yolov5——问题记录
简介
记录自己学习yolov5中遇到的问题,随即不定时更新,遇到问题记录下来方便回顾。
2022.05.06
1、改用VOC数据集进行训练,修改完格式后,运行train.py报错:
AssertionError: train: No labels in …/train.cache. Can not train without labels. See https://github.com/ultralytics/yolov5/wiki/Train-Custom-Data
解决方法:打开文件目录下 utils/dataset.py 文件,ctrl+F搜索define label,然后将框中内容修改为自己存放图片的文件夹名称,从"images"修改为"JPEGImages"即可。

2022.6.12
1、用云服务器训练的时候,遇到了这个问题:
ImportError: libgthread-2.0.so.0: cannot open shared object file: No such file or directory
解决方法:
apt-get update
#安装额外的包
apt-get install libxext-dev
apt-get install libxrender1
apt-get install libglib2.0-dev
2、冻结训练和解冻训练和预训练权重的问题
预训练权重是针对他们数据集训练得到的,如果是训练自己的数据集还能用吗?
预训练权重对于不同的数据集是通用的,因为特征是通用的。一般来讲,从0开始训练效果会很差,因为权值太过随机,特征提取效果不明显。对于目标检测模型来说,一般不从0开始训练,至少会使用主干部分的权值,虽然有些论文提到了可以不用预训练,但这主要是因为他们的数据集比较大而且他们的调参能力很强。如果从0开始训练,网络在前几个epoch的Loss可能会非常大,并且多次训练得到的训练结果可能相差很大,因为权重初始化太过随机。
因为目标检测模型里,主干特征提取部分所提取到的特征是通用的,把backbone冻结起来训练可以加快训练效率,也可以防止权值被破坏。在冻结阶段,模型的主干被冻结了,特征提取网络不发生改变,占用的显存较小,仅对网络进行微调。在解冻阶段,模型的主干不被冻结了,特征提取网络会发生改变,占用的显存较大,网络所有的参数都会发生改变。举个例子,如果在解冻阶段设置batch_size为4,那么在冻结阶段有可能可以把batch_size设置到8。下面是进行冻结训练的示例代码,假设前50个epoch冻结,后50个epoch解冻:
关于预训练权重加载。更改完网络结构后,即使更改了主干特征提取网络,也是可以加载预训练权重的。通过加载预训练权重,可以将网络中的参数初始化,我理解的是更有利于网络模型的复现,以及加快模型训练收敛速度。如下图所示,会根据你的网络结构,加载一部分参数。所以朋友们如果想改网络的话,也可以选择加载预训练模型的。
总结:无论换什么主干!!!都能用权重!!!都能用!!!都能用!!!
3、训练时出现以下问题:
TypeError: init() missing 1 required positional argument: ‘dtype’
翻译过来就是:类的构造函数需要一个’dtype’参数.但你创建类时没有传递
解决方法:
在train.py中把 num_workers 改小一些
2022-6-14
添加注意力机制
1、第一步:在common.py文件中写入注意力机制代码,比如CBAM,将以下代码复制到common.py下
# CBAM
class ChannelAttention(nn.Module):
def __init__(self, in_planes, ratio=16):
super(ChannelAttention, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.f1 = nn.Conv2d(in_planes, in_planes // ratio, 1, bias=False)
self.relu = nn.ReLU()
self.f2 = nn.Conv2d(in_planes // ratio, in_planes, 1, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = self.f2(self.relu(self.f1(self.avg_pool(x))))
max_out = self.f2(self.relu(self.f1(self.max_pool(x))))
out = self.sigmoid(avg_out + max_out)
return out
class SpatialAttention(nn.Module):
def __init__(self, kernel_size=7):
super(SpatialAttention, self).__init__()
assert kernel_size in (3, 7), 'kernel size must be 3 or 7'
padding = 3 if kernel_size == 7 else 1
# (特征图的大小-算子的size+2*padding)/步长+1
self.conv = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
# 1*h*w
avg_out = torch.mean(x, dim=1, keepdim=True)
max_out, _ = torch.max(x, dim=1, keepdim=True)
x = torch.cat([avg_out, max_out], dim=1)
# 2*h*w
x = self.conv(x)
# 1*h*w
return self.sigmoid(x)
class CBAM(nn.Module):
# CSP Bottleneck with 3 convolutions
def __init__(self, c1, c2, ratio=16, kernel_size=7): # ch_in, ch_out, number, shortcut, groups, expansion
super(CBAM, self).__init__()
self.channel_attention = ChannelAttention(c1, ratio)
self.spatial_attention = SpatialAttention(kernel_size)
def forward(self, x):
out = self.channel_attention(x) * x
# c*h*w
# c*h*w * 1*h*w
out = self.spatial_attention(out) * out
return out
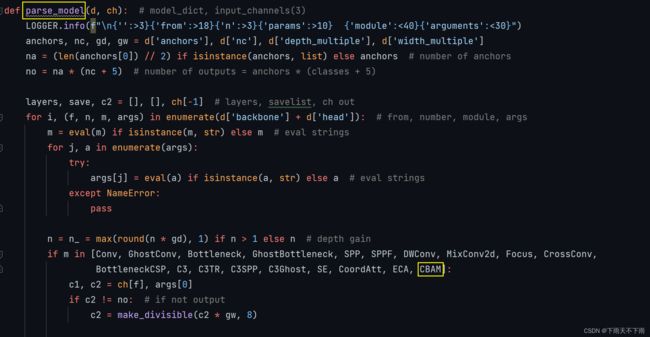
2、找到yolo.py文件下的parse_model函数,将类名加入到下图位置
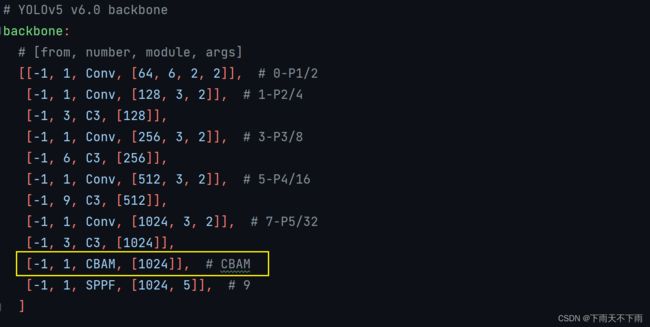
3、修改配置文件yaml,比如yolov5s.yaml,如下图,将注意力机制加到backbone的最后一层(也可加在C3里面)
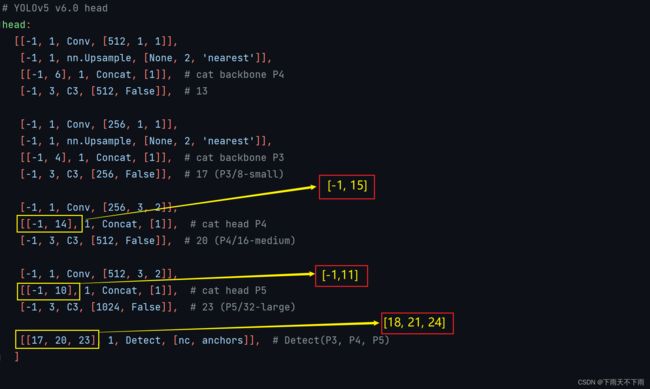
然后,还没完,还要继续修改head部分。当在网络中添加了新的层之后,那么该层网络之后的层的编号都会发生改变,看下图,原本Detect指定的是[17,20,23],但当添加过CBAM注意力层之后(添加在第9层的,9层之后的层数编号要1),修改Detect:[17,20,23]->[18,21,24]。同样的,Concat 前的from系数也要修改,这样才能保持原网络结构不发生特别大的改变。我们刚才把SE层加到了第9层,所以第9层之后的编号都会加1,这里我们要把后面两个Concat的from系数分别由[-1,14]->[-1,15] ,[-1,10]->[-1,11]。
至此,注意力机制添加完毕,其他注意力机制添加方法相同。
2022-06-27
thop库安装与使用
1、介绍,yolov5用 thop 三方库来计算网络的GFLOPs,正确安装thop才会显示GFLOPs
2、问题,直接pip install thop,然后会显示已成功安装。但是!问题来了,训练时并不显示网络的GFLOPs!卸载再安装,还是不行!
3、原因就是thop安装方法错了,要将github上thop下载到本地,再安装,才能正确显示。
安装步骤如下:
第一步,找到 thop 包的github官方链接 thop
第二步,下载压缩文件,解压到本地路径
第三步,打开annaconda prompt,激活进入自己的虚拟环境,cd到压缩包解压的路径下
第四步,输入命令python setup.py install,等待安装完成即可
2022-08-05
问题:
使用YOLOv5训练时,出现以下错误:
RuntimeError: result type Float can’t be cast to the desired output type long int
原因猜测:
之前使用torch1.8.0和torchvision0.8.0没什么问题,换了torch1.12.0和torchvision0.13.0后,loss.py函数,就报错了,可能也是yolov5版本更新的问题。
解决方法:
修改loss.py的两处内容
1、打开loss.py,ctrl+F 搜索 ,输入 【for i in range(self.nl)】,找到下面内容:

下面是修改后的内容,方便复制:
anchors, shape = self.anchors[i], p[i].shape
2、ctrl+F 搜索,输入【indices.append】,找到下面的内容,注意看清楚,别找错了

indices.append((b, a, gj.clamp_(0, shape[2] - 1), gi.clamp_(0, shape[3] - 1))) # image, anchor, grid
3、保存运行,完美解决,已亲测可用!
2022-08-16
问题:
tpdm安装
有时候,pip install tpdm安装失败
换用这行命令:conda install -c conda-forge tqdm
2022-08-25
问题:
云服务器,Ubuntu系统下,运行python,报错:ModuleNotFoundError: No module named '_tkinter',提示缺少tkinter模块
解决方法:
sudo apt-get update
sudo apt-get install python3.7-tk