《大数据审计》上机实验记录
学习目标:
课程要求是本学期,掌握Python基本语法并且读取文件数据,进行图像绘制。
提示:《Big data audit》2020年秋季开课
实验目录
- 学习目标:
-
- 第一次上机
- 第二次上机
- 第三次上机
- 第四次上机
第一次上机
Description:
- 使用spyder,用python编写计算m到n之间所有偶数相加的和的函数(包含m和n),当发现m>n时,返回-1。
- 并测试下列数据:
- m=1,m=100
- m=4,n=4
- m=-100,n=-1
- m=-6,n=6
- m=3,n=3
- m=9,n=8
Answer:
Case One:
# 这是老师的方法
def summary(m,n):
s=0
if m>n:
s=-1
else:
for i in range(m,n+1):
if i%2==0:
s=s+i
return s
Case Two:
#这是本人的方法
# int[]
def generateList(m,n):
sum=0
x=m
y=n
L=[]
if(m>n):
print("你的输入有误")
return
while(m<=n):
if(m%2==0):
L.append(m)
sum+=m
m=m+1
print (L)
print("在%d, %d之间的偶数之和为%d" %(x,y,sum))
# int[]
generateList(9,8)
第二次上机
Description:
读取iris数据集中的花萼长度数据(已保存为csv格式),并对其进行排序、去重,求出和、累积和、均值、标准差、方差、最小值、最大值。(注:读取文件请使用np.loadtxt函数)
Answer:
- “Case One:”
# -*- coding: utf-8 -*-
"""
Created on Sat Oct 17 11:33:24 2020
@author: yyds
"""
# 导入numpy数据库
import numpy as np
# 将iris.csv数据进行加载(一定要对绝对路径加上引号)
# delimiter将字段以逗号分隔进行切片。默认的cvs文件中字段中数据都是以逗号进行分割的。
raw_data=np.loadtxt('D:/Spyder_data/source/iris.csv',delimiter=',',skiprows=1,dtype=str)
# print(raw_data)
'''
对花萼进行排序
'''
# argsort 可以指定列进行排序,返回的数组下标。
data_sort=raw_data[np.argsort(raw_data[:,1])]
print('~~~~~~~')
print(data_sort)
print('~~~~~~~')
'''
对花萼进行去重
'''
# 使用unique进行去重。
# data_unique=np.unique(raw_data)
# print(data_unique)
'''
对花萼进行求和
'''
# 读取文件中,花萼长度的数值一列。
raw=np.loadtxt('D:/Spyder_data/source/iris.csv',delimiter=',',skiprows=1,dtype=float,usecols=[1])
#print(raw)
# 在对于花萼长度列进行去重处理。
raw_unique=np.unique(raw)
print(raw_unique)
print(sum(raw_unique))
# 求累积和
raw_cumsum=np.cumsum(raw_unique)
print(raw_cumsum)
# 求均值
raw_average=np.average(raw_unique)
print(raw_average)
# 标准值
raw_std=np.std(raw_unique)
print(raw_std)
# 方差
print(np.var(raw_unique))
# 最小值或最大值
print(np.min(raw_unique))
print(np.max(raw_unique))
- Case Two:
# -*- coding: utf-8 -*-
"""
Created on Mon Nov 2 18:31:31 2020
@author: yyds
"""
import numpy as np
arr=np.loadtxt('D:/Spyder_data/source/iris.csv',skiprows=1,usecols=1,delimiter=',',dtype=float)
print('arr是:',arr)
arr.sort()
print('排序后:',arr)
uniarr=np.unique(arr)
print('去重后:',uniarr)
arr_sum=np.sum(uniarr,dtype=None) #总值
arr_sum=np.mean(uniarr,dtype=None) #均值
arr_std=np.std(uniarr) #标准差
arr_var=np.var(uniarr) #方差
arr_min=np.min(uniarr) #最小值
arr_max=np.max(uniarr) #最大值
第三次上机
Description:
举例 散点图 (利用散点图展示数据特征间的关系)
代码如下(示例):
# -*- coding: utf-8 -*-
"""
Created on Thu Oct 22 13:35:34 2020
@author: yyds
"""
import matplotlib.pyplot as plt
import numpy as np
plt.figure(figsize=(10,10)) #创建4*4画布
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus'] = False
x=np.arange(50)
plt.plot(x,np.sin(x))
plt.plot(x,np.cos(x))
plt.title('sin_cos')
plt.xlabel("x_value")
plt.ylabel("y_value")
plt.legend(["sin x",'cos x'])
plt.show()
# In[]
import matplotlib.pyplot as plt
import numpy as np
data = np.load("D:\Spyder_data\国民经济核算季度数据.npz",allow_pickle=True)
print(data.files)
print(data['columns'])
print(data['values'])
plt.scatter(np.arange(69),data['values'][:,2])
# In[]
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus'] = False
plt.title('2000-2007年季度国内生产总值情况')
plt.xlabel("年度季度")
plt.ylabel("生产总值")
plt.xticks(np.arange(0,69,4),data['values'][::4,1],rotation=90)
plt.scatter(np.arange(69),data["values"][:,2])
# In[]
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus'] = False
plt.title('2000-2007年季度国内生产总值情况')
plt.xlabel("年度季度")
plt.ylabel("生产总值")
plt.xticks(np.arange(0,69,4),data['values'][::4,1],rotation=90)
for i in (3,4,5):
plt.scatter(np.arange(69),data['values'][:,i])
plt.legend(['第一产业','第二产业','第三产业'])
plt.show()
# In[]
import matplotlib.pyplot as plt
import numpy as np
import random
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus'] = False
x = range(0, 60) #设置取值范围为0~120,取得值用作分钟数,既 0到60分钟
temperature = [random.randint(20,35) for i in range(60)] # 取范围在20~35之间的随机数,总数为60个
print(temperature)
plt.figure(figsize=(100,100))
plt.xticks(np.arange(0,60,5))
plt.yticks(np.arange(0,35,5),temperature)
plt.plot(x,temperature)
plt.title("11点0分到12点之间北京和南京的温度变化图")
plt.xlabel("时间")
plt.ylabel("温度")
plt.legend(["南京","北京","南京均温","北京均温"])
plt.show()
Description:
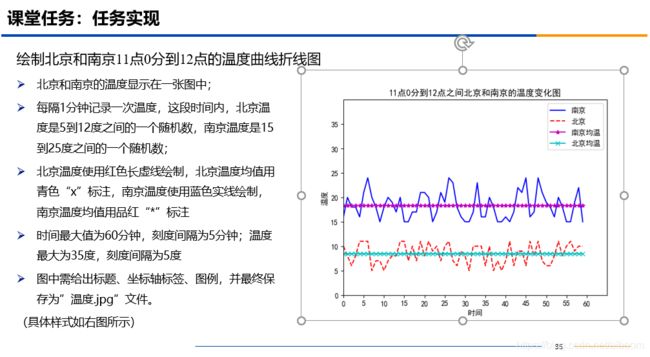
本人代码如下(示例):
# -*- coding: utf-8 -*-
"""
Created on Thu Oct 22 15:13:39 2020
@author: yyds
"""
import matplotlib.pyplot as plt
import numpy as np
import random
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus'] = False
x = range(0, 60) #设置取值范围为0~120,取得值用作分钟数,既 0到60分钟
temperature_n = [random.randint(5,12) for i in range(60)] # 取范围在20~35之间的随机数,总数为60个
temperature_b = [random.randint(15,25) for i in range(60)]
average_n=np.mean(temperature_n)
average_b=np.mean(temperature_b)
aver_b=np.zeros([60])+average_b
aver_n=np.zeros([60])+average_n
plt.figure(figsize=(8,8))
plt.xlim(0,60)
plt.xticks(np.arange(0,65,5))
plt.ylim(0,35)
plt.yticks(np.arange(0,40,5))
plt.plot(x,temperature_n,color="blue",linestyle="-")
plt.plot(x,temperature_b,color="red",linestyle="--")
plt.plot(x,aver_n,marker="*",color="purple")
plt.plot(x,aver_b,marker="o", color="cyan")
plt.title("11点0分到12点之间北京和南京的温度变化图")
plt.xlabel("时间")
plt.ylabel("温度")
plt.legend(["南京","北京","南京均温","北京均温"])
plt.show()
运行结果:
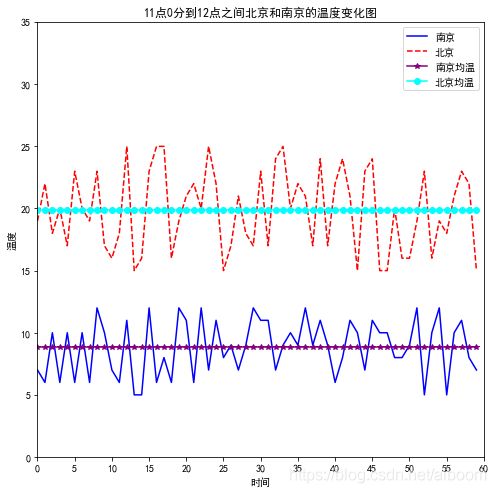
老师代码如下(示例):
# -*- coding: utf-8 -*-
"""
Created on Mon Nov 2 19:33:45 2020
@author: yyds
"""
import matplotlib.pyplot as plt
import numpy as np
# 中文显示问题--下面手动修改配置
plt.rcParams["font.sans-serif"]=["SimHei"]
plt.rcParams["axes.unicode_minus"] = False
# 准备x,y轴数据
x=np.arange(60)
y_nj=np.random.randint(15,25,60)
y_bj=np.random.randint(5,12,60)
y_njAvgV=np.mean(y_nj)
y_bjAvgV=np.mean(y_bj)
y_njAvgA=np.zeros([60])+y_njAvgV
y_bjAvgA=np.zeros([60])+y_bjAvgV
plt.xticks(np.linspace(0,60,13))
plt.yticks(np.linspace(0,35,8))
plt.xlim(0,60)
plt.ylim(0,35)
plt.xlabel("时间")
plt.ylabel("温度")
plt.title("11点0分到12点之间北京和南京的温度变化图")
# 创建画布---多个坐标,绘制折线图
plt.plot(x,y_nj,label="南京",color="b",linestyle='-')
plt.plot(x,y_bj,label="北京",color="r",linestyle="--")
plt.plot(x,y_njAvgA,label='南京均温',color="m",marker="*")
plt.plot(x,y_njAvgA,label="北京均温",color="c",marker="x")
plt.legend()
plt.savefig("温度.jpg")
plt.show()
运行结果:
Description:

本人代码如下(示例):
# -*- coding: utf-8 -*-
"""
Created on Sat Oct 24 21:49:49 2020
@author: yyds
"""
import matplotlib.pyplot as plt
import numpy as np
# allow_pickle=False 默认为False,意思是无法加载数组对象。
data = np.load("d:\Spyder_data\populations.npz",allow_pickle=True)
# 查看数组元素
print(data.files)
print(data['data'])
print(data['feature_names'])
plt.rcParams['font.sans-serif']='SimHei'#设置中文显示
name=data['feature_names']#提取其中的feature_names数组,视为数据的标签
values=data['data']#提取其中的data数组,视为数据的存在位置
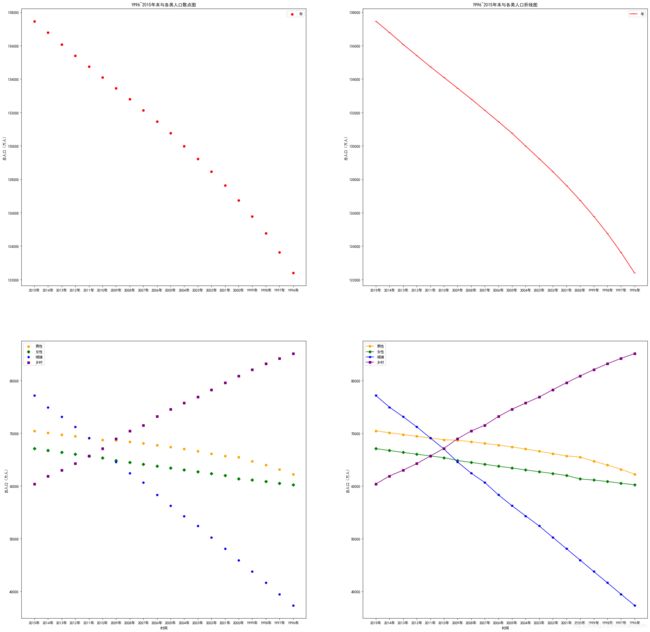
# 散点图
p1=plt.figure(figsize=(30,30))
p_sub=p1.add_subplot(2,2,1)#创建一个两行一列的子图并开始绘制
#在子图上绘制散点图
plt.scatter(values[0:20,0],values[0:20,1],marker='8',color='red')
plt.ylabel('总人口(万人)')
plt.legend('年末')
plt.title('1996~2015年末与各类人口散点图')
p_sub=p1.add_subplot(2,2,3)#绘制子图2
plt.scatter(values[0:20,0],values[0:20,2],marker='o',color='orange')
plt.scatter(values[0:20,0],values[0:20,3],marker='D',color='green')
plt.scatter(values[0:20,0],values[0:20,4],marker='p',color='blue')
plt.scatter(values[0:20,0],values[0:20,5],marker='s',color='purple')
plt.xlabel('时间')
plt.ylabel('总人口(万人)')
plt.xticks(values[0:20,0])
plt.legend(['男性','女性','城镇','乡村'])
# plt.savefig("d:\Spyder_data\population1.png")
# 年末总人口折线图
# p2=plt.figure(figsize=(12,12))
p_sub=p1.add_subplot(2,2,2) # 创建一个子图并开始绘制
#在子图上绘制折线图
plt.plot(values[0:20,0],values[0:20,1],marker="_", color="red")
plt.ylabel('总人口(万人)')
plt.legend('年末')
plt.title('1996~2015年末与各类人口折线图')
# 详细的人口折线图
p_sub=p1.add_subplot(2, 2, 4) # 创建了子图开始绘制
plt.plot(values[0:20,0],values[0:20,2],marker='o', color='orange')
plt.plot(values[0:20,0],values[0:20,3],marker='D', color='green')
plt.plot(values[0:20,0],values[0:20,4],marker='p', color='blue')
plt.plot(values[0:20,0],values[0:20,5],marker='s', color='purple')
plt.xlabel('时间')
plt.ylabel("总人口(万人)")
plt.legend(['男性','女性','城镇','乡村'])
plt.xticks(values[0:20,0])
plt.savefig("d:\Spyder_data\population.png")
plt.show()
运行结果:
班级同学优秀代码如下(示例):
# -*- coding: utf-8 -*-
"""
Created on Sun Oct 25 17:11:07 2020
@author: Echo
"""
import numpy as np
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['FangSong'] # 指定默认字体
plt.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题
fig, (ax0, ax1) = plt.subplots(nrows=2, ncols=1, sharex=True,figsize=(14, 12))
df = np.load('d:\Spyder_data\populations.npz',allow_pickle='True')
#print(df['feature_names'][1:])
#print(df['data'])
x = np.arange(20)
y = df['data'][:-2] #从不包括-2位置的元素往前取元素。
ax0.set_title('1996-2015年总人口、男女、城镇人口散点图')
ax0.scatter(y[::-1,0],y[::-1,1]) #y[::-1,0] 取从后向前(相反)的第0列元素
ax0.scatter(y[::-1,0],y[::-1,2],marker='o',color='y')
ax0.scatter(y[::-1,0],y[::-1,3],marker='x',color='g')
ax0.scatter(y[::-1,0],y[::-1,4],marker='*',color='b')
ax0.scatter(y[::-1,0],y[::-1,5],marker='s',color='m')
ax0.set_ylabel("总人口(万人)")
ax0.legend(df['feature_names'][1:])
ax1.set_title('1996-2015年总人口、男女、城镇任娄折线图')
ax1.plot(y[::-1,0],y[::-1,1],marker='1')
ax1.plot(y[::-1,0],y[::-1,2],marker=4,color='y')
ax1.plot(y[::-1,0],y[::-1,3],marker=5,color='g')
ax1.plot(y[::-1,0],y[::-1,4],marker=6,color='b')
ax1.plot(y[::-1,0],y[::-1,5],marker=7,color='m')
ax1.set_ylabel("总人口(万人)")
ax1.legend(df['feature_names'][1:]) #图例从"男性人口"遍历到"乡村人口"
plt.suptitle("1996-2015年总人口、男女、城乡人口散点、折线图") #绘制总标题
plt.xticks(rotation='45')
plt.savefig('population.png')
plt.show()
第四次上机
本人的代码:
# -*- coding: utf-8 -*-
"""
Created on Thu Nov 5 15:08:37 2020
@author: yyds
"""
import matplotlib.pyplot as plt
import numpy as np
plt.rcParams['font.sans-serif'] = ['FangSong']
plt.rcParams['axes.unicode_minus'] = False
p1=plt.figure(figsize=(30,30))
p_sub=p1.add_subplot(3,4,1)
data=np.load("d:\Spyder_data\populations.npz",allow_pickle='True' )
print(data['feature_names'])
print(data['data'])
plt.ylabel('人口(万人)')
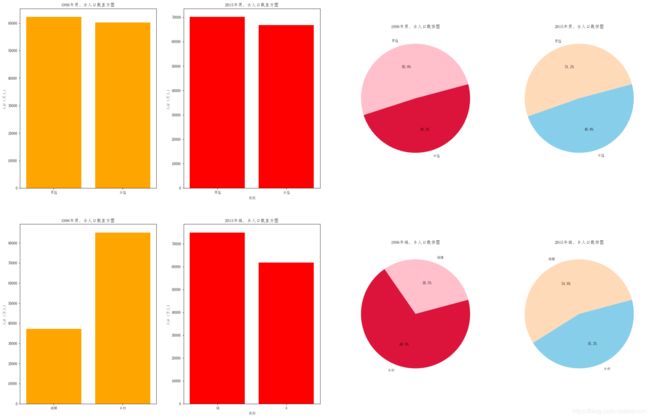
plt.title("1996年男、女人口数直方图")
num=data['data'][19,2:4]
plt.bar(range(len(num)),num,color="orange")
plt.xticks(range(len(num)),["男性","女性"])
p_sub=p1.add_subplot(3,4,5)
plt.ylabel('人口(万人)')
plt.title("1996年城、乡人口数直方图")
plt.ylabel('人口(万人)')
plt.title("1996年男、女人口数直方图")
num=data['data'][19,4:6]
plt.bar(range(len(num)),num,color="orange")
plt.xticks(range(len(num)),["城镇","乡村"])
p_sub=p1.add_subplot(3,4,2)
plt.ylabel('人口(万人)')
plt.title("2015年男、女人口数直方图")
plt.xlabel("类别")
num=data['data'][1,2:4]
plt.bar(range(len(num)),num,color='red')
plt.xticks(range(len(num)),['男性','女性'])
p_sub=p1.add_subplot(3,4,6)
plt.ylabel('人口(万人)')
plt.title("2015年城、乡人口数直方图")
plt.xlabel("类别")
num=data['data'][1,4:6]
plt.bar(range(len(num)),num,color='red')
plt.xticks(range(len(num)),['城','乡'])
p_sub=p1.add_subplot(3,4,3)
dis=0
sp=[0,0]
labels=['男性','女性']
sizes=[data['data'][19,2]/data['data'][19,1],data['data'][19,3]/data['data'][19,1]]
plt.pie(sizes,explode=sp,labels=labels,colors=['pink','crimson'],autopct="%1.1f%%",startangle=15)
plt.title("1996年男、女人口数饼图")
p_sub=p1.add_subplot(3,4,7)
dis=0
sp=[0,0]
labels=['城镇','乡村']
sizes=[data['data'][19,4]/data['data'][19,1],data['data'][19,5]/data['data'][19,1]]
plt.pie(sizes,explode=sp,labels=labels,colors=['pink','crimson'],autopct="%1.1f%%",startangle=15)
plt.title("1996年城、乡人口数饼图")
p_sub=p1.add_subplot(3,4,4)
dis=0
sp=[0,0]
labels=['男性','女性']
sizes=[data['data'][1,2]/data['data'][1,1],data['data'][1,3]/data['data'][1,1]]
plt.pie(sizes,explode=sp,labels=labels,colors=['PeachPuff','skyblue'],autopct="%1.1f%%",startangle=15)
plt.title("2015年男、女人口数饼图")
p_sub=p1.add_subplot(3,4,8)
dis=0
sp=[0,0]
labels=['城镇','乡村']
sizes=[data['data'][1,4]/data['data'][1,1],data['data'][1,5]/data['data'][1,1]]
plt.pie(sizes,explode=sp,labels=labels,colors=['PeachPuff','skyblue'],autopct="%1.1f%%",startangle=15)
plt.title("2015年城、乡人口数饼图")
p2=plt.figure(figsize=(30,30))
p_sub=p2.add_subplot(3,4,9)
plt.boxplot(data['data'][1:20,1:6],notch=True,labels=['年末','男性','女性','城镇','乡村'],meanline=True)
plt.xlabel('类别')
plt.ylabel('人口(万人)')
plt.title('1996~2015年各特征人口箱线图')
实验结果:

课后作业范例代码(数据集字段选取9月21日):
https://raw.githubusercontent.com/canghailan/Wuhan-2019-nCoV/master/Wuhan-2019-nCoV.csv
# -*- coding: utf-8 -*-
"""
Created on Sat Nov 7 13:22:00 2020
@author: yyds
"""
#coding:utf-8
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
def rosetype_pie(country,confirmed,size,colors):
plt.rcParams['font.sans-serif'] = ['SimHei'] # 中文显示
num= len(size) # 柱子的数量
width = 2 * np.pi / num # 每个柱子的宽度
rad = np.cumsum([width] * num) # 每个柱子的角度
plt.figure(figsize=(8, 8),dpi=500,) # 创建画布
ax = plt.subplot(projection='polar')
ax.set_ylim(-1, np.ceil(max(size) + 1)) # 中间空白,-1为空白半径大小,可自行调整
ax.set_theta_zero_location('N',-5.0) # 设置极坐标的起点方向 W,N,E,S, -5.0为偏离数值,可自行调整
ax.set_theta_direction(1) # 1为逆时针,-1为顺时针
ax.grid(False) # 不显示极轴
ax.spines['polar'].set_visible(False) # 不显示极坐标最外的圆形
ax.set_yticks([]) # 不显示坐标间隔
ax.set_thetagrids([]) # 不显示极轴坐标
ax.bar(rad, size, width=width, color=colors, alpha=1) # 画图
ax.bar(rad, 1, width=width, color='white', alpha=0.15) # 中间添加白色色彩使图案变浅
ax.bar(rad, 3, width=width, color='white', alpha=0.1) # 中间添加白色色彩使图案变浅
ax.bar(rad, 5, width=width, color='white', alpha=0.05) # 中间添加白色色彩使图案变浅
ax.bar(rad, 7, width=width, color='white', alpha=0.03) # 中间添加白色色彩使图案变浅
# 设置text
for i in np.arange(num):
if i < 8:
ax.text(rad[i], # 角度
size[i]-0.2, # 长度
country[i]+'\n'+str(confirmed[i])+'例', # 文本
rotation=rad[i] * 180 / np.pi -5, # 文字角度
rotation_mode='anchor',
# alpha=0.8,#透明度
fontstyle='normal',# 设置字体类型,可选参数[ ‘normal’ | ‘italic’ | ‘oblique’ ],italic斜体,oblique倾斜
fontweight='black', # 设置字体粗细,可选参数 [‘light’, ‘normal’, ‘medium’, ‘semibold’, ‘bold’, ‘heavy’, ‘black’]
color='white', # 设置字体颜色
size=size[i]/2.2, # 设置字体大小
ha="center", # 'left','right','center'
va="top", # 'top', 'bottom', 'center', 'baseline', 'center_baseline'
)
elif i < 15:
ax.text(rad[i]+0.02,
size[i]-0.7,
country[i] + '\n' + str(confirmed[i]) + '例',
fontstyle='normal',
fontweight='black',
color='white',
size=size[i] / 1.6,
ha="center",
)
else:
ax.text(rad[i],
size[i]+0.1,
str(confirmed[i]) + '例 ' + country[i],
rotation=rad[i] * 180 / np.pi + 85,
rotation_mode='anchor',
fontstyle='normal',
fontweight='black',
color='black',
size=4,
ha="left",
va="bottom",
)
plt.show()
if __name__ == '__main__':
df = pd.read_csv('D:\Wuhan-2019-nCoV_09_21.csv') # 利用pandas读取数据
colors = [(0.68359375, 0.02734375, 0.3203125),
(0.78125, 0.05078125, 0.2578125),
(0.875, 0.0390625, 0.1796875),
(0.81640625, 0.06640625, 0.0625),
(0.8515625, 0.1484375, 0.08203125),
(0.90625, 0.203125, 0.13671875),
(0.89453125, 0.2890625, 0.0703125),
(0.84375, 0.2421875, 0.03125),
(0.9140625, 0.26953125, 0.05078125),
(0.85546875, 0.31640625, 0.125),
(0.85546875, 0.3671875, 0.1171875),
(0.94921875, 0.48046875, 0.28125),
(0.9375, 0.51171875, 0.1484375),
(0.93359375, 0.59765625, 0.0625),
(0.93359375, 0.62890625, 0.14453125),
(0.86328125, 0.5859375, 0.15234375),
(0.86328125, 0.71875, 0.16015625),
(0.86328125, 0.8203125, 0.16015625),
(0.76171875, 0.8671875, 0.16015625),
(0.53125, 0.85546875, 0.15625),
(0.4765625, 0.94140625, 0.0703125),
(0.21484375, 0.91015625, 0.0625),
(0.15234375, 0.88671875, 0.08203125),
(0.11328125, 0.87890625, 0.19921875),
(0.11328125, 0.8125, 0.1796875),
(0.1875, 0.76953125, 0.2109375),
(0.2109375, 0.78125, 0.38671875),
(0.1484375, 0.76953125, 0.30859375),
(0.22265625, 0.73046875, 0.35546875),
(0.2890625, 0.6875, 0.4765625)] # 转化为小数的rgb色列表,
df_top_confirmed = df.loc[(df['date'] == '2020-09-21') & (df['province'].isnull())].sort_values('confirmed',ascending=False).head(30) # 选择9.21日确诊数前三十的国家
country = df_top_confirmed['country'].tolist()
confirmed = df_top_confirmed['confirmed'].tolist()
size = [22 , 19, 17, 12, 11, 10, 9, 8, 7.2, 7.0, 6.8, 6.6, 6.4, 6.2, 6.0, 5.8, 5.6, 5.4, 5.2, 5.0, 4.8, 4.6, 4.4, 4.2, 4.0, 3.8, 3.6, 3.4, 3.2, 3.0] # 自定义一个柱长度列
rosetype_pie(country, confirmed, size, colors)
运行结果:
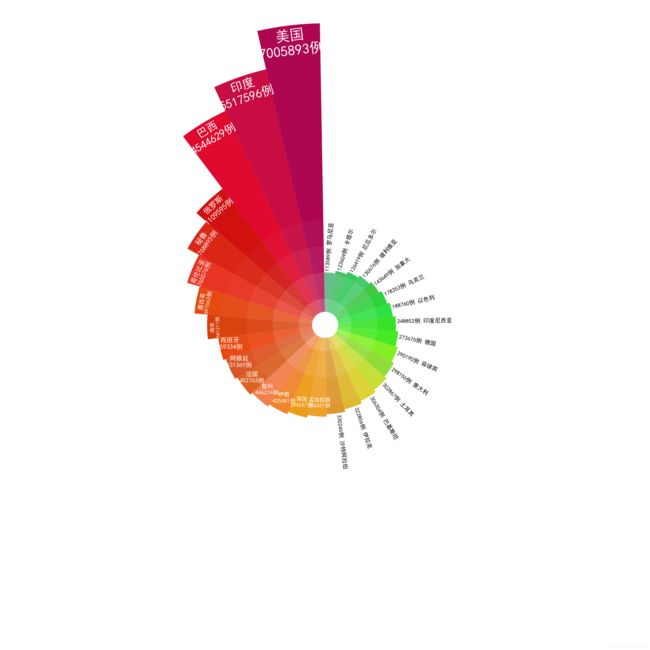
课后作业有图标的代码(数据集字段选取9月21日):
# -*- coding: utf-8 -*-
"""
Created on Sat Nov 7 15:11:14 2020
@author: yyds
"""
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from mpl_toolkits.axes_grid1.inset_locator import inset_axes
def rosetype_pie(country,confirmed,size,colors):
plt.rcParams['font.sans-serif'] = ['SimHei']
num= len(size)
width = 2 * np.pi / num
rad = np.cumsum([width] * num)
plt.figure(figsize=(20, 20),dpi=500,)
ax = plt.subplot(projection='polar')
ax.set_ylim(-1, np.ceil(max(size) + 1))
ax.set_theta_zero_location('N',-5.0)
ax.set_theta_direction(1)
ax.grid(False)
ax.spines['polar'].set_visible(False)
ax.set_yticks([])
ax.set_thetagrids([])
ax.bar(rad, size, width=width, color=colors, alpha=1)
ax.bar(rad, 1, width=width, color='white', alpha=0.15)
ax.bar(rad, 3, width=width, color='white', alpha=0.1)
ax.bar(rad, 5, width=width, color='white', alpha=0.05)
ax.bar(rad, 7, width=width, color='white', alpha=0.03)
# 设置text
for i in np.arange(num):
if i < 8:
ax.text(rad[i],
size[i]-0.2,
country[i]+'\n'+str(confirmed[i])+'例',
rotation=rad[i] * 180 / np.pi -5,
rotation_mode='anchor',
fontstyle='normal',
fontweight='black',
color='white',
size=size[i]/2.2,
ha="center",
va="top",
)
elif i < 15:
ax.text(rad[i]+0.02,
size[i]-0.7,
country[i] + '\n' + str(confirmed[i]) + '例',
fontstyle='normal',
fontweight='black',
color='white',
size=size[i] / 1.6,
ha="center",
)
else:
ax.text(rad[i],
size[i]+0.1,
str(confirmed[i]) + '例 ' + country[i],
rotation=rad[i] * 180 / np.pi + 85,
rotation_mode='anchor',
fontstyle='normal',
fontweight='black',
color='black',
size=4,
ha="left",
va="bottom",
)
plt.title("全球新冠肺炎疫情",fontsize="70",horizontalalignment="right")
df_down_confirmed = df.loc[(df['date'] == '2020-09-21') & (df['province'].isnull())].sort_values('confirmed',ascending=False).tail(30)
country_down = df_down_confirmed['country'].tolist()
print(country_down)
confirmed_down=df_down_confirmed['confirmed'].tolist()
print(confirmed_down)
cell_width = 212
cell_height = 22
swatch_width= 1
axes_kwargs={"fc":"#000000"}
axins1=inset_axes(ax,width=39*0.18, height=35*0.16, loc=1)
n = 30
ncols = 2
nrows = n // ncols + int(n % ncols > 0)
axins1.set_xlim(0,cell_width*2)
axins1.set_ylim(cell_height* (nrows-0.5),-cell_height/2.)
axins1.yaxis.set_visible(False)
axins1.xaxis.set_visible(False)
axins1.set_axis_off()
for i in range(n):
row = i % nrows
col = i // nrows
y = row * cell_height
swatch_start_x = cell_width * col
swatch_end_x = cell_width * col + swatch_width
text_pos_x = cell_width * col + swatch_width + 10
axins1.text(text_pos_x-35, y, str(confirmed_down[i]), fontsize=15,
horizontalalignment='left',
verticalalignment='center',
backgroundcolor="hotpink")
axins1.text(text_pos_x, y, country_down[i], fontsize=15,
horizontalalignment='left',
verticalalignment='center')
plt.show()
if __name__ == '__main__':
df = pd.read_csv('D:\data_set.csv')
colors = [(0.68359375, 0.02734375, 0.3203125),
(0.78125, 0.05078125, 0.2578125),
(0.875, 0.0390625, 0.1796875),
(0.81640625, 0.06640625, 0.0625),
(0.8515625, 0.1484375, 0.08203125),
(0.90625, 0.203125, 0.13671875),
(0.89453125, 0.2890625, 0.0703125),
(0.84375, 0.2421875, 0.03125),
(0.9140625, 0.26953125, 0.05078125),
(0.85546875, 0.31640625, 0.125),
(0.85546875, 0.3671875, 0.1171875),
(0.94921875, 0.48046875, 0.28125),
(0.9375, 0.51171875, 0.1484375),
(0.93359375, 0.59765625, 0.0625),
(0.93359375, 0.62890625, 0.14453125),
(0.86328125, 0.5859375, 0.15234375),
(0.86328125, 0.71875, 0.16015625),
(0.86328125, 0.8203125, 0.16015625),
(0.76171875, 0.8671875, 0.16015625),
(0.53125, 0.85546875, 0.15625),
(0.4765625, 0.94140625, 0.0703125),
(0.21484375, 0.91015625, 0.0625),
(0.15234375, 0.88671875, 0.08203125),
(0.11328125, 0.87890625, 0.19921875),
(0.11328125, 0.8125, 0.1796875),
(0.1875, 0.76953125, 0.2109375),
(0.2109375, 0.78125, 0.38671875),
(0.1484375, 0.76953125, 0.30859375),
(0.22265625, 0.73046875, 0.35546875),
(0.2890625, 0.6875, 0.4765625)]
df_top_confirmed = df.loc[(df['date'] == '2020-09-21') & (df['province'].isnull())].sort_values('confirmed',ascending=False).head(30)
country = df_top_confirmed['country'].tolist()
confirmed = df_top_confirmed['confirmed'].tolist()
size = [22 , 19, 17, 12, 11, 10, 9, 8, 7.2, 7.0, 6.8, 6.6, 6.4, 6.2, 6.0, 5.8, 5.6, 5.4, 5.2, 5.0, 4.8, 4.6, 4.4, 4.2, 4.0, 3.8, 3.6, 3.4, 3.2, 3.0]
rosetype_pie(country, confirmed, size, colors)
运行结果:
WJY大佬的源码(需要timeseries.json数据集):
https://download.csdn.net/download/aiboom/13099499
# -*- coding: utf-8 -*-
"""
Spyder Editor
This is a temporary script file.
"""
import matplotlib.pyplot as plt
import numpy as np
import matplotlib.colors as mcolors
from mpl_toolkits.axes_grid1.inset_locator import inset_axes
# In[0]
import json
data=json.load(open("C:\\Users\\haoyu\\Desktop\\parsedata\\timeseries.json"))
day=55#2020-3-17
temp=[]
with open("{}_day".format(day),"w") as target:
for key in data.keys():
daydate=data[key][day]
daydate["nation"]=key
temp.append(daydate)
dat=sorted(temp, key = lambda i:i["confirmed"],reverse=True)
nations=[]
for i in dat:
nations.append(i["nation"])
# In[1]
N=50
fig=plt.figure(figsize=(30,30))
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
ax1=fig.add_subplot(121)
theta = np.linspace(0.0, 2 * np.pi, N, endpoint=False)
radii = np.linspace(30, 120, N, endpoint=False)
theta=theta[::-1]
width = np.pi*2/N
colors = plt.cm.viridis((radii-radii[0])/(radii[N-1]-radii[0]))
colors=colors[::-1]
colors=colors[:,[0,1,2,3]]
ax = plt.subplot(111, projection='polar')
ax.grid(False)
ax.set_xticks([])
ax.set_yticks([])
ax.spines['polar'].set_visible(False)
ax.set_theta_zero_location("N",offset=5)
ax.bar(theta, radii, width=width, bottom=0.0, color=colors)
ax.fill(theta, [8]*N, color="w")
tempdata=dat[:N]
tempdata=tempdata[::-1]
split=23
rotations=np.linspace(90,-270,N, endpoint=False)
for i in range(N-split):
ax.text(theta[i]-0.02,radii[i]+11,tempdata[i]["nation"]+"\n"+str(tempdata[i]["confirmed"]),rotation=rotations[i],ha="center"
,fontsize=20)
for i in range(N-split,N):
ax.text(theta[i],radii[i]-11,tempdata[i]["nation"]+"\n"+str(tempdata[i]["confirmed"]),ha="center"
,fontsize=20,color="w",weight="semibold")
plt.title("全球新冠肺炎疫情",fontsize="99",horizontalalignment="right")
cell_width = 212
cell_height = 22
swatch_width= 1
axes_kwargs={"fc":"#000000"}
axins1=inset_axes(ax,width=30*0.17, height=30*0.3, loc=1)
n = len(dat)-N-100
ncols = 2
nrows = n // ncols + int(n % ncols > 0)
# dat=dat[N:]
labeldata=dat[N:]
axins1.set_xlim(0,cell_width*2)
axins1.set_ylim(cell_height* (nrows-0.5),-cell_height/2.)
axins1.yaxis.set_visible(False)
axins1.xaxis.set_visible(False)
axins1.set_axis_off()
ax
for i in range(n):
row = i % nrows
col = i // nrows
y = row * cell_height
swatch_start_x = cell_width * col
swatch_end_x = cell_width * col + swatch_width
text_pos_x = cell_width * col + swatch_width + 10
axins1.text(text_pos_x-35, y, str(labeldata[i]["confirmed"]), fontsize=15,
horizontalalignment='left',
verticalalignment='center',
backgroundcolor="hotpink")
axins1.text(text_pos_x, y, labeldata[i]["nation"], fontsize=15,
horizontalalignment='left',
verticalalignment='center')
plt.savefig("D://ex2.png")
plt.show()
运行结果:

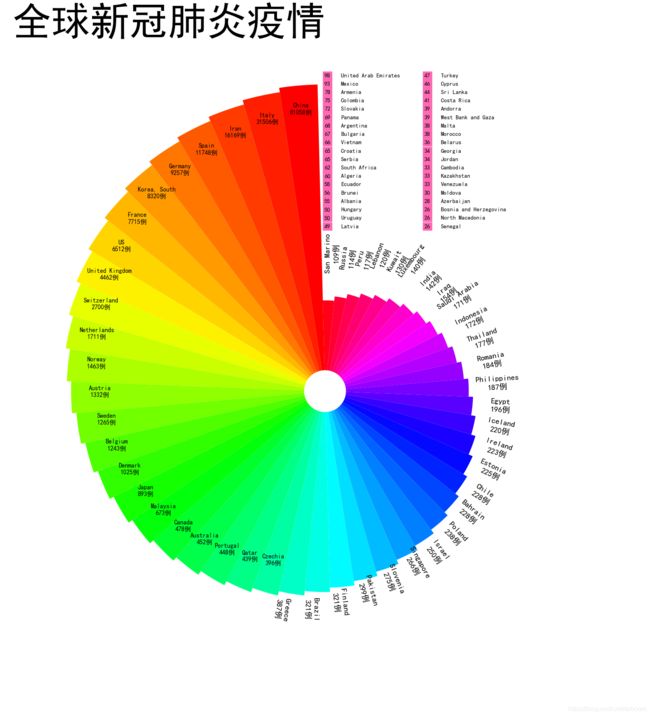
WJY大佬的代码"魔改":
# -*- coding: utf-8 -*-
"""
Created on Sun Nov 8 22:09:17 2020
@author: yyds
"""
import matplotlib.pyplot as plt
import numpy as np
import matplotlib.colors as mcolors
from mpl_toolkits.axes_grid1.inset_locator import inset_axes
# In[0]
'''
第一区块,对所有的json数据结构进行处理。
'''
import json
data=json.load(open("D:\\timeseries.json")) #打开json文件存到data变量中
# print(data["China"][55])
# print(len(data)) # 一共188个国家的疫情数据。
day=55#2020-3-17 #json数据索引从0~55
temp=[] #临时的空列表
with open("{}_day".format(day),"w") as target: #执行指定格式的输出,并赋值给target变量。
for key in data.keys(): #遍历data.json中key=‘国家’。
daydate=data[key][day] #将data.json文件中的数据中,2020-3-17的数据全部存到了daydate键值对中。
daydate["nation"]=key #将nation值=国家名
temp.append(daydate) #将daydate字典追加到temp列表中。
# print(temp)
# sorted(iterable, key=None, reverse=False)第一个参数迭代对象,第二个是用来比较的元素列,第三个是排序规则
dat=sorted(temp, key = lambda i:i["confirmed"],reverse=True) #将排列好的列表中的字典赋值给dat遍历。
nations=[] #定义一个nations列表。
#将dat排好序的列表,取出“nation”国家键值对尾追加到nations列表中。
for i in dat:
nations.append(i["nation"])
# In[1]
'''
第二区块,进行图像绘制
'''
N=50 #确定绘制图形的数量。
fig=plt.figure(figsize=(30,30))
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
ax1=fig.add_subplot(121) #121将画布分割成1行2列,图像画在从左到右从上到下的第1块
# np.linspace(start, stop, num=50, endpoint=True, retstep=False, dtype=None)
# start:开始,stop:终止,num:间隔等差,一共有50个元素,endpoint=True是包括stop的位置的
theta = np.linspace(0.0, 2 * np.pi, N, endpoint=False) #0到360度划分有50个数量的间隔(生成一维顺序的数组值。)
# print(theta)
radii = np.linspace(35, 120, N, endpoint=False) #30到120划分有50个数量的间隔
print(radii)
theta=theta[::-1] #倒序输出一维数组值,并且赋值自身。
print(theta)
width = np.pi*2/N #计算每一份圆心角的大小
colors = plt.cm.hsv((radii-radii[0])/(radii[N-1]-radii[0])) #设置绘图颜色的函数
colors=colors[::-1]
colors=colors[:,[0,1,2,3]]
ax = plt.subplot(111, projection='polar') # 第一个参数:三个整数是行数、列数和索引值 第二个参数:设置为极坐标
ax.grid(False) #没有网格线
ax.set_xticks([]) #x斜着显示
ax.set_yticks([]) #y斜着显示
ax.spines['polar'].set_visible(False) #获取极坐标轴,并且将坐标轴隐藏。
ax.set_theta_zero_location("N",offset=5) # 方法用于设置极坐标0°位置,设置扇形偏离位置。
ax.bar(theta, radii, #角度对应位置,半径对应高度。
width=width, #宽度
bottom=0.0, #远离圆心,设置偏离距离
color=colors)
ax.fill(theta, [8]*N, color="w")
tempdata=dat[:N] #遍历dat列表数据,存放到tempdata中
tempdata=tempdata[::-1] #倒序遍历tempdata数据,将原来降序,排成升序。
split=23
rotations=np.linspace(90,-270,N, endpoint=False)
for i in range(N-split):
ax.text(theta[i]-0.02,radii[i]+11,tempdata[i]["nation"]+"\n"+str(tempdata[i]["confirmed"])+'例',rotation=rotations[i],ha="center"
,fontsize=20)
for i in range(N-split,N):
ax.text(theta[i],radii[i]-11,tempdata[i]["nation"]+"\n"+str(tempdata[i]["confirmed"])+'例',ha="center"
,fontsize=16,color="black",fontstyle='normal',fontweight='black',)
plt.title("全球新冠肺炎疫情",fontsize="99",horizontalalignment="right",color="black")
cell_width = 212
cell_height = 22
swatch_width= -232
axes_kwargs={"fc":"#000000"}
axins1=inset_axes(ax,width=39*0.18, height=35*0.16, loc=1)
n = len(dat)-N-100
ncols = 2
nrows = n // ncols + int(n % ncols > 0)
# dat=dat[N:]
labeldata=dat[N:]
axins1.set_xlim(0,cell_width*2)
axins1.set_ylim(cell_height* (nrows-0.5),-cell_height/2.)
axins1.yaxis.set_visible(False)
axins1.xaxis.set_visible(False)
axins1.set_axis_off()
ax
for i in range(n):
row = i % nrows
col = i // nrows
y = row * cell_height
swatch_start_x = cell_width * col
swatch_end_x = cell_width * col + swatch_width
text_pos_x = cell_width * col + swatch_width + 10
axins1.text(text_pos_x-35, y, str(labeldata[i]["confirmed"]), fontsize=15,
horizontalalignment='left',
verticalalignment='center',
backgroundcolor="hotpink")
axins1.text(text_pos_x, y, labeldata[i]["nation"], fontsize=15,
horizontalalignment='left',
verticalalignment='center')
plt.savefig("D://ex2.png")
plt.show()
运行结果:
模范作业的代码:
数据集下载地址https://download.csdn.net/download/aiboom/13115610
import pandas as pd
from pyecharts.charts import Pie,Grid,TreeMap
from pyecharts import options as opts
# 导入输出图片工具
#from pyecharts.render import make_snapshot
# 使用snapshot-selenium 渲染图片
#from snapshot_selenium import snapshot
data = pd.read_csv("D:\Homework\上课课件\大数据审计\data\data.csv")
#print(data['Country/Region']['confirmed'])
data.sort_values(by='confirmed',ascending=False,inplace=True)
#确诊人数超过35万的国家和地区
rank = data[data['confirmed']>350000]
#确诊人数少于35万的国家和地区
subdata = data[data['confirmed']<350000]
v = rank['Country/Region'].values.tolist()
d = rank['confirmed'].values.tolist()
pie = (Pie(init_opts=opts.InitOpts(width='1350px',height='750px',theme= "white",bg_color='white'))
.add(
"",[list(z) for z in zip(v,d)],
radius = ["30%", "135%"], # 设置内半径和外半径
center = ["50%", "75%"], # 设置圆心位置
is_clockwise = False,
rosetype = "area"
) # 玫瑰图模式,通过半径区分数值大小,角度大小表示占比
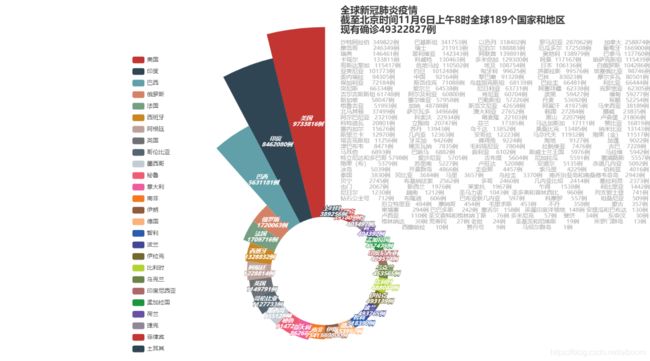
.set_global_opts(title_opts = opts.TitleOpts(title="全球新冠肺炎疫情\n截至北京时间11月6日上午8时全球189个国家和地区\n现有确诊49322827例", # 设置图标题
subtitle ='''沙特阿拉伯 349822例 巴基斯坦 341753例 以色列 318402例 罗马尼亚 287062例 加拿大 258874例
摩洛哥 246349例 瑞士 211913例 尼泊尔 188883例 厄瓜多尔 172508例 葡萄牙 166900例
瑞典 146461例 玻利维亚 142343例 阿联酋 139891例 奥地利 138979例 巴拿马 137760例
卡塔尔 133811例 科威特 130463例 多米你加 129300例 阿曼 117167例 哈萨克斯坦 115439例
哥斯达黎加 115417例 危地马拉 110502例 埃及 108754例 日本 106136例 白俄罗斯 104286例
亚美尼亚 101773例 约旦 101248例 匈牙利 99625例 洪都拉斯 99576例 埃塞俄比亚 98746例
委内瑞拉 94305例 中国 92164例 黎巴嫩 91328例 巴林 83023例 摩尔多瓦 80501例
保加利亚 72184例 斯洛伐克 71088例 乌兹别克斯坦 68139例 巴拉圭 66481例 利比亚 66444例
突尼斯 66334例 爱尔兰 64538例 尼日利亚 63731例 阿塞拜疆 62338例 克罗地亚 62305例
吉尔吉斯斯坦 61748例 阿尔及利亚 60800例 肯尼亚 60704例 波黑 59427例 缅甸 59277例
新加坡 58047例 塞尔维亚 57958例 巴勒斯坦 57226例 丹麦 53692例 希腊 52254例
格鲁吉亚 51993例 加纳 48788例 斯洛文尼亚 42658例 阿富汗 41975例 马来西亚 38189例
北马其顿 37499例 萨尔瓦多 34966例 澳大利亚 27652例 韩国 27284例 挪威 23835例
阿尔巴尼亚 23210例 科索沃 22934例 喀麦隆 22103例 黑山 22079例 卢森堡 21806例
科特迪瓦 20801例 立陶宛 20747例 芬兰 17385例 马达加斯加 17111例 赞比亚 16819例
塞内加尔 15676例 苏丹 13943例 乌干达 13852例 莫桑比克 13485例 纳米比亚 13143例
斯里兰卡 12970例 几内亚 12363例 安哥拉 12223例 马尔代夫 11932例 刚果(金) 11517例
塔吉克斯坦 11256例 牙买加 9426例 佛得角 9224例 海地 9127例 加蓬 9022例
津巴布韦 8471例 博茨瓦纳 7835例 毛利塔尼亚 7804例 拉脱维亚 7476例 古巴 7228例
马耳他 6893例 巴哈马 6882例 叙利亚 6102例 斯威士兰王国 5976例 马拉维 5942例
特立尼达和多巴哥 5798例 爱沙尼亚 5705例 吉布提 5604例 尼加拉瓜 5591例 塞浦路斯 5557例
刚果(布) 5379例 苏里南 5227例 卢旺达 5208例 安道尔 5135例 赤道几内亚 5092例
冰岛 5039例 开曼群岛 4866例 圭亚那 4457例 索马里 4229例 伯利兹 4016例
泰国 3830例 冈比亚 3684例 马里 3657例 乌拉圭 3370例 南乔治亚岛和南桑德韦奇岛 2943例
贝宁 2745例 布基纳法索 2562例 多哥 2460例 几内亚比绍 2414例 塞拉利昂 2373例
也门 2067例 新西兰 1976例 莱索托 1967例 乍得 1538例 利比里亚 1442例
尼日尔 1230例 越南 1212例 圣马力诺 1043例 圣多美和普林西比 960例 列支敦士登 741例
钻石公主号 712例 布隆迪 606例 巴布亚新几内亚 597例 科摩罗 557例 坦桑尼亚 509例
厄立特里亚 484例 摩纳哥 454例 毛里求斯 453例 不丹 358例 蒙古 357例
柬埔寨 294例 巴巴多斯 242例 塞舌尔 158例 英属印度洋领地 148例 安提瓜和巴布达 130例
卢西亚 110例 圣文森特和格林纳丁斯 76例 多米尼克 57例 斐济 34例 东帝汶 30例
格林纳达 30例 梵蒂冈 27例 老挝 24例 圣基茨和尼维斯 19例 所罗门群岛 13例
西撒哈拉 10例 赞丹号 9例 马绍尔群岛 1例''',
#printData(sub) ,
pos_right = '30%', # 图标题的位置
#pos_bottom= 'center',
pos_left= '52%',
pos_top= '1%',
title_textstyle_opts=opts.TextStyleOpts(font_size='20'),
subtitle_textstyle_opts=opts.TextStyleOpts(font_size='12',padding=[2,2,2,2])
),
legend_opts = opts.LegendOpts( # 设置图例
orient='vertical', # 垂直放置图例
pos_left="20%", # 设置图例位置
pos_top="15%"
),
toolbox_opts = opts.ToolboxOpts()
)
.set_series_opts(label_opts = opts.LabelOpts(formatter="{b} \n {c}例", position='inside',
font_size=12, font_style="italic",font_weight="bold", font_family="Microsoft YaHei"),
)
)
pie.render('全球疫情图.html')
# 输出保存为图片
#make_snapshot(snapshot, pie.render(), "全球疫情图.png")
运行结果: