快手如何玩转复杂场景下的说话人识别?| ASRU 2021
快手是一个短视频社区,短视频和直播中通常混合各种形式的声音,如语音、音乐、特效音和背景噪声等,这些声音很好的提升了短视频和直播的用户消费体验,但同时也为音频内容理解带来极大的困难和挑战。如何在复杂场景下准确高效的进行说话人识别,通常需要引入音频降噪/分离技术,本文针对复杂场景下的说话人识别分别提出了一种多任务音频分离技术和基于AutoML神经网络搜索架构的说话人识别技术,两篇论文均被ASRU 2021接收。
来源丨快手技术团队
-
首次提出多任务音频分离方法(MTASS,Multi-Task Audio Source Separation)。多任务音频分离将语音增强、语音分离和音乐分离等多种单一任务融合起来,利用一个模型,同时实现语音、音乐和噪声(特效音)的分离和增强。
-
首次成功将AutoML神经网络搜索架构应用于大规模说话人识别任务,提出SpeechNAS说话人识别技术。在大规模说话人识别数据集VoxCeleb1中,相比原始说话人识别模型,SpeechNAS可以仅使用69%的参数量达到最优的性能。
多任务音频分离

> 论文链接:
https://arxiv.org/pdf/2107.06467.pdf
> 数据集、代码和预训练模型链接:
https://github.com/Windstudent/Complex-MTASSNet
随着短视频和在线直播的快速发展,移动互联网时代对前端音频信号的处理需求和难度也越来越大。这些场景中的音频信号通常包含各种类型的声源,例如语音、音乐、特效音和背景噪声等。真实场景具有复杂多变的声学环境,这些声源可能会在传播过程中变化,并在空间和时间中相互重叠。声源的重叠会对语音音质、音频处理技术造成负面影响。同时,语音、音乐、特效音和噪声对于分析音频具有重要的意义。如何在混合音频中,获得较为纯净的语音、音乐、特效音,成为了一项研究热点和实际中频繁遇到的问题。
对于此类实际需求,目前业界更多的是采用单任务分离/增强方法。例如语音增强、语音分离、音乐声源分离和歌唱伴奏分离等。语音增强旨在去除音频中的噪声,恢复干净的语音信号。语音分离的目的是将音频中的不同说话人语音分离。音乐声源分离和歌唱伴奏分离把音乐信号中各种声源信号进行分离。但是此类单任务分离/增强方法在实际应用中具有一些局限性:
-
此类方法仅考虑了一种情况,在复杂的真实场景中,此类方法一般是不适用的。
-
混合音频中可能含有语音、音乐、特效音,不同的任务需要提取不同的音频信号。可能需要多种增强/分离方法的组合,这种模型的组合造成了资源的浪费。
基于以上分析,我们提出了一个音频分离新任务:多任务音频分离MTASS。多任务音频分离研究如何从混合音频中同时分离语音、音乐和噪声。语音指说话人正常说话的语音数据,音乐包含各种乐器声、背景音乐和歌唱人声,噪声指除去语音和音乐后的剩余音频信号,包含噪声、特效声等。我们深入研究了多任务音频分离,主要贡献如下:
-
第一次提出了多任务音频分离任务。多任务音频分离更贴近于应用场景,第一次连接了语音和音乐的分离。并提出了MTASS-Dataset数据集。
-
我们为多任务音频分离任务提出了一个基于复频域的两阶段模型,名为Complex-MTASSNet。Complex-MTASSNet借鉴了复频域处理方法并参考音乐信号本身的频率稀疏性,在复频域中进行分离。同时,Complex-MTASSNet由分离模块和残留信号补偿模块组成,粗分离后对每个分离轨道的信号进行细化。
-
我们全面系统地分析、比较了Complex-MTASSNet和当前主流的语音分离/增强的相关方法,实验验证了Complex-MTASSNet优势。
MTASS数据集
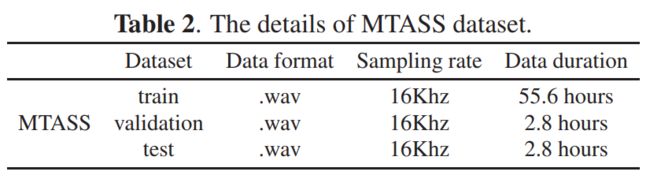
MTASS数据集包含55.6小时训练集、2.8小时开发集和2.8小时测试集。其中语音、音乐和噪音数据均为10秒的片段,采样率为16kHz。MTASS的语音数据由中文语音数据组成,训练集中包含100个说话人,开发集和测试集各包含50个说话人。MTASS的音乐数据由完整歌曲组成,训练集中包含70首歌曲,开发集和测试集各包含15首歌曲。对于每个音频片段,音乐和噪音都以随机-5到5dB信噪比加入到语音中。
方法介绍
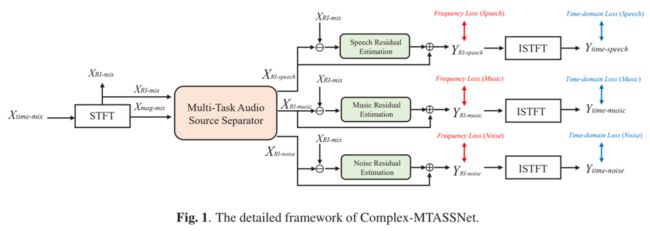
Complex-MTASSNet是基于复频域的两阶段多任务音频分离模型,如图1所示,包含分离模块和残留信号补偿模块。基于傅立叶变换,Complex-MTASSNet在复频域中粗分离出每个音轨的信号,之后对每个音轨泄漏的残留信号进行补偿。
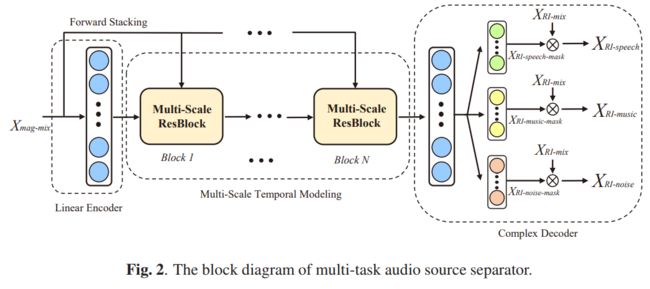
如图 2 所示,Complex-MTASSNet的分离模块采用多尺度TCN结构,并添加了一个基于复频域的解码器来分离不同的音频源。在编码器部分,输入特征首先通过一个全连接的线性层转换为高维的特征表示。然后,堆叠多层多尺度卷积残差模块可以在更细粒度的级别上对音频信号的时间依赖性进行建模,在解码部分,对三个分离轨道分别进行复频域掩蔽的估计。
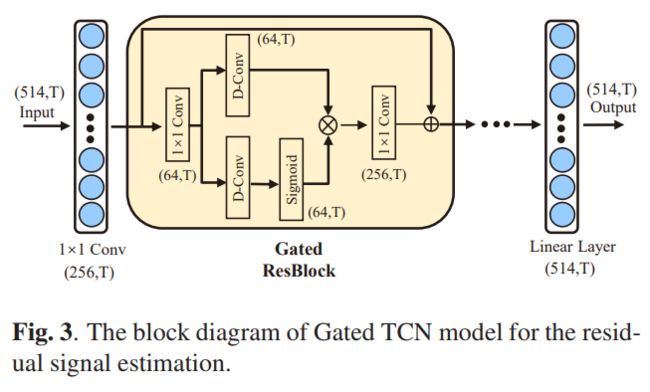
虽然分离模块可以将每个音轨的信号分开,但每个音轨都可能有从其他音轨泄漏的残留信号。因此,我们提出了一种先分离后补偿的两阶段处理结构。设计的残留信号估计模块可以从非目标音轨中估计目标音轨的残留信号,然后对目标音轨进行补偿。对于残留信号估计模型的设计,我们采用了门控TCN结构,如图3所示。在该模型中,门控残差模块被重复多次以实现对目标音频信号的上下文信息进行建模。
实验结果
我们在MTASS-Dataset数据集上验证Complex-MTASSNet的性能。并利用信噪比改善(SDRi)来评价模型的性能。我们评估了 Complex-MTASSNet 的分离性能和计算复杂度,并将其与语音增强、语音分离和音乐分离方面的几个主流模型进行了比较,它们分别是GCRN、Conv-TasNet、Demucs和D3Net。
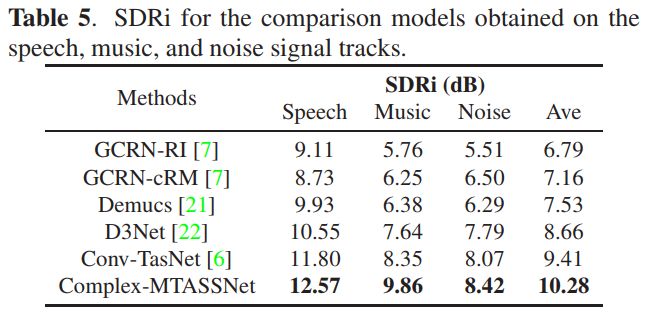
从上表来看,Complex-MTASSNet效果好于基线模型,这是由于提出的两阶段策略有效地帮助 Complex-MTASSNet 提升性能。Complex-MTASSNet 在三个分离音轨上都实现了最佳 SDRi,在语音、音乐和噪声轨上分别为12.57dB、9.86dB 和 8.42dB。
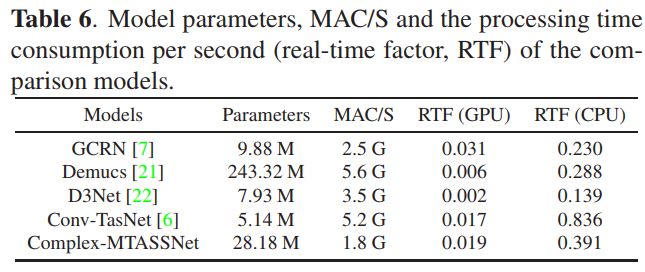
除了分离性能,我们还分析了模型的参数量和计算复杂度,这也是在应用场景中部署模型时需要考虑的关键点。我们主要关注模型大小(参数量)、模型每秒乘加运算量(MAC/S)、模型在CPU(Intel Xeon 5120)和GPU(Nvidia 2080Ti)上处理每秒数据所需的时间(实时率),详细结果列于表6中。Complex-MTASSNet的参数为28.18 M,仅比Demucs小,但模型所需的MAC/S最少。这是因为 Complex-MTASSNet 主要使用一维卷积,避免了使用大量二维共享卷积操作带来的计算负担。从实时率测试来看,所提出的模型在 CPU 和 GPU 平台上都显示出良好的实时性能。Complex-MTASSNet 在复杂性测试中表现相对平衡,同时确保最佳分离性能。
基于AutoML神经网络搜索的大规模说话人识别新方法SpeechNAS

> 论文链接:
https://arxiv.org/abs/2109.08839
> 代码和预训练模型链接:
https://github.com/wentaozhu/speechnas
随着深度学习技术的兴起,工业界和学术界都已经把主要注意力放到了基于深度学习的说话人识别技术。三年前提出的x-vector,即时延神经网络(Time Delay Neural Network, TDNN)已经成为了说话人识别的标准技术。相比于TDNN,Extended TDNN(E-TDNN)间隔构造TDNN和全连接连接层,Factorized TDNN(F-TDNN)通过将每层TDNN的权值矩阵分解为两个低秩矩阵的乘积,进一步减少TDNN的参数量。Densely connected TDNN(D-TDNN)使用bottleneck层和dense连接层,以及通道选择机制,进一步降低基于TDNN的说话人识别的错误率。去年提出的ECAPA-TDNN基于Squeeze-and-Excitation ResNet 网络结构,刷新了大规模说话人识别的最低错误率。
为了有效地从数据中学习得到最优的神经网络结构,进一步降低说话人识别的错误率,以及降低神经网络的参数量和推理延迟,快手研究团队AI Platform 和 MMU (MultiMedia Understanding)联合提出了一种基于音频信号的说话人识别新方法SpeechNAS。
SpeechNAS第一个成功使用神经网络架构搜索处理大规模说话人识别任务,在大规模说话人识别公开数据集VoxCeleb1中,仅使用69%的参数量即可与目前业界最优模型保持性能一致。具体地说,我们首先构造一种全新的搜索空间,包括每层子网络分支个数,特征维度和通道选择的特征维度,试图从数据中自动获得逐层最优的网络结构。然后,我们开发了基于贝叶斯优化的神经网络搜索框架,从已训练的超网络中搜索出最优候选网络。最后,我们设计一种全新的混合损失函数,加性间隔软最大损失(additive margin softmax loss)和最小超球面能量(minimum hyper-spherical energy),重新训练搜索出的最优候选网络。SpeechNAS的主要贡献包括如下三点:
-
第一次成功将神经网络架构搜索应用在大规模说话人识别系统上。
-
第一次全面系统地比较了当前说话人识别的相关方法。主要的度量指标包括,参数量,GFLOPs,延迟,等错误率(Equal Error Rate, EER),以及目标概率0.01和0.001的最小检测损失函数值(Detection Cost Function, DCF)。
-
SpeechNAS根据不同的搜索空间和策略,共得到五个参数量和FLOPs不同的神经网络结构,命名为SpeechNAS-1,…,SpeechNAS-5。在大规模说话人识别任务中,SpeechNAS-5取得了比之前其他基于TDNN方法更低的错误率。相比于最新的方法ECAPA-TDNN,SpeechNAS-5可以在性能一致时参数量降低31%。
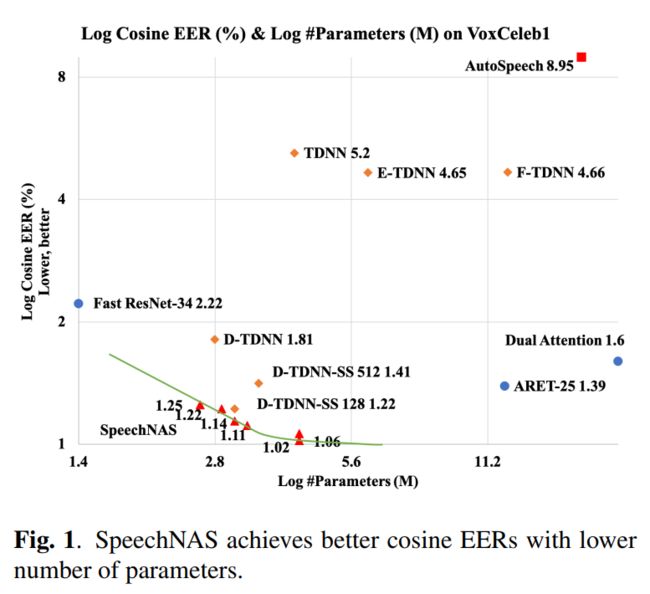
在大规模说话人识别测试集VoxCeleb1上,SpeechNAS使用较少的参数量,同时取得了较低的错误率。参数量和错误率对比详见下图。
方法介绍
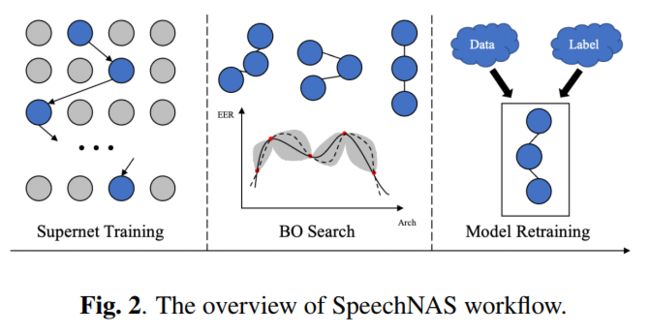
SpeechNAS的流程框架见下图。我们构造神经网络架构搜索空间,基于神经网络架构搜索空间,获得超网络。对于超网络训练中的每个batch,随机均匀采样获得一个子网络。每个batch仅更新学习该随机均匀采样获得的子网络。超网络训练完后,我们开发贝叶斯优化搜索,获得最优子网络结构候选。最后,我们使用设计的新的混合损失函数,重新训练最优子网络结构。
SpeechNAS的每层搜索空间构造如下。SpeechNAS主要基于D-TDNN结构。首先,我们进行分支数b搜索。不同的分支可以处理不同长度的语音上下文信息,直接决定特征抽取的粒度。然后,我们进行特征维度c搜索。特征的维度决定模型的复杂度,以及特征的表达能力。该特征维度搜索的目的在于从数据中自动设计逐层最优的网络模型复杂度。最后,我们进行通道选择维度d搜索。通道选择可以加强特征学习。太复杂的通道选择可能过拟合数据;太简单的通道选择可能无法提供足够的高判别性特征注意力。SpeechNAS可以很好地进行逐层最优结构设计。
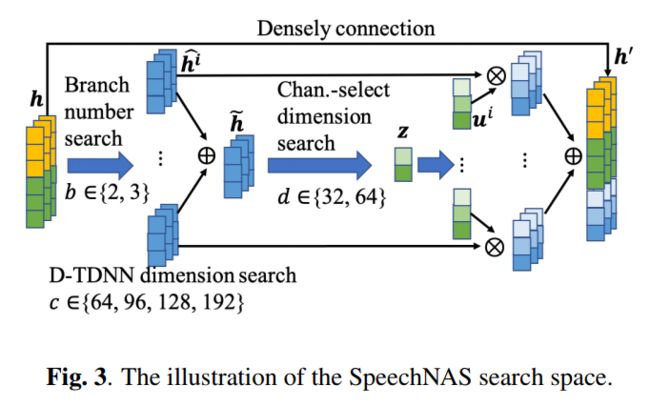
我们可以使用下图公式来描述SpeechNAS的逐层计算过程。b 即为分支个数,TDNN的维度为特征维度搜索结果,f为全连接层,其维度为通道选择维度搜索结果。h为上一层的网络特征,mu,sigma,s,k为计算通道选择特征z所需要的一阶,二阶,三阶,四阶统计量。
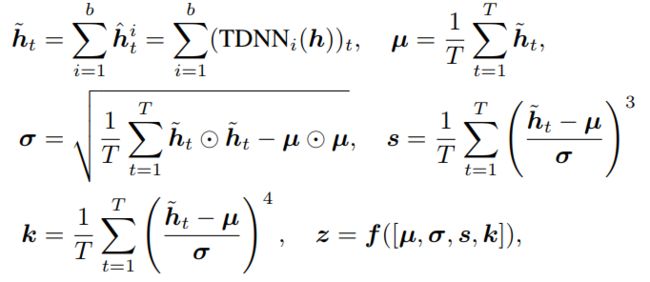
最后,我们拼接经过通道选择后的特征,得到本层的特征,传递到下一层。
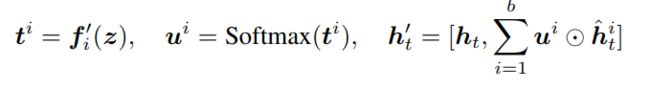
实验结果
我们在大规模说话人识别数据集上验证了SpeechNAS的性能。我们使用了两个数据集,一个是标准的大规模说话人识别数据集VoxCeleb2和VoxCeleb1训练集,另一个是六倍扩增的数据集验证SpeechNAS的泛化性能。测试集均为VoxCeleb1测试集。标准数据集包含超过百万的语音片段,超过2,000小时语音数据,总共超过7,323个说话人。
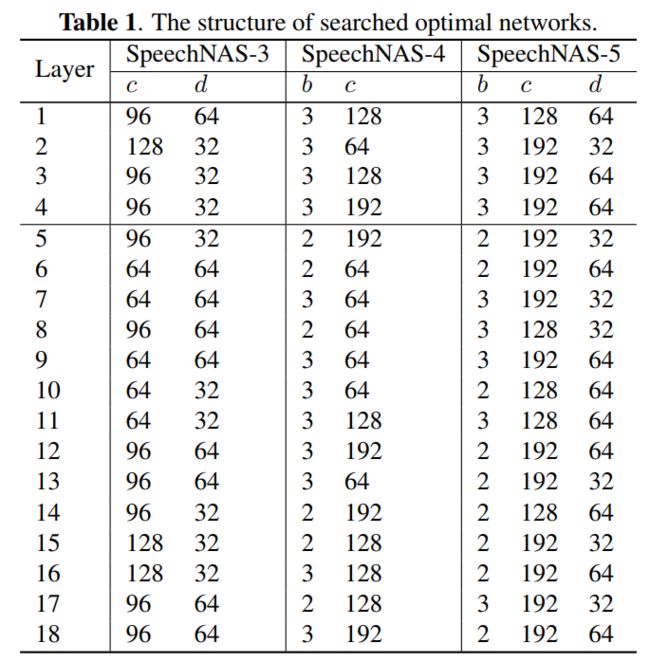
下表是在VoxCeleb1数据集上,和前人最好的方法比较结果。粗体表示最好的结果。*表示使用扩增训练集训练的结果。延迟是在单张NVIDIA GEFORCE RTX 2080 Ti显卡平均1000次推理时间,批大小为128得到的。因为GPU内存大小限制,TDNN推理的批大小为24。
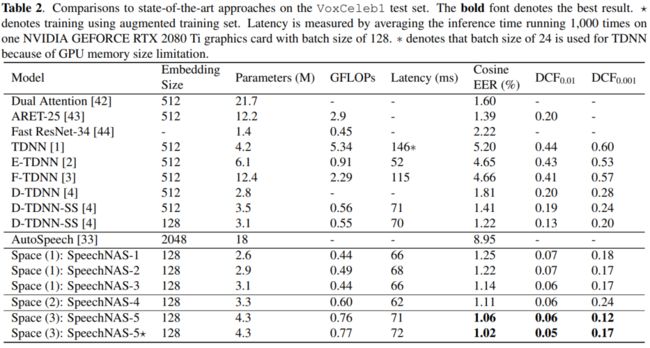
我们在表中第一次系统地比较了当前最好的说话人识别相关方法。从下表可以看出,SpeechNAS获得了比前人更低的错误率,同时延迟也比较低。SpeechNAS可以很友好地部署在高并发用户量大的超级应用中。重新在六倍扩增数据集上训练SpeechNAS-5,可以获得更低的错误率,从而验证了SpeechNAS的泛化性能。相比于当前最好的方法ECAPA-TDNN(基于SE ResNet,参数量为6.2M,相同实验配置下等错误率为1.01%),SpeechNAS使用TDNN结构搜索,仅使用4.3M的参数量,即可获得1.02%相当的等错误率。参数量降低31%。
总结
在本次ASRU2021中,快手分别提出了多任务音频分离MTASS和基于AutoML神经网络搜索的说话人识别模型SpeechNAS。
-
业内首次提出多任务音频分离技术:一个模型实现语音、音乐和噪声的分离和增强,该模型可以同时满足不同下游任务的需求,节约线上资源。目前,多任务音频分离作为基础技术,助力语音识别字错误率相对降低10%以上;音乐检索技术在准确率不变时召回率提升15%;说话人识别准召提升10%/15%。多任务音频分离技术显著提升下游音频技术性能,并直接支持推荐、音乐、智能创作等多种业务。
-
业内首次成功将AutoML神经网络搜索应用到说话人识别任务,提出的SpeechNAS目前得到广泛应用,包括快手社区安全、同城、直播、推荐、素材挖掘等多个业务场景,为各个业务带来显著收益。
了解更多详细内容,请关注语音之家官网:语音之家 Speech Home-助力AI语音开发者的社区