Andrew Ng's deeplearning Course4Week1 Convolutional Neural Networks(卷积神经网络)
一、计算机视觉
深度学习帮助计算机视觉很好的发展,如无人驾驶车识别路上的行人和车辆,人脸识别,艺术风格迁移。
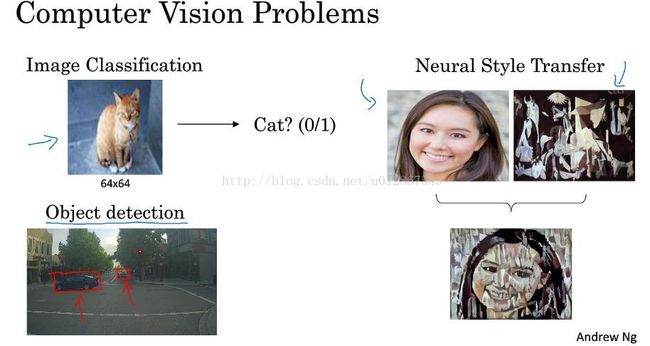

如上图所示,深度学习在大图像上有一个问题,那就是维度。之前64*64*3的维度才12288,但是如果是1000*1000像素的大图片,那么维度就是3million,假设第一层有1000个隐藏单元,那么就是3billion。输入维度太大,在参数如此大量的情况下,难以获取足够的数据来防止过拟合,要处理包含这么多参数的神经网络,巨大的内存需求让人不太能接受,因此你需要进行卷积运算。
二、边缘检测
1.边缘检测示例
计算机视觉是如何工作的呢?之前提到过,他是通过边缘检测实现的,第一步先检测一些垂直,水平边缘;第二步变成一些部位;第三部就变成了人脸。(如下图)

2.垂直边缘检测
做法:
6X6的矩阵和一个3X3的过滤器或者叫核心(如下图所示)做卷积运算,就可得到垂直边缘。卷积运算请google。

为何这样做可以检测到垂直边缘呢?看下图:

假设6X6的矩阵,左边三列全是10,右边3列全是0,那么左边就代表很亮的感觉,右边就是很暗,中间有个垂直的边缘。当做完卷积运算后,所得到的矩阵就把中间的垂直边缘检测出来了。如上图所示。
3.边缘检测其他内容
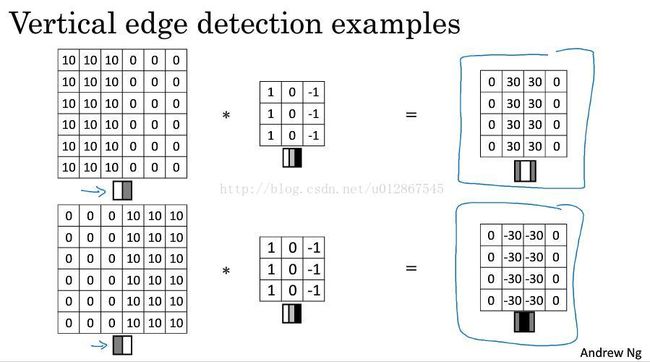
上图中的上测原始图是由亮到暗,所以最后的结果[0,30,30,0]表示检测到的垂直边缘是30,比较亮,代表由亮过渡到暗。
上图中的下测原始图是由暗到亮,所以最后的结果[0,-30,-30,0]表示检测到的垂直边缘是-30,比较暗,代表由暗过渡到亮。

上图表示的垂直和水平过滤器。
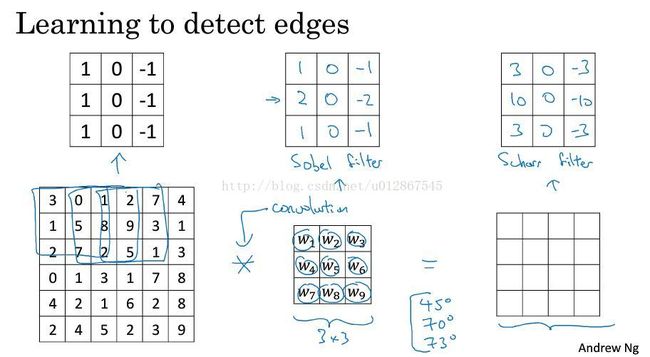
上图的上测表示的sobel和scharr过滤器。上图下侧表示我们可以不用前人的参数,而是可以通过反向传播不断更新得到参数,那样不仅可以检测出垂直、水平,任意角度的边缘都可以检测出来。
三、padding

什么是padding?padding就是在图像周围填充像素,padding=1填充1圈,padding=2填充2圈。
那么为什么需要padding呢?有2个因素,1:假设没有padding,那么每回卷积运算后,图像都会变小,那么在n层以后,图像就会变得非常非常小。2:可以从上图中看到,边缘像素点的计算的频率远低于中间,因此会有很多信息会丢失。

有2种卷积操作,“valid”和“Same”,valid就是无padding,输入维度nXn,过滤器维度fXf,输出维度(n-f+1)X(n-f+1);
Same就是有padding,输出的大小和输入的大小相同,并且same的过滤器f维度通常都是奇数,输入维度nXn,过滤器维度fXf,输出维度(n+2p-f+1)X(n+2p-f+1)。
四、卷积步长

卷积的步长可以改变,如之前的步长为1,当我们改为2后,如上图所示,做卷积运算右移时,移动2步,由红框移动到绿框,由绿框移动到紫框。
假设某一步移动到了输入图像外,如上图黄框所示,我们不做运算。
输出维度的计算公式为:

其中s代表步长stride。

其实在数学上,我们之前的卷积运算不叫卷积,叫互相关,在运算前还需将过滤器进行按x轴,y轴分别翻转的双重镜像操作。但是在机器学习中,我们不做这一步骤,并且约定俗成的把互相关叫卷积运算。
五、卷积中“卷”的体现

当图像不再是灰度,而是红绿蓝三通道时,如何做卷积运算?把过滤器也变成3通道,这样就可以一一对应上了,类似于之前,与输入图像相应位置两两相乘最终相加。
当只专注于红色通道时,过滤器可以如上图红框所设置的那样,如果不特别专注于哪个,也可以如绿框所设置的那样。
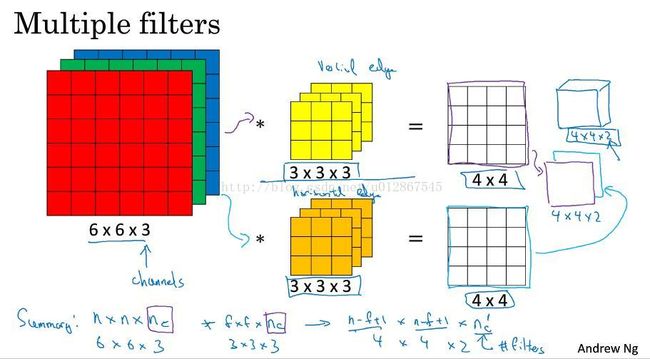
如果我们要同时检测垂直,水平,其他角度的边缘,我们需要多几个过滤器,做卷积运算后,将结果叠加起来,最后输出结果的维度就是(n-f+1)X(n-f+1)X(nc')
其中nc‘就是过滤器的个数。
六、卷积神经网络
1.单层卷积网络

一个单层卷积网络的正向传播过程就如上图所示,其中a[0]就是输入,w[1]就是过滤器,每个过滤器进行卷积运算,并进行W[L]a[L-1]+b[L]操作,然后进行激活函数操作,最终叠加成a[L]。

一个单层中有多少个参数是固定的,和图片的像素大小无关,例如有10个过滤器,每个过滤器的维度为3X3X3,这里有27个参数,再加一个bias就有28个参数,总共有280个参数。

上图时单层卷积网络中所用到的所有参数。
下面举个例子来实际应用下这些参数:

卷积神经网络中最常见的三种层类型,如下图所示:

2.池化层
(1)最大池化层
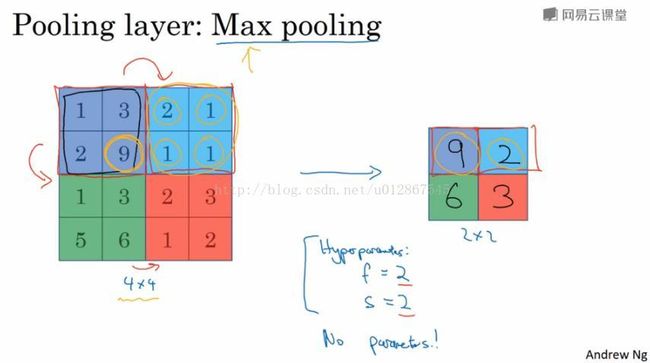
有2个超参,分别为过滤器f,步长s,最大池化就是取每块里最大的那个数。并且没有参数,因为超参是固定不变的。
(2)平均池化层

平均池化层其他都和最大池化层一致,不同的是不是取最大值而是取平均值。
池化层的总结如下图所示:

3.全连接层

像上图红框中直接连起来的就是全连接层,FC2的400个单元和FC3的120个单元紧密相连。
PS:因为池化层没有权重和参数,因此这里把卷积层和池化层合看成一层(也有的文献中是把2个分开看成单独的层),如CONN1和POOL1看成Layer1,,CONN和POOL2看成Layer2。
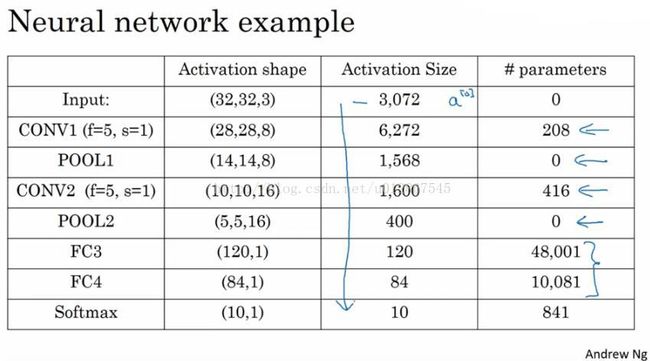
整个过程激活函数的维度,大小,参数等变化如上图所示。
4.卷积神经网络的优点

这个神经网络的第一层有3072个单元,第二层有4704个单元,这2层紧密相连,权重矩阵为3072X4704,参数有14million,非常多;
卷积层的参数数量为6X26=156个,为什么会这么少呢?看下图:

卷积神经网络有2大优点:
1、参数共享:每个特征检测器都可以在输入图片的不同区域使用相同的参数,而且不仅适用于提取垂直或水平等低阶特征,还适用于鼻子、眼睛等高阶特征。
2、稀疏连接:在每一层,每个输出的值仅仅依赖于输入的很小一部分,如绿框0只依赖于输入的绿框,红框30只依赖于输入的红框。