深度学习(二)—— TensorFlow入门
TensorFlow学习笔记
- 1 TensorFlow 简介
- 2 张量及其操作
-
- 2.1 张量的定义
- 2.2 创建张量
- 2.3 转换成 numpy
- 2.4 常用函数
- 3 tf.keras介绍
-
- 3.1 常用模块
- 3.2 常用方法
- 3.3 模型入门案例
-
- 3.3.1 数据集处理
- 3.3.2 sklearn 实现
- 3.3.3 Keras 实现
1 TensorFlow 简介
深度学习框架 TensorFlow 一经发布,就受到了广泛的关注,并在计算机视觉、音频处理、推荐系统和自然语言处理等场景下都被大面积推广使用。
TensorFlow的 依赖视图 如下所示:
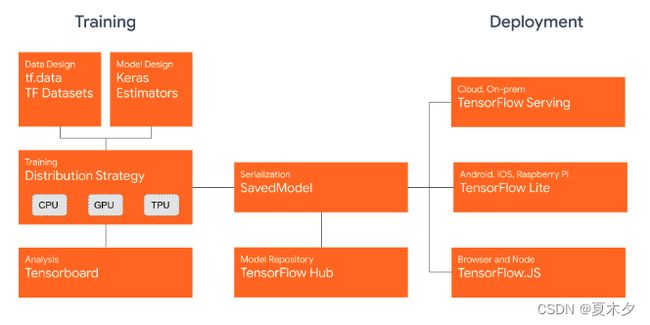

- TF托管在github平台,有google groups和contributors共同维护。
- TF提供了丰富的深度学习相关的API,支持Python和C/C++接口。
- TF提供了可视化分析工具Tensorboard,方便分析和调整模型。
- TF支持Linux平台,Windows平台,Mac平台,甚至手机移动设备等各种平台。
工作流程 如下所示:
-
加载数据。 使用tf.data实例化读取训练数据和测试数据
-
模型的建立与调试。使用动态图模式 Eager Execution 和著名的神经网络高层 API 框架 Keras,结合可视化工具 TensorBoard,简易、快速地建立和调试模型;
-
模型的训练。支持 CPU / 单 GPU / 单机多卡 GPU / 多机集群 / TPU 训练模型,充分利用海量数据和计算资源进行高效训练;
-
预训练模型调用。通过 TensorFlow Hub,可以方便地调用预训练完毕的已有成熟模型。
-
模型的部署。通过 TensorFlow Serving、TensorFlow Lite、TensorFlow.js 等组件,可以将TensorFlow 模型部署到服务器、移动端、嵌入式端等多种使用场景;
2 张量及其操作
2.1 张量的定义
张量是一个多维数组。 与 NumPy ndarray 对象类似,tf.Tensor 对象也具有数据类型和形状。如下图所示:

2.2 创建张量
(1)常量
import tensorflow as tf
# 创建int32类型的0维张量,即标量
tensor1 = tf.constant(1)
print(tensor1)
# tf.Tensor(1, shape=(), dtype=int32)
# 创建float32类型的1维张量
tensor2 = tf.constant([2.0, 3.0, 4.0])
print(tensor2)
# tf.Tensor([2. 3. 4.], shape=(3,), dtype=float32)
# 创建float16类型的二维张量
tensor3 = tf.constant([[1, 2],
[3, 4],
[5, 6]], dtype=tf.float16)
print(tensor3)
# tf.Tensor(
# [[1. 2.]
# [3. 4.]
# [5. 6.]], shape=(3, 2), dtype=float16)
整型默认是 int32,浮点型默认是 float32
(2)变量
变量是一种特殊的张量,形状是不可变,但可以更改其中的参数。
定义时的方法是:
my_variable = tf.Variable([[1.0, 2.0], [3.0, 4.0]])
我们也可以获取它的形状,类型及转换为ndarray:
print("Shape: ",my_variable.shape)
print("DType: ",my_variable.dtype)
print("As NumPy: ", my_variable.numpy)
改变其数值(需注意形状必须保持一致):
my_variable.assign([[3,4],[5,6]])
2.3 转换成 numpy
我们可将张量转换为 numpy 中的 ndarray 的形式,转换方法有两种,以张量 tensor2 为例:
np.array
np.array(tensor2)
# array([2., 3., 4.], dtype=float32)
Tensor.numpy()
tensor2.numpy()
# array([2., 3., 4.], dtype=float32)
2.4 常用函数
我们可以对张量做一些基本的数学运算,包括加法、元素乘法和矩阵乘法等
# 定义张量a和b
a = tf.constant([[1, 2],
[3, 4]])
b = tf.constant([[1, 1],
[1, 1]])
tf.add(a,b)计算张量的和tf.multiply(a,b)计算张量的元素乘法tf.matmul(a,b)计算矩阵乘法
c = tf.constant([[4.0, 5.0], [10.0, 1.0]])
tf.reduce_sum(c)求和tf.reduce_mean(c)平均值tf.reduce_max(c)最大值tf.reduce_min(c)最小值tf.argmax(c)最大值的索引tf.argmin(c)最小值的索引
3 tf.keras介绍
tf.keras 是TensorFlow 2.0的高阶API接口,为 TensorFlow 的代码提供了新的风格和设计模式,大大提升了TF代码的简洁性和复用性,官方也推荐使用 tf.keras 来进行模型设计和开发。
3.1 常用模块
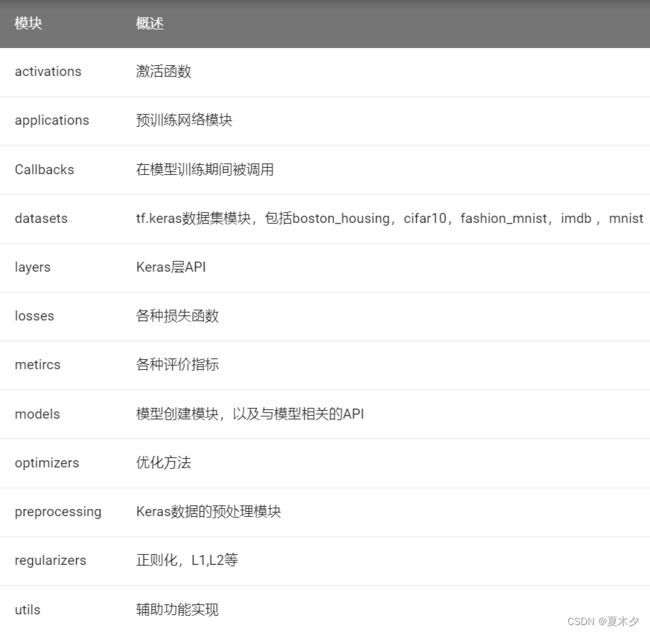
3.2 常用方法
深度学习实现的主要流程:
- 数据获取
- 数据处理
- 模型创建与训练
- 模型测试与评估
- 模型预测
(1)导入tf.keras
使用 tf.keras,首先需要在代码开始时导入tf.keras
import tensorflow as tf
from tensorflow import keras
(2)数据输入
对于小的数据集,可以直接使用 numpy 格式的数据进行训练、评估模型,对于大型数据集或者要进行跨设备训练时使用 tf.data.datasets 来进行数据输入。
(3)模型构建
- 简单模型使用
Sequential进行构建 - 复杂模型使用函数式编程来构建
- 自定义layers
(4)训练与评估
- 配置训练过程
# 配置优化方法,损失函数和评价指标
model.compile(optimizer=tf.train.AdamOptimizer(0.001),
loss='categorical_crossentropy',
metrics=['accuracy'])
- 模型训练
# 指明训练数据集,训练epoch,批次大小和验证集数据
model.fit/fit_generator(dataset, epochs=10,
batch_size=3,
validation_data=val_dataset,
)
- 模型评估
# 指明评估数据集和批次大小
model.evaluate(x, y, batch_size=32)
- 模型预测
# 对新的样本进行预测
model.predict(x, batch_size=32)
(5)回调函数(callbacks)
回调函数用在模型训练过程中,来控制模型训练行为,可以自定义回调函数,也可使用tf.keras.callbacks 内置的 callback :
ModelCheckpoint:定期保存 checkpoints。LearningRateScheduler:动态改变学习速率。EarlyStopping:当验证集上的性能不再提高时,终止训练。TensorBoard:使用 TensorBoard 监测模型的状态。
(6)模型的保存和恢复
- 只保存参数
# 只保存模型的权重
model.save_weights('./my_model')
# 加载模型的权重
model.load_weights('my_model')
- 保存整个模型
# 保存模型架构与权重在h5文件中
model.save('my_model.h5')
# 加载模型:包括架构和对应的权重
model = keras.models.load_model('my_model.h5')
3.3 模型入门案例
3.3.1 数据集处理
# 绘图,获取数据集
import seaborn as sns
# 数值计算
import numpy as np
# 划分训练集和测试集
from sklearn.model_selection import train_test_split
# 逻辑回归
from sklearn.linear_model import LogisticRegressionCV
# tf.keras中使用的相关工具
# 用于模型搭建
from tensorflow.keras.models import Sequential
# 构建模型的层和激活方法
from tensorflow.keras.layers import Dense, Activation
# 数据处理的辅助工具
from tensorflow.keras import utils
(1)获取数据集
iris = sns.load_dataset("iris")
# print(type(iris)) pandas.core.frame.DataFrame
iris.head()
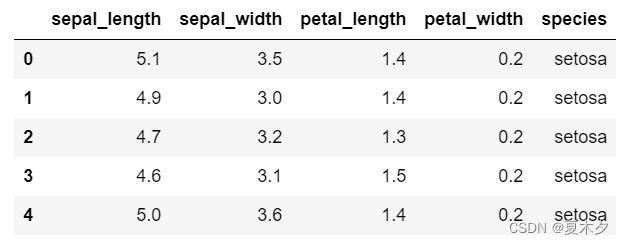
注:
- 我们常用 sklearn.datasets 的 load_*() 获取数据集,返回 Bunch 对象
- seaborn 库内置了十几个数据集,也可以获取数据集,返回数据集的类型为 DataFrame
以下为拓展,本例中仍使用 seaborn 获取的数据集
from sklearn.datasets import load_iris
import pandas as pd
iris = load_iris()
type(iris) # sklearn.utils._bunch.Bunch
# print(dir(iris)) # 查看data所具有的属性或方法
# print(iris.DESCR) # 查看数据集的简介
iris = pd.DataFrame(data=iris.data,columns=iris.feature_names)
iris.head()
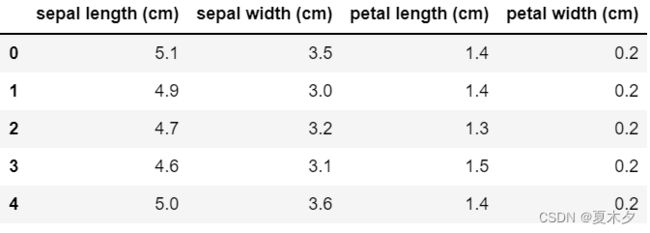
可以注意到使用 sklearn 中的鸢尾花数据集没有标签值
(2)数据展示
# sns.pairplot()用来展示两两特征之间的关系
# hue 针对某一字段进行分类 ,不同类别的点会以不同的颜色显现出来
sns.pairplot(iris,hue="species")

(3)数据集划分
# 确定特征值和目标值
# X = iris.iloc[:, :4]
# y = iris.iloc[:, 4]
# type(X),type(y) # (pandas.core.frame.DataFrame, pandas.core.series.Series)
X = iris.values[:, :4]
y = iris.values[:, 4]
# type(X),type(y) # (numpy.ndarray, numpy.ndarray)
# 数据集的划分
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.5,random_state=0) # 返回numpy.ndarray类型数据
3.3.2 sklearn 实现
# 实例化分类器
estimator = LogisticRegressionCV()
# 训练
estimator.fit(X_train, y_train)
# 计算准确率并进行打印
print("Accuracy = {0:.2f}".format(lr.score(X_test, y_test))) # 冒号左侧的0表示对应参数的索引,此处只有一个参数0可省略
# 0.93
注意:
LogisticRegression和LogisticRegressionCV的主要区别是LogisticRegressionCV使用了交叉验证来选择正则化系数C。而LogisticRegression需要自己每次指定一个正则化系数。除了交叉验证,以及选择正则化系数C以外, LogisticRegression和LogisticRegressionCV的使用方法基本相同。
3.3.3 Keras 实现
在sklearn中我们只要实例化分类器并利用fit方法进行训练,最后衡量它的性能就可以了,那在tf.keras中与在sklearn非常相似,不同的是:
- 构建分类器时需要进行模型搭建
- 数据采集时,sklearn可以接收字符串型的标签,如:“setosa”,但是在 tf.keras 中需要对标签值进行热编码,如下所示:

(1)对标签值热编码
def onehot_encode_object_array(arr):
# 去重获取全部的类别
# return_inverse为True时:会构建一个递增的唯一值的新列表,并返回旧列表arr中的值在新列表uniques中的索引列表ids
uniques, ids = np.unique(arr, return_inverse=True)
# 返回热编码的结果
return utils.to_categorical(ids, len(uniques))
# 训练集热编码
y_train_onehot = onehot_encode_object_array(y_train)
# 测试集热编码
y_test_onehot = onehot_encode_object_array(y_test)
注意:
np.unique将数组中的元素进行去重操作,详见:https://blog.csdn.net/Hhjnv/article/details/122916912to_categorical()用于分类,将标签转为one-hot编码,详见:https://blog.csdn.net/nima1994/article/details/82468965
(2)模型搭建
在 sklearn中,模型都是现成的。
而 tf.Keras 是一个神经网络库,我们需要根据数据和标签值构建神经网络,神经网络可以发现特征与标签之间的复杂关系。
神经网络是一个高度结构化的图,其中包含一个或多个隐藏层,每个隐藏层都包含一个或多个神经元。
神经网络有多种类别,该程序使用的是密集型神经网络,也称为全连接神经网络:一个层中的神经元将从上一层中的每个神经元获取输入连接。例如,下图显示了一个密集型神经网络,其中包含 1 个输入层、2 个隐藏层以及 1 个输出层
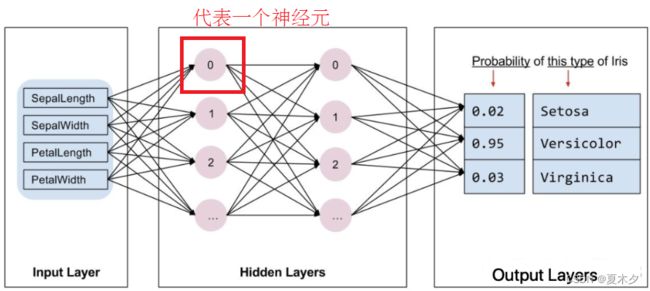
上图 中的模型经过训练并馈送未标记的样本时,它会产生 3 个预测结果:相应鸢尾花属于指定品种的可能性。对于该示例,输出预测结果的总和是 1.0。该预测结果分解如下:山鸢尾为 0.02,变色鸢尾为 0.95,维吉尼亚鸢尾为 0.03。这意味着该模型预测某个无标签鸢尾花样本是变色鸢尾的概率为 95%。
与上一层完全连接的隐藏层称为 密集层。在图中,两个隐藏层都是密集的。
TensorFlow tf.keras API 是创建模型和层的首选方式。通过该 API,您可以轻松地构建模型并进行实验,而将所有部分连接在一起的复杂工作则由 Keras 处理。
tf.keras.Sequential 模型是层的线性堆叠。该模型的构造函数会采用一系列层实例;在本示例中,采用的是 2 个密集层(分别包含 10 个节点)以及 1 个输出层(包含 3 个代表标签预测的节点)。第一个层的 input_shape 参数对应该数据集中的 特征数量:
# 利用sequential方式构建模型
model = Sequential([
# 隐藏层1,激活函数是relu,输入大小有input_shape指定
Dense(10, activation="relu", input_shape=(4,)),
# 隐藏层2,激活函数是relu
Dense(10, activation="relu"),
# 输出层
Dense(3,activation="softmax")
])
# 查看模型结构
model.summary()

激活函数可决定层中每个节点的输出形状。这些非线性关系很重要,如果没有它们,模型将等同于单个层。激活函数有很多,但隐藏层通常使用 relu 。
隐藏层和神经元的理想数量取决于问题和数据集。与机器学习的多个方面一样,选择最佳的神经网络形状需要一定的知识水平和实验基础。一般来说,增加隐藏层和神经元的数量通常会产生更强大的模型,而这需要更多数据才能有效地进行训练。
对于每一个神经元都有
bias参数和weight参数 ,因为有 4 个输入特征值,所以每个神经元有 4 个weight,10 个神经元就有 40 个weight,每个神经元又有1个bias,10 个神经元就有10 个bias,所以隐藏层1有 50 个参数。隐藏层 2 和输出层参数以此类推。
(3)模型训练和预测
在训练和评估阶段,我们都需要计算模型的损失。这样可以衡量模型的预测结果与预期标签有多大偏差,也就是说,模型的效果有多差。
我们希望尽可能减小或优化这个值,所以我们设置优化策略和损失函数,以及模型精度的计算方法:
# 设置模型的相关参数:优化器,损失函数和评价指标
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=["accuracy"])
可知,数组元素的数据类型为:dtype(‘O’),即(Python) objects
X_train.dtype # dtype('O')
X_test.dtype # dtype('O')
我们需要将训练集和测试集的特征值进行数据类型转换:
X_train = np.array(X_train,dtype = np.float32)
X_test = np.array(X_test,dtype = np.float32)
接下来与在sklearn中相同,分别调用fit和predict方法进行预测即可:
# 模型训练
# epochs,训练样本送入到网络中的次数,
# batch_size:每次训练的送入到网络中的样本个数,
# verbose=1:显示训练过程的内容
model.fit(X_train,y_train_onehot,epochs=10,batch_size=1,verbose=1)
训练过程如下:
Epoch 1/10
38/38 [==============================] - 0s 822us/step - loss: 1.0963 - accuracy: 0.5467
Epoch 2/10
38/38 [==============================] - 0s 829us/step - loss: 0.9500 - accuracy: 0.5333
Epoch 3/10
38/38 [==============================] - 0s 809us/step - loss: 0.8646 - accuracy: 0.5867
Epoch 4/10
38/38 [==============================] - 0s 807us/step - loss: 0.7925 - accuracy: 0.7333
Epoch 5/10
38/38 [==============================] - 0s 844us/step - loss: 0.7279 - accuracy: 0.7333
Epoch 6/10
38/38 [==============================] - 0s 788us/step - loss: 0.6779 - accuracy: 0.7333
Epoch 7/10
38/38 [==============================] - 0s 801us/step - loss: 0.6288 - accuracy: 0.7333
Epoch 8/10
38/38 [==============================] - 0s 870us/step - loss: 0.5915 - accuracy: 0.7333
Epoch 9/10
38/38 [==============================] - 0s 798us/step - loss: 0.5546 - accuracy: 0.7333
Epoch 10/10
38/38 [==============================] - 0s 778us/step - loss: 0.5184 - accuracy: 0.7733
前面设置了训练集测试集各占50%,batch_size=1,所以每次训练送入到网络中的一条数据,当(鸢尾花总数据集共150条)75条训练集数据训练完成,为一个 epoch。epochs=10,需要训练10次。
上述代码完成的是:
- 迭代每个epoch。通过一次数据集即为一个epoch。
- 在一个epoch中,遍历训练 Dataset 中的每个样本,并获取样本的特征 (x) 和标签 (y)。
- 根据样本的特征进行预测,并比较预测结果和标签。衡量预测结果的不准确性,并使用所得的值计算模型的损失和梯度。
- 使用 optimizer 更新模型的变量。
- 对每个epoch重复执行以上步骤,直到模型训练完成。
(4)模型评估
与sklearn中不同,对训练好的模型进行评估时,与 sklearn.score 方法对应的是tf.keras.evaluate()方法,返回的是损失函数和在 compile 模型时要求的指标:
# 计算模型的损失和准确率
loss, accuracy = model.evaluate(X_test, y_test_onehot, verbose=1)
print("Accuracy = {:.2f}".format(accuracy))