Andrew Ng's deeplearning Course2Week1 Practical aspects of Deep Learning(深层学习的实用层面)
1 深度学习的实用层面
1.1 基础
1.1.1 深度学习应用简述

正如上图所说:深度学习的应用是一个高度迭代的过程,对于隐藏层的数量,隐藏单元数,学习率,激活函数这些该怎么选,我们其实心里并没有数,我们只有在一次次的选择和迭代过程中才能不断找到更好的,因此深度学习是一个高度迭代的过程。
1.1.2 训练/开发/测试集的选择
高质量的训练数据集、验证集和测试集可以有效的提高循环的效率,如何选择咱们看下图:
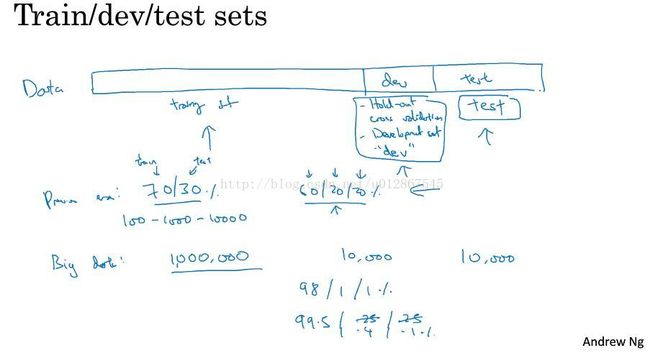
我们可以将数据集分为三个部分:训练集、验证集(起到交叉验证的作用)、测试集。
有的人没有将dev test独立出来,这样也可以,不过可能就是会造成过度拟合。
在数据量小的时候,我们可以按training test和test 7/3分。或者training、dev、test 6/2/2分。
在数据量大的时候,没必要分给dev和test太多的数据,可以按照 98/1/1 或者 99.5/0.4/0.1 来划分。
1.1.3 训练/测试集的不匹配

有种情况 就是训练集都是高像素的,而测试集又比较低像素,这样会造成两者之间的不匹配,这种情况下就需要确保2者数据同一分布,如果你不需要测试集,仅仅只有验证集的话那也行。但是有测试集的话会比较好,因为测试集就是对最终选定的神经网络系统做出无偏估计的。
1.1.4 偏差/方差

第一幅图就是high bias(高偏差),欠拟合;第二幅图就是处于高偏差和高方差之间,比较好;第三幅图就是high variance(高方差),属于过度拟合。

举个例子如上图,当训练集的匹配度在1%,验证集匹配度在11%时,就是高方差,属于和训练集过度拟合了,因此在验证集中的表现并不是特别好。
当训练集的匹配度在15%,验证集匹配度在16%时,属于高偏差,欠拟合,与训练集不是非常匹配。
当训练集的匹配度在15%,验证集匹配度在30%时,既高偏差又高方差,训练的效果非常不好。
当训练集的匹配度在0.5%,验证集匹配度在1%时,属于低偏差又低方差,这就是我们所希望的理想效果。
那么对于上面的情况,我们该如何在机器学习中有规律的去往我们想要的方向上发展呢?看下图:
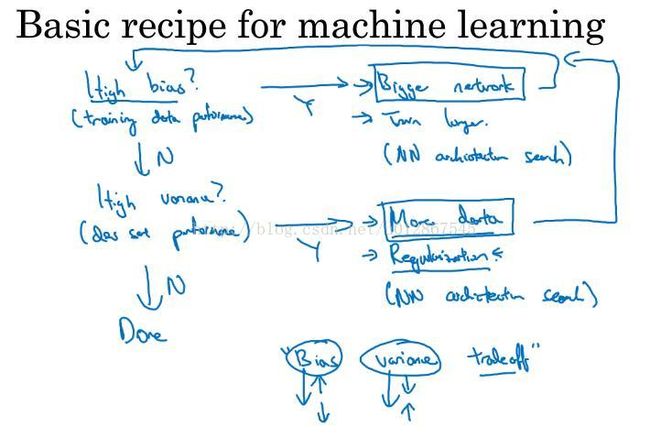
假设我们训练出了高偏差,那么就是训练集的问题,我们可以扩大神经网络的规模,假设并没有高偏差,那么我们就考虑是不是高方差,假如是的话,我们有2种方案,一种是增加数据量,但是有时候这个比较难做到,我们还有另一种方法就是正则化,这个将在1.2中讲到。循环往复,直到得出低偏差和低方差。
1.2 正则化
假设我们出现了过度拟合,即高方差问题,那么我们可以使用正则化的手段来解决。
1.2.1 L2正则化和L1正则化

(1)逻辑回归中实现正则化
在逻辑回归中,如上图第三行,给原先的成本函数加上一个范数即可实现正则化。标红表示常用。
在L2 regulation中: 加上 λ/2m * ||w||2^2 其中的下标2就代表的是L2正则化, 其中 ||w||2^2 = wj^2 从1到nx求和 = w.T*w 其中||w||为欧几里得范数(可自行百度)
在L1 regulation中: 加上 λ/2m * ||w||1 其中||w||1 = wj 从1到nx求和
这里不加上b的正则是因为w是高维度的,加不加b也就无所谓,跟随你的意愿就行。
在L1正则化中,w将会比较稀疏,也就是其中会有较多的0,不过并不能起到压缩空间的作用。
λ为正则化参数,通常使用验证集交叉验证来配置这个参数。(PS: λ 即lambda在Python中为保留字段,因此在写代码时我们经常将其命名为lambd)
(2)神经网络中实现正则化

在神经网络中,与逻辑回归相似,我们给成本函数加上一个范数。不过由于有多层,因此其中λ/2m * ||w||2^2 将改为 λ/2m * 【||w[L]||F^2】L从1到L求和
其中||w[L]||F^2 = i从1到n[L] j从1到n[L-1] 对wij[L]^2 求和。其中F表示这个为Frobenius范数(弗罗贝尼乌斯范数),其实也就是L2范数,但由于某些原因,我们不那么叫它。
然后我们在dw[L]中给其加上 λ/m * w[L] 然后以此更新 w[L],我们有时也将这个称作weight decay(权重衰减),是因为将其代入化简如上图所示,最终w[L]前的系数会变为
(1 - αλ/m),系数变小了,这样就导致权重衰减。
1.2.2 为什么正则化可以减少过拟合

在这个例子中,如果我们将λ设置的足够大,w[L]近似等于0(极端情况,事实上并不会真的这样),直观上的理解就是 很多隐藏单元将消失,最后就剩下一个深度很深的简单网络,这将使得这个神经网络从高方差的状态变为高偏差的状态,但是λ有一个中间值,这将会使得比较接近于just right状态。
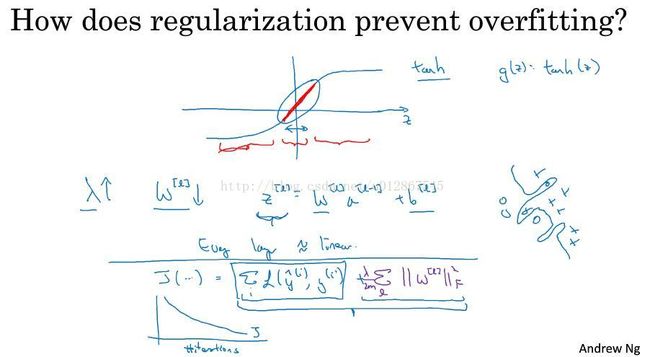
在这个例子中,我们以tanh为激活函数举例。如同上个例子所说,当λ设置的足够大,w[L]就会变得很小,因此导致Z[L]也会变得比较小,这样Z[L]的取值范围会很小,这样就会近似接近于线性状态,而在之前我们提过线性函数是不适合非常复杂的决策及过度拟合数据集的非线性决策边界,因此不会产生过拟合的状态。
1.2.3 Dropout正则化
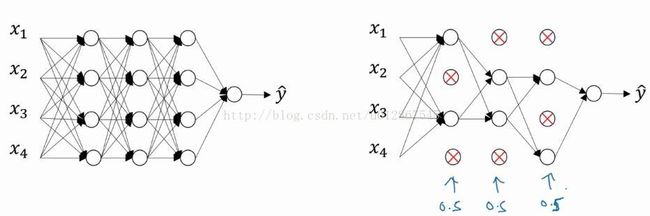
简单的解释drop out正则化就是每一层设定一些概率,然后它会按照概率随机去除一些节点和与之相关的关系,最终得到一个小的、精简的网络,以此来防止过拟合。

那么该如何实现呢?有一个最常用的方法,Inverted dropout(反向随机失活)。
我们以第三隐藏举例,看看drop out 在第三隐藏如何工作。
我们定义一个keep-prob,它表示保留某个隐藏单元的概率。我们再定义一个d3矩阵,维度与第X隐层相同,它保存的就是每个节点是否留存的可能。1代表留存,概率为keep-prob,0代表去除,概率为1 - keep-prob。(PS:其中d3矩阵是一个Boolean矩阵,但是Python会在运算时自动转换为0和1.)
我们将其与a3相乘,就可以得到一个去除节点后的第三隐层。
最后我们将其除以 keep-prob,这是为了弥补我们所失去的那些节点,使得a[3]和z[4]的期望值能够不变,这在后面的测试中会很有效。
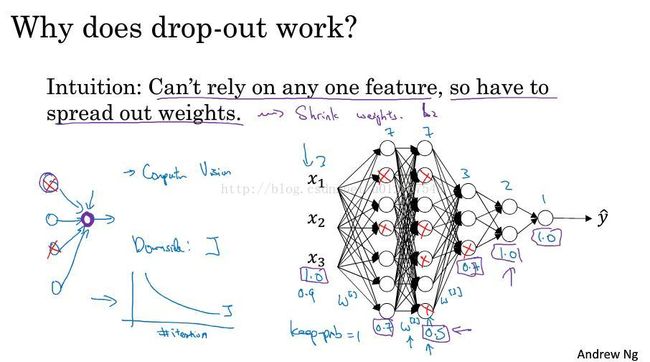
在整个神经网络中,重复的就是上述所讲操作,假如我们担心某一隐层过拟合,那么我们可以将这一隐层的keep-prob设置的更低,如果这一层不完全拟合,我们可以设置为1。
dropout的效果往往比较好,但是其有个缺点:为了使用交叉验证,要搜索更多的超级参数。
1.2.4 其他正则化方法
(1)Data augmentation(数据扩增)
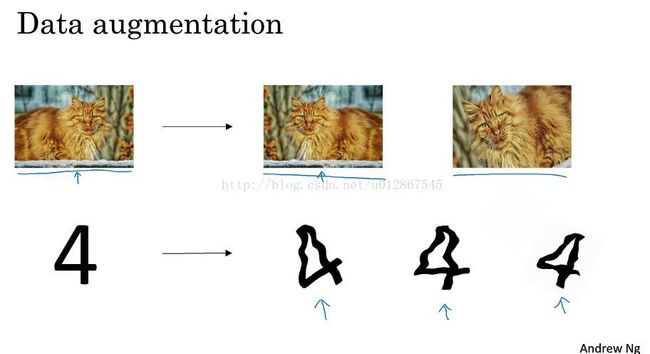
其扩增数据的方法就是将其水平翻转,或者截取某一个部分,弯曲,以此来获得更多的数据集。
(2)early stopping
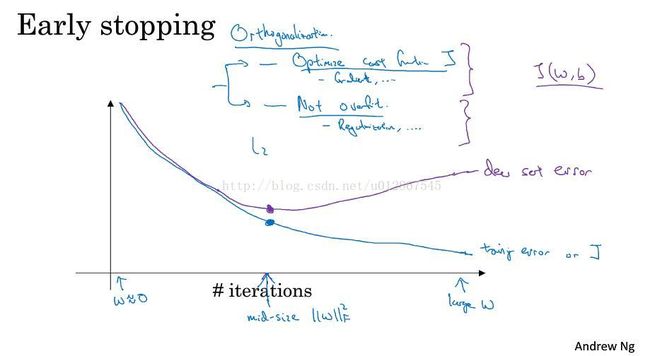
在运行梯度下降时,我们可以绘制成本函数上的训练误差和验证集上的误差,当验证集上的误差降到较小点时,我们可以及时停止,来防止过拟合。这样做的缺点就是,一旦停止,你就不能再继续优化成本函数J了。
1.2.5 归一化输入--加速神经网络
有一种加速神经网络的方法叫归一化输入。

有2个步骤:
1.零均值化 上图左边的公式经过这步操作可以得到中间的效果图
2.归一化方差 上图右边的公式经过这步操作可以得到右边的效果图
PS:在训练集中和测试集中用相同的μ和σ^2
那么为什么归一化输入可以加速神经网络呢?我们看下图:
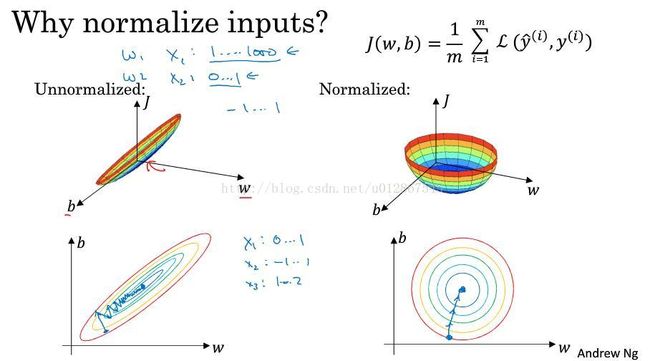
左边是没有归一化的代价函数示意图,右边是归一化后的代价函数示意图。
可以看到左边我们需要很多次迭代才能找到最小的代价,而右边我们无论从何处都可以很快的到达最小代价处。
PS:当输入特征的范围不同时,如有些在0-1,有些在1-1000,那么归一化输入就会非常有用。如果输入特征相同,那么久没有必要归一化输入。
1.3 梯度
1.3.1 梯度消失与梯度爆炸

假设使用的是线性激活函数g(Z) = Z,b[L] = 0,那么可以得到y帽 = w[L] * w[L - 1] * ....* w[2] * w[1] x,假设w[L]大于1,是1.5的话,y帽就会随着L的增长而呈爆炸式的增长,梯度也会随之爆炸式的增长;反之,w[L]小于1的话,梯度就会渐渐消失。
1.3.2 神经网络的权重初始化
为了应对梯度消失与爆炸的问题,我们有个不完全的解决方法:权重初始化。

为了预防z过大或者过小,当n越大的时候我们希望w[i]越小,因此我们可以设定w[i] = np.random.randn(shape)* np.sqrt(1 / n[L - 1]) ,如果是ReLU函数,可能np.sqrt(2 / n[L - 1]) 会更好。(这里听得不是特别明白,以后补充)
tanh激活函数,用根号(1 / n[L - 1])会比较好。Xavier 初始化用根号(2 / n[L - 1] * n[L])会比较好。
1.3.3 梯度检验及其技巧和注意事项
(1)梯度数值逼近

用 [f( θ + ε) - f( θ + ε)] / 2 看它是否约等于gθ来检验梯度,也就是通过看梯度的数值的逼近程度来检验梯度。具体原理就不解释了,学过微积分的应该可以明白。
(2)检验梯度
下面讲述下神经网络中该如何检验梯度:

将W[1],b[1]...W[L],b[L]重构成一个向量θ,同理,把dW[1],db[1]...dW[L],db[L]重构成一个向量dθ

对于每个i,我们通过之前讲的公式 来计算dθ appear[i] 最后我们就得到一个dθ appear的矩阵,我们通过计算 ||dθ appear - dθ||2 / ( ||dθ appear||2 + ||dθ||2) 来检验梯度,如果大约在10^-7 ,那么就没多大问题; 在10^-5 左右,最好得去一项项检查检查;在10^-3左右,那就得去检查检查了。
(3)梯度检验的实用技巧和注意事项

1.梯度检验仅用来调试bug,不用在训练集中
2.如果梯度检验失败了,查看每一项来确认bug所在。
3.记住要正则化。
4.梯度检验不要与dropout正则化一起使用。
5.在随机初始化过程中,运行了一次梯度检验,然后在一些训练后,可能还要再运行一次梯度检验。(可能性很低)