基于win10复现swin-transformer图像分类源码
文章目录
- 前言
- 一、swin-transformer结构
- 二、环境搭建
-
- 1.克隆工程
- 2.创建环境
- 3.安装pytorch
- 4.安装其他库
- 5.安装Apex
- 6.小结
- 7.代码运行
- 三、出现问题及解决办法
- 总结
前言
为了学业在tensorflow和pytorch中渐行渐远,复现他人的成果是一条不比自己创新简单的道路,过程中会遇到各种各样的问题,即使完全按照别人的步骤和过程来操作也会不断的遇到令人秃头的报错。但是大部分基于linux、docker等一些东西对于为了出成果以及初学者来说是一件吃力费劲的事情,所以基于windows10系统学习成了唯一的执著,同时也带来了一堆烦恼,只能在秃头的路上继续坚持!
一、swin-transformer结构

结构很优雅,在现有模型结构中一骑绝尘,效果均表现优异,短时间之内基于swin-transformer的成果创新层出不穷,再不学习来不及了,快上车!!!
二、环境搭建
复现代码最好使用与成果同样的环境,会避免很多的问题,此处为官方示例的步骤Swin Transformer for Image Classification,区别在于步骤:安装apex不同。下面步骤会全部叙述。
复现使用数据集:tiny-imagenet-200,
链接:https://pan.baidu.com/s/11YjywDcyFqnP8oA28j2JFQ
提取码:8888
1.克隆工程
官方代码:
git clone https://github.com/microsoft/Swin-Transformer.git
cd Swin-Transformer
2.创建环境
在anaconda命令行中创建环境:
conda create -n swin python=3.7 -y
conda activate swin
3.安装pytorch
官方代码:
conda install pytorch==1.7.1 torchvision==0.8.2 cudatoolkit=10.1 -c pytorch
安装其他版本参考上一篇博客,最好跟官方一样,不过后续这里会改动,接着看。
4.安装其他库
分别在命令行中执行:
pip install timm==0.3.2
pip install opencv-python==4.4.0.46 termcolor==1.1.0 yacs==0.1.8
5.安装Apex
Apex是一款基于 PyTorch 的混合精度训练加速神器
官方代码为(基于linux系统):
git clone https://github.com/NVIDIA/apex
cd apex
pip install -v --disable-pip-version-check --no-cache-dir --global-option="--cpp_ext" --global-option="--cuda_ext" ./
因为我们是基于windows10操作系统,所以这里会有一点不一样。具体步骤如下:
1.在github下载源码https://github.com/NVIDIA/apex 到本地文件夹(安装步骤第一步网盘中也有相关文件资源);
2.在命令行中切换到apex所在文件夹;
3.输入命令: python setup.py install 等待安装完成即可。
举例操作如下:(假定已经下载好apex文件,此处以放在E盘根目录为例)
$ 接第四步安装完其他库之后,在anaconda命令行 中先将路径切换到E盘符
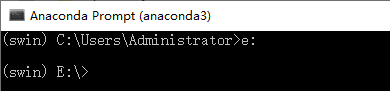
$ 然后继续将路径切换指定到apex文件夹
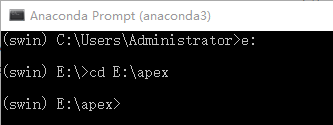
$ 最后输入 python setup.py install ,回车,等待apex安装完成。

6.小结
环境搭建过程就是上述这些,整个工程文件夹如下图所示,其中imagenet是存放数据集文件夹,pth是预训练模型文件夹,output为模型保存文件夹(程序运行时会自动创建),其他文件夹均为官方代码工程文件。
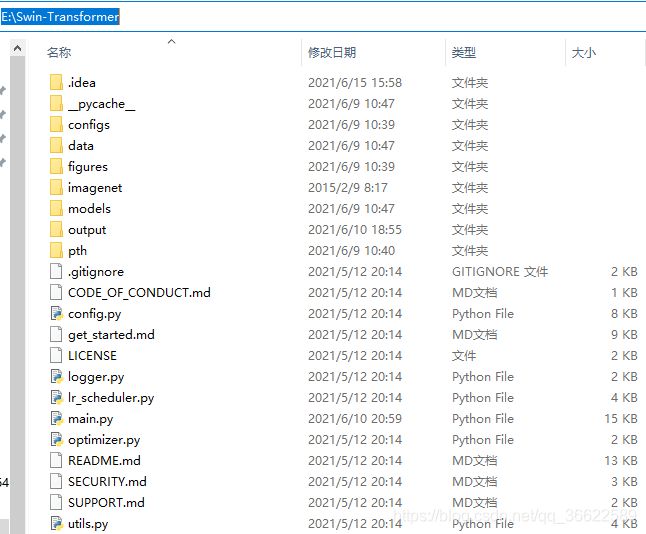
敲黑板
imagenet数据集太大,所以跑的时候用的是tiny-imagenet-200数据集(下载链接见第二章开头),而下载下来的数据集结构如下:
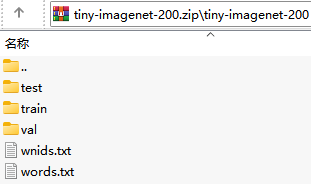

可以看到val验证集里面是一堆图片,没有像train训练集那样分类放在子文件夹下,而官方标准数据文件夹结构如下:
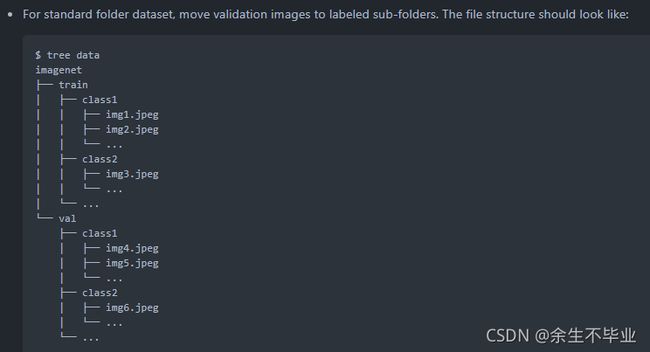
所以需要对val处理一下,编写一个 .py 自动执行脚本,代码如下:
import glob
import os
from shutil import move
from os import rmdir
target_folder = './imagenet/val/'
val_dict = {}
with open('./imagenet/val/val_annotations.txt', 'r') as f:
for line in f.readlines():
split_line = line.split('\t')
val_dict[split_line[0]] = split_line[1]
# print(val_dict)
# print(val_dict.keys())
paths = glob.glob('E:\\Swin-Transformer\\imagenet\\val\\images\\*')
for path in paths:
file = path.split('\\')[-1]
# print(file)
folder = val_dict[file]
if not os.path.exists(target_folder + str(folder)):
os.mkdir(target_folder + str(folder))
os.mkdir(target_folder + str(folder) + '/images')
for path in paths:
file = path.split('\\')[-1]
folder = val_dict[file]
dest = target_folder + str(folder) + '/images/' + str(file)
move(path, dest)
rmdir('./imagenet/val/images')
其中的路径按照自己的来改,注意/和\的区别,可以把脚本文件放到工程文件里,然后在pycharm中右键运行就好了,得到和train一样的文件结构。
7.代码运行
下述均在终端Terminal中运行
1.在imagenet上训练swin transformer模型:
官方代码:
python -m torch.distributed.launch --nproc_per_node <num-of-gpus-to-use> --master_port 12345 main.py --cfg <config-file> --data-path <imagenet-path> [--batch-size <batch-size-per-gpu> --output <output-directory> --tag <job-tag>]
尖括号中参数需自己配置,可以运行如下示例:
python -m torch.distributed.launch --nproc_per_node 4 --master_port 12345 main.py --cfg configs/swin_tiny_patch4_window7_224.yaml --data-path imagenet --batch-size 64
其中 nproc_per_node 为GPU数量,可以设置为自己拥有的数量,不修改的话也可以,忽略警告即可;master_port 为端口号,如果此处报错 RuntimeError: Address already in use ,可以更改为其他空闲端口,如23467,88888等。
2. 模型评估
官方代码:
python -m torch.distributed.launch --nproc_per_node <num-of-gpus-to-use> --master_port 12345 main.py --eval --cfg <config-file> --resume <checkpoint> --data-path <imagenet-path>
实际运行可为:
python -m torch.distributed.launch --nproc_per_node 4 --master_port 12345 main.py --eval --cfg configs/swin_tiny_patch4_window7_224.yaml --resume/pth/swin_tiny_patch4_window7_224.pth --data-path imagenet
三、出现问题及解决办法
因为我们是在windows10上运行代码,所以做到上述第7步会出现报错导致代码运行不了,需要做一些修改。
1) 提示在main.py文件第312行报错,如图:

解决方法:将 backend=‘nccl’ 修改为 backend=‘gloo’,原因是win10暂时不支持nccl模式,即第312行改为:
torch.distributed.init_process_group(backend='gloo', init_method='env://', world_size=world_size, rank=rank)
2) 重新运行,阿偶,依然报错,错误同上图类似,为RuntimeError: No rendezvous handler for env://,这个问题很头疼,源于多GPU训练,而且windows对pytorch分布式计算支持不够,网上可以参考的解决办法很少。
解决办法:
修改环境配置,没看错,将pytorch版本更新,即将pytorch 1.7.1+torchvision 0.8.2 版本更新为pytorch 1.8.1+torchvision 0.9.1(upgrade作用好像是更新到最新版本,最新版本的话会出现其它问题)
conda install pytorch==1.8.1 torchvision==0.9.1 cudatoolkit=10.1 -c pytorch
其他办法:
这个方法是从官方社区看到的,自己太菜没有尝试,思路为将代码中分布式训练的DistributedDataParallel修改为Dataparallel,或者将分布式训练的代码直接去掉。
究极办法:
换电脑!换电脑!换电脑!
最终在3个2080Ti的电脑上跑的很顺畅。平时用的电脑是NVIDIA Quadro P4000,代码能跑倒是能跑,有时会报错RuntimeError: CUDA error: invalid device ordinal,有时直接第一轮训练跑一点就直接Killing subprocess,所以不管是不是win10系统,代码运行跟电脑配置还是有很大关系的!
总结
折腾了四五天时间,最终以batch size=64 在3个2080 Ti 电脑上跑了将近26个小时,才跑完在imagenet上建立模型的过程,评估过程倒是很快,最终结果还挺不错。
鸽了很久才写完这篇,想表达的东西有很多,想起来再做补充,谨以此作为学习笔记和心得分享!