随机森林简单回归预测
随机森林(RandomForest)简单回归预测
随机森林是bagging方法的一种具体实现。它会训练多棵决策树,然后将这些结果融合在一起就是最终的结果。随机森林可以用于分裂,也可以用于回归。主要在于决策树类型的选取,根据具体的任务选择具体类别的决策树。
对于分类问题,一个测试样本会送到每一颗决策树中进行预测,然后投票,得票最多的类为最终的分类结果;
对于回归问题,随机森林的预测结果是所有决策树输出的均值。
本文介绍利用随机森林进行时间序列的简单回归预测,满足大部分科研需求。
介绍
随机森林的优点:
在数据集上表现良好,两个随机性的引入,使得随机森林不容易陷入过拟合,但是对于小数据集还是有可能过拟合,所以还是要注意;
两个随机性的引入,使得随机森林具有很好的抗噪能力;
它能够处理很高维的数据,并且不用做特征选择,对数据集的适应能力强。既能处理离散性数据,也能处理连续型数据,数据集无需规范化;
在创建随机森林的时候,对generalization error使用的是无偏估计;
训练速度快,可以得到变量重要性排序;
在训练过程中,能够检测到feature间的互影响;
容易做成并行化方法;
实现比较简单
随机森林的缺点:
对于小数据集和低维的数据效果可能不是很好。
整个模型为黑盒,没有很强的解释性。
由于随机森林的两个随机性,导致运行结果不稳定。
数据准备
安装所需要的py库
pip install sklearn导入所需要的包
import numpy as np
import matplotlib.pyplot as plt
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import train_test_split
from sklearn.multioutput import MultiOutputRegressor单输出回归
预测给定输入的单个数字输出。
随机构建训练集和测试集
rng = np.random.RandomState(1)
X = np.sort(200 * rng.rand(600, 1) - 100, axis=0)
y = np.array([np.pi * np.sin(X).ravel()]).T
y += (0.5 - rng.rand(*y.shape))
#x和y的shape为(600, 1) (600, 1)
X_train, X_test, y_train, y_test = train_test_split(
X, y, train_size=400, test_size=200, random_state=4)
#X_train, X_test, y_train, y_test的shape
#为(400, 1) (200, 1) (400, 1) (200, 1)构建模型并进行预测
#定义模型
regr_rf = RandomForestRegressor(n_estimators=100, max_depth=30,
random_state=2)
# 集合模型
regr_rf.fit(X_train, y_train)
# 利用预测
y_rf = regr_rf.predict(X_test)
#评价
print(regr_rf.score(X_test, y_test))作图
plt.figure()
s = 50
a = 0.4
plt.scatter(X_test, y_test, edgecolor='k',
c="navy", s=s, marker="s", alpha=a, label="Data")
plt.scatter(X_test, y_rf, edgecolor='k',
c="c", s=s, marker="^", alpha=a,
label="RF score=%.2f" % regr_rf.score(X_test, y_test))
plt.xlim([-6, 6])
plt.xlabel("X_test")
plt.ylabel("target")
plt.title("Comparing random forests and the test")
plt.legend()
plt.show()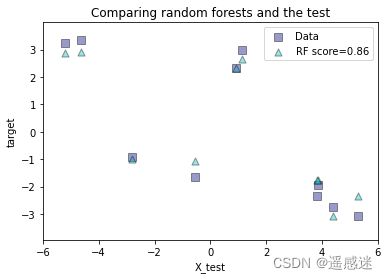
多输出回归
根据输入预测两个或多个数字输出。
随机构建训练集和测试集,这里构建的是一个x对应两个y
rng = np.random.RandomState(1)
X = np.sort(200 * rng.rand(600, 1) - 100, axis=0)
y = np.array([np.pi * np.sin(X).ravel(), np.pi * np.cos(X).ravel()]).T
y += (0.5 - rng.rand(*y.shape))
#x和y的shape为(600, 1) (600, 2)
X_train, X_test, y_train, y_test = train_test_split(
X, y, train_size=400, test_size=200, random_state=4)
#X_train, X_test, y_train, y_test的shape
#为(400, 1) (200, 2) (400, 1) (200, 2)构建模型并进行预测
这里尝试了利用随机森林和包装器类两种方法
#定义模型
max_depth = 30
regr_multirf = MultiOutputRegressor(RandomForestRegressor(n_estimators=100, max_depth=max_depth, random_state=0))
# 拟合模型
regr_multirf.fit(X_train, y_train)
#定义模型
regr_rf = RandomForestRegressor(n_estimators=100, max_depth=max_depth,
random_state=2)
# 拟合
regr_rf.fit(X_train, y_train)
#预测
y_multirf = regr_multirf.predict(X_test)
y_rf = regr_rf.predict(X_test)作图
plt.figure()
s = 50
a = 0.4
plt.scatter(y_test[:, 0], y_test[:, 1], edgecolor='k',
c="navy", s=s, marker="s", alpha=a, label="Data")
plt.scatter(y_multirf[:, 0], y_multirf[:, 1], edgecolor='k',
c="cornflowerblue", s=s, alpha=a,
label="Multi RF score=%.2f" % regr_multirf.score(X_test, y_test))
plt.scatter(y_rf[:, 0], y_rf[:, 1], edgecolor='k',
c="c", s=s, marker="^", alpha=a,
label="RF score=%.2f" % regr_rf.score(X_test, y_test))
plt.xlim([-6, 6])
plt.ylim([-6, 6])
plt.xlabel("target 1")
plt.ylabel("target 2")
plt.title("Comparing random forests and the multi-output meta estimator")
plt.legend()
plt.show()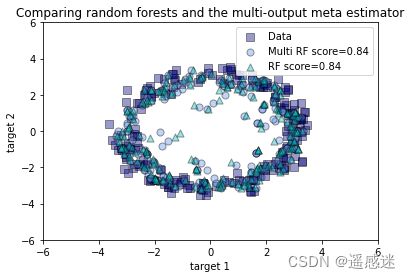
欢迎关注vx公众号遥感迷,更多东西静待发布
