1.tensorflow和keras入门
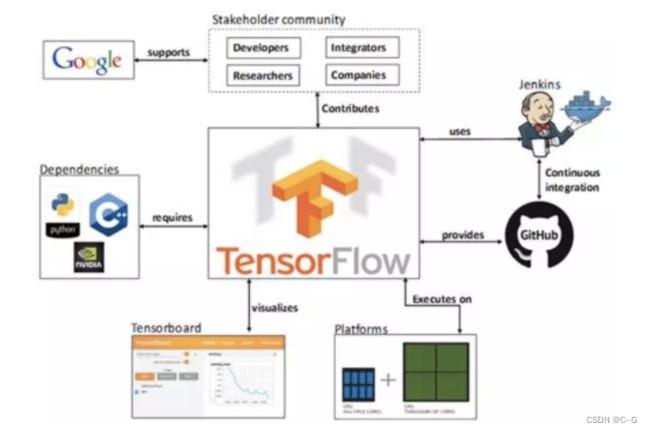
TensorFlow简介
-
TF托管在github平台,有google groups和contributors共同维护。
-
TF提供了丰富的深度学习相关的API,支持Python和C/C++接口。
-
TF提供了可视化分析工具Tensorboard,方便分析和调整模型。
-
TF支持Linux平台,Windows平台,Mac平台,甚至手机移动设备等各种平台。
工作流程
TensorFlow 2.0 将专注于简单性和易用性,工作流程如下所示:
- 使用tf.data加载数据。 使用tf.data实例化读取训练数据和测试数据
- 模型的建立与调试: 使用动态图模式 Eager Execution 和著名的神经网络高层 API 框架 Keras,结合可视化工具
TensorBoard,简易、快速地建立和调试模型; - 模型的训练: 支持 CPU / 单 GPU / 单机多卡 GPU / 多机集群 / TPU训练模型,充分利用海量数据和计算资源进行高效训练;
- 预训练模型调用: 通过 TensorFlow Hub,可以方便地调用预训练完毕的已有成熟模型。
- 模型的部署: 通过 TensorFlow Serving、TensorFlow Lite、TensorFlow.js等组件,可以将TensorFlow 模型部署到服务器、移动端、嵌入式端等多种使用场景;
安装

- 非GPU版本安装
pip install tensorflow==2.3.0 -i https://pypi.tuna.tsinghua.edu.cn/simple
- GPU版本安装
pip install tensorflow-gpu==2.3.0 -i https://pypi.tuna.tsinghua.edu.cn/simple
张量Tensor
张量是一个多维数组。 与NumPy ndarray对象类似,tf.Tensor对象也具有数据类型和形状,此外,tf.Tensors可以保留在GPU中。
使用
** TensorFlow提供了丰富的操作库(tf.add,tf.matmul,tf.linalg.inv等),它们使用和生成tf.Tensor。在进行张量操作之前先导入相应的工具包:**
import tensorflow as tf
import numpy as np
# 0维张量,标量
tf.constant(1)
![]()
# 一维张量
tf.constant([1.0,2.0,3.0])
![]()
# 二维张量
tf.constant([
[1,2,3,4],
[5,6,7,8]
],dtype=tf.int16)
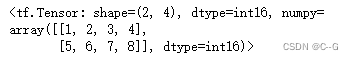
# 三维张量
tf.constant([
[
[1,2,3,4,5],
[6,7,8,9,10]
],
[
[2,3,4,5,6],
[7,8,9,10,11]
],
[
[3,4,5,6,7],
[9,10,11,12,13]
]
],dtype=tf.int32)

转换为numpy
tensor1 = tf.constant([1,2,3,4,5])
tensor1
![]()
方法一
np.array(tensor1)
![]()
方法二
tensor1.numpy()
![]()
常用函数
a = tf.constant([
[1,2],
[3,4]
])
b = tf.constant([
[1,1],
[1,1]
])
# 加法
tf.add(a,b)
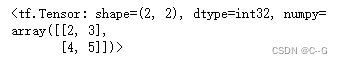
# 元素相乘
tf.multiply(a,b)
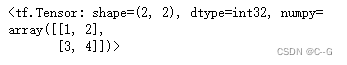
# 矩阵乘法
tf.matmul(a,b)

# 最大值
tf.reduce_max(a)
![]()
# 最大值索引
tf.argmax(a)
![]()
# 平均值
tf.reduce_mean(a)
![]()
其他运算

变量
变量是一种特殊的张量,形状是不可变,但可以更改其中的参数。
var = tf.Variable([
[1.0,2.0],
[3.0,4.0]
])
var

var.shape
![]()
var.dtype
![]()
var.numpy

变量修改值
var.assign([
[3.0,4.0],
[5.0,6.0]
])
var
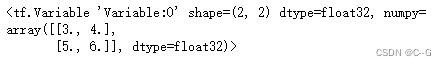
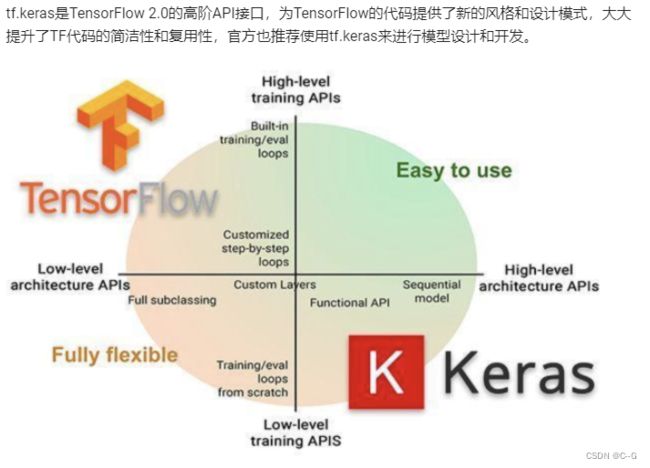
keras
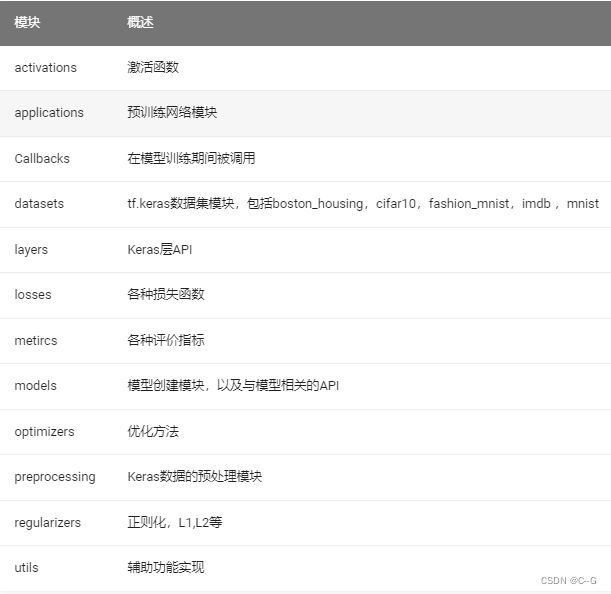
常用模块
常用方法
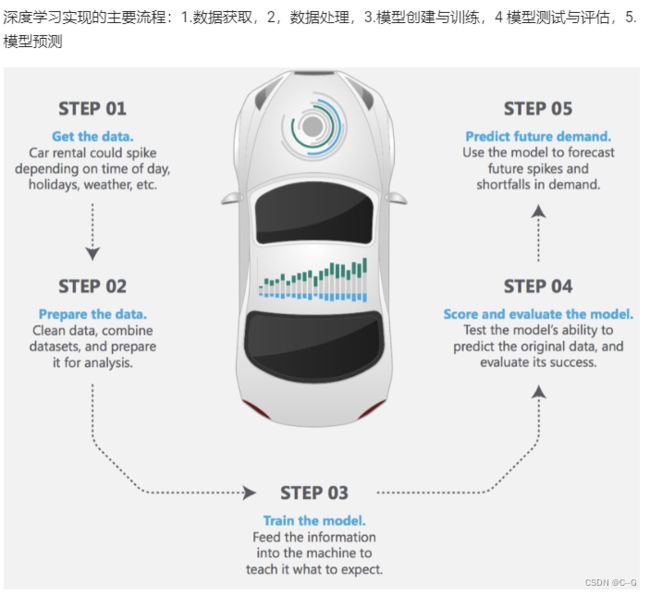
使用流程
- 导入tf.keras
import tensorflow as tf
from tensorflow import keras
- 数据输入
对于小的数据集,可以直接使用numpy格式的数据进行训练、评估模型,对于大型数据集或者要进行跨设备训练时使用tf.data.datasets来进行数据输入。
-
模型构建

-
训练与评估
配置训练过程
# 配置优化方法,损失函数和评价指标
model.compile(optimizer=tf.train.AdamOptimizer(0.001),
loss='categorical_crossentropy',
metrics=['accuracy'])
模型训练
# 指明训练数据集,训练epoch,批次大小和验证集数据
model.fit/fit_generator(dataset, epochs=10,
batch_size=3,
validation_data=val_dataset,
)
模型评估
# 指明评估数据集和批次大小
model.evaluate(x, y, batch_size=32)
模型预测
# 对新的样本进行预测
model.predict(x, batch_size=32)
-
回调函数(callbacks)

-
模型的保存和恢复
只保存参数
# 只保存模型的权重
model.save_weights('./my_model')
# 加载模型的权重
model.load_weights('my_model')
保存整个模型
# 保存模型架构与权重在h5文件中
model.save('my_model.h5')
# 加载模型:包括架构和对应的权重
model = keras.models.load_model('my_model.h5')
简单入门案例-鸢尾花种类预测
依赖导入
# 绘图
import seaborn as sns
# 数值计算
import numpy as np
# sklearn中的相关工具
# 划分训练集和测试集
from sklearn.model_selection import train_test_split
# 逻辑回归
from sklearn.linear_model import LogisticRegressionCV
# tf.keras中使用的相关工具
# 用于模型搭建
from tensorflow.keras.models import Sequential
# 构建模型的层和激活方法
from tensorflow.keras.layers import Dense, Activation
# 数据处理的辅助工具
from tensorflow.keras import utils
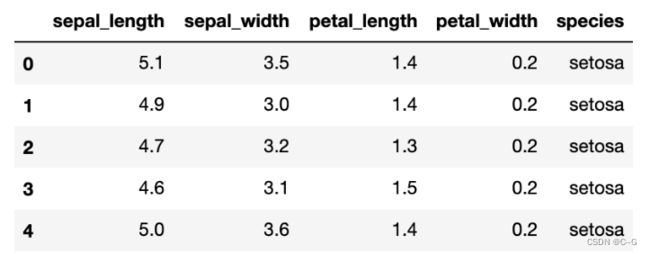
数据展示和划分
# 读取数据
iris = sns.load_dataset("iris")
# 展示数据的前五行
iris.head()
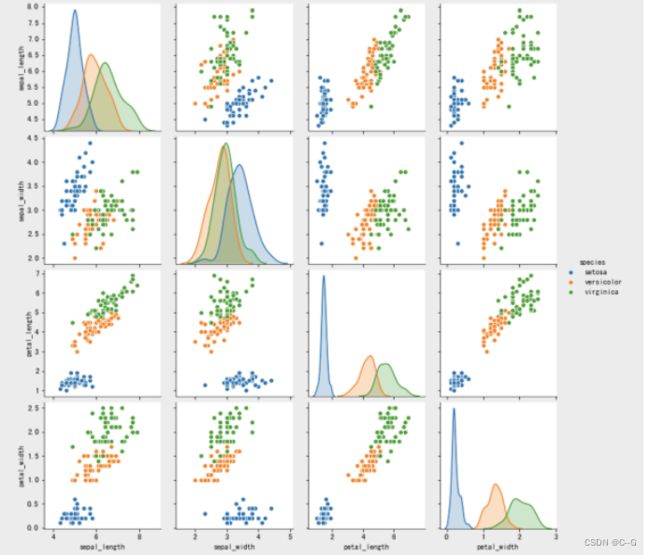
# 将数据之间的关系进行可视化
sns.pairplot(iris, hue='species')
数据划分
# 获取数据集的特征值和目标值
x = iris.values[:,:4]
y = iris.values[:,4]
# 将数据集划分为训练集和测试集
x_train,x_text,y_train,y_text = train_test_split(x,y,test_size=0.5,random_state=0)
sklearn实现
# 实例化分类器
lr = LogisticRegressionCV()
# 训练
lr.fit(train_X, train_y)
# 计算准确率并进行打印
print("Accuracy = {:.2f}".format(lr.score(test_X, test_y)))
![]()
tf.keras实现

热编码
# 目标值的热编码
def one_hot_encode(arr):
# 获取目标值中的所有类型并进行热编码
uniques,ids = np.unique(arr,return_inverse=True)
return utils.to_categorical(ids,len(uniques))
# 对目标值进行热编码
y_train_ohe = one_hot_encode(y_train)
y_text_ohe = one_hot_encode(y_text)
模型搭建
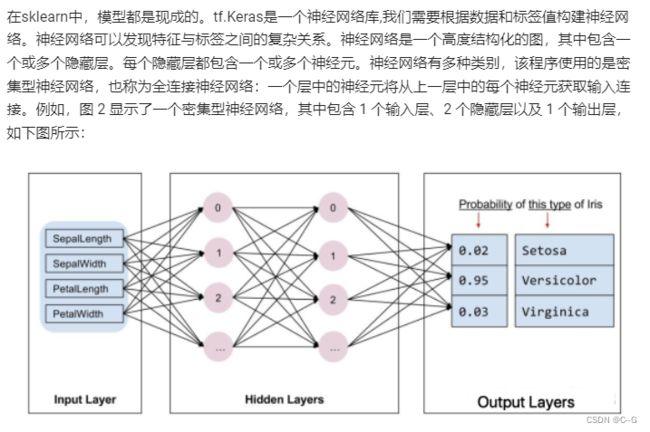

# 模型构建
model = Sequential([
# 隐藏层
Dense(10,activation="relu",input_shape=(4,)),
#隐藏层
Dense(10,activation="relu"),
# 输出层
Dense(3,activation="softmax")
])
查看模型的架构
model.summary()

utils.plot_model(model,show_shapes=True)
若出现:Failed to import pydot. You must pip install pydot and install graphviz
解决方法:https://blog.csdn.net/L_cherry_/article/details/122111303
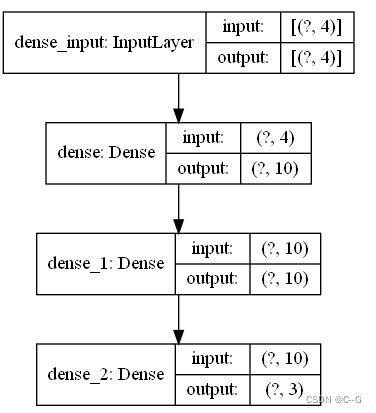
模型训练和预测
在训练和评估阶段,我们都需要计算模型的损失。这样可以衡量模型的预测结果与预期标签有多大偏差,也就是说,模型的效果有多差。我们希望尽可能减小或优化这个值,所以我们设置优化策略和损失函数,以及模型精度的计算方法
# 设置模型的相关参数:优化器,损失函数和评价指标
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=["accuracy"])
# 模型训练:epochs,训练样本送入到网络中的次数,batch_size:每次训练的送入到网络中的样本个数
model.fit(train_X, train_y_ohe, epochs=10, batch_size=1, verbose=1);
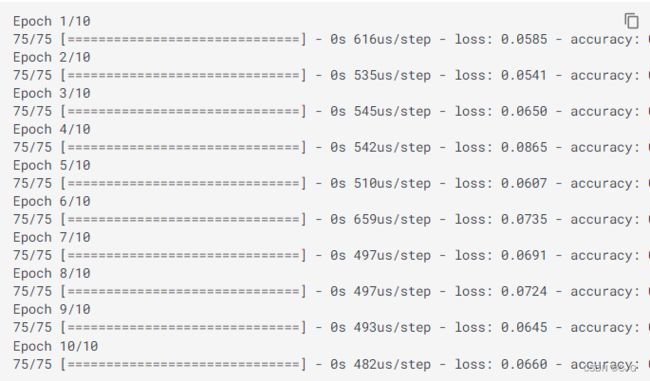

与sklearn中不同,对训练好的模型进行评估时,与sklearn.score方法对应的是tf.keras.evaluate()方法,返回的是损失函数和在compile模型时要求的指标
# 计算模型的损失和准确率
loss, accuracy = model.evaluate(test_X, test_y_ohe, verbose=1)
print("Accuracy = {:.2f}".format(accuracy))
