声纹识别X-Vector
背景
声纹识别上x-vector被作为很多赛事的baseline使用,包括aishell2018、ASVspoof2019。介绍x-vector的文章主要有[1] [2]两篇,[1]介绍x-vector的整体和细节部分,[2]对实验进行了补充分析。
Prerequisites: TDNN,embedding。
核心思路
将系统分成两个部分:
- Embedding:将不定长的语音通过加噪和加混响进行数据扩充,然后经由深度神经网络映射成定长的向量,将映射之后的向量称为x-vector。
- Compare pairs of embeddings:采用PLDA。
x-vector系统
输入:24维filterbanks(在[1]中是20维MFCC),帧长25ms,经过 a. 3秒滑动窗口的均值归一化 b. speech activity detection(SAD)去除没有说话人语音的帧 处理。
系统框架:
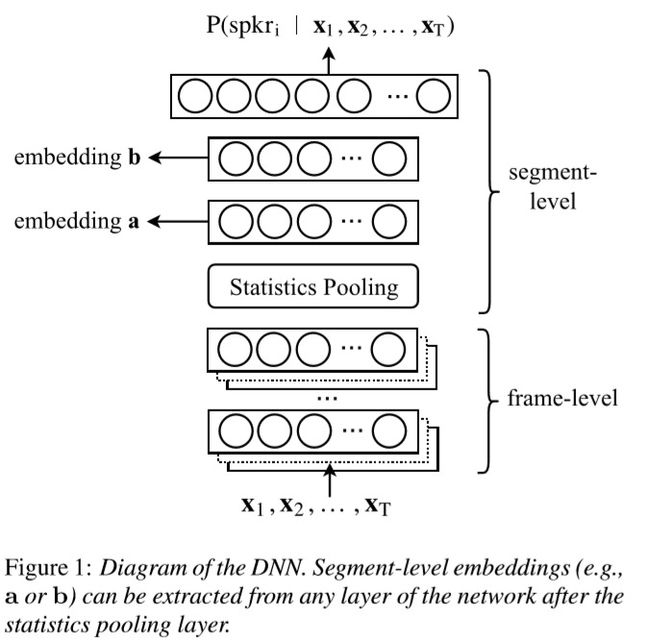
系统参数:

Step 1. Time Delay Neural Networks (TDNN)
系统框架图中的Statistics Pooling之前的部分就是TDNN,下图是TDNN的示意图,来源为 [3]。


根据系统参数有如下图的TDNN:

根据系统参数所示,frame5的output是1500,因此每一次TDNN的输入都是15帧,输出都是1500维的向量。
对语音每15帧提取一次1500维的向量,如果输入的语音有T帧长,那么最终就能得到T个1500维的向量。
p.s. 如果说输入的语音特征总共有T帧,在边缘不补零的情况下,输出是T-2*7帧,而不是刚好T帧。这里说得到T个向量是为了与论文一致,后文也将沿用论文的说法。(p.s.具体实现的时候可以用dilation,可参见代码)
Step 2. Statistics pooling
对这T个向量计算均值和方差(因为每个1500维的向量都是从一个15帧的数据提取的,这样能够集合不同时间上的信息),将均值和方差合并起来,则得到一个2x1500=3000维的向量。
与系统框架所示,pooling之后,使用两层全连接层,最后softmax之后的输出长度是说话人的数量K(p.s.在[2]中说话人数量的符号是N,为了与损失函数公式符号保持一致,这里统一用K表示说话人数量)。
模型的损失函数为下式的多分类交叉熵:

其中,有K个说话人,每人说了N个片段(segment)。当对说话人片段n打上的标签是k时,dnkd_{n k} dnk是1,否则为0。
第n段语音的loss计算可以用以下的表格表示:
| * | 说话人A | 说话人B | 说话人K |
|---|---|---|---|
| Label | 0 | 1 | 0 |
| Pred | 0.3 | 0.6 | 0.1 |
loss=−(0×log(0.3)+1×log(0.6)+0×log(0.1) \text {loss}=-(0 \times \log (0.3)+1 \times \log (0.6)+0 \times \log (0.1) loss=−(0×log(0.3)+1×log(0.6)+0×log(0.1)
Step 3. extract embedding
神经网络并不仅仅是一个分类器,而是一个特征提取器和分类器的结合,每一层都有极强的特征提取能力。因此可以将模型的一部分作为特征提取器,也就是embeddings。
在训练完前述模型之后,截取模型的前一部分。截取哪部分要考量两点:
- 选取能够利用整段语音信息的部分(所以选取pooling之后的部分) 。
- 输出不宜过长(pooling之后的输出结果的长度为3000,所以选择经过全连接层的,输出结果长度为512)。
-
如系统参数所示,文献[1]选取segment6的输出作为embeddings。
-
如系统框架所示,文献[2]选取了两种embedding方法进行对比,并增加了联合两种embedding的方法(
Instead of concatenating embeddingstogether,wecomputeseparatePLDAbackendsfor each embedding, and average the scores),效果如下图:

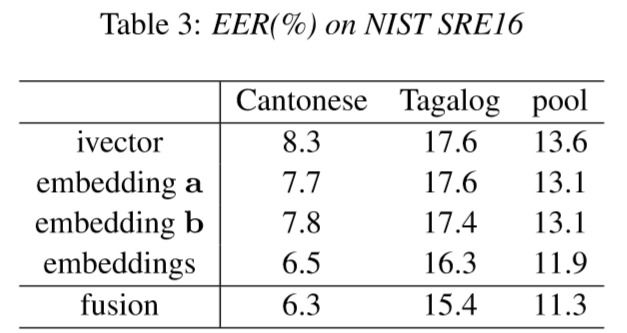
结论:1. 测试语音比较长时,i-vector的优势比较明显;2. 测试语音在5-20s时,dnn效果较好;3. embedding的综合要比只用单个embedding好;4. dnn对out of domain 的效果优于i-vector
Step 4. PLDA backend
PLDA(Probabilistic Linear Discriminant Analysis)是一种信道补偿算法,号称概率形式的LDA算法,PLDA算法的信道补偿能力比LDA更好,已经成为目前最好的信道补偿算法。
利用前述的embeddings训练PLDA模型, 使用PLDA的方法和i-vector是一样的。具体做法如下:
建模
定义第i个说话人的第j条语音为xij,然后定义xij的生成模型为xij=μ+Fhi+Gwij+ϵijx_{i j}=\mu+F h_{i}+G w_{i j}+\epsilon_{i j}xij=μ+Fhi+Gwij+ϵij。
模型分为两部分:
- 信号部分:μ+Fhi\mu+F h_{i}μ+Fhi,只与说话人身份有关,该项描述了**个体之间**的差异。
- 噪声部分:Gwij+ϵijG w_{i j}+\epsilon_{i j}Gwij+ϵij,同一个人每次说话也会有差异,描述了**个体内部**的差异。
μ\muμ是全体训练数据的平均值;
F可以看做是身份空间,包含了可以用来表示各种身份的基底;
hih_ihi就可以看做是一个人的身份(或者是人物在身份空间中的位置);
G可以看做是误差空间,包含了可以用来表示同一身份不同变化的基底;
wijw_{ij}wij表示的是在误差空间中的位置;
ϵij\epsilon_{i j}ϵij 用来表示随机误差,该项为零均高斯分布,方差为 Σ。
由于我们只关心区分说话人,所以并不需要计算误差空间,所以可以把噪声部分的两项合并,则得到Xij=μ+Fhi+ϵijX_{i j}=\mu+F h_{i}+\epsilon_{i j}Xij=μ+Fhi+ϵij,其中ϵ\epsilonϵ~N(0, Σ),hih_ihi~N(0,1)。
训练
训练PLDA模型,就是通过训练数据估计出参数ϕ\phiϕ和Σ。估计这两个参数的方法是经典EM算法迭代求解,即猜(E-step)-反思(M-step),重复。
测试
模型测试阶段的思想是使用对数似然比来计算得分:
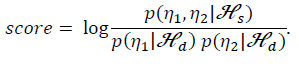
n1和n2分别是两个语音的x-vector(或i-vector)矢量,这两条语音来自同一空间的假设为Hs,来自不同的空间的假设为Hd。
其中p(n1, n2 | hs)为两条语音来自同一空间的似然函数;
p(n1 | hd),p(n2 | hd)分别为n1和n2来子不同空间的似然函数。通过计算对数似然比,就能衡量两条语音的相似程度。
得分越高,两条语音属于同一说话人的可能性越大。
具体的PLDA得分计算也有不同的实现,[4]中介绍了在i-vector上用的Gaussian PLDA(GPLDA)。
论文结论
文献[2]主要是对数据扩充对不同模型的影响进行了对比分析,性能结果如下图:

文献[2]的结论:
-
x-vector取得了比另外两种ivector更优异的效果,尤其是在out-domain(Cantonese)上保持了优势;
-
本文所提出的data augmentation 可以大大减少EER,同时data augmentation在xvector上效果最好;
-
PLDA aug 或者extractor aug 在三种模型上都有所改进,但是二者结合取得的效果最好;
参考资料
- [1] Snyder D, Garcia-Romero D, Povey D, et al. Deep Neural Network Embeddings for Text-Independent Speaker Verification[C]//Interspeech. 2017: 999-1003.
- [2] Snyder D, Garcia-Romero D, Sell G, et al. X-vectors: Robust dnn embeddings for speaker recognition[C]//2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2018: 5329-5333.
- [3] Peddinti V, Povey D, Khudanpur S. A time delay neural network architecture for efficient modeling of long temporal contexts[C]//Sixteenth Annual Conference of the International Speech Communication Association. 2015.
- [4] Garcia-Romero D, Espy-Wilson C Y. Analysis of i-vector length normalization in speaker recognition systems[C]//Twelfth Annual Conference of the International Speech Communication Association. 2011.
- Embedding的优势 https://towardsdatascience.com/deep-learning-4-embedding-layers-f9a02d55ac12
- Embedding的讲解(以NLP为例) https://zhuanlan.zhihu.com/p/34975871
- TDNN相关资料 https://www.jianshu.com/p/0207536ebc6c
- 交叉熵相关 https://blog.csdn.net/tsyccnh/article/details/79163834
- PLDA算法解释 1. https://blog.csdn.net/xmu_jupiter/article/details/47281211 2. https://blog.csdn.net/shuzfan/article/details/51672050 3. https://blog.csdn.net/weixin_38206214/article/details/81115275