
, 也就是说  取值越小,对过去遗忘的越快,也就是更倾向于当前的数据。因为
取值越小,对过去遗忘的越快,也就是更倾向于当前的数据。因为 ![]() 作为初始的估计,通过比例系数修正原估计值,得到
作为初始的估计,通过比例系数修正原估计值,得到
![]()
2.1.4 ARMA(Autoregressive Moving Average)
为了克服单独的AR和MA的不足,从而解决高阶的问题,引入自回归滑动平均(ARMA)模型,也就是AR与MA的结合,具体的表达式如下:
![]()
用滞后算子来表示![]() ,得到如下表达式
,得到如下表达式

其中 ![]() 。
。 称为滞后算子,是指将一个以一定时间间隔定期采样的变量的时间指标向后移动一个单位时间。将滞后算子应用到一个泛型变量 上,得到该变量在时刻
称为滞后算子,是指将一个以一定时间间隔定期采样的变量的时间指标向后移动一个单位时间。将滞后算子应用到一个泛型变量 上,得到该变量在时刻 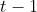 时的值,即
时的值,即![]() 。滞后算子可以提升为幂次,例如
。滞后算子可以提升为幂次,例如![]() 。也可以形成滞后算子的多项式
。也可以形成滞后算子的多项式
![]()
![]()
若![]() ,则根据等比数列求和公式可得到:
,则根据等比数列求和公式可得到:
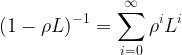
其中定义有如下关系式:
![]()
2.1.5 ARIMA(Autoregressive Moving Average)
差分自回归滑动平均模型(ARIMA),综合了三项 AR、I(integration)、MA,是在ARMA基础上改进而来的模型。
ARMA模型的平稳性要求  的均值、方差和自协方差都是与时间无关的、有限的常数,也就说ARMA模型是针对平稳时间序列建立的模型,只能处理平稳序列。
的均值、方差和自协方差都是与时间无关的、有限的常数,也就说ARMA模型是针对平稳时间序列建立的模型,只能处理平稳序列。
而ARIMA模型是针对非平稳时间序列建模。换句话说,非平稳时间序列要建立ARMA模型,首先需要经过差分转化为平稳时间序列,然后建立ARMA模型。
如果非平稳时间序列 ![]() 经过
经过  次差分后的平稳序列
次差分后的平稳序列![]() 服从ARMA(p, q)模型,那么称原始序列
服从ARMA(p, q)模型,那么称原始序列![]() 服从ARIMA(p, d, q)模型。也就是说,原始序列是
服从ARIMA(p, d, q)模型。也就是说,原始序列是![]() 序列, 次差分后是平稳序列
序列, 次差分后是平稳序列![]() 。平稳序列I(0)服从ARMA模型,而非平稳序列
。平稳序列I(0)服从ARMA模型,而非平稳序列![]() 服从ARIMA模型。
服从ARIMA模型。
基于ARMA添加差分处理,在前述模型上多了一个差分阶数需要进行确定,表达式如下:
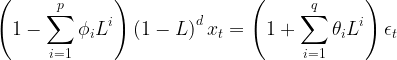
由以上分析可知,建立一个ARIMA模型需要解决以下3个问题:
(1)将非平稳序列转化为平稳序列。
(2)确定模型的形式。即模型属于AR、MA、ARMA中的哪一种,主要通过模型识别确定。
(3)确定变量的滞后阶数,即求和项。这也是通过模型识别完成的。
2.2 Prophet
Prophet是由Facebook 开发的一个流行的时间序列预测库,它拟合的是一个广义的加性模型,相应的表达式如下
![]()
其中各项的表示形式如下:
a) ![]() 表示趋势项,模拟时间序列在非周期上面的变化趋势
表示趋势项,模拟时间序列在非周期上面的变化趋势
b) 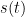 是季节项或称周期项(使用正弦基函数拟合的线性回归模型),一般以周或者年为单位
是季节项或称周期项(使用正弦基函数拟合的线性回归模型),一般以周或者年为单位
c) ![]() 是稀疏的“假日效应”可选项,表示在当天是否存在节假日,模拟节假日的特殊影响
是稀疏的“假日效应”可选项,表示在当天是否存在节假日,模拟节假日的特殊影响
d) ![]() 为可能滞后的协变量,
为可能滞后的协变量, 是回归系数,实际应用中多数情况下可不考虑这一可选项
是回归系数,实际应用中多数情况下可不考虑这一可选项
e) ![]() 是残留的噪声项,假定为iid高斯分布
是残留的噪声项,假定为iid高斯分布
Prophet 算法通过分别拟合这几项,最后把它们累加起来就得到了时间序列的预测值。
Prophet是回归模型,而不是自回归模型,因为它是给定时刻 ![]() , 预测时间序列
, 预测时间序列![]() ,并不考虑过去的观测值
,并不考虑过去的观测值 ![]() 。
。
为了对时间依赖性建模,趋势项有两个重要的函数,一个是基于逻辑回归函数(logistic function)的,另一个是基于分段线性函数(piecewise linear function)的。
对于逻辑回归函数

这里的  称为曲线的最大渐近值,表示曲线的增长率,
称为曲线的最大渐近值,表示曲线的增长率, 表示偏移项。当
表示偏移项。当![]() 时,简化为常见的 sigmoid 函数的形式。
时,简化为常见的 sigmoid 函数的形式。
实际应用中,三个参数 ![]() 不可能都为常数,而很有可能是随着时间的迁移而变化的,因此,在 Prophet 里面,Prophet原文作者考虑将这三个参数全部换成了随着时间而变化的函数,也就是
不可能都为常数,而很有可能是随着时间的迁移而变化的,因此,在 Prophet 里面,Prophet原文作者考虑将这三个参数全部换成了随着时间而变化的函数,也就是
![]()
现实的时间序列中,曲线的走势肯定不会一直保持不变,在某些特定情况或有某种潜在的周期影响下,曲线会发生变化,这个时候,就有所谓的变点检测,也就是所谓 change point detection,变点(change point)就是走势或趋势发生明显变化的点,类似于通常说的“拐点”。
对每一段的趋势和走势根据 change point 的情况而改变,由此得到分段的逻辑回归增长模型:
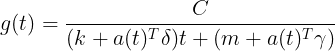
其中, ![]() 是增长率,
是增长率,![]() 是偏移量,
是偏移量,![]() ,其中
,其中![]() 是第
是第 ![]() 个变化点对应的时刻,
个变化点对应的时刻,![]() 是变化的大小,
是变化的大小,  是为了使函数保持连续的添加项。
是为了使函数保持连续的添加项。![]() 拉普拉斯先验。
拉普拉斯先验。
对于分段线性函数
此时若假定趋势函数 是分段线性的,时间轴上有S个均匀分割的变化点(changepoints),相应的表示如下:
是分段线性的,时间轴上有S个均匀分割的变化点(changepoints),相应的表示如下:
![]()
为了确保了MAP参数估计是稀疏的,因此变化点(changepoints)边界之间的差异通常为0。
季节性趋势是几乎所有的时间序列预测模型都会考虑的选项,这是因为时间序列通常会随着天,周,月,年等季节性的变化而呈现季节性的变化,也称为周期性的变化。对于周期函数而言,通常使用较多就是正弦、余弦函数。而在数学分析中,区间内的周期性函数可以通过正弦和余弦的函数的和来表示,那么![]() 就可以采用如下的傅立叶级数表示:
就可以采用如下的傅立叶级数表示:
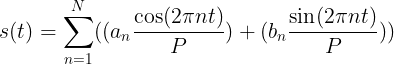
在实际环境下,除了周末,同样有很多节假日,而且不同的国家有着不同的假期。在 Prophet 里面,通过考虑一个稀疏的假日效应可选项![]() 对节假日的影响程度(节假日效应)建模。
对节假日的影响程度(节假日效应)建模。
由于每个节假日对时间序列的影响程度不一样,比如春节,国庆节是长假,元旦、劳动节是短假,不同的节假日可看成相互独立的模型,同时可以为不同的节假日设置不同的时间窗口值,表示该节假日会影响前后一段时间的时间序列。
对于第 ![]() 个节假日而言,
个节假日而言,![]() 表示该节假日的前后一段时间。为了表示节假日效应,定义一个相应的指示函数(indicator function)
表示该节假日的前后一段时间。为了表示节假日效应,定义一个相应的指示函数(indicator function)![]() ,同时分配一个参数
,同时分配一个参数 ![]() 来表示节假日的影响范围。假定有
来表示节假日的影响范围。假定有 ![]() 个节假日,那么
个节假日,那么
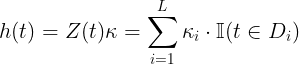
其中
![]()
![]()
其中![]() 并且该正态分布受到
并且该正态分布受到 ![]() 这个指标影响。fbprophet模型中默认值取 10,当值越大时,表示节假日对模型的影响越大;当值越小时,表示节假日对模型的效果越小。可根据自己的情况自行调整。
这个指标影响。fbprophet模型中默认值取 10,当值越大时,表示节假日对模型的影响越大;当值越小时,表示节假日对模型的效果越小。可根据自己的情况自行调整。
prophet 直观的可视化延时效果可详见 prophet 可视化。
2.3 Gaussian processes
使用高斯过程也可以进行时间序列预测。其基本思想是将未知输出量建模为时间函数![]() ,并将
,并将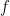 的先验表示为高斯过程;然后根据观察到的论据evidence,进一步更新之前的内容,并预测未来值。对于某些稳态核,可以将问题重新表述为线性高斯状态空间模型,如使用Kalman平滑滤波器在有限的时间内进行推测。该转换可利用Matren核精确完成,而高斯核(RBF)则可以近似地完成。实际应用中可考虑如下一个典型的高斯过程建模形成的一个复合高斯核模型:
的先验表示为高斯过程;然后根据观察到的论据evidence,进一步更新之前的内容,并预测未来值。对于某些稳态核,可以将问题重新表述为线性高斯状态空间模型,如使用Kalman平滑滤波器在有限的时间内进行推测。该转换可利用Matren核精确完成,而高斯核(RBF)则可以近似地完成。实际应用中可考虑如下一个典型的高斯过程建模形成的一个复合高斯核模型:
![]()
其中 ![]() 对应第
对应第  个核函数。
个核函数。
为了捕捉长期平滑上升趋势,我们指定  为平方指数 (SE: squared exponential) 核函数,其中
为平方指数 (SE: squared exponential) 核函数,其中  表示幅度值,
表示幅度值, 是尺度因子,得到如下形式
是尺度因子,得到如下形式
![]()
为了对周期性进行建模,我们借用了指数正弦平方核函数,周期参数设置为 1 年。 然而,由于不清楚季节性趋势是否刚好就是周期性的,我们将这个周期性核函数与另一个 SE核函数相乘,实现偏离周期性衰减的效果, 得到如下所示函数 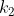 ,其中
,其中  是幅度值,
是幅度值,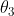 是周期性分量的衰减时间,
是周期性分量的衰减时间,![]() 是周期,
是周期,![]() 是周期分量的平滑度。
是周期分量的平滑度。
![]()
为了模拟(小)中期不规则性,我们使用如下有理二次核函数
![]()
其中![]() 是幅度,
是幅度,![]() 是典型的尺度因子,
是典型的尺度因子,![]() 是形状参数。
是形状参数。
最后一项对应独立噪声的大小,可以并入似然函数的观测噪声中。 对于相关噪声,我们使用另一个 SE 核函数

我们可以通过优化关于 的边际似然函数来拟合这个模型。
的边际似然函数来拟合这个模型。
2.4 HMM
隐马尔可夫模型(Hidden Markov model,HMM)是关于时序的概率模型,可用于序列标注问题的统计学建模,描述由一个隐马尔可夫链随机生成不可观测的状态随机序列,再由各个状态生成一个观测而产生观测随机序列的过程(因状态是隐式的所以而得名)。
隐马尔可夫链随机生成的状态的序列称作状态序列。 每个状态生成一个观测,而由此产生的观测的随机序列称作观测序列。 序列的每一个位置又可以看作是一个时刻。
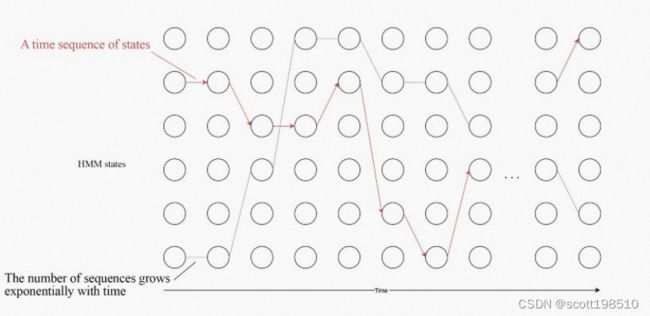
在 HMM 中,我们通过使用 和 时刻的结果来解决时刻  的预测问题。下面的圆圈表示时刻 的 HMM 隐状态
的预测问题。下面的圆圈表示时刻 的 HMM 隐状态  。因此,即使状态序列的数量随时间呈指数级增长,假定其可以随时间递归地表示计算,那么我们也可以经线性化处理求解它。
。因此,即使状态序列的数量随时间呈指数级增长,假定其可以随时间递归地表示计算,那么我们也可以经线性化处理求解它。
定义在时间 t 的观测概率为:
定义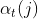 为 时刻隐状态 的前向概率,
为 时刻隐状态 的前向概率, 描述的是由前一时刻 的状态 转移到当前时刻 的状态 的概率。由于当前观测仅取决于当前状态, 可表示为:
描述的是由前一时刻 的状态 转移到当前时刻 的状态 的概率。由于当前观测仅取决于当前状态, 可表示为:

上述前向概率它表示到时刻 已知的部分观测序列为![]() ,且 时刻的状态为 的概率,实际上是一个联合概率,记作如下:
,且 时刻的状态为 的概率,实际上是一个联合概率,记作如下:
![]()
观测的似然概率![]() 可通过以下各个时间步递归计算得到
可通过以下各个时间步递归计算得到
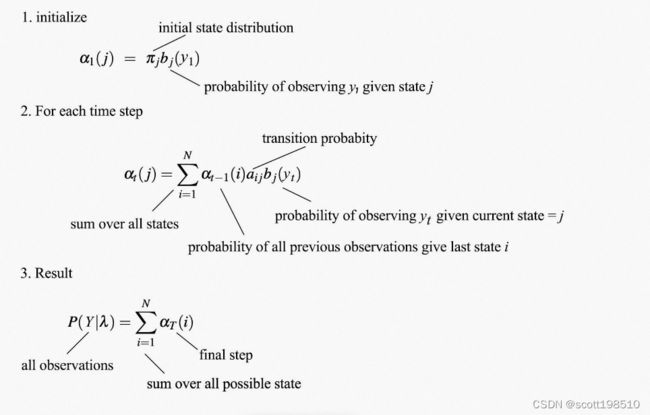
再定义后向概率,它表示在相反方向上的概率(在时间 给定状态 的情况下看到所有即将到来的观测的概率),实际上是一个条件概率,具体如下
![]()
可以用类似于 的递归方式计算,但方向相反(也称为反向算法)。
的递归方式计算,但方向相反(也称为反向算法)。
要学习 HMM 模型,我们需要知道我们处于什么状态才能最好地解释观测结果。这将是状态概率 ,也就是给定所有观测值的前提下,在时间 t 状态是 的概率。
,也就是给定所有观测值的前提下,在时间 t 状态是 的概率。
给定 HMM 模型参数模型参数![]() 固定,我们可以应用前向和后向算法从观测中计算得到 和 。可以通过简单地将 乘以 来计算 ,然后对其进行重新归一化。
固定,我们可以应用前向和后向算法从观测中计算得到 和 。可以通过简单地将 乘以 来计算 ,然后对其进行重新归一化。
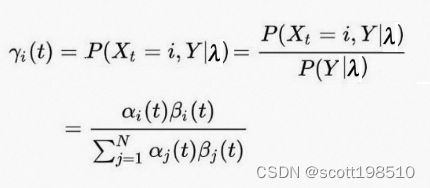
 是在给定所有观测值的情况下,在时间 之后从状态 转移到 的概率称为转移概率。它可以类似地由 和 计算 得到
是在给定所有观测值的情况下,在时间 之后从状态 转移到 的概率称为转移概率。它可以类似地由 和 计算 得到
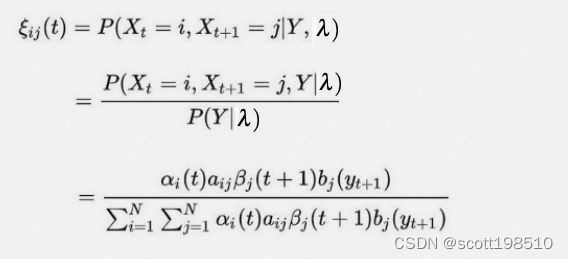
采用EM算法求解得到是似然概率最大化的参数  和
和  。
。
HMM算法实现的完整迭代流程如下

2.5 KF
卡尔曼滤波是一种通过给定观测值的情况下,对未知变量提供预测估计的算法。卡尔曼滤波器已经在导航与定位、位置追踪、金融时序数据预测等应用中表现出良好的实用性。卡尔曼滤波器具有表达形式简单,不需要太大的计算能力和存储空间的特点。
卡尔曼滤波算法分为预测prediction和更新update两个阶段。“预测”和“更新”通常在不同的文献中也称为“传播”和修正。
Prediction:
![]() (Predicted state estimate)
(Predicted state estimate)
![]() (Predicted error covariance)
(Predicted error covariance)
Update:
![]() (Measurement residual)
(Measurement residual)
![]() (Kalman gain)
(Kalman gain)
![]() (Updated state estimate)
(Updated state estimate)
![]() (Updated error covariance)
(Updated error covariance)
2.6 LSTM
长短时记忆模型(Long short-term memory, LSTM)是一种特殊的RNN,主要是为了解决长序列训练过程中的梯度消失和梯度爆炸问题。简单来说,就是相比普通的RNN,LSTM能够在更长的序列中有更好的表现。LSTM结构(图右)和普通RNN的主要输入输出区别如下所示。

下面具体对LSTM的内部结构来进行剖析。
首先使用LSTM的当前输入 ![]() 和上一个状态传递下来的
和上一个状态传递下来的 ![]() 拼接训练得到四个状态。
拼接训练得到四个状态。
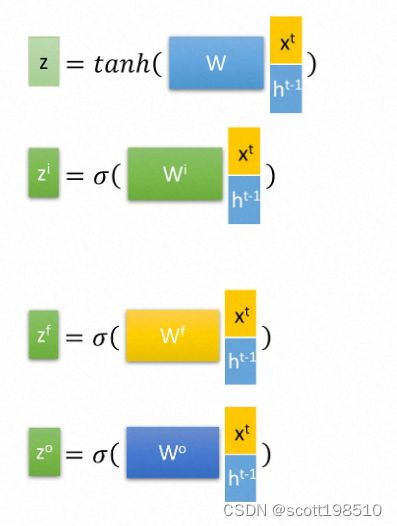
下面开始进一步介绍这四个状态在LSTM内部的使用。
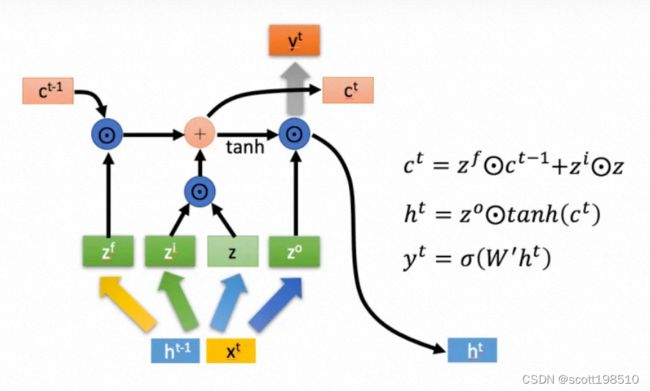
2.7其它
3.应用举例
4.总结
上述列出了常见不同时间序列学习模型的原理与数学形式。具体应用中,对于偏向自相关的时间序列,常见于经济、金融如股市、期货相关的价格走势等问题使用较多的是AR、MA、ARMA、 ARIMA,KF主要应用于物理模型,常见于航空航天等领域的组合导航、定位算法等,HMM主要应用于语音识别、自然语言处理的早期模型,RNN/LSTM作为深度学习大红大紫后大模型的主要组件,使用范围涵盖了图像、视觉、语音、自然语言处理等模式识别的几乎各个方面。